包阅导读总结
1. `MySQL`、`版本`、`崩溃`、`BUG`、`测试`
2. MySQL 8.038、8.4.1、9.0 版本存在大 BUG,表数量超 10000 张会系统崩溃重启。某云厂商成员报告问题,提醒开源数据库使用方不要急于升级,稳定性最重要。
3.
– MySQL 新版本存在问题
– 8.038、8.4.1、9.0 均有 BUG
– 表数量超 10000 张会系统崩溃重启
– 发现问题及质问
– 某国内云厂商内核开发质问甲骨文未测试就推新版本
– 提醒与建议
– 开源数据库上新 1 年后再计划升级版本
– 强调稳定性重要
– 相关案例
– POSTGRESQL 14 版本初期在线添加索引导致丢失数据
– 某云厂商成员报告
– 指出未完全测试的严重问题及原因
– 对相关函数设计合理性提出质疑
思维导图: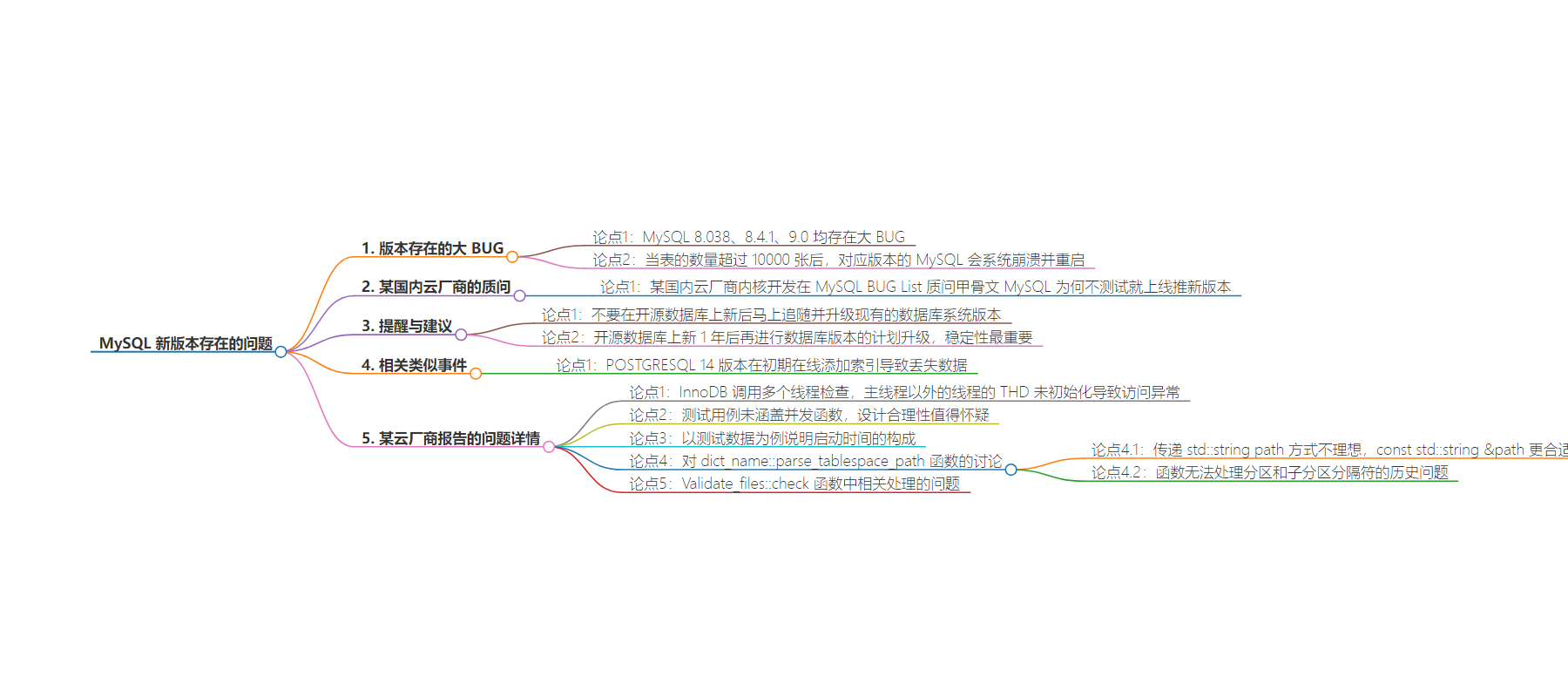
文章地址:https://mp.weixin.qq.com/s/LcSW19BBYwhCpl_OMNJUmA
文章来源:mp.weixin.qq.com
作者:dbaplus社群
发布时间:2024/7/29 10:23
语言:中文
总字数:1352字
预计阅读时间:6分钟
评分:85分
标签:MySQL,数据库管理,数据库稳定性,版本升级,系统崩溃
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
最近看一些友人都在发MySQL9的新功能,很想查查有什么新鲜的东西,但不查不要紧,一查吓一跳。MySQL 8.038 ,8.4.1, 9.0 均存在大BUG,并挖出大瓜,某国内云厂商内核开发在MYSQL BUG List 质问甲骨文MYSQL,为什么这么简单的问题连测试都不测试就上线推新版本。
根据Percona的BLOG中的文章显示,当前他们发现MYSQL 8.037后面的版本均存在BUG,当表的数量超过 10000 张后,对应版本的MYSQL会系统崩溃,并进行重启。当前发现的 8.038, 8.4.1, 9.0 均存在此问题。

这再次提醒使用开源数据库的公司和人员,不要在开源数据库上新后,就马上进行追随,升级现有的数据库系统的版本,具体稳妥的方式为,在开源数据库上新1年后,在进行数据库版本的计划的升级。终究数据库升级不是儿戏,也不是越新越好,稳定性才是最重要。
其他开源数据库也发生过类似的一些事情,如POSTGRESQL 14版本在初期在线添加索引,导致丢失数据的问题等。
更多具体的信息参见:https://perconadev.atlassian.net/browse/PS-9306
另某云厂商 RDS 核心团队的成员 Huaxiong Song,报告了此次问题给MYSQL官方,具体的翻译内容如下
我从 Percona 的博客中了解到了 bug#115517,这是一个严重的问题,尚未完全经过测试。实际上,这个 bug 的原因非常简单:当数字超过 8000 时,InnoDB 会调用多个线程进行检查,而主线程以外的线程的 THD 未初始化,导致在 commit#28eb1ff 引入的修复中对 DD 的访问异常。
但我想谈谈其他问题。
这是一个并发函数,但测试用例并未涵盖它。这种设计的合理性值得怀疑。我对 MySQL InnoDB 大型表的启动进行了大量测试和研究。获取 DD 信息并不是一项非常快速的行为。以我的测试数据为例:100 万个表(sysbench 构建),正常关闭和重新启动,启动时间如下:Tablespace_dirs::scan() – 44.4 秒 fetch_global_components(&tablespaces) – 25.5 秒 validate(tablespaces) – 15.8 秒 总计 – 90.7 秒 我们可以发现,fetch_global_components(&tablespaces) 占据了启动时间的 28%,而这个函数是用来读取 DD::tablespace 表并构建 DD::tablespace 对象的。
在引入 commit#28eb1ff 后,忽略 bug#115517,我们可以假设除了获取所有表空间外,还需要获取所有 DD::table。与获取 DD::tablespace 不同,获取 DD::table 将更耗资源,因为每次获取都需要构建和销毁 Auto_releaser 对象。(尽管引入了多线程,我认为问题仍然存在)。对于函数 dict_name::parse_tablespace_path,我认为这个函数值得单独讨论:3.1 我认为将 std::string path 传递给函数并不理想。我认为 const std::string &path 更为合适。3.2 函数中使用了 SUB_PART_SEPARATOR 和 PART_SEPARATOR,但由于历史原因,分区和子分区的分隔符也可能是 #P# 和 #SP#。显然,这个函数无法处理这个问题。让我们回到 Validate_files::check 函数。在 parse_tablespace_path 之后,实际上调用了 fil_update_partition_name 来处理我上面提到的分区分隔符问题。因此,dict_name::parse_tablespace_path 的设计和使用并不完全合理。