
包阅导读总结
1. 关键词:Spanner、ANN 搜索、Vector Search、ScaNN、高效支持
2. 总结:Spanner 现支持近似最近邻(ANN)搜索,此功能适用于大规模非分区工作负载,具有规模、速度、操作简单、结果一致等优势,利用了 Google 高效算法 ScaNN,并介绍了在 Spanner 中执行 ANN 的方式。
3. 主要内容:
– Spanner 支持向量搜索技术,用于在大型数据集中查找相似项,在处理非结构化数据时有用,对生成式 AI 应用有重要作用。
– 精确 k 近邻(KNN)向量搜索适用于高分区负载,如今推出的 ANN 搜索适用于大规模非分区工作负载。
– ANN 搜索的优势包括规模和速度快、操作简单、一致性好。
– Spanner 利用 ScaNN 算法,包括将嵌入聚类为树状结构、量化原始向量嵌入、优化距离计算等优化。
– 在 Spanner 中执行 ANN 需用标准 SQL DDL 创建向量索引,指定搜索树形状和距离类型,树的形状根据数据集大小可为两级或三级。
思维导图: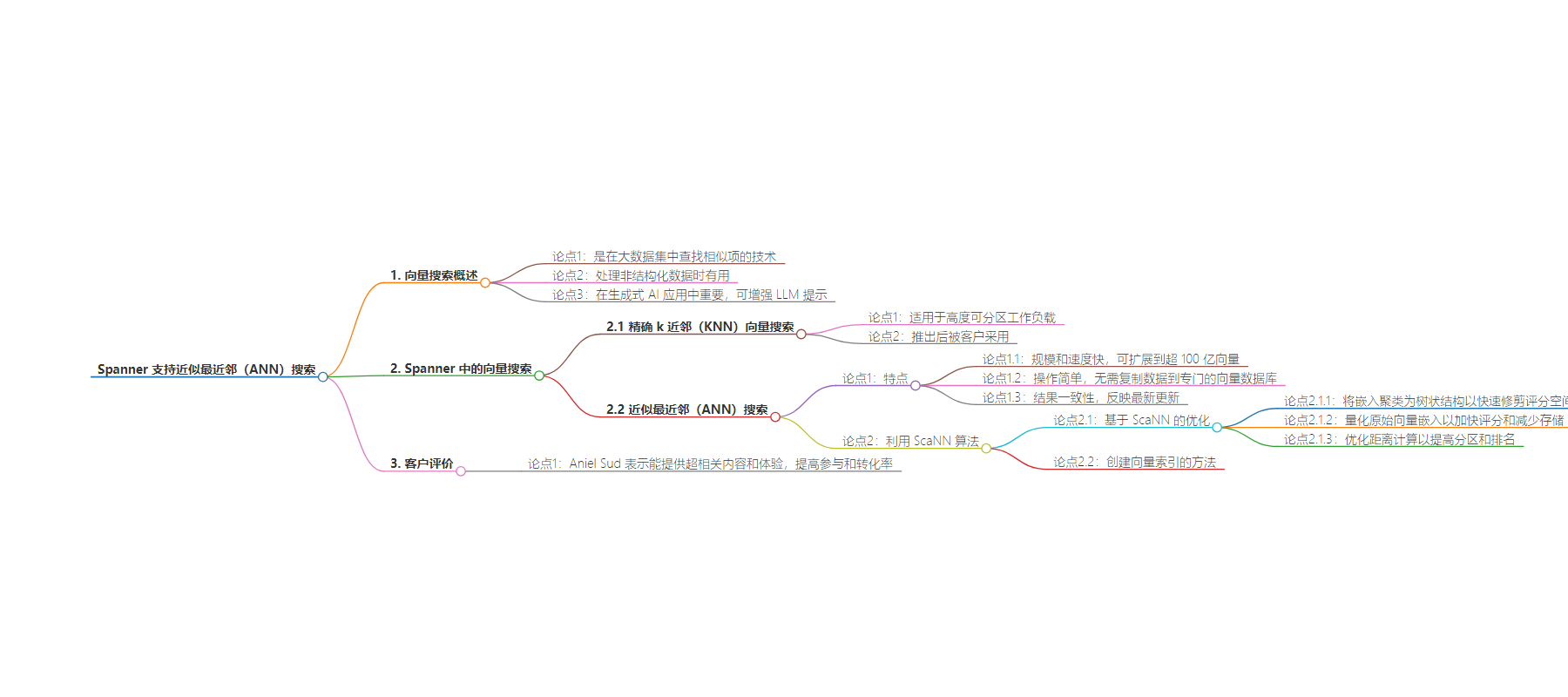
文章来源:cloud.google.com
作者:Zhiyan Liu
发布时间:2024/8/8 0:00
语言:英文
总字数:1400字
预计阅读时间:6分钟
评分:93分
标签:向量搜索,近似最近邻 (ANN),Google Cloud Spanner,ScaNN,生成式 AI
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Vector search is a technique used to find items that are similar to a given query item within a large dataset. It’s particularly useful when dealing with unstructured data like images, text, or audio, where traditional search methods (based on exact matches) might not be as effective. Vector search plays a crucial role in generative AI applications because it can also be used to enhance large language model (LLM) prompts, increasing relevance and reducing hallucinations. Having this functionality built into a general-purpose database means you will have scalable vector search capabilities integrated directly into your operational database, without the need to manage a separate database or ETL pipeline.
Spanner exact k-nearest neighbor (KNN) vector search, currently in preview, is a great fit for highly partitionable workloads such as searching through personal photos, where the number of entities involved in each query is relatively small. Since we launched KNN vector search earlier this year, it has seen increased adoption by Spanner customers. And now, for large-scale unpartitioned workloads, you can take advantage of approximate nearest neighbor (ANN) search in Spanner, delivering:
-
Scale and speed: fast, high-recall search scaling to more than 10B vectors
-
Operational simplicity: no need to copy your data to a specialized vector DB
-
Consistency: the results are always fresh, reflecting the latest updates
With the addition of ANN search capabilities, Spanner is ready to provide highly scalable and efficient support for your vector search needs. But don’t take our word for it, hear what our customers are saying:
“By leveraging the power of semantic understanding provided by Spanner’s vector search, we’re looking to deliver hyper-relevant content and experiences to our customers, resulting in increased engagement and conversion rates.” – Aniel Sud, Chief Technology Officer, Optimizely
Using ANN
Let us walk you through the details of the innovations in Spanner that deliver vector search at scale.
Spanner leverages ScaNN (Scalable Nearest Neighbors), Google Research’s highly efficient vector similarity search algorithm, which is an integral part of Google and Google Cloud applications. The main ScaNN-based optimizations that are now in Spanner include:
-
Cluster embeddings into a tree-like structure for fast query time pruning of the scoring space, trading accuracy for significant performance boost
-
Quantized raw vector embeddings to speed up scoring and reduce storage
-
Optimized distance calculation by focusing on the most relevant parts of the vectors, improving partitioning and ranking for better recall
To perform ANN in Spanner, you need to create a vector index on vector embeddings using standard SQL DDL, specifying the search tree shape and a distance type.
Tree shape
Depending on the dataset size, the tree can be two- or three-level. Three-level trees have an extra layer of branch nodes between the root and leaves, providing hierarchical partitioning that scales to 10B+ vector datasets. Representatives of the leaf partitions, called centroids, which themselves are also embeddings, are calculated and stored in the root and branch nodes.