
包阅导读总结
1.
关键词:DevOps、Platform Engineering、Allianz Direct、Software Development、Transformation
2.
总结:本文讲述了 Allianz Direct 公司的 DevOps 团队向平台工程团队转型的历程,包括面临的问题、采取的措施、构建的平台及衡量其影响的方式,强调了清晰任务、控制工作积压、多方合作等的重要性。
3.
主要内容:
– 背景与问题
– 许多 DevOps 工程师岗位转变为平台工程师,但多数仅名称变化,DevOps 关注运营,平台工程侧重开发者体验。
– Petean 加入 Allianz 时团队存在问题,如“假 SRE 拓扑”,Dev 与 SRE 协作不佳,软件可观测性差。
– 转型措施
– 考虑所有利益相关者,定义 DevOps 原则。
– 明确团队任务和挑战,决定构建自服务平台,控制工作积压。
– 与安全和软件工程师等利益相关者合作,修复 CI/CD 管道。
– 建立自服务内部开发者平台,迁移 CI/CD 管道,采用云原生技术。
– 衡量影响
– 证明技术能力,理解新决策框架和角色。
– 工程部门重组,中央 DevOps 团队负责 DevSecOps 和软件发布周期。
– 采用 DORA 指标衡量影响,设定新目标和关键结果,软件发布流程表现优异。
思维导图: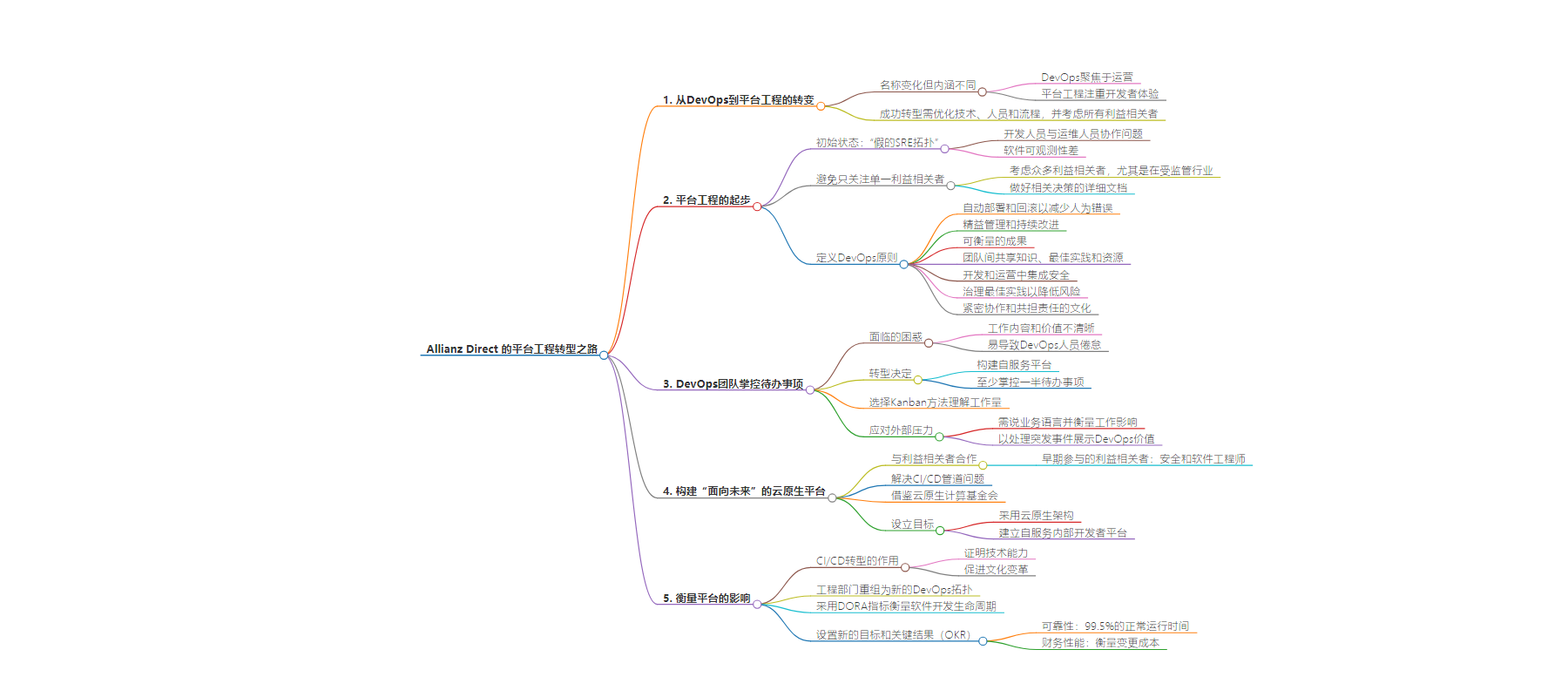
文章地址:https://thenewstack.io/how-a-devops-team-became-a-platform-engineering-team/
文章来源:thenewstack.io
作者:Jennifer Riggins
发布时间:2024/8/16 14:54
语言:英文
总字数:2575字
预计阅读时间:11分钟
评分:88分
标签:平台工程,DevOps 转型,云原生,CI/CD,Allianz Direct
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
The last couple of years have seen a lot of job titles updated from DevOps engineer to platform engineer.
For most, it’s been a change in name only. It wasn’t a natural substitution anyway, since DevOps focuses on operations, while platform engineering centers on developer experience. A successful DevOps or platform engineering transformation will optimize technology, people and processes on both sides of that persistent silo. It will also consider all the other stakeholders in the increasingly complex software development life cycle.
That’s exactly what Allianz Direct, an international insurance company, sought to do when it set off on its journey of a DevOps team toward platform engineering. Sergiu Petean, as director of cloud engineering and operations, shared this story of scale on a recent episode of the Platformers Community livestream.
Getting Started with Platform Engineering
When Petean joined Allianz in 2021, he found his team in what he dubbed “a state of fake SRE topology,” referencing an anti-pattern from “Team Topologies,” which has operations engineers dubbing themselves site reliability engineers without making changes.
“Devs still throw software that is only ‘feature-complete’ over the wall to SREs,” he said. “Software observability suffers because devs are no closer to actually running the software that they build, and the SREs [site reliability engineers] still don’t have time to engage with devs to fix problems when they arise.”
This isn’t an uncommon place to start, but companies must be careful not to get stuck there.
Petean also wanted to avoid another platform engineering anti-pattern that only looks to address a single stakeholder — the software engineer.
“In a huge enterprise, you have to consider as many stakeholders as possible, ideally all stakeholders that have anything to say about your production status,” he said, particularly in such a regulated industry. You also need thorough documentation that represents the decisions of each of those stakeholders.
Once everyone was considered, it was time to define DevOps for Petean’s new team and the organization as a whole. Building on Google’s DevOps definition, Allianz Direct’s DevOps principles are grounded in:
- Automated deployments and rollbacks to reduce human error.
- Lean management and continuous improvement.
- Measurable outcomes.
- Sharing knowledge, best practices and resources among teams.
- Security integrated within development and operations.
- Governance best practices that reduce risk.
- A culture of closer collaboration and shared responsibility.
It took the DevOps team a couple of months to clarify and collect all the tasks, stories and epics among these stakeholders and to reflect on its current challenges.
Why DevOps Must Own the Backlog
“It was extremely confusing for anyone in our organization to know what we were doing,” Petean said.
“Sometimes, even for us, it was quite challenging to understand: What are we working on? Why are we working? What’s the value that we are bringing to the overall organization?” he added. “How is that going to evolve together with the whole stack in the next six months?”
This is why DevOps burnout is exceedingly common.
“The life of a DevOps [team] is not easy, especially when you have a lot of incidents, technical debt, technical questions, so you don’t know much of your backlog,” Petean said.
Which is when his team decided “we actually want to build a platform, and we want that platform to be self-service,” turning the DevOps team into an internal product and platform engineering team.
“In order to do that,” he said, “we needed to own at least half of the backlog.”
The DevOps team originally wanted to do Scrum, but since it didn’t own the engineering organization’s backlog, it couldn’t set its own sprint goals. Instead Petean and his DevOps engineers went the Kanban route. This allowed them to better understand their workload, which enabled them to understand how big the team needed to be to cope with that pressure.
Controlling the backlog was also the only way he felt the team could drive automation, security and DevOps concepts into their processes.
In the modern multinational corporation, there are countless stakeholders outside your team influencing your work. Inevitably this team’s demand was met with resistance.
“If you’re a digital company, basically every part of your organization could be or should be stakeholders for platform engineering.”
— Sergiu Petean, Allianz Direct
“You have pressure from everywhere, and that’s why it’s very important to start speaking the business language,” Petean said. “And that’s why you need to measure the impact of your work.”
Start raising it as a lost opportunity, he advised, because, without ownership of the backlog, his team couldn’t prioritize features nor address and prevent incidents as quickly. And then, once you get that budget for more full-time DevOps engineers, you have to measurably show the impact of it.
During those exploratory first months, the DevOps team started getting noticed around the handling of incidents, which highlighted several DevOps touch points, like automation, logging and documentation.
“We always use these emergencies to show the value of DevOps — at least DevOps the way we envision it,” Petean said. “That’s how we built a vision and sold it to other stakeholders.”
Building a ‘Future-Proof’ Cloud Native Platform
“The only way we can build a product that is going to be future-proof, is to build it together with our stakeholders,” Petean said.
The first stakeholders his team engaged were security and the software engineers. Early on, the DevOps team took on the role of advocate for the needs of these two stakeholders and for the principles of DevOps.
An immediate demand was to fix the CI/CD pipeline, an apparent barrier to developer productivity that also triggered a lot of incidents.
Faced with this complexity, the Allianz DevOps team chose to look to the Cloud Native Computing Foundation, to learn from other teams how to build a platform as a product and how to build a cloud native stack. Petean also heads the CNCF’s technical advisory working group on reference architectures.
“The group standards are simply unbeatable,” Petean said. The newly formed DevOps platform team set the six-month goal of adopting cloud native architecture across infrastructure, containerization, orchestration, storage and caching by default.
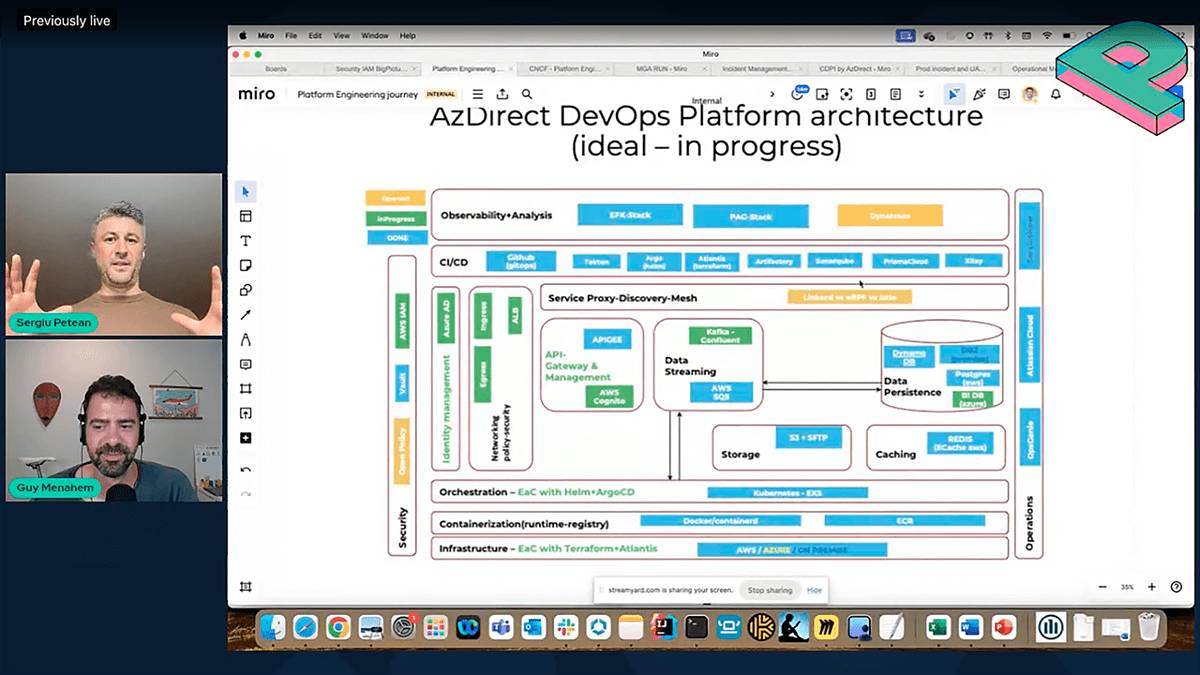
Allianz Direct’s “ideal state in six months” is to achieve a DevOps platform architecture. This snapshot shows what at the time of recording was open, in progress and done.
The team also established that, to reach the necessary multinational scale, it needed a self-service internal developer platform, in part, Petean said, “because of how scarce the DevOps resources are.
The goal became to “enable teams to deploy, monitor and maintain their own production environments,” he added. Otherwise, “there is no way that we could scale at the same speed as the organization.”
At this time, the Allianz Direct product was launching into a new market with microservices deployed in different environments. This newly formed central DevOps platform team decided it was the right moment to migrate the frustration-sparking, existing CI/CD pipeline to Argo CD. The team redesigned the whole CI/CD stack in three months, as the first deliverable of this newly central DevOps platform team.
“We had more than 200 GUI jobs that no one was touching that had so many owners in the past, and it was very slow and was very complicated. It was a nightmare,” he said, which caused a lot of duplication.
In three months, his team migrated about half the batches and depreciated the other half. Then they adopted a fully cloud native stack with quality gates, Terraform automation and more.
Measuring the Platform’s Impact
This CI/CD transformation was a way to not only prove what the new DevOps platform team could technically build. It also helped everyone understand the new decision process framework and roles.
“The DevOps cultural change was visible and further supported by management and developers,” Petean said.
During the first three months of this platform transformation, the Allianz Direct engineering division was also reorganized into a new DevOps topology:
- Development, including engineering, quality analysts and database administrators.
- Operations, including security and this newly reformed central DevOps team.
The central DevOps team became responsible for both DevSecOps and the software release cycle. This team, Petean said, was able to boost software delivery performance by designing a modern software release stack. This also enabled the software engineers to adopt core DevOps practices, including:
Once it launched the new CI/CD pipeline, in 2022, the platform team chose Google’s DORA metrics — deployment frequency, lead time for changes, change failure rate and failed delivery recovery time (previously called mean time to recovery, or MTTR) — to measure the impact on the software development life cycle. As the DevOps platform now owned the full stack, it was easy to track these numbers.
Within six months the Allianz Direct software release process scored among the top 11% of all companies in terms of speed and quality.
The DevOps platform team also set new objectives and key results, or OKRs for the entire tech organization for primary applications and services, which included those four core DORA metrics, plus:
- Reliability: 99.5% uptime
- Financial performance: measuring the cost of change. In 2022, this was about $53 per change.
“We’ve evolved DORA metrics into a continuous improvement software delivery framework for the whole organization,” Petean said.
“We look at all the teams, and we compare and we see different patterns of software release on one single screen. Teams can zoom in on their work and look at all the versions and look if there was a feature request, a bug fix or anything else. It’s allowing them to take ownership over their speed of delivery and quality.”
They can also see how they compare with other teams, especially those with similar metrics and/or programming languages.
“We already had an impact at the team level,” Petean said, and “we started having impact at the engineering level.”
Shifting Security Left
Next the team worked to introduce the concept of continuous security, building DevSecOps onto the new CI/CD pipelines.
“We started looking into vulnerabilities, and we got a lot of noise,” Petean said, because “you cannot shift left with noise, which means you have to build security intelligence in-house.”
Together with the CISO and an external consultancy, the DevOps platform team was able to reduce vulnerabilities and unnecessary pings, he said, going from around 50,000 to less than 120 essential vulnerabilities. This translated to about five or six priority vulnerabilities per engineering team to worry about.
A new SRE culture emerged, which demanded new incident management, alerting and observability tooling.
The DevOps platform built a library of all the services, owners and roles, mapping out the whole software organization. This offered transparency into which team is responsible for which alert, and even who on that team — usually whoever last deployed it — should be pinged first.
“Then we deleted more than 50% of existing alerts because they were simply noise,” Petean said. “If you don’t have a runbook behind an alert and you don’t know how to react and it doesn’t have an owner, you delete it.”
The DevOps platform team was able to reduce vulnerabilities and unnecessary pings, he said, going from around 50,000 to less than 120 essential vulnerabilities. This translated to about five or six priority vulnerabilities per engineering team to worry about.
The DevOps platform team did this over about eight months, transferring or deprecating about 10% of alerts at a time. That one team observed and reacted to all the alerts for some time before distributing to the respective dev teams.
This resulted in another shift in the shape of the organization toward that federated SRE topology or SRE as a service — where teams maintain a sense of autonomy and ownership over security. The DevOps platform team could now focus on operational performance and reliability, and a new SRE team was formed to redesign the observability stack.
Identifying SLIs for All Stakeholders
Then it was time to achieve what Petean called OrgOps or organizational operation.
“Because if you’re a digital company,” he explained, “basically every part of your organization could be or should be stakeholders for platform engineering.”
His team identified eight target stakeholders and their respective service-level indicators (SLIs):
- Users: availability, correctness, latency.
- Quality: defects, error logs, coverage.
- Security: certifications, vulnerabilities.
- Delivery: CI/CD availability, performance.
- Data: compliance, correctness.
- Sustainability: efficiency, occupancy.
- Incident management: MTTR, incidents open.
- Compliance: open source software.
Business is closest to the end users, but also, as a highly regulated insurance company, compliance is another essential stakeholder.
“GitOps is the best thing you can have to make compliance happen,” Petean added.
The linchpins of all platform engineering strategy — automation and self-service — were then codified within working agreements with these stakeholders.
They democratized observability, Petean said. Each engineering team elected a representative to spend 20% of their time on operational concerns, acting as the voice for their team.
“We have the vision to have a self-service platform. So we made a big step toward empowering software engineers to do more than just consuming the service,” he said. “Now they could already create their own pipelines, extend the pipelines, create secrets, create [service-level objectives], create alerts, dashboards, and so on and so forth.”
In less than six months, the organization ended up with 210 SLOs, or service-level objectives. Some were global, like that every API should respond within five seconds. Others were customized for different teams and services. Every time an SLO budget runs out, the relevant teams are alerted.
OrgOps to Scale the Platform
As the program expanded, so did the organization, growing from about 200 employees to more than 1,500 employees, a third of which were engineers. The number of stakeholders, SLIs and SLOs also grew, while the DevOps platform team remained the same.
“Platform engineering is something that you have to treat holistically, and that means that every single change you have in one part of your platform will have an impact on other parts,” Petean said.
The organization adopted what “Team Topologies” calls the Reverse or Inverse Conway Maneuver. Conway’s Law contends that an organization will naturally build technology in a way that reflects communication structures. This inverse, as Petean explained, has platform engineering building cross-functional teams around the tech stack in order to include all stakeholders in the software release process.
Petean calls this approach to platform engineering “OrgOps,” where SREs have the foundation to move teams toward federated DevOps — “You build it, you run it.” — and the new stakeholders — like quality, compliance, data — are able to set data-driven agreements.
This OrgOps topology has the whole company working together to surface previously unseen levels of organizational performance.
Allianz Direct is now moving into what Petean calls the “Age of Platforms.”
“Once you have a platform engineering team in place that builds a cool platform,” he said, you have built a “bedrock” to serve different business needs across an org.
The DevOps platform team has already built a second, multitenant platform to consider internal customers that have stateless jobs, databases and legacy architecture.
The same DevOps platform engineering team now is in charge of two platforms for new stakeholders with different needs.
But, as Petean predicted, as the company continues to grow, “We are going to have to evolve again to keep up.”
Check out his full presentation to learn more about Allianz Direct’s platform engineering journey:
VIDEO
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.