
包阅导读总结
1.
– `Kafka`、`开发者自主`、`自服务工具`、`开发效率`、`数据管理`
2.
本文探讨了 Apache Kafka 在开发中面临的问题,如资源管理和数据访问的摩擦,影响开发者效率。提出可通过自服务工具解决,包括探索和排障、监控和告警等组件,同时介绍了最佳实践和原则。
3.
– Apache Kafka 及开发者面临的问题
– 随着项目发展,Kafka 可能成为开发者的摩擦源。
– 早期项目需求简单,后期需其他团队接管维护和服务数据访问请求,导致延迟和额外工作。
– 影响开发进程的关键因素
– 过度集中的治理延缓资源访问和变更批准。
– 开发者对 Kafka 生态系统不熟悉。
– 团队间沟通障碍。
– 解决减速问题的 Kafka 自服务工具
– 探索和排障:帮助开发者理解处理的数据。
– 监控和告警:评估基础设施可用性和代码更新影响。
– 所有权和发现:数据目录帮助发现和导航数据。
– 数据集成:确保开发团队适当的访问权限。
– 更自主开发团队的最佳实践
– 实施配置即代码和 CI/CD。
– 团队成员理解客户端配置。
– 规划应用时明确需求和选择合适模式。
– 寻找合适的方法推动开发者成果
– 实施有益的防护栏。
– 优化 Kafka 基础设施以有效管理成本。
– 提供强大的安全控制。
思维导图: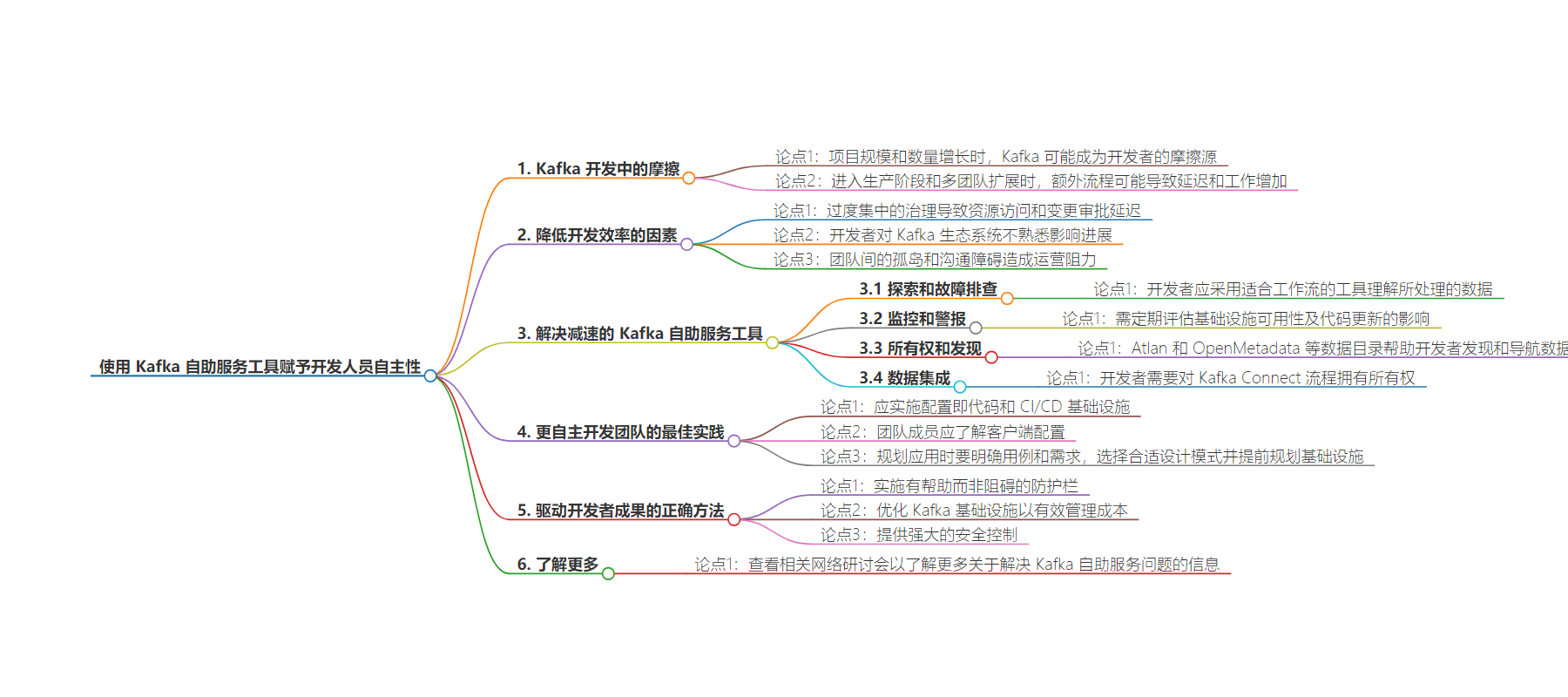
文章地址:https://thenewstack.io/make-developers-autonomous-with-kafka-self-service-tools/
文章来源:thenewstack.io
作者:James White
发布时间:2024/6/21 15:15
语言:英文
总字数:1329字
预计阅读时间:6分钟
评分:81分
标签:Kafka,自助服务,开发者自治,数据管理,数据安全
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Apache Kafka is a flexible real-time data streaming solution that’s used to develop and deploy highly responsive applications and data pipelines, but it can become a source of friction for developers as their projects grow in scope and increase in number.
The resource requirements, data access and security needs of early-stage Kafka projects are usually straightforward and can be managed by the development team internally. But, when moving into production and scaling to multiple teams, it’s common for a site reliability engineering (SRE) team, data platform team or ops team to take over Kafka infrastructure maintenance, as well as servicing requests from the development team for data access.
The introduction of additional processes frequently causes delays and additional work (such as filling out request tickets) in a way that slows down Kafka adoption and makes developers already using Kafka less productive.
It doesn’t have to be this way, however. The friction isn’t a function of the process but rather of how it’s implemented. It’s possible to provide developers with the tools required to efficiently develop Kafka applications, as well as the processes to work with platform teams to provision resources and self-service data requests, without introducing bottlenecks.
Improperly Managed Kafka Drives Down Developer Productivity
There are a few key factors that add drag to development processes when scaling Kafka deployments:
- Overly centralized governance: While tight control over data is necessary for compliance, poorly structured governance delays resource access and change approvals.
- Lack of familiarity with Kafka: Developers who aren’t aware of the full extent of the Kafka ecosystem (Kafka, Kafka Connect, Kafka Streams, MirrorMaker) and how these components interact can slow down progress, especially during ramp-up.
- Silos and communication barriers: Poor communication with other teams (especially knowing who has ownership over specific resources) and poor understanding of the data itself (for example, understanding what metrics are meaningful) create operational drag.
In addition to these primary concerns, inflexible security policies that add layers of complexity to production deployments (for example, encryption, which is not provided out of the box in Kafka) and your own use-case-specific data and regulatory requirements can add further development hurdles.
Solving these problems for developers — without placing expectations on platform teams that they cannot possibly meet or pushing Kafka maintenance and governance tasks back onto them — presents a challenge.
Kafka Self-Service Tools That Can Address the Slowdown
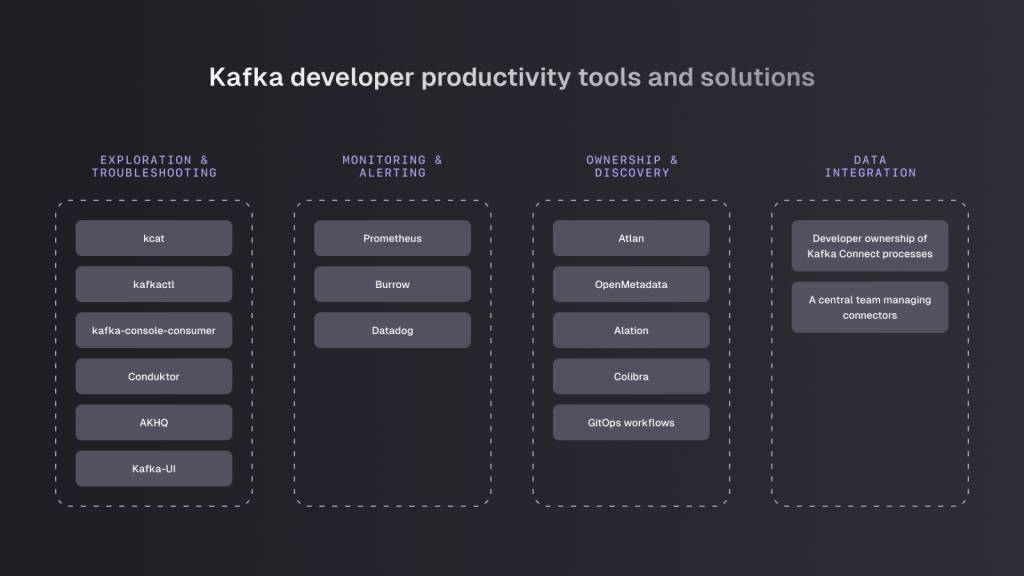
Each application has its own specification, workflows and supporting infrastructure that will determine which tools are appropriate to use. But there are a few key components you should consider introducing to your Kafka environments that will increase developer responsiveness.
Exploration and Troubleshooting
Developers must understand the data they’re handling so that they can quickly identify the source of bugs or unexpected results from their code. They should adopt tools suitable for their workflows that enable this:
Monitoring and Alerting
Infrastructure availability and the performance and operational impacts of code updates need to be regularly assessed so that ongoing development does not affect production reliability. Prometheus, Burrow and Datadog provide robust components for monitoring Kafka deployments.
Ownership and Discovery
Atlan and OpenMetadata are data catalogs that help developers discover and navigate data to detect patterns and answer questions. For larger organizations, Alation and Collibra provide enterprise-grade data intelligence platforms that can classify and secure extensive data assets.
Data ownership best practices can be reflected in your GitOps processes. Record metadata about resources, including their owner, as soon as they are created so there are no barriers to finding out what a resource is and who is responsible for it.
Data Integration
Integrating data from multiple sources, or moving your data to a location where other teams or organizations can integrate it, is a function of many Kafka use cases. Developers need ownership of Kafka Connect processes (like Debezium) for many business applications and data-sharing use cases so that applications can listen to changes in state and events. It’s important to ensure that configuration and connectors give development teams access to everything they need to operate independently, without granting them access that is too broad.
The alternative to this is a central team that manages connectors. But without the full context and understanding of each specific application and use case, this can have the opposite of the intended effect, reducing efficiency by requiring additional back-and-forward communication between teams until the required access and shared understanding is obtained.
Best Practices for More Autonomous Development Teams
Self-service tools are not a panacea and can’t solve organizational problems that mire down development workflows. Configuration as code (GitOps) and CI/CD for infrastructure should be implemented to help ensure reliable and reproducible development and testing environments — but that’s true with Kafka as well as without.
Your team members should also have a functional understanding of your client configurations to avoid misconfiguration: Kafka producer and consumer behavior (batch sizes, buffer sizes, timeouts) impact Kafka performance and, if incorrectly configured, can lead to excessive resource usage, increased latency and reduced throughput.
When planning your application, it goes without saying that you should carefully identify the use case and requirements, and choose appropriate design patterns (e.g., orchestration, choreography, event-driven, stream-processing or compaction/retention architectures). Resilient and scalable infrastructure capable of meeting your application’s requirements (especially in event-driven architectures using Kafka for event sourcing) should also be planned in advance.
The less technical debt your projects accrue in their early stages, the more time developers can spend verifying that data pipelines are properly implemented and that the right people can access the data they need without technical or process delays.
Finding the Right Approach To Drive Developer Outcomes
Learning the tools and establishing the practices outlined above is a lot for any single developer or team to take on. Most products are not tightly integrated, and their lack of overarching governance functionality can lead to poor understanding and ownership and result in data mishandling.
It’s possible that you’ll adopt only some of the tools in the beginning, or different tools. But there are a few principles you can use to drive towards a frictionless experience for your developers, regardless of the specific pieces of software and engineering practices you choose:
- Implement guardrails that help rather than hinder: Give your developers autonomy within a bounded context that includes only the data they need. This reduces errors and helps you stay compliant with privacy regulations like GDPR and the California Consumer Privacy Act (CCPA).
- Optimize Kafka infrastructure to manage costs effectively: Kafka costs can quickly become expensive. Data replication processes create multiple sources of truth, each requiring infrastructure and maintenance. While replication is sometimes necessary, usually for sharing a subset of data with third-party partners, it’s worth challenging this if the use case can be serviced another way (for example, using tightly controlled access or virtualization).
- Provide robust security controls: Platforms that grant access to data must provide mechanisms for creating and enforcing robust security policies and protecting user data with redaction and personal identifiable information (PII) masking.
And, at an even higher level: When designing your applications and the infrastructure that powers them, the goal should be to facilitate self-service and collaboration, not shift responsibility away from ops teams. Developers need freedom, and ops teams need to know their Kafka deployments are being used properly without micromanaging each access request.
Learn More About Developer Autonomy and Kafka
If you want to find out more about identifying scaling challenges in the Kafka ecosystem, check out our Conduktor 2.0 webinar to find out how Conduktor solves the self-service problems that teams and organizations face when working with real-time data at scale, resulting in faster delivery times and more realized value from data investments.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.