
包阅导读总结
1. 关键词:生成式 AI、个性化营销、内容创作、工作流程、客户数据
2. 总结:
本文探讨了利用生成式 AI 实现更个性化营销内容创作的工作流程,指出个性化和规模曾相互排斥,生成式 AI 改变了这一现状,还介绍了相关工作流程及实践中的经验教训。
3. 主要内容:
– 个性化营销现状与生成式 AI 的作用
– 历史上个性化和规模难以兼顾,生成式 AI 降低内容创作成本,使大规模定制内容成为可能。
– 生成式 AI 个性化营销内容创作工作流程
– 所需条件:受众细分和属性、营销内容中央存储库、生成式 AI 模型。
– 步骤:从 CDP 导入客户数据到数据湖屋、探索客户细分、总结细分、设计提示并测试、生成产品描述变体。
– 实践中的经验教训
– 需人工创建提示和审核模型输出以获得高质量内容。
– 随着技术发展,有望实现更自动化和高效的个性化营销。
思维导图: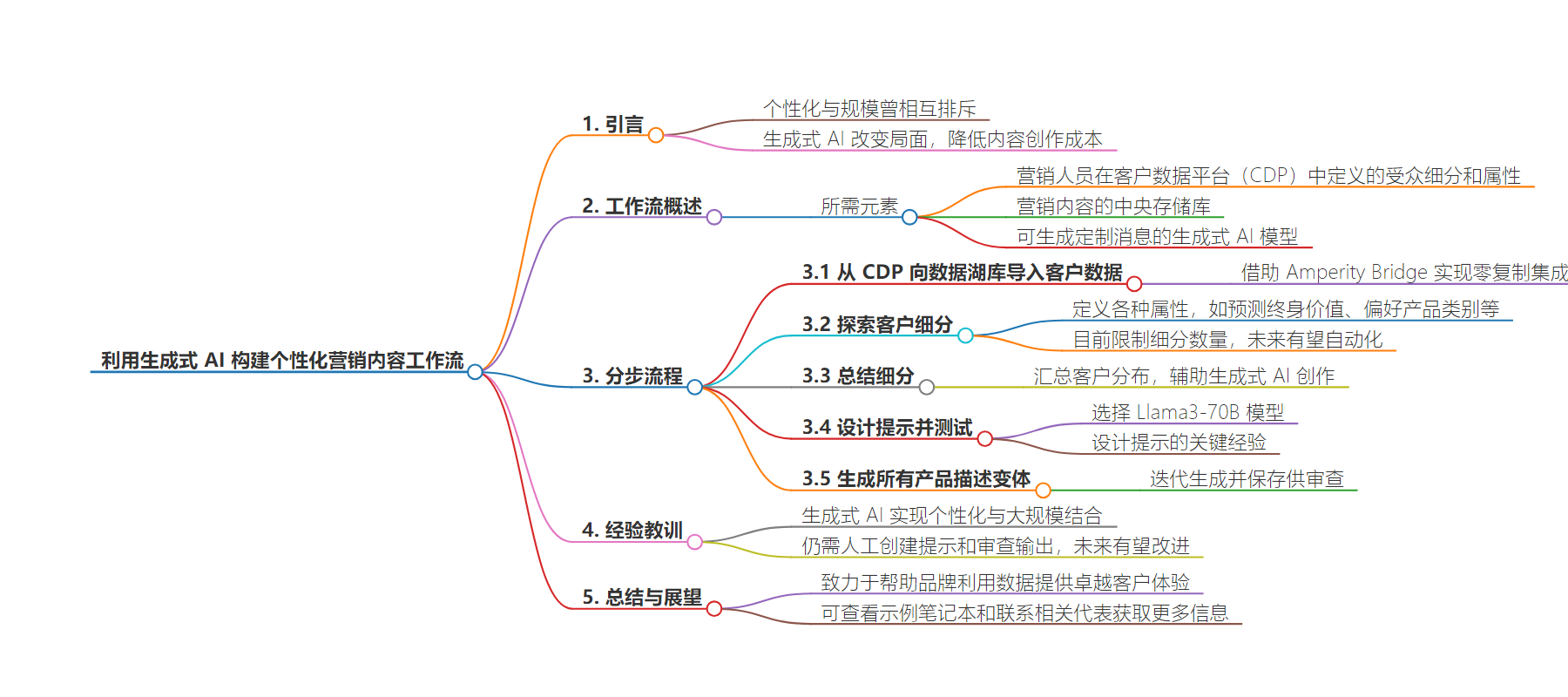
文章来源:databricks.com
作者:Databricks
发布时间:2024/9/9 10:45
语言:英文
总字数:1446字
预计阅读时间:6分钟
评分:84分
标签:生成式 AI,营销内容个性化,Databricks,Amperity 客户数据平台,AI 工作流程
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Personalization and scale have historically been mutually exclusive. For all the talk of one-to-one marketing and hyper-personalization, the reality has been that we were always limited by how much marketing content we could create. Personalization often meant tailoring content for groups of tens of thousands or hundreds of thousands of customers due to the limited bandwidth of marketers. Generative AI changes that, driving down the cost of content creation and making tailored content at scale a reality.
To help bring that to life, we’ll share with you a simple workflow that takes a standard unit of content – in this case a product description – and customizes it based on customer preferences and traits. While our initial approach customizes by segment and is therefore still not truly one-to-one, there is clear potential to create even finer-grained content variants, and soon we expect to see more and more marketing teams using approaches like these to create tailored email subject lines, SMS copy, web experiences, and more.
This workflow requires:
- audience segments and attributes as defined by our marketers within their customer data platform (CDP),
- a central repository of marketing content
- access to a generative AI model that will create customized messaging
For this demonstration, we will make use of the Amperity CDP where data is exposed to the Databricks lakehouse architecture in a zero-copy manner. This allows seamless integration between customer information like marketing segment definitions with both product descriptions and generative AI capabilities available through the Databricks Platform. Using these elements, we will create segment-aligned product description variants, demonstrating the potential of generative AI to combine these data to create unique and compelling content.
A Step-by-Step Walkthrough
Let’s imagine an ecommerce platform presenting product descriptions on a website or in a mobile app. Each description has been carefully crafted by our merchandising teams with input from marketing to align the content with the general audience it’s intended to reach. But each person visiting the site or app, will see the exact same product description for these items (Figure 1).
Step 1: Import customer data from CDP to data lakehouse
Assuming we have copies of these product descriptions in the Databricks Platform, we need a means to access the customer data from our CDP. Assuming our company makes use of the Amperity CDP, we can easily access this data via Amperity Bridge which uses the open source Delta Sharing protocol supported by Databricks to enable a zero-copy integration between the two platforms.
Performing a few simple configuration steps, we can now access Amperity CDP data from within the Databricks Data Intelligence Platform(Figure 2).
Step 2: Explore customer segments
Each marketing team will approach segment design differently, but here we have attributes defined around predicted lifetime value, preferred product categories and subcategories, price preferences, discount sensitivities and geographic location. The number of unique values across all these fields will result in tens of thousands of possible combinations, potentially more (Figure 3).
While we might create a variant for each of these combinations, we expect that most marketing teams will want to carefully review any generated content before it goes in front of customers. Over time, as organizations become more familiar with the technology, and techniques around it evolve to ensure consistent generation of content that’s high-quality and trustworthy, we expect this human-in-the-loop approach to become fully automated. But for now, we’ll limit our efforts to 14 variants created from the intersection of preferred product subcategories (as a surrogate for customer interest) and predicted value tier (as a proxy for brand loyalty).
Step 3: Summarize segments
Each of our 14 segments combines individual customers from across various lifetime value tiers, discount sensitivities, geographic locations, etc. To help the generative AI craft compelling content, we might summarize the distribution of customers across these elements. This is an optional step, but should we discover for example that a significant proportion of customers in one segment is from a particular geographic region or has a strong discount sensitivity, the generative AI model might use this information to create content more aligned with that information (Figure 4).
Step 4: Design prompt and test
Next we will design a prompt for a large language model that will generate your personalized descriptions. We’ve elected to use the Llama3-70B mode model which accepts a general instruction, i.e. system prompt, and supporting information, i.e. content. As can be seen in Figure 5, our prompt incorporates segment information into a whole lot of detailed instruction and supplies the general product description as part of the prompt’s content.
Clearly, this prompt was not created in one go. Instead, we used the Databricks AI Playground to explore various models and prompts until we arrived at something that produced satisfactory results. Some key lessons learned through this exercise were:
- Make clear in the prompt the role you wish the model to play, e.g. “You are a sales associate at a store.”
- Provide concrete guidance on how to use information about any data you provide such as the distribution information for the segment, e.g. “Your job is to use information from {segment_description} to tailor the generic product description.”
- Include course corrections when necessary. For example, we added in “You are writing copy for the entire segment.” Before adding in this stipulation, the AI was producing things like “As a cyclist and a New Yorker” when not all customers in the segment live in New York, even though the segment might skew that way.
Step 5: Generate all product description variants
Now that all the building blocks are in place, we can generate variants for each of our segments by simply iterating over each description and segment combination. With a small set of descriptions and segments, this is reasonably quick to perform. If we have a large number of combinations, we might consider parallelizing the work using a more robust batch inference technique for generative AI models available through Databricks. Either way, the generated description variants are persisted to a table for review (Figure 6).
With the custom descriptions generated, it’s important to have someone with a good eye and ear for marketing copy review the output. There’s no easy way to quantify the accuracy or performance of the LLM in generating high quality results. Someone simply needs to review the copy to verify it’s producing appropriate results. If the copy isn’t just right, altering the prompt and regenerating the descriptions is required.
It’s important to note that in our prompt, we requested the model provide an explanation for the copy it created. You will find a **Rationale** marker within most of the descriptions that delineates the generated result and this explanation. The explanation would not typically be presented to a customer but may be useful to include in the results until you arrive at consistently good output from the model.
Lessons learned
This exercise is an important demonstration of the potential of generative AI to take us toward a truly hyper-personalized marketing future.
AI brings together for the first time personalized interactions and massive scale. Using detailed information about a customer, we now have the potential to truly tailor content to the individual, leveraging generative AI to achieve the scale we couldn’t access in the past.
Getting the generative AI models to create high-quality, trustworthy content still requires human effort both in the creation of the prompts and the review of model outputs. Today, this limits the scale at which we can apply these approaches, but we expect to see a steady progression as more reliable models, more consistent prompting techniques, and new evaluation approaches more fully unlock the potential demonstrated here.
At both Amperity and Databricks, we are committed to helping brands use data to deliver exceptional customer experiences. Through our partnership, we look forward to progressing the adoption of analytics to drive more effective marketing engagement with our mutual users.
If you’d like to see more details behind the demonstration addressed in this blog, please review the sample notebook capturing the programmatic details of the work performed here. To learn more about how you can integrate your CDP with the generative AI capabilities in the lakehouse, reach out to your Amperity and Databricks representatives.