
包阅导读总结
1. 关键词:Dataproc Metastore、Apache Hive、Deployment Patterns、Google Cloud、Metadata
2. 总结:
本文介绍了 Dataproc Metastore,一种在 Google Cloud 上运行的全托管 Apache Hive 元数据存储,探讨了从本地 Hadoop 环境迁移到它时的部署模式,包括集中式和分散式等,每种模式有其优势,可根据组织需求选择。
3. 主要内容:
– Dataproc Metastore 是全托管的 Apache Hive 元数据存储,运行于 Google Cloud,具有高可用等特性
– 迁移时需考虑组织架构,如集中与分散、单区域与多区域、持久与联合等
– 介绍了四种部署模式
– 单一集中式多区域 DPMS
– 集中式元数据联合与每个域的 DPMS
– 分散式元数据联合与每个域的 DPMS
– 临时元数据联合
– 每种模式有其优势,设计复杂度和成熟度递增,可依需求选择
思维导图: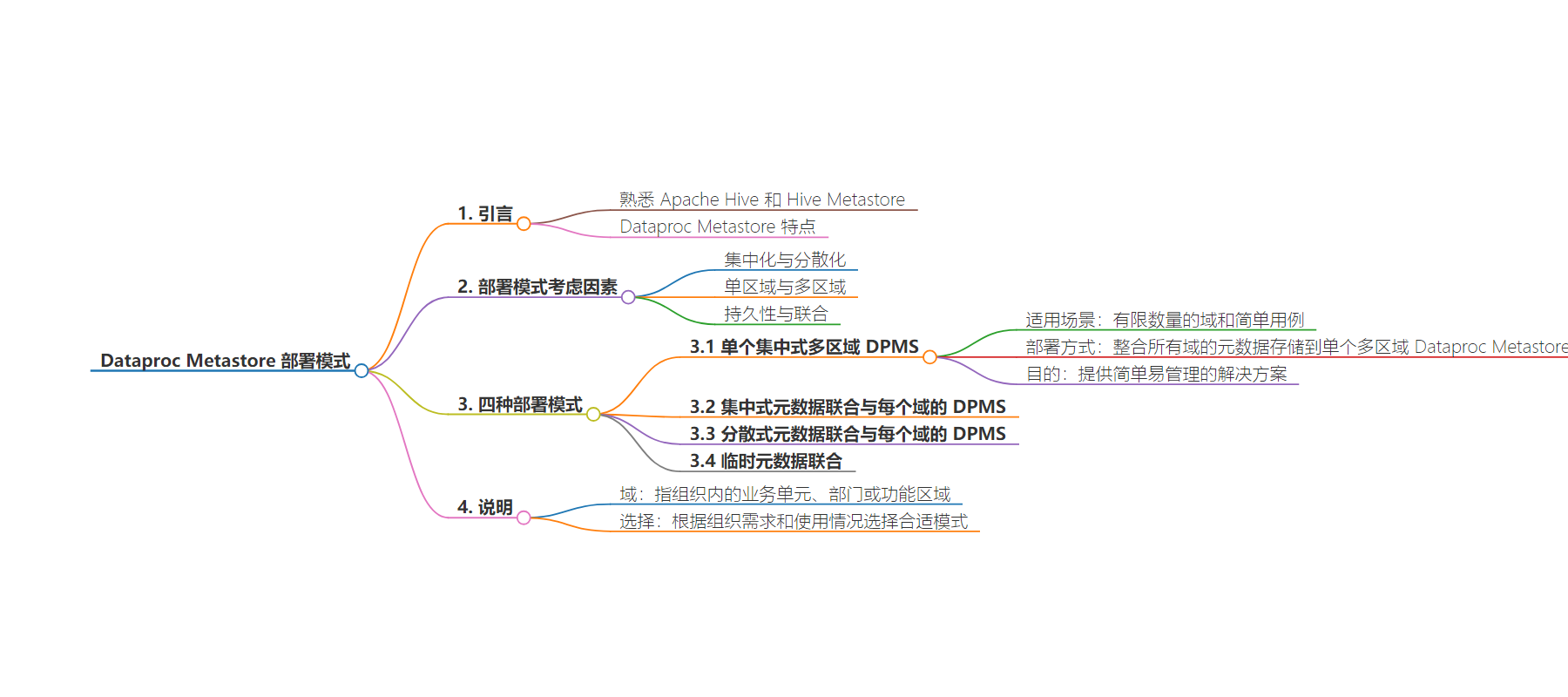
文章地址:https://cloud.google.com/blog/products/data-analytics/four-dataproc-metastore-deployments-patterns/
文章来源:cloud.google.com
作者:Rajashekar Pantangi,Vince Gonzalez
发布时间:2024/7/8 0:00
语言:英文
总字数:1350字
预计阅读时间:6分钟
评分:85分
标签:Dataproc 元数据存储,元数据管理,Google Cloud,部署模式,大数据
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
If you work with big data, you’re likely familiar with Apache Hive, and the Hive Metastore, which has become the de facto standard for managing metadata in the big data ecosystem. Dataproc Metastore is a fully managed Apache Hive metastore (HMS) that runs on Google Cloud. Dataproc Metastore is highly available, autoheals, auto-scales, and is serverless. All of this helps you manage your data lake and metadata, and provides interoperability between various data processing engines and any tools that you’re using.
If you are in the process of migrating from an on-premises Hadoop environment with multiple Hive Metastores to Dataproc Metastore on Google Cloud, you may be seeking ways to effectively organize your Dataproc Metastores (DPMS). When designing a DPMS architecture, there are several important factors to consider: centralization vs. decentralization, single-region vs. multi-regions, and persistence vs. federation. These architectural decisions can significantly impact the scalability, resilience, and manageability of your metadata.
The blog post explores four DPMS deployment patterns:
-
A single centralized multi-regional DPMS
-
Centralized metadata federation with per-domain DPMS
-
Decentralized metadata federation with per-domain DPMS
-
Ephemeral metadata federation
Each of these patterns has its own advantages to help you determine the best fit for your organization’s needs. The designs are presented in increasing order of complexity and maturity, allowing you to choose the most suitable pattern based on your organization’s specific DPMS requirements and usage.
Note: In the context of this blog post, a domain refers to a business unit, department, or a functional area within your organization. Each domain may have its own specific requirements, data processing needs, and metadata management practices.
Let’s take a closer look at each of these patterns.
1. Centralized multi-regional Dataproc Metastore
This design is suitable for simpler use cases where you have a limited number of domains and can consolidate all metastores into a single multi-regional (MR) Dataproc Metastore.
In this design, a single multi-regional DPMS is deployed by consolidating all the metastores across the domains within a central shared project. This setup allows all domain projects within the organization to access metadata from this centralized DPMS. The primary objective of this design is to provide a straightforward and easy-to-manage solution for organizations with a limited number of domains and a relatively simple use case.
When you create a Dataproc Metastore service, you permanently set a geographic location for your service to reside in, otherwise known as a region. You can select either a single region or a multi-region. A multi-region is a large geographic area that contains two or more geographic places and provides higher availability. Multi-regional Dataproc Metastore services store your data in two different regions and use the two regions to run your workloads. For example, the multi-region nam7 contains the us-central1 and us-east4 regions.