
包阅导读总结
1. 关键词:Dataflow、Apache Flink、Yahoo、Cost、Throughput
2. 总结:在 Yahoo 的测试中,Dataflow 比自管理的 Apache Flink 成本效益高约 1.5 – 2 倍。通过计算实现相似吞吐量的成本得出,Dataflow 将大量繁重计算发送到后端,需更少 vCPUs,更稳定且吞吐量更一致,新计费功能能优化成本。
3. 主要内容:
– 对比 Dataflow 和 Apache Flink 在 Yahoo 的情况
– 测试目的是计算达到相似吞吐量的成本
– 目标是各应用每秒处理消息数尽可能接近
– 案例分析
– Enrichment 用例中,GKE 上 Flink 的 vCPUs 约为 Dataflow 的 13 倍
– 并非 Flink 低效,而是 Dataflow 计算模式不同
– 优势说明
– Dataflow 后端做繁重计算,需更少 vCPUs,更稳健,吞吐量更一致
– 成本分析
– Dataflow 有新计费功能优化成本
– Flink 未花太多时间调优,假设最佳利用率计算成本
思维导图: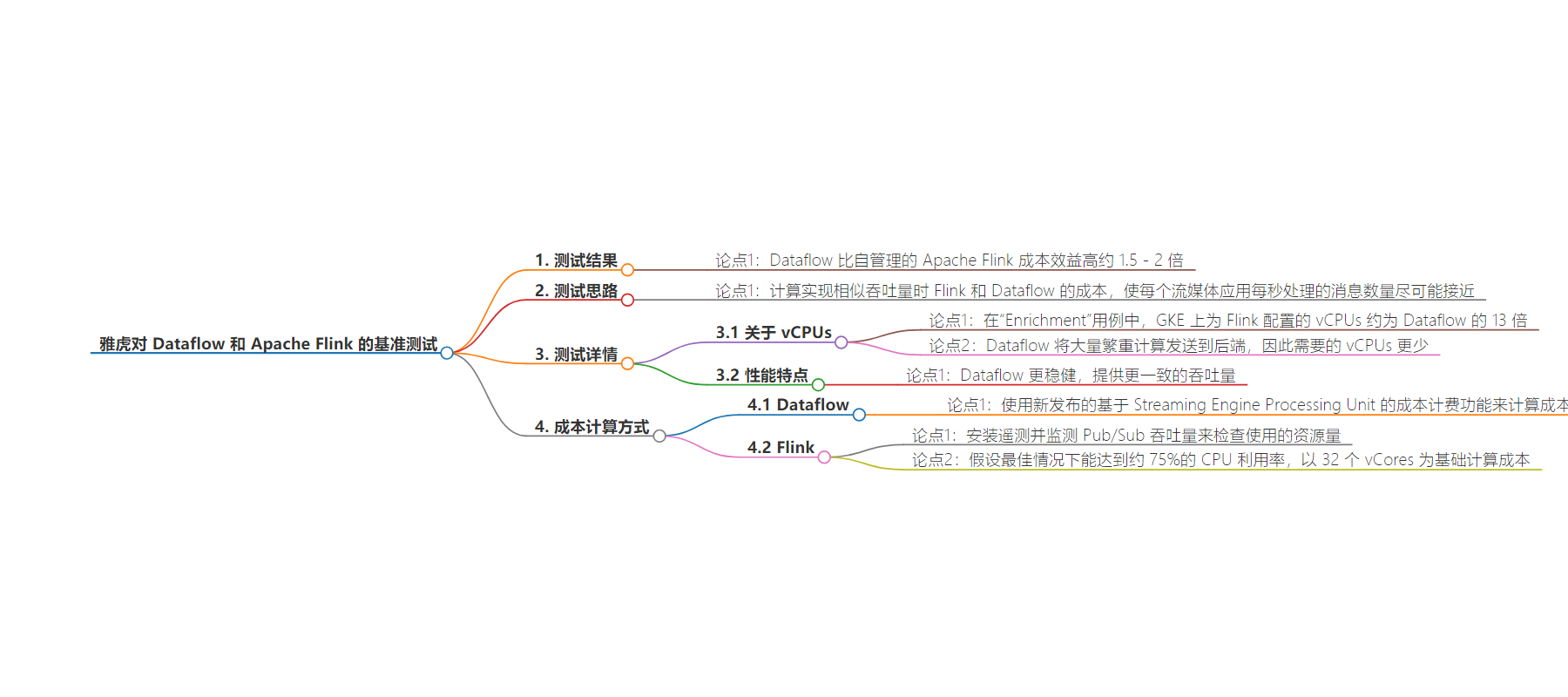
文章来源:cloud.google.com
作者:Ihaffa Murtopo,Abel Lamjiri
发布时间:2024/8/15 0:00
语言:英文
总字数:1206字
预计阅读时间:5分钟
评分:84分
标签:数据处理,基准测试,Apache Flink,谷歌云数据流,大数据
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
The result shows that Dataflow is around 1.5 – 2 times more cost effective in comparison to self-managed Apache Flink on our test cases. Let’s understand in more detail how we achieved these numbers.
The idea for the benchmark was to calculate Flink/Dataflow costs for achieving similar throughput, with the goal of having the number of messages processed per second for each of the streaming applications to be as close as possible. In the table above, for the Enrichment use case, the number of provisioned vCPUs on GKE is approximately 13x higher compared to Dataflow. This is not because Flink is inefficient, but because in Dataflow, Streaming Engine sends a lot of the heavy computation to the Dataflow backend. Of course, there was some room to improve Flink utilization, but doing that turned out to make the job unstable, so we did not spend further time there and calculated the cost for 32 vCPUs (2 x n2d-standard-16 machines) as if utilization was ~75%.
You can think of the Dataflow backend as a Google Cloud backend resource for doing heavy computation (e.g., shuffling) rather than doing it on Dataflow’s worker. This naturally makes Dataflow require fewer vCPUs, makes it more robust, and provides much more consistent throughput. This is critical for Yahoo use cases to be able to leverage the Streaming Engine.
In the image below, our Dataflow pipeline uses a newly released cost billing feature that calculates cost based on Streaming Engine Processing Unit. From our testing, the new billing feature was able to optimize pipeline costs for our throughput-based workloads. On the Flink side, we installed telemetry and monitored Pub/Sub throughput to check the amount of resources it was using. For the Flink setup, we didn’t spend too much time tuning the job and therefore, assumed lowest cost if we had improved utilization, i.e., the cost was based on having 32 vCores assuming we could get around 75% CPU utilization as a best case.
To see a detailed breakdown of the cost of Dataflow, go to the Dataflow Cost tab, like this: