
包阅导读总结
1.
关键词:LLMs、AIOps、Observability、Custom Queries、Data Communication
2.
总结:本文探讨了 LLMs 在 AIOps 中的应用,对比了语音助手与 LLMs 的差异,介绍了 Senser 利用 LLMs 实现自定义查询的两层解决方案、关键考虑因素、实施细节及未来发展方向,旨在为用户提供更优的数据查询体验。
3.
主要内容:
– 引言
– 提及阿兰·图灵关于发展能思考的机器的观点
– 指出 LLMs 是 AI 发展的新篇章,正处于应用阶段
– 对比
– 传统语音助手的局限性
– LLMs 能识别意图、跟踪对话上下文,交流更自然
– Senser 中的应用
– 是为用户构建新能力的机会,适用于解决自定义数据库查询挑战
– 两层解决方案
– 第一层:用户与 LLM 交互,LLM 引导用户补充细节
– 第二层:LLM 与数据库交互,需特殊训练
– 关键考虑因素:设计简单、成本优化、性能
– 实施细节:用户-LLM 交互和 LLM-数据库交互的具体方式
– 未来方向:增强聊天历史、细化用户交互、处理复杂查询、提升算法能力
– 结尾
– 强调提供高效查询体验,LLMs 使数据利用更便捷
思维导图:
文章地址:https://thenewstack.io/chatting-with-data-llms-are-transforming-aiops/
文章来源:thenewstack.io
作者:Avitan Gefen
发布时间:2024/8/20 19:17
语言:英文
总字数:1525字
预计阅读时间:7分钟
评分:86分
标签:大型语言模型,人工智能运维,自然语言处理,NoSQL 数据库,数据查询
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
In his 1950 paper “Computing Machinery and Intelligence,” Alan Turing famously said, “We can only see a short distance ahead, but we can see plenty there that needs to be done.” He referred to the challenge of developing “machines that can think.”
Decades later, we’ve made significant progress in the “plenty” that needs to be done, and we can see a short distance further. Large language models (LLMs) are the latest chapter in this story, garnering perhaps the most attention of any AI development so far. For the first time, the general public is directly interfacing with AI models in their daily lives, allowing more people to ideate around novel applications of this powerful technology.
Technological advancements often follow a two-phase journey: discovery and application. In the discovery phase, we explore and understand the technology. In the application phase, we use this understanding to solve real-world problems. With LLMs, we are now in this second phase. However, as we develop applications, it is crucial to maintain a practical approach. Instead of getting lost in speculative visions of AI, we should concentrate on realistic and attainable objectives. While it is inspiring to consider AI’s potential, genuine progress stems from effective solutions in real-world scenarios. By setting pragmatic goals, we can ensure that AI is impressive and genuinely helpful.
I’ve been thinking and writing about LLMs lately, not just because it’s a popular topic, but because the “short distance” we can see ahead is getting more straightforward for AI in observability. In my last blog, I teased two LLM use cases we’re building at Senser. This piece double-clicks on one of them: Chatting with data.
From Commands to Conversations: Voice Assistants vs. LLMs
In many ways, voice assistants like Apple’s Siri, Amazon’s Alexa, and Google Assistant have traditionally had their limitations. As a user, you are limited to a specific set of questions or commands that must be stated a certain way. Otherwise, the voice assistant issues some response like “Sorry, I am having trouble finding information on [topic] right now,” or worse, a twenty-second reply of random information you didn’t ask for. Don’t try correcting it — the voice assistant doesn’t consider past responses.
In contrast, LLMs can recognize the intent behind what you are trying to ask, even if you didn’t use the same words it was expecting. They can also keep track of the context within a conversation and allow you to modify a prompt or clarify a statement. These capabilities result in a much more natural and comfortable form of communication, better resembling how humans communicate with one another. No wonder the voice assistants are starting to implement LLMs!
Unlocking Potential: LLMs in AIOps at Senser
As an AIOps platform, Senser sees the introduction of LLMs as a valuable opportunity to build new capabilities for our users. LLMs are well-suited to solving the challenge of supporting custom database queries. Rather than creating a custom query for each new customer request, we can use AI, with the proper guardrails, to give our users more flexibility over how they interact with their observability data while ensuring they always receive the most relevant data related to API queries, workload, nodes, and more.
Typically, supporting custom database queries would require users to have a certain degree of proficiency in writing database queries, which is non-trivial for NoSQL databases that often have unique ways of organizing data. Query builders and templates can help, but they require hands-on support and can be restrictive or time-consuming.
Unfortunately, the solution is not as simple as bolting on an LLM to your NoSQL database and interacting with it in free text. It’s a bit more involved than that, but we’ll walk you through one simple, fast, and cost-effective solution.
The Two-Layered Solution: A Blueprint
When it comes to leveraging LLMs for custom queries in observability, there are two main layers to consider. Layer One is the interaction between the user and the LLM. Layer Two is the interaction between the LLM and the data. Both layers have high degrees of complexity.
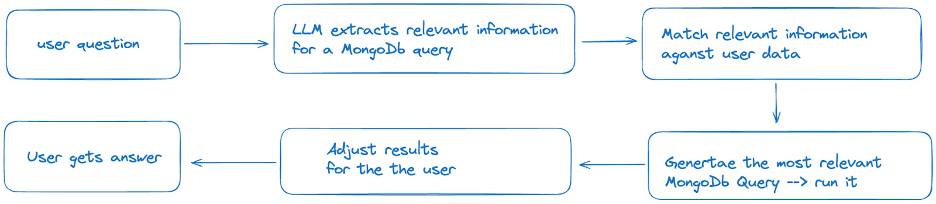
Layer One: User Chats With LLM
Consider this seemingly simple example query:
Which API has the highest number of errors?
This query needs a lot of context. We don’t know which protocol it’s referring to or which namespace, workload, cluster, time frame, or type of error is referenced. The absence of these details leads to the LLM making assumptions, something we want to avoid. The LLM prompts the user to fill in the necessary details to address this. For example, it might ask, “Which API protocol are you referring to?” or “Can you specify the time frame for this query?”
Layer Two: LLM Chat With Database
The interaction between the LLM and the data requires a nuanced understanding of how NoSQL databases and LLMs work. Because NoSQL databases have no predefined structure, they cannot be easily queried by someone who doesn’t know the database structure. Therefore, a generic LLM is not ready out-of-the-box for this task. Special training is needed to mediate effectively between the user and the data. This training involves teaching the LLM how to interpret and translate user queries into database-specific queries.
Key Considerations
When we set out to build an effective custom query engine at Senser, we started by identifying several key considerations:
- Simplicity in Design: More complex designs can lead to performance and reliability issues. Our goal was to keep the engineering design simple and robust.
- Cost Optimization: The solution needed to be affordable, which mostly entailed avoiding designs that resulted in excessive querying of commercial LLMs.
- Performance: Fast response times were critical. We optimized our solution to ensure quick query processing and maintained a history of previous queries to avoid “already solved” user questions in Layer One. Hallucinations must be avoided by ensuring the user’s question is translated into a valid NoSQL database query.
Bringing It to Life: Implementation Details
To illustrate the practical aspects, let’s dive deeper into the implementation:
Layer One: User-LLM Interaction
The user interacts with a Senser chat feature that provides directions and guidelines for the LLM. If the query has already been answered, the chat returns the answer without consulting the LLM. The LLM extracts relevant information for new queries to generate an accurate response based on the guidelines provided. This includes the time frame, entity name (cluster, namespace, workload, pods, etc.), metric or field, aggregation operation (mean, median, max, min, threshold, limits, etc.), and metadata. If the query is incomplete, the LLM prompts the user for additional information. For instance, if the time frame is missing, the LLM might ask, “Please specify the time frame for your query.” If the user submits an invalid prompt, such as a simple “Hello”, the LLM politely answers, but it can also “block” certain types of general information asked aimed at hacking the system. The only answers containing any substance are those that directly answer approved database queries.
Layer Two: LLM-Database Interaction
Under the hood, Senser developed several chosen generators based on the query’s extracted information. These generators convert the user’s intent into database-specific queries. The query is then run, and the results are parsed into a human-readable format and displayed in a table.
One challenge we faced was dealing with time frame calculations. We wanted to use the UNIX time format, a standard way to represent time in a database. However, the LLM was limited in accurate mathematical calculations for UNIX times. To overcome this, we asked the LLM to provide the difference in [days, hours, minutes] from the current time. We then converted these components into the UNIX standard format.
Charting the Future: The Short Distance Further
There are several logical directions we could take from here:
- Enhanced Chat History: We plan to enhance the model’s chat history to enable the LLM to ask more sophisticated follow-up questions. For example, if a user queries a metric over the past five days and wants the same metric for the last ten minutes, the model should remember the previous query details and adjust the time frame accordingly.
- Granular User Interaction: Users should be able to ask about specific APIs in particular directions or given interactions on specific endpoints.
- Complex Queries: Allowing more complicated queries that involve multiple metrics or datasets could provide better insights.
- Algorithmic Capabilities: The Senser chat-based application, which operates with the LLM, could suggest interesting interactions between variables or predict when a specific metric will exceed a threshold based on the extracted data.
Approachable AIOps
We aim to provide our users with a seamless and efficient querying experience by addressing these challenges and continuously improving our implementation. Our approach simplifies interacting with NoSQL databases and leverages the power of LLMs to make observability data more accessible and actionable.
Just as Alan Turing envisioned a future with thinking machines, we now realize that vision, step by step, as LLMs bring us closer to understanding and utilizing our data in unprecedented ways. The distance ahead is getting more evident, and the journey promises exciting developments for AI and observability.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.