
包阅导读总结
1. 关键词:AIGC、技术突破、模型、数据集、创新
2. 总结:本文涵盖了多个 AIGC 领域的新进展,包括全球街景图像数据集 OpenStreetView-5M、长视频生成的 FlexiFilm 模型、提升 SWE-bench 解决率的新成果、为 Claude Opus 协调子代理的 Maestro 框架等,展现了 AIGC 技术的不断创新和发展。
3. 主要内容:
– OpenStreetView-5M
– 是包含超 500 万张来自 225 个国家地理标签街道图像的开放获取数据集
– 旨在推动计算机视觉极限,特别是图像定位方面
– 为研究人员提供资源,推动计算机视觉研究和发展
– FlexiFilm
– 专为生成超 30 秒长视频设计的扩散模型
– 保证生成视频的一致性和质量,推动视频制作技术发展
– SWE-bench
– 无代理仅用语言模型实现 24%以上解决率
– 打破依赖代理提高解决率的传统观念,为语言模型研究提供新路径
– Maestro
– 为 Claude Opus 智能协调子代理的新框架
– 提高工作效率,实现灵活性和可适应性,为解决复杂任务提供新可能
– Florence 2
– 基于 onnx 和 WebGPU 的小型视觉模型在浏览器运行
– 旨在帮助开发者理解和利用 WebGPU 性能优势,无需服务器支持
– 纯音频 LLM
– 法国实验室 Kyutai 训练出低延迟纯音频 LLM,未来几个月开源
– 展示了通过最小化延迟提高性能
– CELLO
– 全新数据集包含 14094 个因果问题
– 提升 AI 对因果关系理解能力,超越常识推理层次,标志新里程碑
– PTQ4SAM
– 新框架减轻 SAM 内存和计算压力
– 通过后训练量化使其更实用,推动实用化进程
– SEMamba
– 基于 Mamba 状态空间模型的语音增强系统
– 提高语音信号清晰度,具灵活性,在多领域有广泛应用前景
思维导图:
文章地址:https://mp.weixin.qq.com/s/S_ZxXMTMqqjcp860IQGlLQ
文章来源:mp.weixin.qq.com
作者:漫话开发者
发布时间:2024/7/5 16:08
语言:中文
总字数:3842字
预计阅读时间:16分钟
评分:82分
标签:AI技术,计算机视觉,视频生成,语言模型,图像定位
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
1. OpenStreetView:一个全球图像街景定位数据集开放
OpenStreetView-5M是一个重要的开放获取数据集,包含超过500万张来自225个国家的地理标签街道图像。该数据集旨在通过测试图像定位能力,推动计算机视觉的极限。OpenStreetView-5M不仅覆盖了全球范围内的街道图像,也为研究人员提供了丰富的数据资源,进一步推动了计算机视觉的研究和发展。该数据集对于图像定位,尤其是在复杂环境中的图像定位,具有重要的推动作用。通过该数据集的研究,可以提高现有技术在处理全球范围内的街道图像时的效率和准确性。
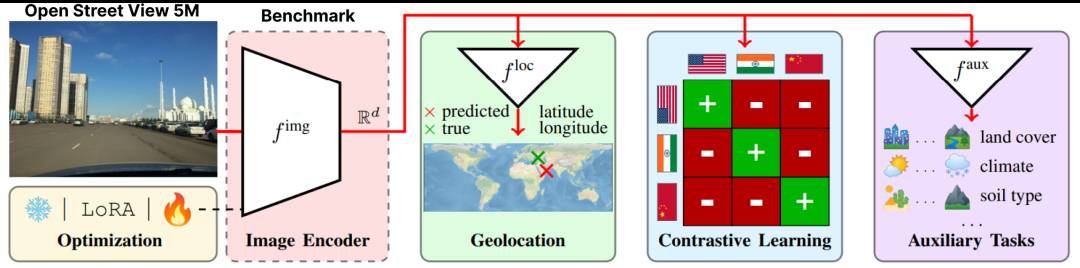
划重点
-
OpenStreetView-5M是一个包含超过500万张来自225个国家的地理标签街道图像的开放获取数据集 -
该数据集旨在推动计算机视觉的极限,特别是在图像定位方面 -
OpenStreetView-5M为研究人员提供了丰富的数据资源,推动了计算机视觉的研究和发展
标签:OpenStreetView-5M, 计算机视觉, 图像定位
原文链接见文末/1[1]
2. FlexiFilm-新扩散模型助力长视频生成
FlexiFilm 是一种专门为生成超过30秒的长视频而设计的扩散模型,它能够保证生成的视频具有高度的一致性和质量。这一新模型的出现,将在视频制作领域开启新的可能性。视频长度不再受限,而且模型生成的视频质量也得以保证。这是一个重要的技术突破,为多媒体内容创建者提供了新的工具,使他们能够更有效地制作和分享他们的作品。FlexiFilm 的出现,无疑将推动视频制作技术向前发展。
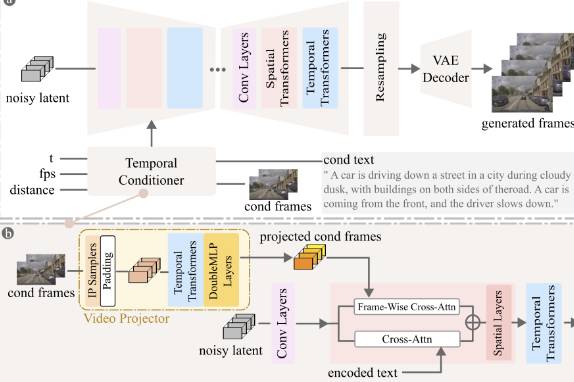
划重点
-
FlexiFilm 是一种专门为生成超过30秒的长视频而设计的扩散模型 -
FlexiFilm 的出现,无疑将推动视频制作技术向前发展
标签:FlexiFilm, 视频生成, 新技术
原文链接见文末/2[2]
3. Agentless 针对SWE-bench解决率大幅提升
近日,一项新的技术研究实现了在无代理的情况下,仅使用语言模型,就能在SWE-bench上实现24%以上的解决率。这一成果对于深化我们对SWE-bench的理解,提高其解决效率具有重要的参考价值。SWE-bench是一款广泛应用于语言模型的评估工具,其在语言模型研究领域有着重要的地位。此次研究的成功,打破了以往必须依赖代理才能提高SWE-bench解决率的传统观念,为未来的语言模型研究提供了新的研究路径。
划重点
-
在无代理的情况下,仅使用语言模型,就能在SWE-bench上实现24%以上的解决率。 -
这一成果对于深化我们对SWE-bench的理解,提高其解决效率具有重要的参考价值。 -
这一研究的成功,打破了以往必须依赖代理才能提高SWE-bench解决率的传统观念,为未来的语言模型研究提供了新的研究路径。
标签:SWE-bench, 语言模型, 无代理
原文链接见文末/3[3]
4. Maestro:为Claude Opus智能协调Agent的新框架
GitHub Repo上的Maestro框架为Claude Opus提供了一个全新的解决方案,它智能地协调子代理。这个框架透过嵌入的方法,将多个子代理整合在一起,以达到更高的效率和效果。此框架的引入,为了解复杂的任务提供了新的可能性。在此框架下,每个子代理可以专注于其特定的任务,而由Maestro进行总体的协调和管理,大大提高了工作效率。同时,它还可以根据任务的实际情况动态调整子代理的数量和功能,实现更高的灵活性和可适应性。这是一个很有前景的技术,值得我们关注和学习。
划重点
-
Maestro是一个新的框架,能够为Claude Opus智能地协调子代理 -
Maestro可以提高工作效率并实现更高的灵活性和可适应性 -
Maestro的引入为解决复杂任务提供了新的可能性
标签:GitHub Repo, Maestro, Claude Opus
原文链接见文末/4[4]
5. 支持在浏览器WebGPU上运行的Florence 2模型
Florence 2是一个小型视觉模型,完全基于onnx和WebGPU在浏览器中运行。WebGPU是一种新型的Web标准,为Web应用程序提供高效的低级图形和计算功能。这种模型旨在帮助开发者更好地理解和利用WebGPU的性能优势。Onnx则是一个开放的模型格式,可以帮助优化机器学习的生态系统。这个模型的运行完全不需要服务器支持,可以在用户的浏览器上进行所有的运算,大大增加了用户体验的便利性和安全性。
划重点
-
Florence 2是一个基于onnx和WebGPU的小型视觉模型 -
Florence 2模型旨在帮助开发者更好地理解和利用WebGPU -
Florence 2模型的运行完全不需要服务器支持,可以在用户浏览器上进行
标签:WebGPU, onnx, Florence 2
原文链接见文末/5[5]
6. 法国实验室Kyutai Moshi研发出低延迟的纯音频LLM
Kyutai,一家法国的开放研究实验室,成功地训练出一款具有极低延迟的纯音频LLM。他们成功地创建了一个令人印象深刻的演示,将在未来几个月内开源。Kyutai的这项工作表明,纯音频LLM的实现并不遥不可及,只是需要在技术和实践上做出一些创新和改进。在这个演示中,Kyutai的研究团队展示了如何通过最小化延迟来提高音频LLM的性能。这对于希望在音频处理和生成领域获得更高效率和质量的开发者来说,是一项重要的创新。

划重点
-
法国开放研究实验室Kyutai成功训练出一款纯音频LLM -
通过最小化延迟,Kyutai提高了音频LLM的性能
标签:Kyutai, 音频LLM, 开源技术
原文链接见文末/6[6]
7. 面部筛查工具可在几秒钟内检测出中风
一项新颖的AI技术通过分析面部肌肉运动和对称性,使用面部表情识别来检测中风。这项技术的开发是为了提高中风的早期发现和治疗,从而减少患者的痛苦和死亡率。通过使用AI技术分析患者的面部表情,我们能够快速准确地识别中风的迹象,避免了传统的医学检查带来的延误。此外,这种方法还能够帮助医生更加精确地诊断和治疗中风,提高患者的生活质量。

划重点
-
新颖的AI技术通过分析面部肌肉运动和对称性,使用面部表情识别来检测中风 -
这种方法还能够帮助医生更加精确地诊断和治疗中风,提高患者的生活质量
标签:AI, 健康科技, 中风检测
原文链接见文末/7[7]
8. 论文:CELLO-增强因果理解的全新数据集
CELLO是一种全新的数据集,包含了14,094个因果问题,旨在提升AI对因果关系理解的能力,超越了常识推理的层次。这个数据集的构建,旨在推动AI技术在处理更复杂问题时,具有更深沉的因果关系理解。由此,可以有效提升机器学习模型在面对复杂问题推理时的准确性,也能帮助AI能够更好地理解和解释世界,提升其实用性。CELLO的推出,标志着AI研究在因果推理领域的新里程碑,预示着AI将在未来的各种应用场景中,展现出更强大的因果关系理解能力。
划重点
-
CELLO是一种全新的数据集,包含了14,094个因果问题 -
CELLO旨在提升AI对因果关系理解的能力,超越了常识推理的层次 -
CELLO的推出,标志着AI研究在因果推理领域的新里程碑
标签:AI, 因果理解, 数据集
原文链接见文末/8[8]
9. PTQ4SAM:用后训练量化使SAM更实用
PTQ4SAM是一个新的框架,旨在减少大规模Segment Anything Model(SAM)的内存和计算需求。SAM是一个全新的大规模模型,但其大规模的特性也使得其在实际应用中面临着严峻的挑战,尤其是在内存和计算资源上的需求。而PTQ4SAM就是针对这个问题提出的解决方案。通过后训练量化,PTQ4SAM能够有效降低SAM模型的内存和计算需求,使其在实际应用中更加实用。PTQ4SAM的出现,对于推动SAM模型的实用化进程,无疑具有重要的意义。
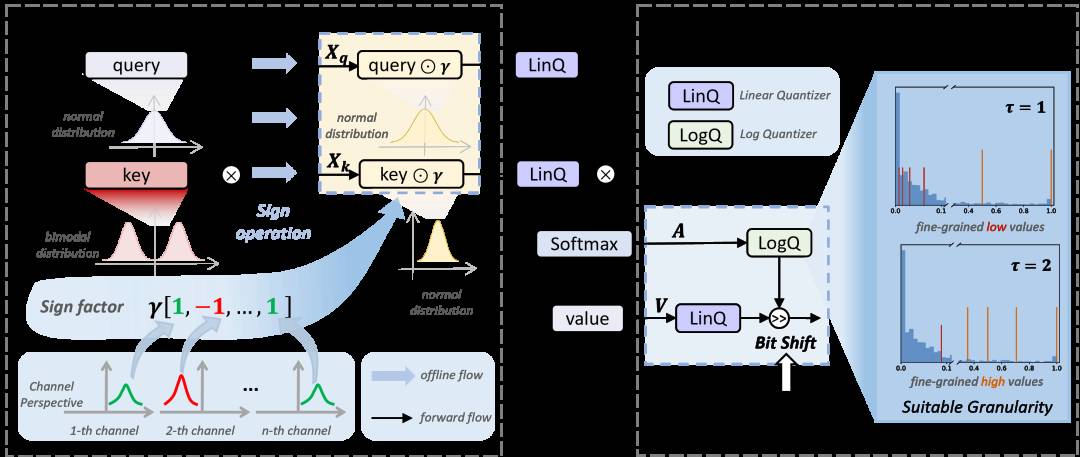
划重点
-
PTQ4SAM是一个新的框架,旨在减轻大规模Segment Anything Model(SAM)的内存和计算压力。 -
后训练量化可以有效降低SAM模型的内存和计算需求,使其在实际应用中更加实用。 -
PTQ4SAM对于推动SAM模型的实用化进程具有重要意义。
标签:SAM, PTQ4SAM, 后训练量化
原文链接见文末/9[9]
10. SEMamba:一种基于Mamba状态空间模型的语音增强系统
SEMamba是一款全新的语音增强系统,它利用了Mamba状态空间模型来提高语音信号的清晰度。这款语音增强系统的主要目标是通过去噪和清晰的语音信号处理,来提高人们的语音识别和理解。SEMamba系统具有高度的灵活性,能够适应各种不同的环境和语音信号。通过这种技术,人们可以更好地理解和分析语音信号,从而在语音识别、助手机器人、语音转录等领域得到广泛的应用。尽管这是一种新的技术,但它的潜力和应用前景十分广阔。
划重点
-
SEMamba是一款新的语音增强系统,利用Mamba状态空间模型提高语音信号清晰度 -
SEMamba系统具有高度灵活性,能适应各种环境和语音信号 -
SEMamba在语音识别、助手机器人、语音转录等领域有广泛应用前景
标签:语音增强, SEMamba, Mamba状态空间模型
原文链接见文末/10[10]
每日AIGC
如果觉得内容有帮助,欢迎分享转发有需要的朋友。如果想第一时间跟踪AI前沿或者交个朋友,也可扫码添加微信(还请备注来意)。

👉关注「漫话开发者」,精选全球AI前沿科技资讯以及高质量AI开源工具,帮你给每天AI前沿划重点!👀
– END –
参考资料
原文链接见文末/1: https://github.com/gastruc/osv5m?utm_source=uwl.me
[2]原文链接见文末/2: https://y-ichen.github.io/FlexiFilm-Page/?utm_source=uwl.me
[3]原文链接见文末/3: https://github.com/OpenAutoCoder/Agentless?utm_source=uwl.me
[4]原文链接见文末/4: https://github.com/Doriandarko/maestro?utm_source=uwl.me
[5]原文链接见文末/5: https://github.com/xenova/transformers.js/tree/v3/examples/florence2-webgpu?utm_source=uwl.me
[6]原文链接见文末/6: https://kyutai.org/cp_moshi.pdf?utm_source=uwl.me
[7]原文链接见文末/7: https://www.rmit.edu.au/news/all-news/2024/june/stroke-face-screening?utm_source=uwl.me
[8]原文链接见文末/8: https://arxiv.org/abs/2406.19131v1?utm_source=uwl.me
[9]原文链接见文末/9: https://github.com/chengtao-lv/ptq4sam?utm_source=uwl.me
[10]原文链接见文末/10: https://arxiv.org/abs/2405.06573v1?utm_source=uwl.me