
包阅导读总结
1. 分词器、BPE 算法、代码补全、自然语言处理、token
2. 本文介绍了分词器的实现,包括其在自然语言处理和代码补全中的应用,阐述了 BPE 算法原理,详细说明了自定义分词器的实现过程及核心步骤。
3.
– 什么是分词器
– 是自然语言处理的重要部分,能把文本转换为 token
– 在基于 Transformer 的大语言模型中很重要
– OpenAI 有测试页面展示文本拆分 token
– 分词器在代码补全领域的应用
– 以 Copilot 插件为例,介绍其工作原理
– 编码器是核心功能模块,计算 token 数量,避免超阈值
– BPE 算法
– 训练过程包括构建词汇表、转换 token、合并字节对等
– 最终产生词表文件和 BPE 文件
– 为什么不直接使用社区中的分词器
– 每个模型词表文件不同,可能导致分词结果不准确
– 实现分词器
– 核心是使用 BPE 算法合并字符对
– 涉及函数如 dictZip、get_char_pairs、mutatingConcat 等
– 详细说明了分词器的处理过程及缓存机制
思维导图: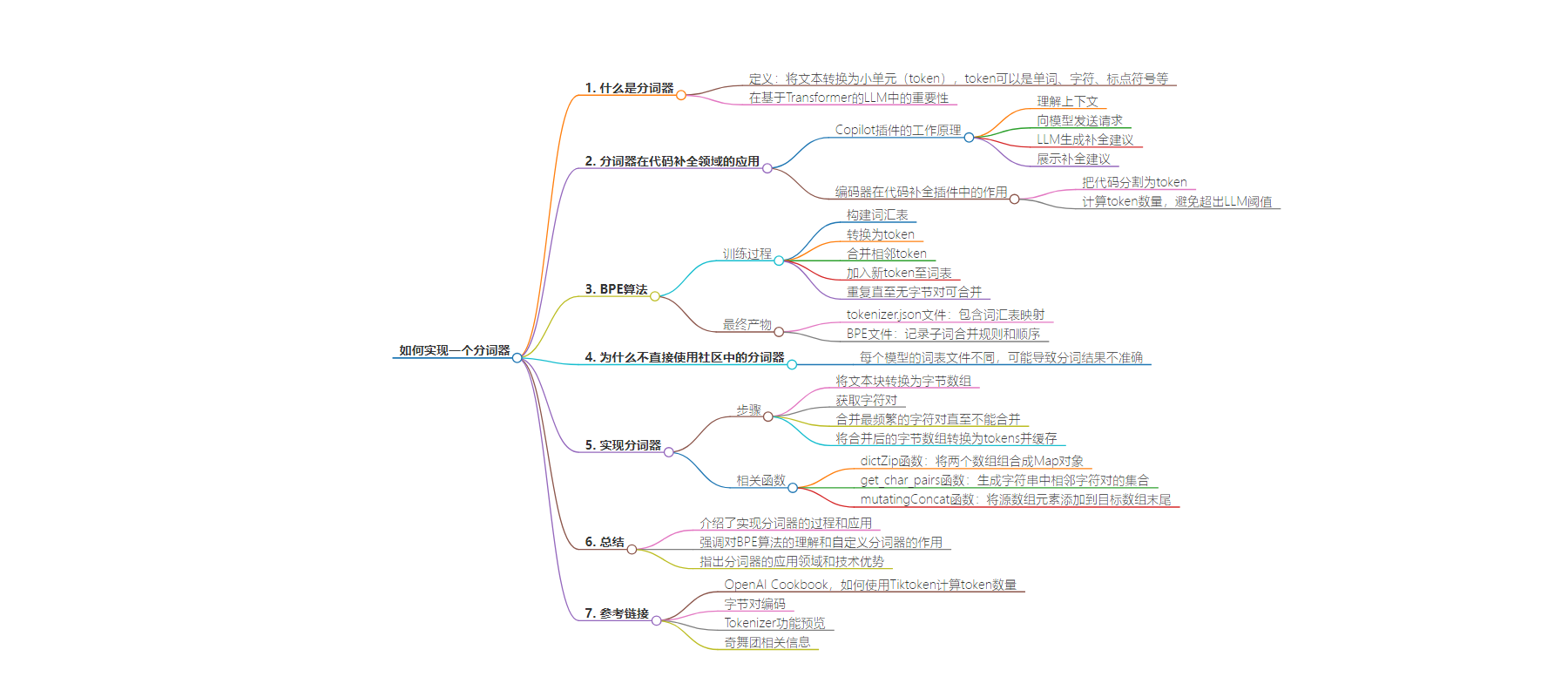
文章地址:https://mp.weixin.qq.com/s/OCgkOaJAgHymNovlKYQmGg
文章来源:mp.weixin.qq.com
作者:宁航
发布时间:2024/7/29 9:58
语言:中文
总字数:4631字
预计阅读时间:19分钟
评分:89分
标签:分词器,NLP,BPE算法,代码补全,自然语言处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
如何实现一个分词器
在开发代码补全插件的过程中,根据项目需要,我实现了一个分词器,本文将介绍分词器的具体实现细节。
一、什么是分词器?
分词器是 NLP(natural language processing,自然语言处理)领域的一个重要部分,它可以把一段文本转换为小的单元,称为 token 。token可以是单词、字符、标点符号等。在基于 Transformer 的 LLM (Large Language Model,大语言模型)中,如 BERT 或 GPT 等,分词器扮演着更重要的角色。大模型通过不断学习来发现 token 之间的联系,从而能够预测下一个 token,实现与人类对话的效果。
OpenAI官方提供了一个测试页面,来帮助我们理解一段文本会怎样被拆分为一系列 token ,访问该链接即可查看相关内容。计算一段文本会被拆分为多少个 token 非常重要,因为模型能够一次能够读取的 token 数量是有限的。
二、分词器在代码补全领域的应用
代码补全是 LLM 的一个应用场景,在编辑器中安装 Copilot 插件后,在编写代码时,就能自动获取实时的补全建议,提高开发速度。Copilot插件的工作原理如下:
(1)理解上下文:当开发者编写代码的时候,Copilot 会持续地分析当前的上下文,包括当前正在输入的代码、注释、和文件中的其他代码。同时,还会分析项目整体结构和用到的库。
(2)向模型发送请求: 基于当前上下文,Copilot 会给 LLM 发送一个请求。该请求会包含相关的代码上下文,例如:光标前的代码、光标后的代码、函数名称和注释等。
(3)LLM 生成补全建议: LLM 收到请求信息后,基于它从大量公共代码库学到的知识和当前项目的具体上下文信息,生成多个代码建议。
(4)展示补全建议:Copilot 会把多个代码建议显示到编辑器中,开发者可以采纳、拒绝或修改补全代码。
在代码补全插件中,编码器是一个核心的功能模块,它会把代码分割为token,包括:关键词、运算符、单词、标点符号、空格等。假设我们输入一行代码:
letname='julian'
编码器会把代码拆分为几个独立部分:
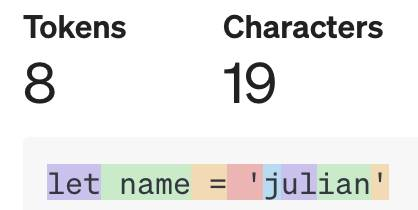
再把每个部分进行编码,具体结果为:
[1169,836,284,364,73,360,1122,6]
由上图可以看出,分词器能够计算出每段代码的token数量,在向LLM发送请求前,Copilot会先检查当前 Prompt 的token数量是否超过了 LLM 的阈值,如果超出,就需要对 Prompt 进行截取,避免由于 token 超出指定范围而导致代码补全失败。因此,分词器的作用不言而喻,如果不能精确的计算token数量,会影响开发者的使用体验。
三、BPE算法
目前主流的 LLM 都基于 BPE算法(Byte-Pair Encoding,字节对编码)来实现分词器,如 OpenAI 的 GPT 模型。
BPE 算法训练过程
(1)从语料库中获取用于编写所有单词的符号来构建词汇表,每个符号即为一个token,假设我们的语料库是一个字符串man woman,那么我们就可以得到一个词汇表:
consttext='manwoman'
consttokens={
'':0,
'a':1,
'm':3,
'n':4,
'o':5,
'w':6,
}
(2)把text转换为token:
consttokenized_text=[
'm','a','n','','w','o','m','a','n'
]
(3)把每两个相邻的token进行合并,计算每个字节对出现的次数;
(4)把出现次数最多的字节作为一个新的token加入词表;
(5)重复上述过程,直到没有字节对可以合并。
具体的字节对合并过程如下:
(a)第1次合并
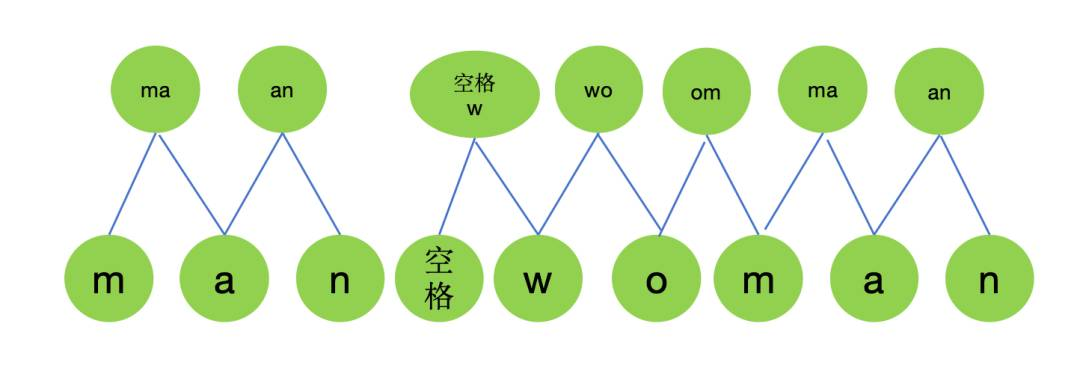
mergeObj={
'ma':2,
'an':2,
'w':1,
'wo':1,
'om':1,
}
//将'm'和'a'进行合并,作为新的token
tokens={
'':0,
'a':1,
'm':2,
'n':3,
'o':4,
'w':5,
'ma':6
}
//重新把text转为token
tokenized_text=[
'ma','n','','w','o','ma','n'
]
(b)第2次合并
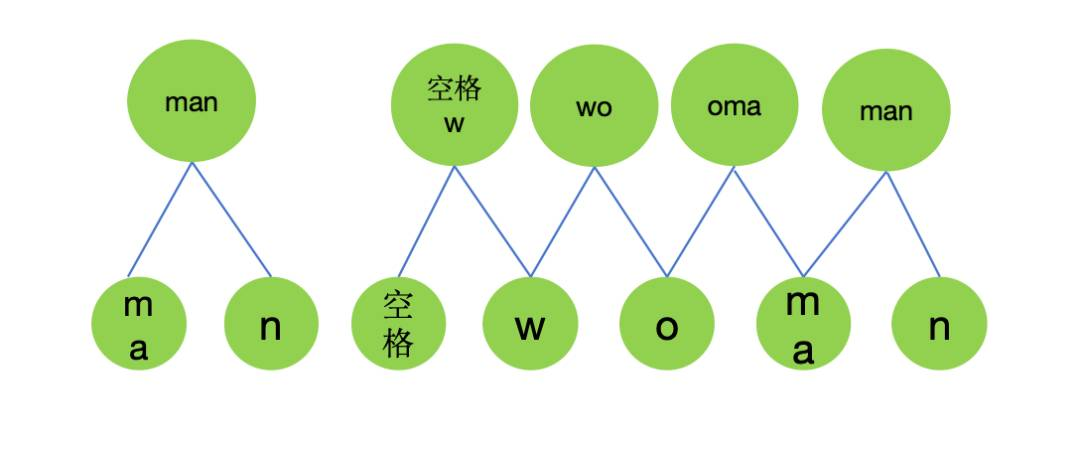
mergeObj={
'man':2,
'w':1,
'wo':1,
'oma':1,
}
//将'ma'和'n'进行合并,作为新的token
tokens={
'':0,
'a':1,
'm':2,
'n':3,
'o':4,
'w':5,
'ma':6,
'man':7
}
//重新把text转为token
tokenized_text=[
'man','','w','o','man'
]
(c)第3次合并
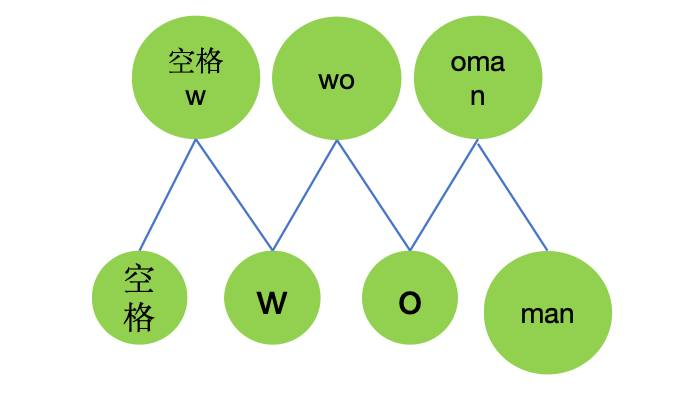
mergeObj={
'w':1,
'wo':1,
'oman':1,
}
//将'w'和'o'进行合并,作为新的token
tokens={
'':0,
'a':1,
'm':2,
'n':3,
'o':4,
'w':5,
'ma':6,
'man':7,
'wo':8
}
//重新把text转为token
tokenized_text=[
'man','','wo','man'
]
(d)第4次合并
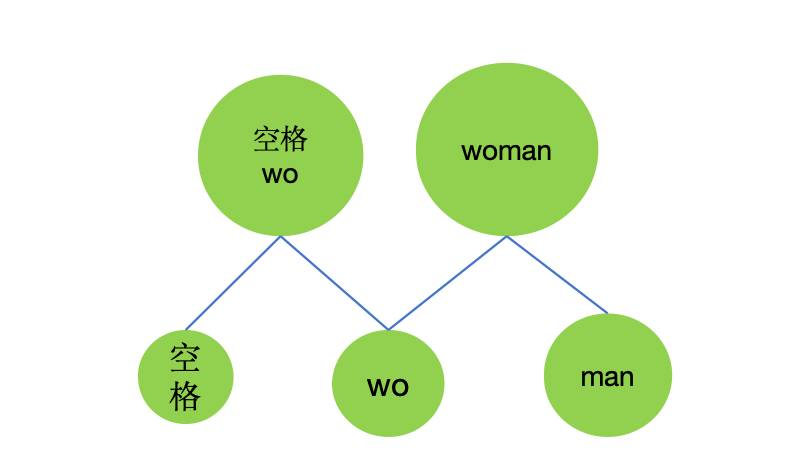
mergeObj={
'wo':1,
'woman':1,
}
//将'wo'和'man'进行合并,作为新的token
tokens={
'':0,
'a':1,
'm':2,
'n':3,
'o':4,
'w':5,
'ma':6,
'man':7,
'wo':8,
'woman':9
}
//重新把text转为token
tokenized_text=[
'man','','woman'
]
最终,会产生一个词表文件tokenizer.json和一个BPE文件。tokenizer.json文件会包含完整的词汇表映射,即每个token(词或子词)到其唯一ID的对应关系。BPE文件记录了子词的合并规则和顺序,模型在需要对新文本进行分词时会根据这些规则进行处理。
//tokenizer.json文件
{
'':0,
'a':1,
'm':2,
'n':3,
'o':4,
'w':5,
'ma':6,
'man':7,
'wo':8,
'woman':9
}
//BPE文件
ma
man
wo
woman
四、为什么不直接使用社区中的分词器?
当我们向分词器中输入一段文本后,分词器会读取tokenizer.json文件和BPE文件,对文本进行编码。假设我们输入man woman后,分词器会把该文本编码为[7, 0, 9]。由于每个模型经过训练产生的词表文件不同,如果直接使用社区中的分词器,可能导致分词结果不准确。因此,很有必要基于当前模型产生的tokenizer.json文件和BPE文件,来实现一个分词器。
五、实现分词器
将文本块转换为字节数组,这是编码的第一步,例如,将字符串 “let” 转换为字节数组 [ ‘l’, ‘e’, ‘t’ ]。然后,获取字符对,即文本中相邻字符的组合,如上述字节数组会得到 [ [‘l’, ‘e’], [‘e’, ‘t’] ]。
如果没有字符对(通常是输入文本长度为1),则直接返回编码后的字节。否则,进入一个循环,不断合并最频繁的字符对,直到不能再合并为止。这是BPE算法的核心,通过合并频繁出现的字符对来减少文本的长度。在每次循环中,找出当前最频繁的字符对,并将它们合并。合并后,更新字节数组并继续下一轮合并,直到字节数组长度为1或没有更多字符对可以合并。
最后,将合并后的字节数组转换为tokens,并将结果缓存,这样相同的输入在下次处理时可以直接从缓存中获取结果,提高效率。通过这些步骤,分词器能够高效地处理文本块,将其转换为tokens,同时利用缓存避免重复计算。
vocab.bpe: 记录字符合并的顺序。
tokenizer.json: 包含编码的映射关系。
(1)dictZip函数的作用是将两个数组x和y组合成一个Map对象。对于每个索引i,x数组中的元素将作为键,y数组中相应的元素将作为值。这样,每个x中的元素都会与y中相应位置的元素配对,形成键值对。最终,函数返回这个包含了所有键值对的Map对象。
constdictZip=(x,y)=>{
letresult=newMap();
x.forEach((_,i)=>{
result.set(x[i],y[i]);
});
returnresult;
};
(2)get_char_pairs函数的作用是接收一个字符串作为参数,然后生成并返回一个包含该字符串中所有相邻字符对的集合。
functionget_char_pairs(word){
//初始化一个空的Set用于存储字符对
letpairs=newSet(),
prev_char=word[0];//存储前一个字符,初始为单词的第一个字符
for(leti=1;i<word.length;i++){//从第二个字符开始遍历单词
letchar=word[i];//当前字符
pairs.add([prev_char,char]),(prev_char=char);//将前一个字符和当前字符组成的对添加到集合中,并更新前一个字符
}
returnpairs;//返回包含所有字符对的集合
}
(3)mutatingConcat可以将源数组(src)的元素添加到目标数组(dest)的末尾,并返回修改后的目标数组。
functionmutatingConcat(dest,src){
for(leti=0;i<src.length;i++)dest.push(src[i]);
returndest;
}
//读取"tokenizer.json"文件并解析其内容
letencoder_text=fs.readFileSync(path.resolve(__dirname,"tokenizer.json"));
letencoder_json=JSON.parse(encoder_text.toString());
//读取"vocab.bpe"文件
letbpe_file=fs.readFileSync(path.resolve(__dirname,"vocab.bpe"),"utf-8");
//把编码文件中的内容存入Map中
//encoder={
//"A":32,
//"B":33,
//"C":34,
//"D":35,
//}
this.encoder=newMap(Object.entries(encoder_json));
//创建decoderMap,通过交换encoder的键和值来实现
//decoder={
//'32':'A',
//'33':'B',
//'34':'C',
//'35':'D'
//}
for(let[key,value]ofthis.encoder){
this.decoder.set(value,key);
}
//将 bpe_file 按行拆分,过滤掉空行,得到 bpe_merges。
//使用 dictZip 函数将 bpe_merges 和其索引创建一个字典 bpe_ranks。
//如{
//'ĠĠ'=>0,
//'Ġt'=>1,
//'Ġa'=>2,
//'in'=>3,
//}
letbpe_merges=bpe_file
.split(/\r?\n/)
.slice(1)
.filter((l)=>l.trim().length>0);
this.bpe_ranks=dictZip(bpe_merges,range(0,bpe_merges.length));
-
分词器的核心是使用BPE算法不断合并出现最频繁的字符对,将输入的文本块转换为tokens,具体过程如下:
//假设输入的文本是"let"
bpe(chunk){
//检查缓存中是否已有处理结果,如果有,则直接返回缓存的结果,避免重复计算
if(this.cache.has(chunk)){
returnthis.cache.get(chunk);
}
//将文本块转换为字节数组,这是编码的第一步
//例如,对于字符串"let",输出将是['l','e','t']
letbytes=this.byteEncodeStr(chunk);
//获取字节对(即字符对),这是为了找出文本中相邻字符的组合
//例如,对于上面的字节数组,输出将是[['l','e'],['e','t']]
letpairs=get_char_pairs(bytes);
//如果没有字符对,则直接返回编码后的字节
//这种情况通常发生在输入文本长度为1时
if(!pairs){
returnbytes.map((x)=>this.encoder.get(x));
}
//不断合并最频繁的字符对,直到不能再合并为止
//这是BPE算法的核心,通过合并频繁出现的字符对来减少文本的长度
while(true){
letminPairs=newMap();
//找出当前最频繁的字符对
//这里使用一个映射来记录每个字符对的频率(或排名)
pairs.forEach((pair)=>{
letjoined_pair=pair.join("");
letrank=this.bpe_ranks.get(joined_pair);
minPairs.set(rank===undefined||isNaN(rank)?1e11:rank,pair);
});
//获取在bpe文件中最先出现的字符对,后续会合并该字节对
//之所以先合并该字节对,是因为后续的合并依赖于前面的合并结果
letminPairsKeys=Array.from(minPairs.keys()).map((x)=>Number(x));
letbigram=minPairs.get(Math.min(...minPairsKeys));
//如果没有更多字符对可以合并,跳出循环
if(!bigram||!this.bpe_ranks.has(bigram.join(""))){
break;
}
letfirst=bigram[0];
letsecond=bigram[1];
letnew_bytes=[];
leti=0;
//合并字符对
//这个循环遍历字节数组,寻找并合并指定的字符对
while(i<bytes.length){
letj=bytes.indexOf(first,i);
if(j===-1){
//如果找不到字符对中的第一个字符,则将剩余的所有字符添加到新的字节数组中
this.mutatingConcat(new_bytes,bytes.slice(i));
break;
}
//将当前位置到找到的位置之间的字符添加到新的字节数组中
this.mutatingConcat(new_bytes,bytes.slice(i,j));
i=j;
if(
bytes[i]===first&&
i<bytes.length-1&&
bytes[i+1]===second
){
//如果找到了字符对,则将它们合并为一个字符,并添加到新的字节数组中
new_bytes.push(first+second);
i+=2;
}else{
//如果没有找到字符对,则只添加当前字符
new_bytes.push(bytes[i]);
i+=1;
}
}
//更新字节数组为合并后的结果,以便进行下一轮合并
bytes=new_bytes;
//如果字节数组长度为1,则停止合并
if(bytes.length===1){
break;
}
//重新获取字符对,以便进行下一轮合并
pairs=get_char_pairs(bytes);
}
//将合并后的字节数组转换为tokens
//这里的转换是基于一个预定义的编码器,将每个字节(或字节组合)映射到一个特定的token
lettokens=bytes.map((x)=>this.encoder.get(x));
//缓存结果并返回
//这样,相同的输入在下次处理时可以直接从缓存中获取结果,提高效率
this.cache.set(chunk,tokens);
returntokens;
}
以上就是实现一个分词器的具体过程。
总结
本文详细介绍了如何实现一个分词器,并探讨了其在自然语言处理和代码补全中的应用。通过理解BPE算法的原理和实现过程,我们不仅能够创建自定义的分词器,还能更好地适配和优化大语言模型的使用。本文提供的分词器实现方案不仅适用于代码补全工具,还可以扩展到其他需要文本处理的领域。通过掌握这些技术,我们可以提升模型的准确性和效率,为开发更智能的应用打下坚实的基础。
参考链接
-
OpenAI Cookbook,如何使用Tiktoken计算token数量:https://cookbook.openai.com/examples/how_to_count_tokens_with_tiktoken
-
字节对编码:https://towardsdatascience.com/byte-pair-encoding-subword-based-tokenization-algorithm-77828a70bee0
-
Tokenizer功能预览:https://platform.openai.com/tokenizer
END-
如果您关注前端+AI 相关领域可以扫码进群交流


扫码进群2或添加小编微信进群1😊
关于奇舞团
奇舞团是 360 集团最大的大前端团队,非常重视人才培养,有工程师、讲师、翻译官、业务接口人、团队 Leader 等多种发展方向供员工选择,并辅以提供相应的技术力、专业力、通用力、领导力等培训课程。奇舞团以开放和求贤的心态欢迎各种优秀人才关注和加入奇舞团。
