
包阅导读总结
1.
关键词:threejs、智慧塔吊大屏、vite、typescript、技术栈
2.
总结:本文介绍了基于 threejs 与 vite 开发的智慧塔吊大屏项目,采用 typescript 语法,涵盖基础场景、镜头、渲染器、控制器、处理模型等方面,包括相关技术设置和实现细节,如模型加载处理、动态计算、标注绘制及图例显示隐藏等。
3.
主要内容:
– 项目介绍
– 由 threejs 与 vite 开发,采用 typescript 语法
– 基于工地塔吊设备的智慧大屏功能
– 技术栈
– vite 4.3.2
– three 0.161.0
– node v18.19.0
– 基础场景
– 场景:包括 THREE.Scene,设置背景和雾
– 镜头:PerspectiveCamera 透视相机,使用 camera.layers 处理图层
– 渲染器:THREE.WebGLRenderer 和 CSS2DRenderer
– 控制器:OrbitControls 用于操作场景
– 处理模型
– 模型格式为 gltf,使用 GLTFLoader 加载
– 对塔吊等模型进行处理,如获取、复制、设置阴影和 layers
– 动态计算横梁尺寸,模拟横梁上小车位置
– 绘制标注信息,包括确定点位、创建和修改标注
– 处理模拟数据推送,如平台移动、横梁小车移动和塔吊旋转
– 实现图例显示隐藏功能
思维导图: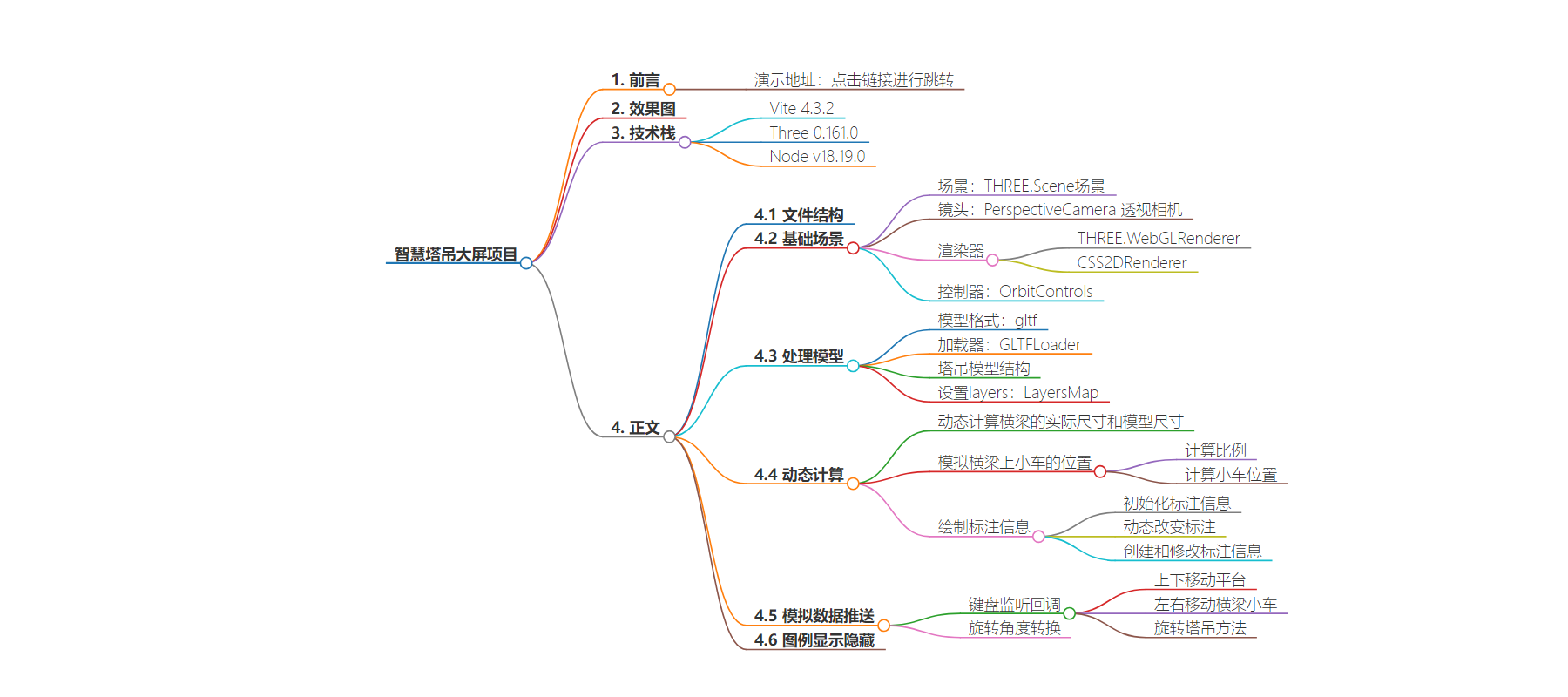
文章地址:https://juejin.cn/post/7402912295166607399
文章来源:juejin.cn
作者:孙_华鹏
发布时间:2024/8/15 3:05
语言:中文
总字数:5736字
预计阅读时间:23分钟
评分:85分
标签:Three.js,Vite,TypeScript,3D可视化,前端开发
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
这都4202年了,你写的大屏还是平平无奇?
前言
演示地址
点击链接进行跳转
随着物联网的火爆,和ai的快速崛起,传统行业在AI赋能的加持下,都在改头换面,拿工地举例,从工人进门开始就有智能打卡机,施工时佩戴的安全帽结合gps和其他传感器能够及时了解人员是否佩戴,在视频监控区域也可以通过ai算法检查工人是否佩戴安全帽;各种传感器安装到机械设备上,能够实时监控设备的数据,下面文章内容就是基于工地的塔吊设备衍生出的一个智慧大屏功能,先上效果图,
欢迎点赞收藏关注
效果图
操作:
图例:
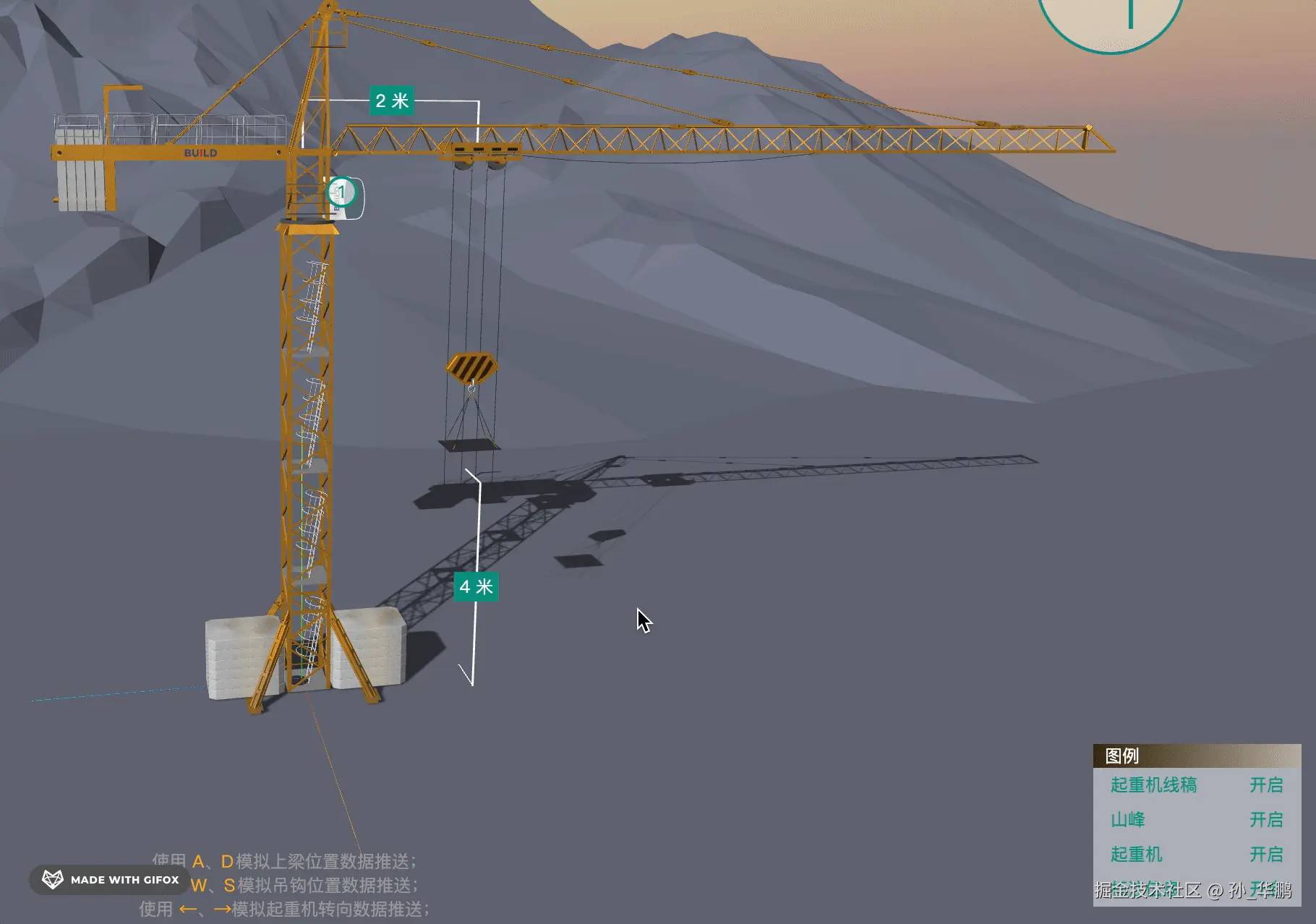
视频演示:

技术栈
- vite 4.3.2
- three 0.161.0
- node v18.19.0
正文
大屏由几个部分组成,最上部是标题,左侧是设备信息,右侧是图例,方向预览和表单,下面主要写的内容是3d部分操作,不涉及设备信息表头这些辅助类的模块
文件结构
为了阅读代码方便,每一个功能都单独抽离到ts文件中,参考以下文件目录

(前摇真长啊~)
基础场景
场景
基础场景在文件scene.ts中主要包括 # THREE.Scene场景,用于承载所有3d部分的内容。
scene = new THREE.Scene();scene.background = new THREE.Color('#000000');scene.fog = new THREE.Fog(new THREE.Color("rgba(111, 114, 130, 0.5)"), 8000, 12000)镜头
镜头使用的是PerspectiveCamera 透视相机,也是常规用的相机,没什么说的,这里要说一下camera.layers.enableAll(),项目中有图例的功能,主要api就是 camera.layers,enableAll启用所有图层,enable 启用某个图层,disableAll 隐藏所有图层,toggle禁用某个图层
透视相机layers的api是从基类 Object3D继承来的,所以理论上基于Object类的物体都支持这个功能。
camera = new THREE.PerspectiveCamera(60, width / height, 0.2, 2000000);camera.position.copy(cameraPos);camera.layers.enableAll()后续在模型中也设置相同的layers,在后面的处理模型和图例显示隐藏会具体提到
渲染器
代码中渲染器写了3种,但实际中只用到了两种THREE.WebGLRenderer和CSS2DRenderer
webglrenderer
renderer = new THREE.WebGLRenderer({ canvas, precision: 'highp', antialias: true, powerPreference: 'high-performance', logarithmicDepthBuffer: true,});renderer.toneMappingExposure = 0.6renderer.setPixelRatio(window.devicePixelRatio);renderer.setSize(width, height);renderer.setPixelRatio(window.devicePixelRatio);renderer.shadowMap.enabled = true;renderer.shadowMap.needsUpdate = truerenderer.shadowMap.autoUpdate = true构建时的参数除了canvas,其他都是调整性能的,代码里调整的都是最高性能,precision着色器精度,antialias抗锯齿,powerPreference以怎样的配置进行渲染,因为选用的渲染器是webglrenderer,所以这个api你也可以在webgl的源码中查看到
enum WebGLPowerPreference { "default", "low-power", "high-performance" };WebGLPowerPreference powerPreference = "default";这些值可以调整为其他可选值用来适配不同的设备性能
setPixelRatio是设置像素比的,用来防止渲染模糊的,这是设置成0.2的效果,如果你想做一些特殊的效果,可以根据不同的数值调整

shadowMap 是用来渲染阴影的,如果设备的性能不行,也可以不渲染,或者渲染低质量的阴影
CSS2DRenderer
labelRenderer = new CSS2DRenderer({ element: css2dDiv});labelRenderer.domElement.classList.add('css2d')labelRenderer.setSize(width, height);CSS2DRenderer是用来显示创建的css2DObject的,其实就是通过css的transform的属性将html的元素放置在不同位置,大概像这样
transform: translate(-50%, -50%) translate(476.36px, 228.269px);而并不是将html元素放到3d世界中,3d渲染元素是canvas,而2d场景是另一个html元素内,如果想做遮挡,需要一些其他手段,比如做防碰撞功能时候需要两个以上塔机,而前面的塔机遮挡了后面的塔机,但是他们的名字标签都展示出来了,这时候需要处理后面被遮挡的塔机名称标签隐藏
具体做法可以参考我之前的文章threejs 打造 world.ipanda.com 同款3D首页,里面有详细的解释
控制器
controls = new OrbitControls(camera, renderer.domElement);controls.minAzimuthAngle = Math.PI * 0.25;controls.maxAzimuthAngle = Math.PI * 0.75;controls.minPolarAngle = Math.PI * 0.25;controls.maxPolarAngle = Math.PI * 0.6;controls.target.set(-144, 814, 0);controls.addEventListener('start', () => { controlsStartPos.copy(camera.position)})controls.addEventListener('end', () => { controlsMoveFlag = controlsStartPos.distanceToSquared(camera.position) === 0})轨道控制器OrbitControls用于操作场景,旋转缩放,都可以单独进行限制,代码里将水平转角和垂直转角进行了限制,让用户只能在某个范围内进行操作,注释掉的代码maxDistance是控制缩放深度,你也可以通过各种enabled属性限制控制器的禁用和启用
控制器的target是用来修改场景位置的,和相机的position不同,这个属性是可以直接修改场景的中心位置,代码中对此进行了设置,如果不设置则是下面的效果
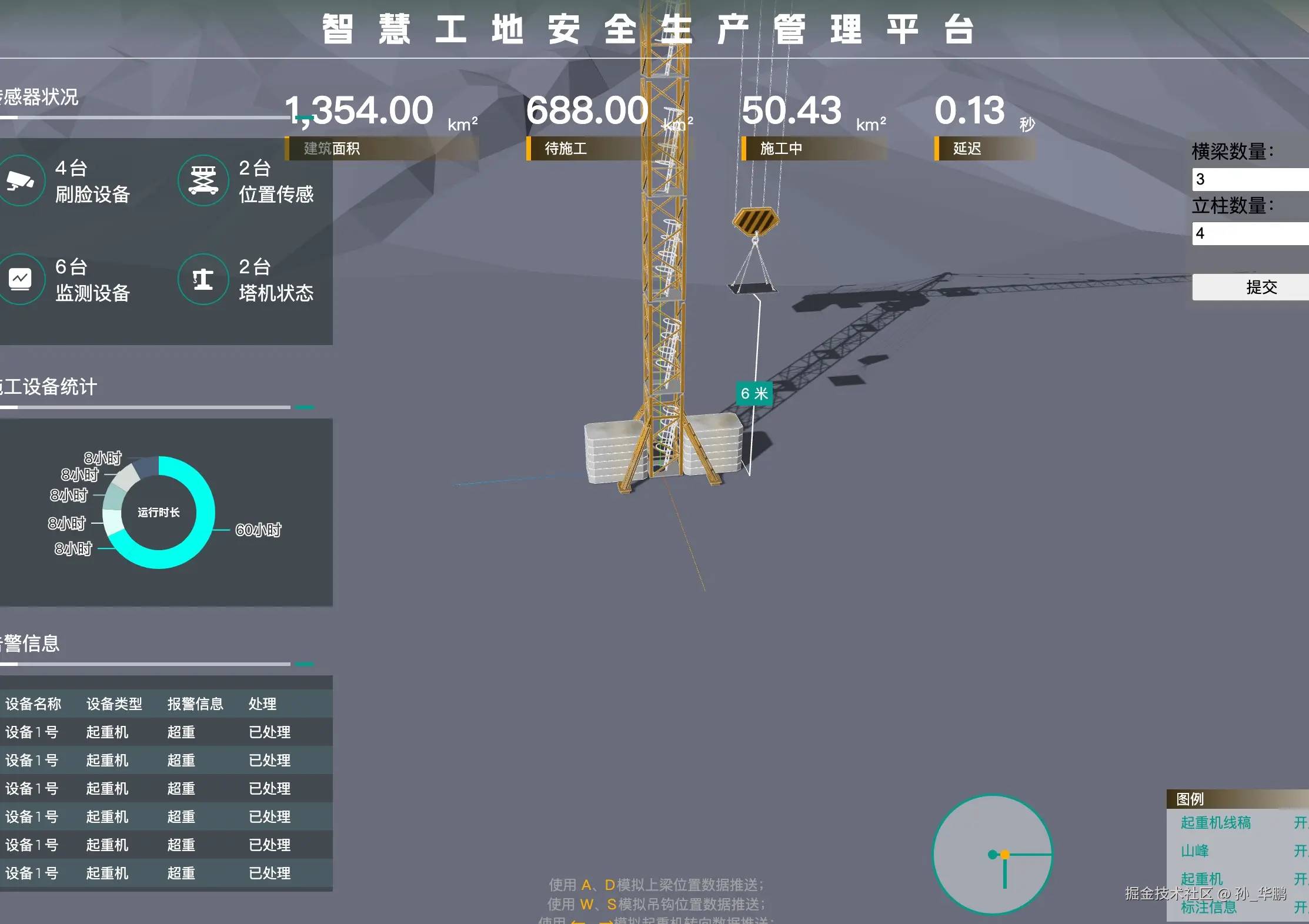
场景的中心在屏幕正中央,导致模型并未展示完全,并且下面还都是空着的,在使用的过程中,根据需要调整。
处理模型
模型格式是gltf的,那么加载器就选择# GLTFLoader,在loader.ts中封装了loadGltf方法,返回GLTF类型,gltf中的scene就是加载后的模型信息
const gltfLoader = new GLTFLoader();export function loadGltf(url: string) { return new Promise<GLTF>((resolve, reject) => { gltfLoader.load(url, function (gltf: GLTF) { console.log(gltf); resolve(gltf) }); })}塔吊模型结构: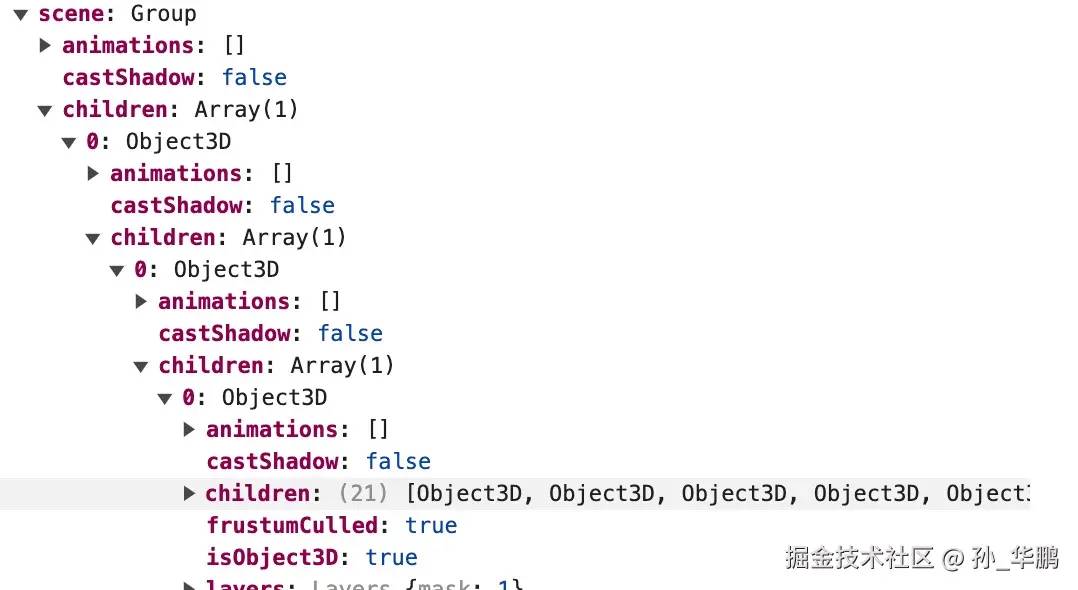
项目中加载了两个模型,一个是后面的山模型,另一个就是塔吊模型,加载模型以后需要对模型进行处理,比如绘制线稿、添加阴影,提取立柱和横梁模型等,都在handleModules.ts中进行的,
模型名称示意:
通过getObjectByName获取立柱对应的模型,删除原有模型(removeFromParent)并赋值给corpsCopy作为新的模型以便后续动态渲染立柱时候使用,横梁同理。
const corps002 = piedClone.getObjectByName('corps002');if (corps002) { corps002.removeFromParent() corpsCopy = corps002.clone() corpsCopy.traverse((mesh: any) => { setLayers(mesh, 'crane') mesh.castShadow = true })}复制模型后通过traverse方法进行遍历,找到每一个模型,设置每一个模型的castShadow属性让模型产生阴影,setLayers设置模型的layers,图例根据不同模型的不同layers进行展示和隐藏
设置layers
export const setLayers = (mesh: Object3D, type: string) => { const meshLayers = LayersMap.get(type); if (meshLayers !== undefined) { mesh.layers.set(meshLayers) }}layersMap是模型类型和layers值的映射,在layerMap.ts文件内,如果想添加其他图例 也可以,只要camera设置的enable和模型的layers对应上,就可以控制显示隐藏
export const LayersMap = new Map([ ['line', 2], ['mountain', 1], ['crane', 3], ['line-tag', 5], ['device-tag', 5],])以上展示了立柱的获取方法,通过getObjectByname的api获取相对应的模型,并赋值给一个公共变量
export let corpsCopy: Object3Dexport let piedClone: Object3Dexport let RootNode: Object3Dexport let corpsHautCopy: Object3D于是我们得到了立柱和横梁的标准节模型
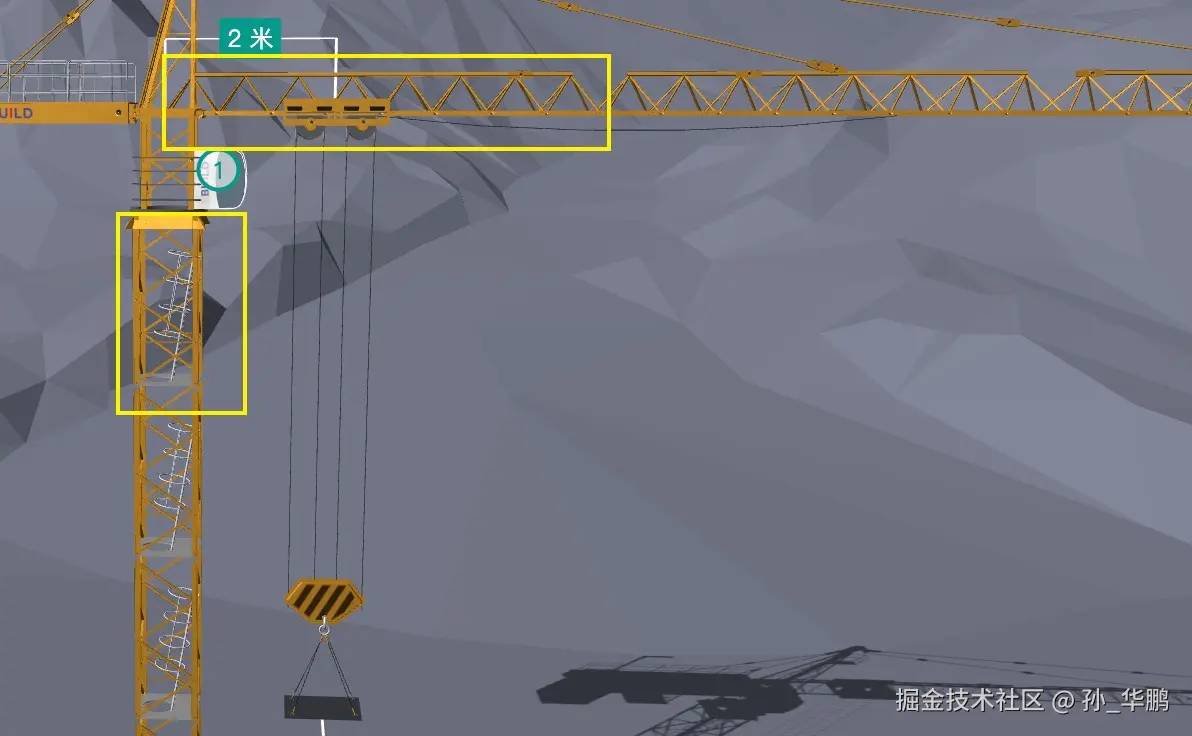
黄色框内两部分就是横梁和立柱的标准节,通过右侧的表单可以复制对应的数量并堆叠在一起,在dynamicConfig.ts文件中进行组装,我们拿横梁作为例子:
动态计算横梁的实际尺寸和模型尺寸
export const rowConfig = (rowCount: number) => { const size = corpsHautCopy.userData.size modalLength = size.z * rowCount rowLength = rowCount * 5 rowEffectiveRange.push(rowLength - 1) for (let i = 0; i < rowCount; i++) { const newHau = corpsHautCopy.clone(); newHau.position.z = -size.z * i RootNode.add(newHau) newHau.traverse((mesh: any) => { const line = getLine(mesh, 10, undefined, 0.5) mesh.parent.add(line) setLayers(line, 'line') }) }}从这个方法中得到:
模型总长度modalLength:标准件数量 rowCount * 标准件模型宽度 corpsHautCopy.userData.size.z(加载模型时通过getBox3Info获取corpsHautCopy.userData.size = size)
实际总长度allLength:标准件数量 * 标准件实际宽度 3米(模拟的)
标准件位置 -size.z * i 标准件模型宽度 * 索引(第几个标准件)
这样我们就计算出了标准件组成的实际宽度和模型宽度,用来计算比例,在代码中对模型绘制了线稿和设置线稿的layers
横梁和立柱都设置最大值9时的效果图:

模拟横梁上小车的位置
移动逻辑 distance.ts文件中包含修改方向盘对应位置,绘制距离标注等功能DistanceTags类用作绘制距离标注和动态修改距离标注的功能
模拟数据字段:distance(推送传入)
横梁实际总长度:allLength(前文获取到的)
横梁模型总长度:modalLength(前文获取到的)
计算比例 sl:distance/allLength
计算小车位置:modalLength * sl
changeModaPosition(distance: number) { this.distance = distance const sl = this.distance / this.allLength; this.proportion = sl const position = this.modalLength * sl this.name2d.element.innerText = `${distance} 米` return position}绘制标注信息
还是以横梁举例:横梁的标注信息含有白色的区域线,还有标签文字,首先要确定区域线的几个定点,首先确认start点位和end点位,再根据固定的偏移量设定其他两点,一共四个点位组成一个区域线。这里讲的是初始化时的标注信息。
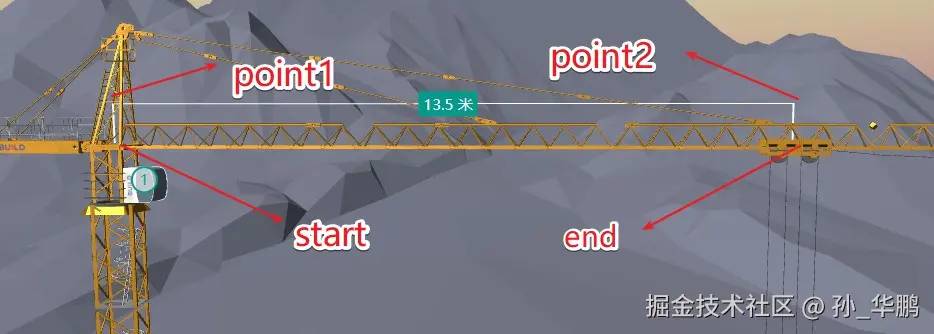
const { worldPosition } = getBox3Info(poulie_poulie_0) const start = new Vector3(0, worldPosition.y, 0)const point1 = new Vector3(0, worldPosition.y + offset, 0)const end = start.clone().setZ(worldPosition.z)const point2 = end.clone().setY(start.y + offset)起点是从0,0,0的位置将高度设置为worldPosition.y,这个是横梁小车的y轴世界坐标,从起点出发,到point1点位,只是将y轴改变了,让它变得更高,offset是自定义的常亮,展示图中的效果的offset是80,当然也可以自定义,根据自己喜好来,end坐标和start坐标唯一的区别就是z轴位置变了,变得更远,也是根据横梁小车的z轴世界坐标获取,而point2是基于end点位将y轴加一个offset的距离。这样四个点就形成了一个区域
动态改变标注
动态改变横梁标注信息在changeRowDistance方法中需要重新计算四个点位,改变的只有end和point2,因为在横梁小车移动时,只有结束的位置改变了,记得上面提到的修改小车position的方法了么,通过获取的position,来计算end和point2的点位信息
const end = start.clone().setZ(-position)const point2 = end.clone().setY(start.y + offset)创建和修改标注信息
通过前面确定的点位信息构建成一个Float32Array再使用BufferGeometry缓冲几何形状将这几个点位信息设置为顶点信息
getGeometry() { const vertices = new Float32Array([ ...this.poulieStart.toArray(), ...this.point1.toArray(), ...this.point2.toArray(), ...this.poulieEnd.toArray() ]); const geometry = new BufferGeometry(); geometry.setAttribute('position', new BufferAttribute(vertices, 3)); return geometry}这样我们就得到了一个缓冲几何形状,再使用line2.ts中提供的方法geometryAttribute2Array将定点信息转成line2线段,
export const geometryAttribute2Array = (geometry: BufferGeometry) => { let linePoints = [] if (geometry.isBufferGeometry) { const position = geometry.getAttribute('position') const { count } = position for (let i = 0; i < count; i++) { const v3 = new Vector3().fromBufferAttribute(position, i); linePoints.push(v3.x, v3.y, v3.z) } } const line2Geometry = new LineGeometry(); line2Geometry.setPositions(linePoints); let line2 = new Line2(line2Geometry, radarLine2MatLine); return line2}想要绘制线段只要传入geometry就可以了,有了顶点信息也绘制出区域线了,那么接下来就是文字标注了,文字标注使用到的就是前面提的css2dObject了,其实就是一个dom元素,确定一下position就可以了,而这个position就是point1和point2这两个点位中间的位置:
getCss2dLabelPos() { const center = this.point2.clone().sub(this.point1).divideScalar(2) return center}用到的都是vector3向量的api:sub相减和divideScalar除以标量
创建css2dObject时需要先创建一个div再将想要放的内容append给div或者直接修改div的innerHTML,当然我这里使用的是原生html,如果用react或者vue这样的mvvm框架的话,需要将框架组件转成html元素后再去创建css2dObject对象。
export const css2dContent = (info: DistanceLabelType) => { const moonMassDiv = document.createElement('div'); moonMassDiv.classList.add(info.class); moonMassDiv.innerHTML = `${info.text}` if (info?.clickBack) { moonMassDiv.addEventListener('click', info?.clickBack) } const label = new CSS2DObject(moonMassDiv); return label}同理驾驶舱的那个标注也是这样写的。
模拟数据推送
键盘监听回调在craneOperate.ts文件中,操作方法有三种,
上下移动平台 changeColumnDistance
左右移动横梁小车 changeRowDistance
旋转塔吊方法
changeRowDistance修改横梁小车的方法前面讲过了,上下移动平台方法和左右移动的方法类似,只不过是轴向变了,左右移动改变的是模型position的Z轴,而上下移动改变的是模型的Y轴;
旋转塔吊相对其他比较简单。需要旋转的模型组在整个塔吊的模型里名称是RootNode,所以我们还用getObjectByName获取到对应的模型,在操作的时候改变rotation.y即可。
RootNode.rotation.y += rotateStep有一点需要注意,这个旋转角度是要和右下角2维图例的旋转相同,但是呢,rotation是代表弧度,是一个euler欧拉角,而css的transform的rotate是角度deg,所以这时候就需要转变一下了,利用弧度转角度的方式
if (needle) { (needle as any).style.transform = `rotate(${-rotate * 180 / Math.PI}deg)`}这样3d模型的旋转和2d图例的旋转就对应上了
图例显示隐藏
图例显示隐藏只是一个例子,主要满足显示的东西太多而导致画面变得凌乱,还那防碰撞功能举例,多个塔吊模型的时候,要专注看某两个模型之间的碰撞关系,就需要隐藏掉其他的塔吊模型,而又不能直接删除,再看的时候再加载一次,所以要用到layers,前面处理模型的时候已经将layers设置进去了,所以监听图例的点击事件做出对应的显示或者隐藏动作即可,功能在文件layers.ts中
...if (newState) { camera.layers.enable(layers)} else { camera.layers.toggle(layers)}...抛去dom的操作只剩两个api,就是enable启用某个图层接受一个图层序列,在前文定义的layersMap映射对应的layers值,toggle隐藏该图层,具体api看camera和Object3d的介绍,用处很大,这是官网的介绍:
物体的层级关系。 物体只有和一个正在使用的Camera至少在同一个层时才可见。当使用Raycaster进行射线检测的时候此项属性可以用于过滤不参与检测的物体.
结语
项目不是很大,但是包含的内容都是threejs基础的,不要把threejs想的多高级多难,只是一个库,不学不会对工资有影响,也不影响做leader和升迁,
如果感兴趣万一不小心学会了,也不会有什么好处,顶多职业生涯多了一个技能,仅此而已
就像当年学会jquery或者学会了echart一样,该淘汰还是淘汰,该用不到还是用不到,
如果真的是对图形学感兴趣,可以学原生webgl或者opengl,那完全是另一个方向了…
源码下载地址
相关源码的下载链接地址点击链接进行跳转
历史文章
高德地图+threejs打造智慧景区大屏
three.js——完整3d大屏展示超详细讲解
threejs——可视化风力发电车物联交互效果 内附源码
three.js——商场楼宇室内导航系统 内附源码
three.js——可视化高级涡轮效果+警报效果 内附源码
three.js 专栏