
包阅导读总结
1. 关键词:Apache Spark、Gluten、物理计划、性能优化、转换机制
2. 总结:
此提案旨在将 Gluten 项目的物理计划转换、验证和回退机制引入 Apache Spark,以增强其灵活性和性能,解决 Spark 缺乏跨平台物理计划执行机制的问题,提高其可移植性和互操作性,还介绍了相关的设计方案和实施步骤。
3. 主要内容:
– 目的
– 将 Gluten 物理计划相关机制引入 Apache Spark
– 动机
– Spark 缺乏支持物理计划跨平台执行的官方机制
– Gluten 利用 Substrait 标准优化 Spark 物理计划,引入可增强 Spark 物理计划的可移植性和互操作性,提高执行效率
– 设计提案
– 定义 TransformSupport 接口及不同类型的子接口,扩展 SparkPlan 以支持计划转换
– 物理计划验证过程中向不同原生后端传递 Protobuf 格式的 Substrait 计划进行验证
– 验证失败使用 Spark 自身算子执行计划,需支持数据格式转换
– 实施步骤
– 先完成计划转换阶段,利用 Substrait 转换为通用格式
– 完成第一步后考虑验证和回退步骤
– 结论
– 已在 Apache Gluten 中成功融入转换方法,支持 ClickHouse 和 Velox 后端,取得性能突破,众多客户已在生产环境中部署 Gluten
思维导图: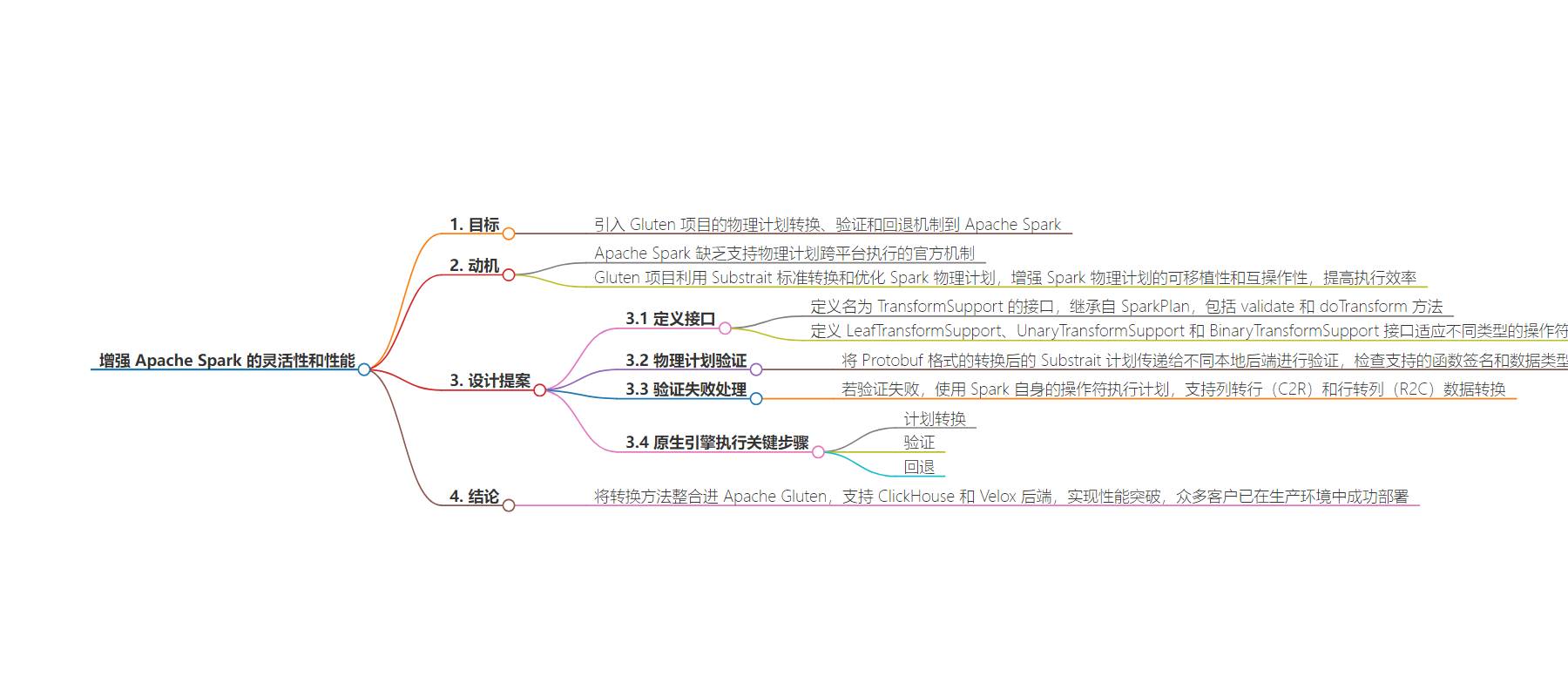
文章来源:thenewstack.io
作者:Mark Andreev
发布时间:2024/6/24 14:06
语言:英文
总字数:512字
预计阅读时间:3分钟
评分:81分
标签:贡献
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
This proposal aims to introduce the physical plan conversion, validation, and fallback mechanisms from the Gluten project into Apache Spark. This will allow Spark to have greater flexibility and robustness when executing physical plans, while also taking advantage of the performance optimizations provided by Gluten.
Motivation
Apache Spark currently lacks an official mechanism to support cross-platform execution of physical plans. The Gluten project offers a mechanism that utilizes the Substrait standard to convert and optimize Spark’s physical plans. By introducing Gluten’s plan conversion, validation, and fallback mechanisms into Spark, we can significantly enhance the portability and interoperability of Spark’s physical plans, enabling them to operate across a broader spectrum of execution environments without requiring users to migrate, while also improving Spark’s execution efficiency through the utilization of Gluten’s advanced optimization techniques.
Design Proposal
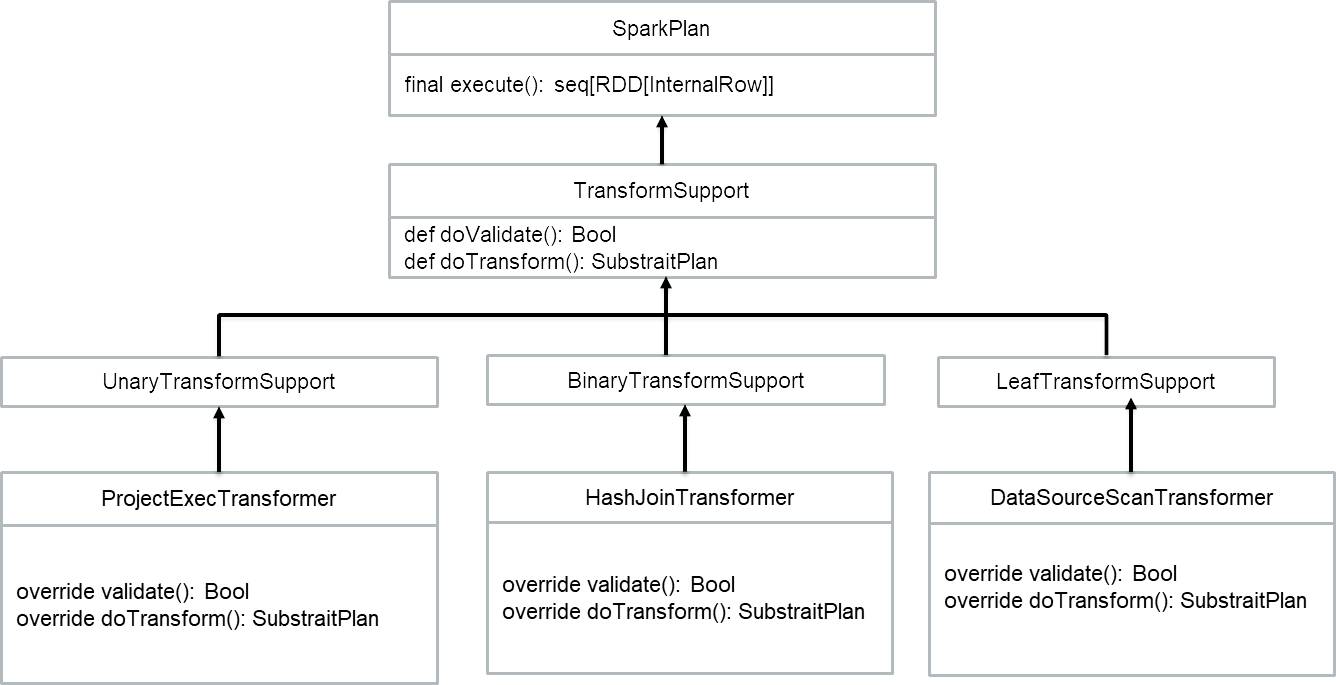
- To integrate Gluten’s plan conversion mechanism within Spark, we first defined an interface called TransformSupport, which inherits from SparkPlan. The TransformSupport interface includes two methods: def validate(): Boolean for validating if this operator/expression is supported in native code, and def doTransform(): SubstraitPlan for performing the plan conversion. Next, we defined three interfaces — LeafTransformSupport, UnaryTransformSupport, and BinaryTransformSupport — to adapt to different types of operators. For example, ProjectExecTransformer will inherit from UnaryTransformSupport, HashJoinTransformer will inherit from BinaryTransformSupport, and DatasourceScanTransformer will inherit from LeafTransformSupport. This way, we can extend SparkPlan to support plan conversion.
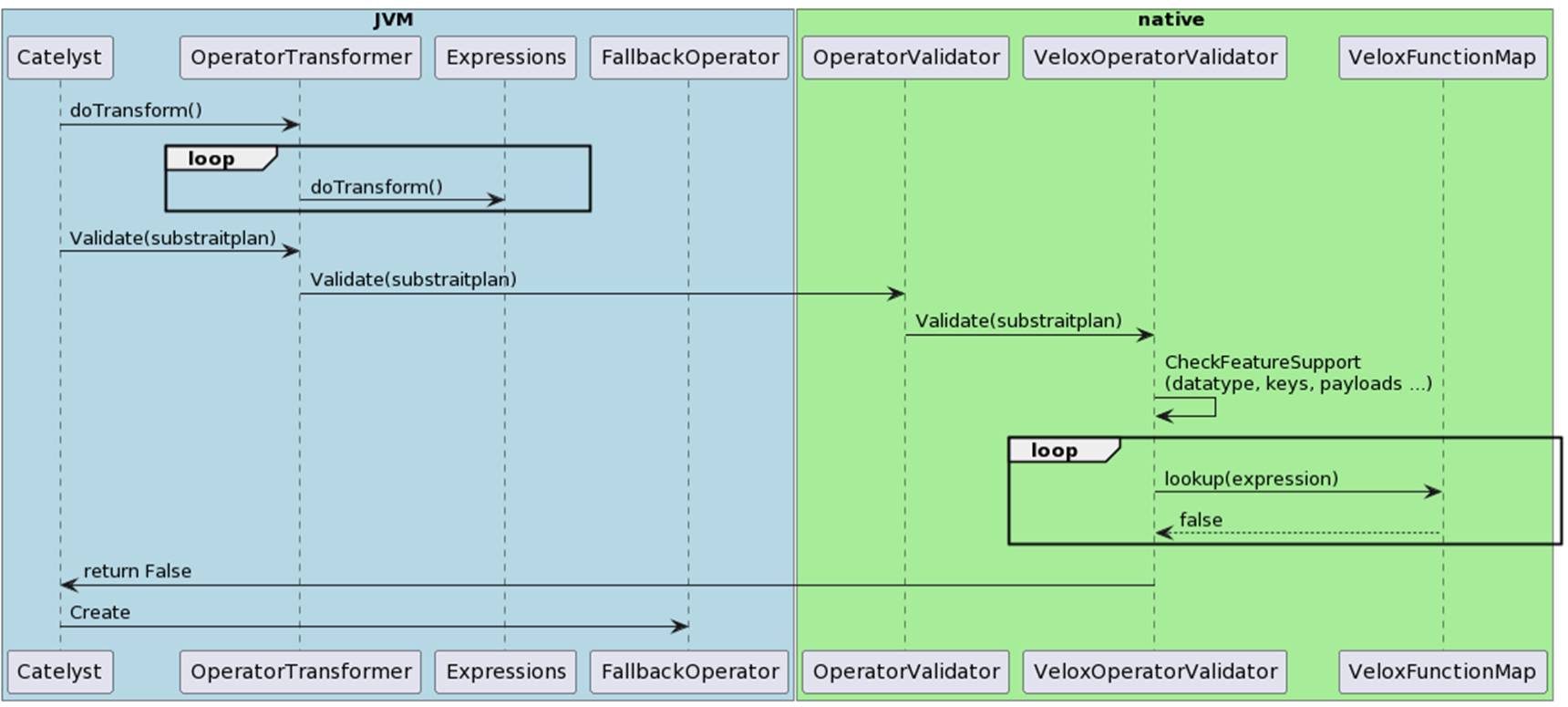
2. During the physical plan validation process, we will pass the converted Substrait plan in Protobuf format to different native backends for validation. This process includes checking supported function signatures and data types. If the validation is successful, it returns true; otherwise, it returns false.
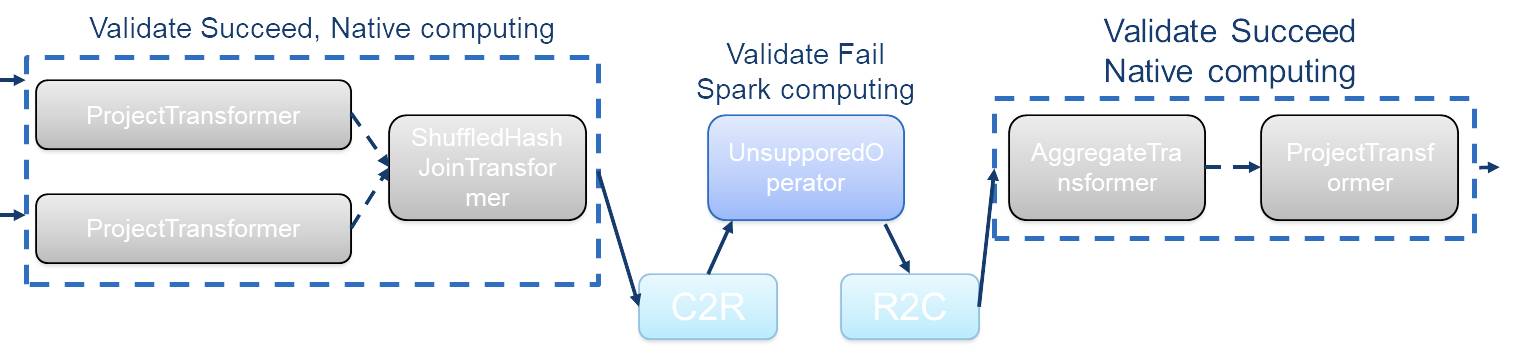
3. If the validation fails, we will continue to use Spark’s own operators to execute the plan, but at this point, support for column-to-row (C2R) and row-to-column (R2C) data transformations is required. Taking the Velox backend as an example, we need to convert Velox’s columnar data format to Spark’s UnsafeRow format in the C2R transformation; conversely, in the R2C transformation, we convert Spark’s UnsafeRow format to Velox’s columnar data format.
To implement the execution of Spark physical plans on a native engine, we need to complete three key steps: plan transformation, validation, and fallback. Given that these steps involve substantial modifications to Spark, we have decided to first focus on the plan transformation phase. By utilizing Substrait, we will convert Spark plans into a common format, thereby achieving compatibility with various backends. After the first step is completed, we will further consider the remaining validation and fallback steps.
Conclusions
We have adeptly incorporated this conversion methodology into Apache Gluten, enabling seamless support for both ClickHouse and Velox backends. Our integration efforts with either backend have culminated in a substantial performance breakthrough. For an in-depth look at the enhancements, please refer to the information provided at this link. Moreover, it is with great pride that we acknowledge the successful deployment of Gluten by numerous customers within their production settings.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.