
包阅导读总结
1. 关键词:AI/BI 仪表盘、交互性、数据探索、性能提升、新功能
2. 总结:本文介绍了 Databricks 的 AI/BI 仪表盘的新功能,包括交叉过滤、静态部件参数、默认值设置、性能改进和基于查询的参数,这些功能增强了仪表盘的性能和交互性,有助于用户更深入地探索数据和做出决策。
3. 主要内容:
– AI/BI 仪表盘新功能
– 交叉过滤:点击可视化中的数据点可过滤仪表盘,探索数据关系和相关性。
– 静态部件参数:创建多个突出数据不同方面的可视化,无需为每个可视化创建单独数据集。
– 默认值:设置初始加载的默认过滤值,引导观众关注特定数据。
– 性能提升:通过查询缓存等技术优化性能,提供快速的交互体验。
– 基于查询的参数:允许参数和字段组合,能从其他数据集获取参数值。
– 功能优势
– 帮助用户动态探索数据,更快做出更明智的决策。
– 减少数据集混乱,简化仪表盘构建过程。
– 确保初始加载时观众聚焦关键数据点。
– 提升查询速度,减少等待时间。
– 增加灵活性,实现高级分析能力。
思维导图: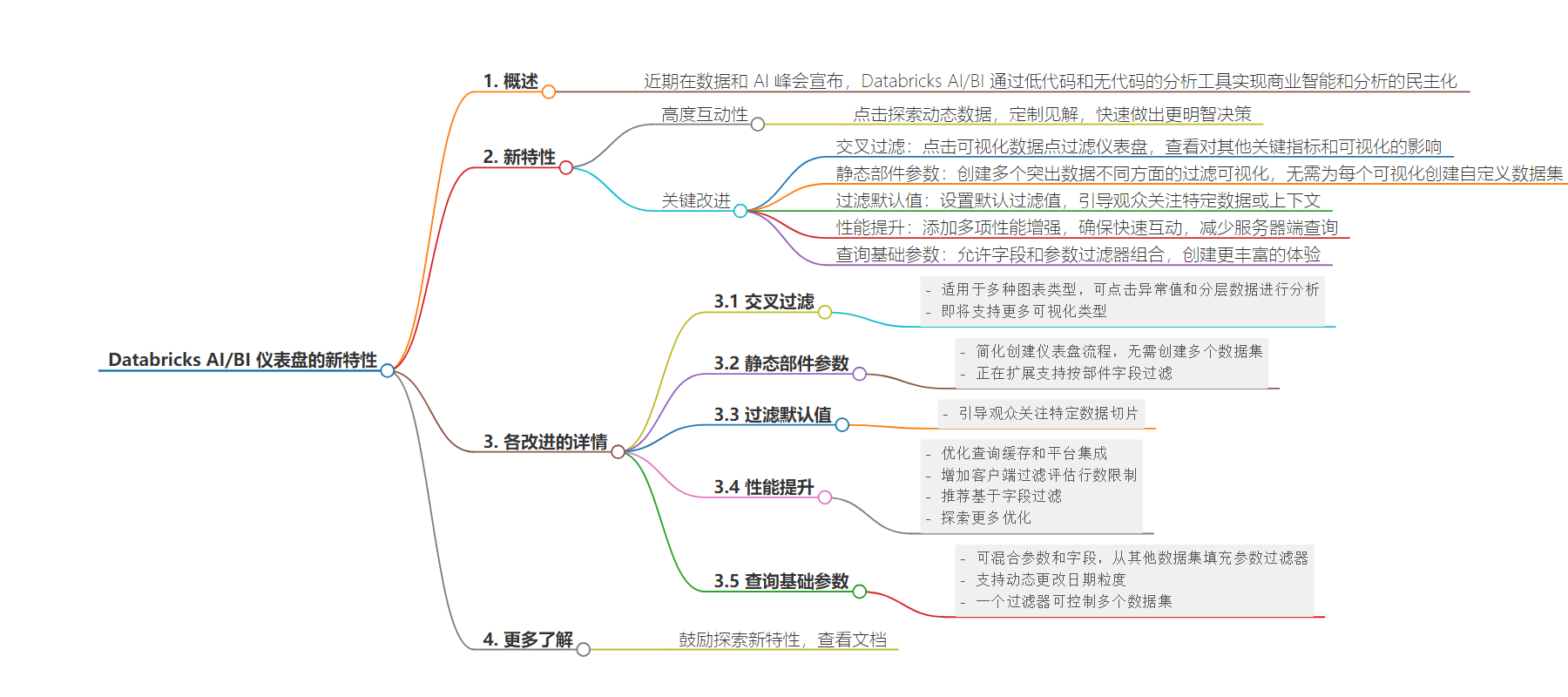
文章地址:https://www.databricks.com/blog/next-level-interactivity-aibi-dashboards
文章来源:databricks.com
作者:Databricks
发布时间:2024/9/9 8:46
语言:英文
总字数:1504字
预计阅读时间:7分钟
评分:88分
标签:AI/BI 仪表盘,交互式仪表盘,数据探索,商业智能,性能优化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
As recently announced at this year’s Data and AI Summit, Databricks AI/BI democratizes business intelligence and analytics across your organization with highly visual and interactive low-code AI/BI Dashboards and no-code conversational analytics powered by AI/BI Genie. In this blog, we are excited to showcase a number of new features that enhance the performance and interactivity of AI/BI Dashboards.
Highly interactive (or clickable) business intelligence dashboards are table stakes these days. They are essential because they enable dashboard users to explore data dynamically, customizing insights with every click. This allows them to ask follow-up questions of their data and make more informed decisions much faster, unlike static dashboards that limit exploration and problem-solving through analytics.
Key improvements that we will cover in this blog include:
- Cross-Filtering: You can now click on interesting data points in a visualization to filter your dashboard and see the impact on other key metrics and visuals. This helps you explore your data to understand relationships and correlations that uncover new insights.
- Static Widget Parameters: Create multiple filtered visualizations that highlight different aspects of your data. For example, build two charts focusing on sales, one from the current year and one from the previous year. With static widget parameters, you can build visualizations from a single parameterized dataset without needing to create a custom dataset per visualization.
- Filter Default Values: Focus viewers on specific data or context within a dashboard by setting default filter values that apply on initial load.
- Improved Performance: Nobody likes dashboards that lock up or tell you to “please wait” every time you open them or click on an interesting data point. To that end, we have added several performance enhancements to ensure users get lightning-fast interactive dashboards so they can ask follow-on questions of their data without running additional SQL queries.
- Query-Based Parameters: Dashboard authors should be able to create expressive experiences with both field and parameter filters. By allowing the combination of parameters and fields in a single filter, we’ve enabled new capabilities, such as dynamically populating a parameter dropdown with query results.
Cross-Filtering
When exploring a dashboard, specific data points in a visualization may stand out for further investigation. While some filters may already be in place, they may not anticipate every viewer’s needs.
With cross-filtering, every chart can now be used to filter your data. Simply click on visualizations to filter the dashboard and explore the data more deeply. Cross-filtering is automatically enabled for all visualizations that share the same dataset, meaning you can click on one part of a visualization (like a bar in a bar chart) to filter the data across all related visualizations in the dashboard.
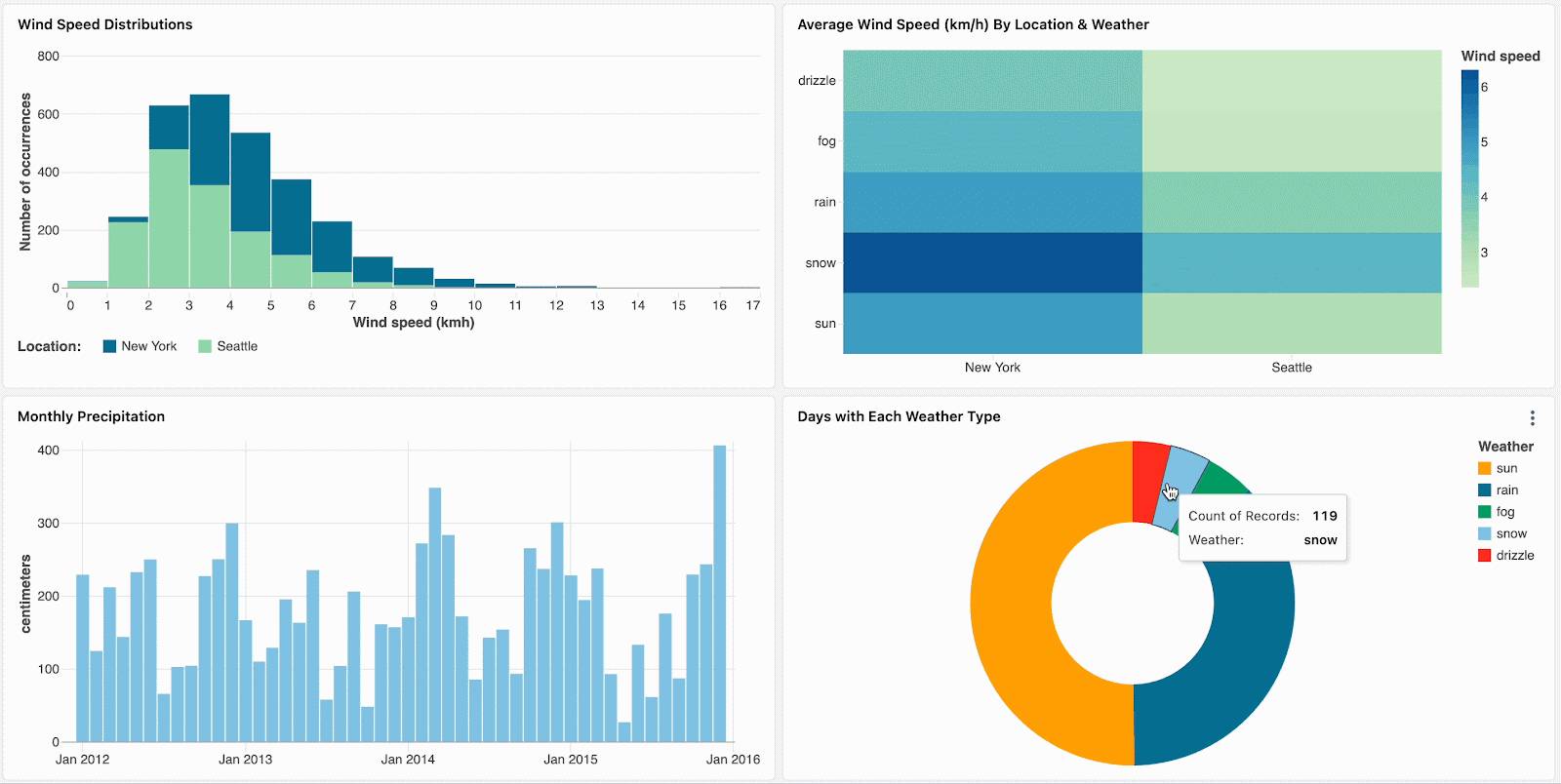
Slice through your data and focus your analysis by clicking on outliers, such as visually distinct marks in a heatmap.
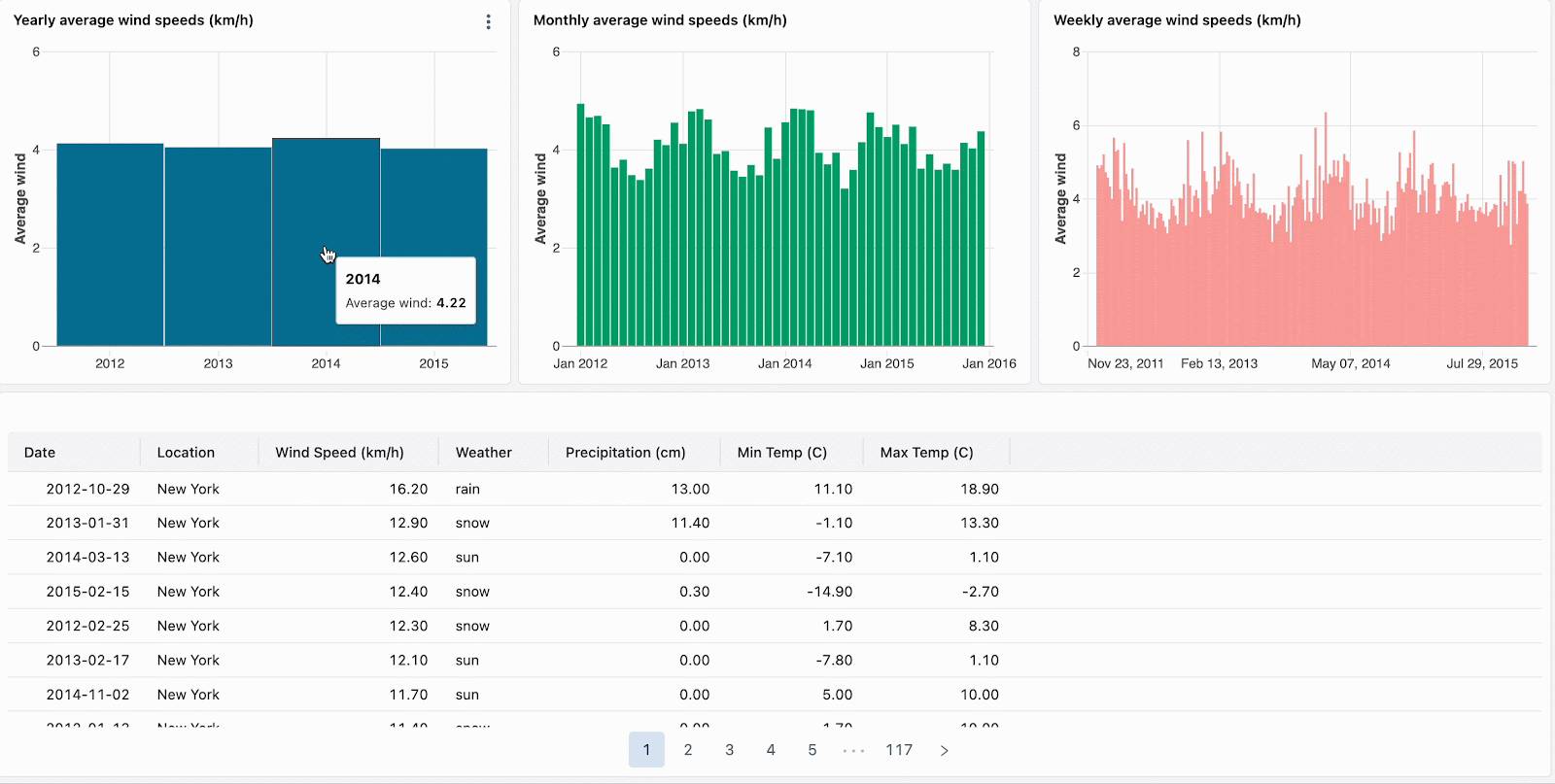
Navigate hierarchical data by drilling down through aggregated visualizations. For example, click on yearly data to restrict other charts to that year’s data. Click on bars in month-level and week-level charts to continue drilling down.
Currently available for bar charts, heatmaps, pie charts, and scatter plots, cross-filtering complements existing field and parameter filters. Support for additional visualizations, including histograms, line charts, area charts, combo charts, and multi-value selection, is coming soon.
Static Widget Parameters
Building dashboards is easier with fewer datasets. Cloning a dataset just to add another filter or aggregate for a specific visualization introduces clutter and friction
Static widget parameters simplify this process by allowing you to customize filters for each visualization without creating separate filtered datasets. This feature complements the existing ability to define per-visualization aggregates and bins.
For example, to highlight temperature metrics for different locations using a single dataset, you can augment it with a condition like:
/*This filter allows for the display of grand totals when the viewer selects 'All'.- If a specific location is selected, the filter matches records for that location.- If 'All' is selected, the filter condition always returns true, including all locations in the results.Read more details about this pattern here*/WHERE location = :location OR :location = 'All'Next, simply set a different static parameter value for each new visualization. In the example below, you can see three charts: one for all locations, one for Seattle and one for New York. Each chart uses the same dataset, but different static values are applied to filter the data accordingly.
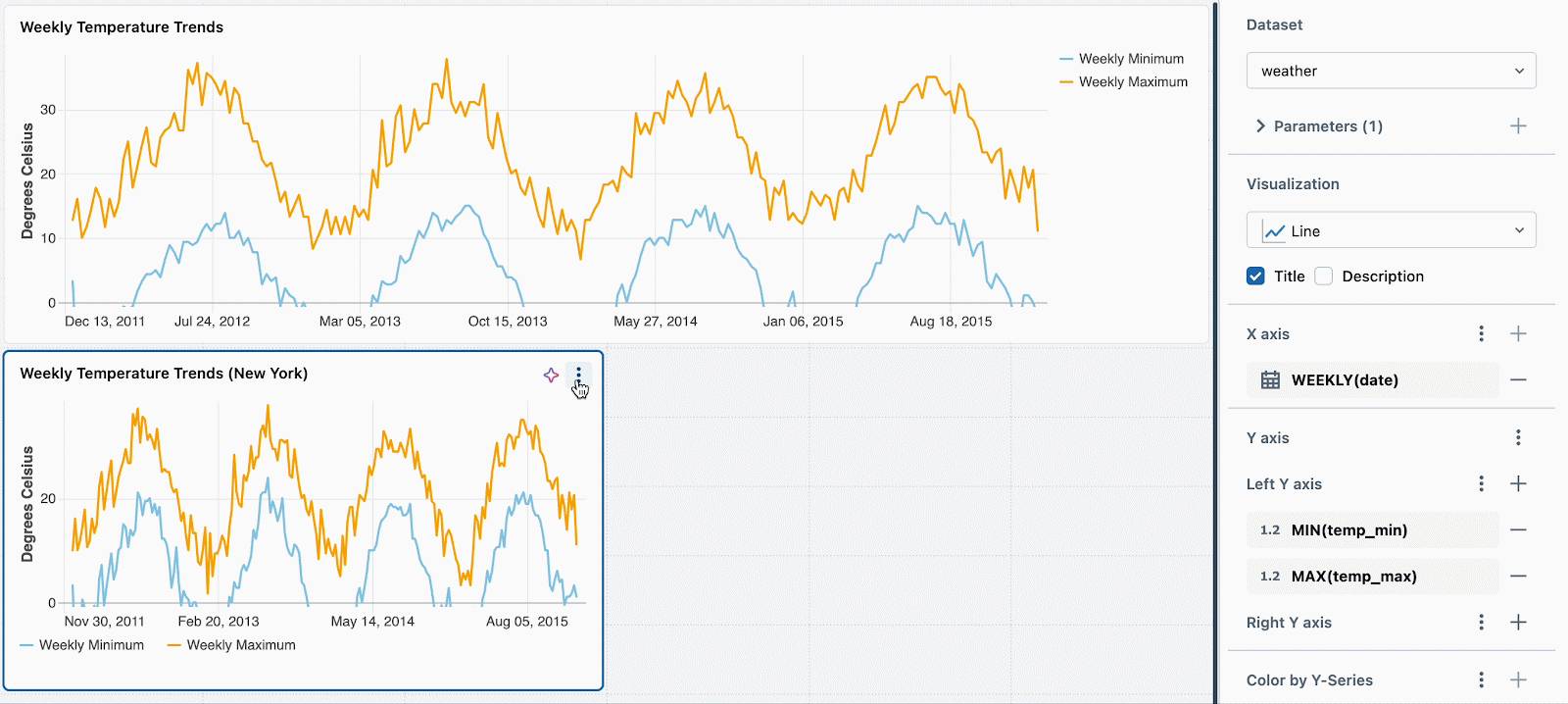
We’re working on extending this functionality to support per-widget filtering using fields. For example, you could filter each chart on the location field without needing to parameterize the underlying dataset.
Default Values
As a dashboard author, you might want to guide viewers to a specific data slice, such as a particular date range or location.
With default values, you can set specific filter values that apply on initial dashboard load or when selections are reset. This ensures that viewers focus on the key data points from the start. Default values complement the existing ability to preserve dashboard filter selections by sharing a URL of your current view.
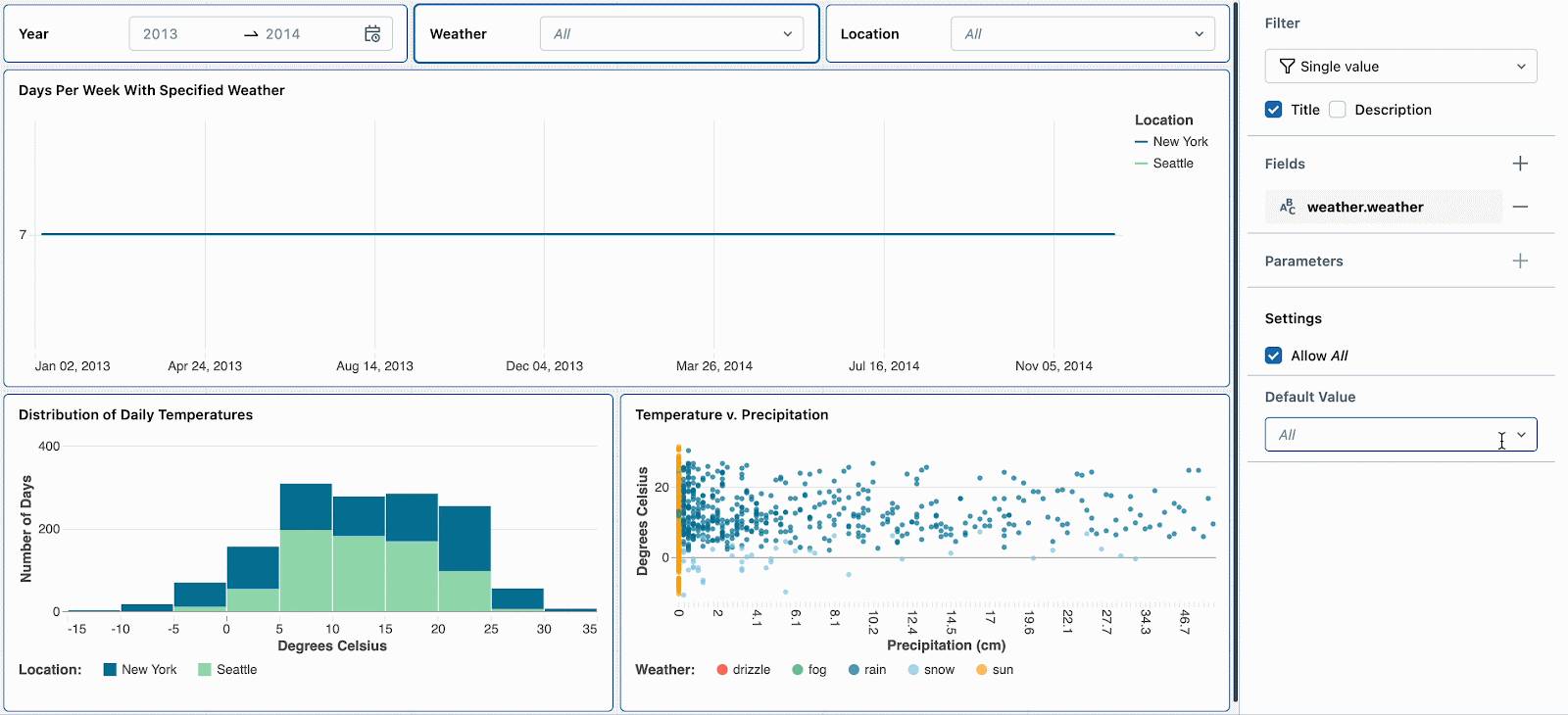
For example, snow days are interesting because they have extreme temperatures and high precipitation. Setting the default weather filter to ‘snow’ will encourage new dashboard viewers to explore this weather type first. After reviewing other weather trends, they can reset the filter to continue their deep dive into snow days.
Improved Performance
For an interactive dashboard to truly be delightful, it must be fast. Waiting for queries to run with each filter application can disrupt the flow of analysis.
AI/BI Dashboards are optimized for high performance, even with large data, through techniques like query caching and deep platform integration. Query caching automatically stores the query results for 24 hours, ensuring faster performance by leveraging previously executed queries. You can also proactively populate the cache through schedules.
In addition to delivering fast initial load, AI/BI Dashboards provide near-instant interactivity for smaller datasets by evaluating filters in the browser rather than re-executing queries on every change.
We recently increased the client-side filter evaluation limit to 100K rows. This means that for datasets within this limit, the entire dataset is queried once, and all subsequent filtering is handled client-side, eliminating the need for additional server-side queries. Even with large tables, techniques like pre-aggregation with materialized views can create smaller, faster-filtering datasets.
We generally recommend filtering on fields rather than parameters, which always require server-side queries. Parameters are best suited for cases that filtering on fields can’t yet handle, like filtering in subqueries or defining datasets with complex aggregates.
We continue to explore additional optimizations such as further increasing the client-side filter limit. Upcoming features such as visualization-level calculations will increase the number of use cases that can be fully achieved through filtering on fields.
Query-Based Parameters
Parameters are a powerful tool because they can be introduced anywhere in a dataset’s SQL, offering maximum flexibility when defining filters. Although parameters are placeholders for literals in SQL, they should act like any other field, allowing authors to populate dropdowns and other filters used to configure their values.
By enabling the mixing of parameters and fields, we’ve added the ability to populate parameter filters with values from other datasets. This approach to query-based parameter values unlocks advanced analysis capabilities, such as dynamically changing date granularities.
For example, you can enable drilling down through different date granularities by parameterizing the DATE_TRUNC function used for aggregation. The resulting dataset and metrics are aggregated, which means that adding an additional weather filter also requires parameterizing the query.
SELECT DATE_TRUNC(:date_granularity, date) as date, avg(wind) as average_wind_speed, sum(precipitation) as total_precipitationFROM weatherWHERE :weather = 'All' or weather = :weatherGROUP BY ALLDashboard viewers should be able to easily choose valid values in their filter dropdowns. For example, they should not need to guess if “YEAR” or “YEARLY” is the correct literal for date truncation. To populate the dropdowns correctly, create the following two datasets
--Dataset 1: Generate a static list of valid date granularitiesSELECT * FROM VALUES ('day'), ('week'), ('month'), ('year') AS t(date_granularity)--Dataset 2: Choose the distinct weather categories from the underlying tableSELECT DISTINCT weather FROM weather UNION ALL SELECT DISTINCT 'All' AS WeatherModify the date granularity and weather parameter filters to reference the fields in these dataset to populate the dropdowns and start drilling down through dates.
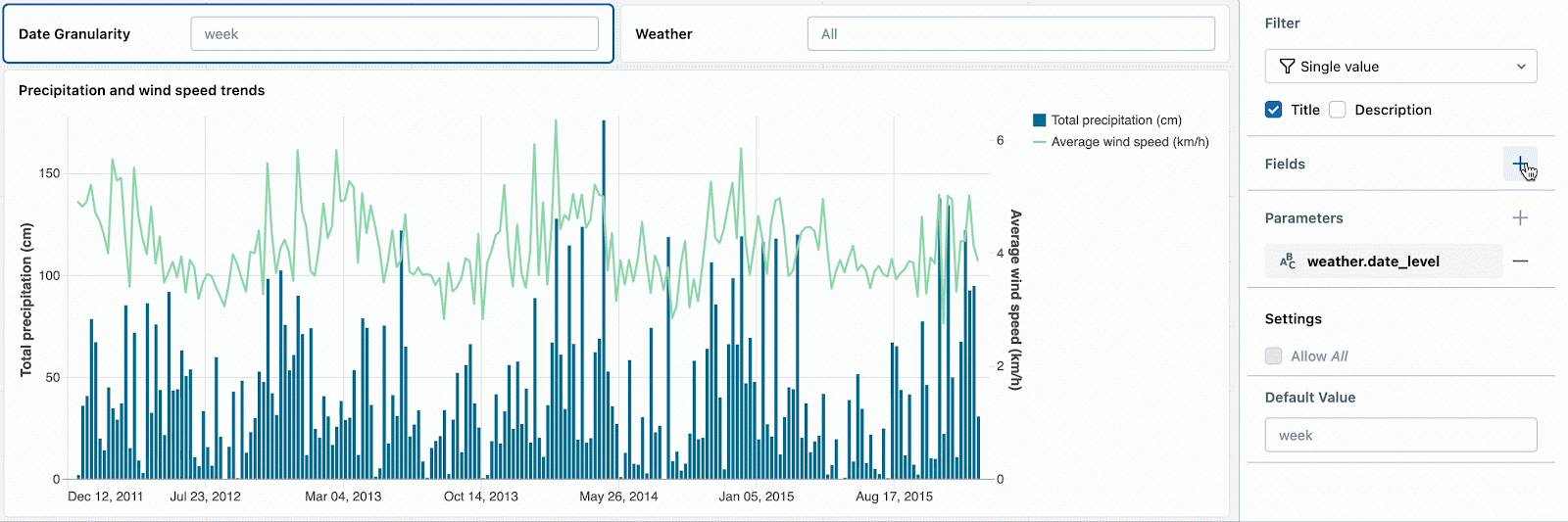
Combining fields and parameters in a single widget also lets you use one filter to control multiple datasets, regardless of whether those datasets use parameters or field filters.
We’re looking forward to providing even more flexibility in field and parameter filtering with upcoming features like date range parameters and multi-value parameters.
Learn More About AI/BI Dashboards
As we’ve demonstrated, AI/BI Dashboards are a significant area of investment for Databricks, with interactivity being a key focus. We encourage you to explore these new features and see how they can elevate your own dashboards. Check out the Databricks documentation around AI/BI Dashboards, including deep dives on parameters and filters.
Your feedback is invaluable as we continue to refine and expand our AI/BI Dashboards. We look forward to hearing your thoughts and suggestions!