
包阅导读总结
1. 关键词:
– Wesfarmers Health
– Amazon SQS FIFO
– Serverless Technologies
– Consent Capture
– Upstream Event Buffering
2. 总结:
本文介绍了 Wesfarmers Health 如何利用 Amazon SQS FIFO 和相关技术解决上游事件缓冲问题,以确保用户同意捕获的准确性和合规性,还阐述了选择无服务器服务的原因,最后提供了示例架构和相关资源。
3. 主要内容:
– 背景
– SaaS 应用广泛,但集成可能带来新要求。
– 问题
– Wesfarmers Health 捕获用户同意时,集成选项不支持有序保证和恰好一次处理。
– 分析了可能出现错误顺序和多次处理事件的场景。
– 解决方案
– 采用 Amazon SQS FIFO 队列,保证顺序和恰好一次处理。
– 利用消息组 ID 并行处理用户。
– 使用 Amazon DynamoDB 表缓冲消息,记录处理的时间戳。
– 由 AWS Lambda 函数根据 DynamoDB 表决定处理或延迟消息。
– 架构
– 展示了最终的高层架构图。
– 选择无服务器服务原因
– 团队战略倾向,可专注业务成果。
– 按需付费,适合请求波动的情况。
– 结论与后续
– SaaS 集成很关键,可利用 AWS 服务构建适合的模式。
– 提供了设置此架构的资源供查看和修改。
思维导图: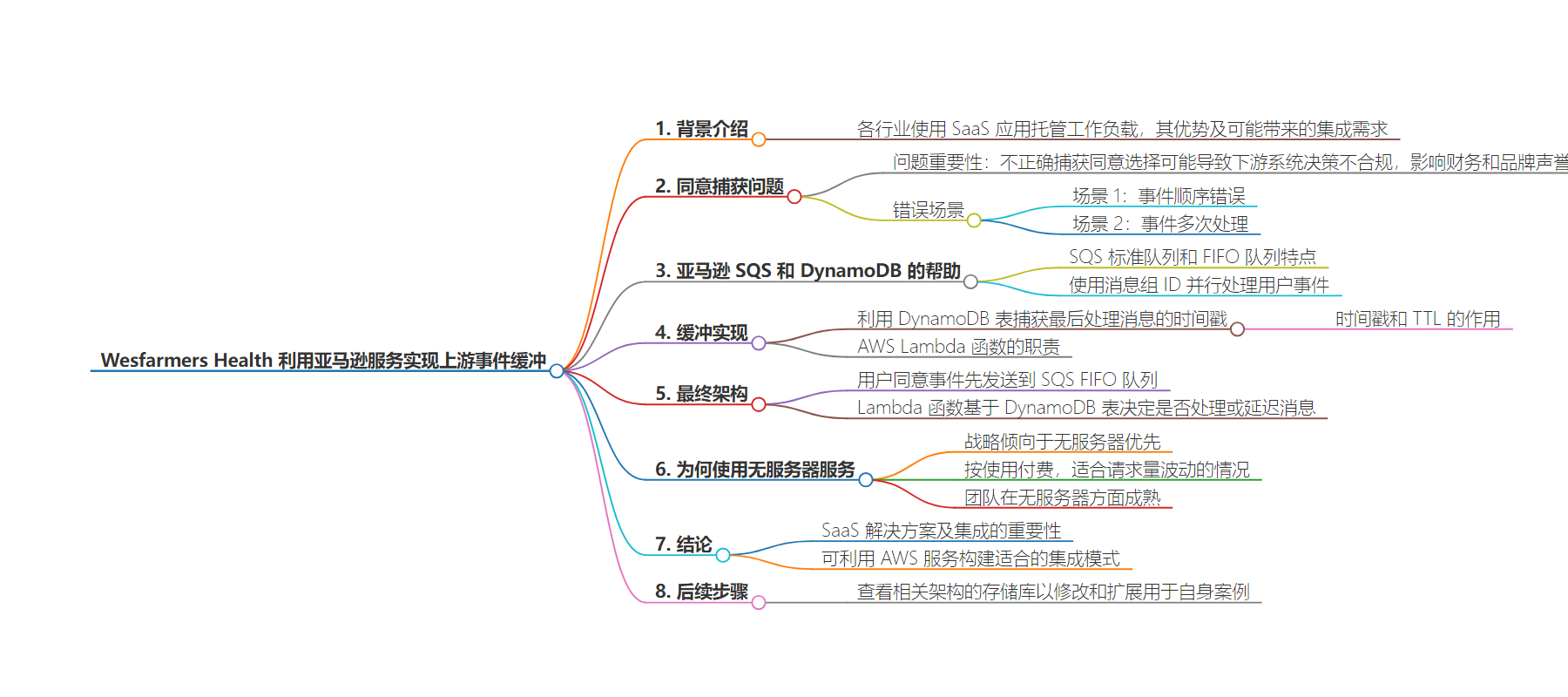
文章来源:aws.amazon.com
作者:Robbie Cooray
发布时间:2024/8/22 10:50
语言:英文
总字数:1138字
预计阅读时间:5分钟
评分:85分
标签:SaaS 集成方案,Amazon SQS FIFO 队列,Amazon DynamoDB,无服务器体系结构,AWS Lambda
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Customers of all sizes and industries use Software-as-a-Service (SaaS) applications to host their workloads. Most SaaS solutions take care of maintenance and upgrades of the application for you, and get you up and running in a relatively short timeframe. Why spend time, money, and your precious resources to build and maintain applications when this could be offloaded?
However, working with SaaS solutions can introduce new requirements for integration. This blog post shows you how Wesfarmers Health was able to introduce an upstream architecture using serverless technologies in order to work with integration constraints.
At the end of the post, you will see the final architecture and a sample repository for you to download and adjust for your use case.
Let’s get started!
Consent capture problem
Wesfarmers Health used a SaaS solution to capture consent. When capturing consent for a user, order guarantee and delivery semantics become important. Failure to correctly capture consent choice can lead to downstream systems making non-compliant decisions. This can end up in penalties, financial or otherwise, and might even lead to brand reputation damage.
In Wesfarmers’ case, the integration options did not support a queue with order guarantee nor exactly-once processing. This meant that, with enough load and chance, a user’s preference might be captured incorrectly. Let’s look at two scenarios where this could happen.
In both of these scenarios, the user makes a choice, and quickly changes their mind. These are considered two discreet events:
- Event 1 – User confirms “yes.”
- Event 2 – User then quickly changes their mind to confirm “no.”
Scenario 1: Incorrect order
In this scenario, two events end up in a queue with no order guarantee. Event 2 might be processed before Event 1, so although the user provided a “no,” the system has now captured a “yes.” This is now considered a non-compliant consent capture.
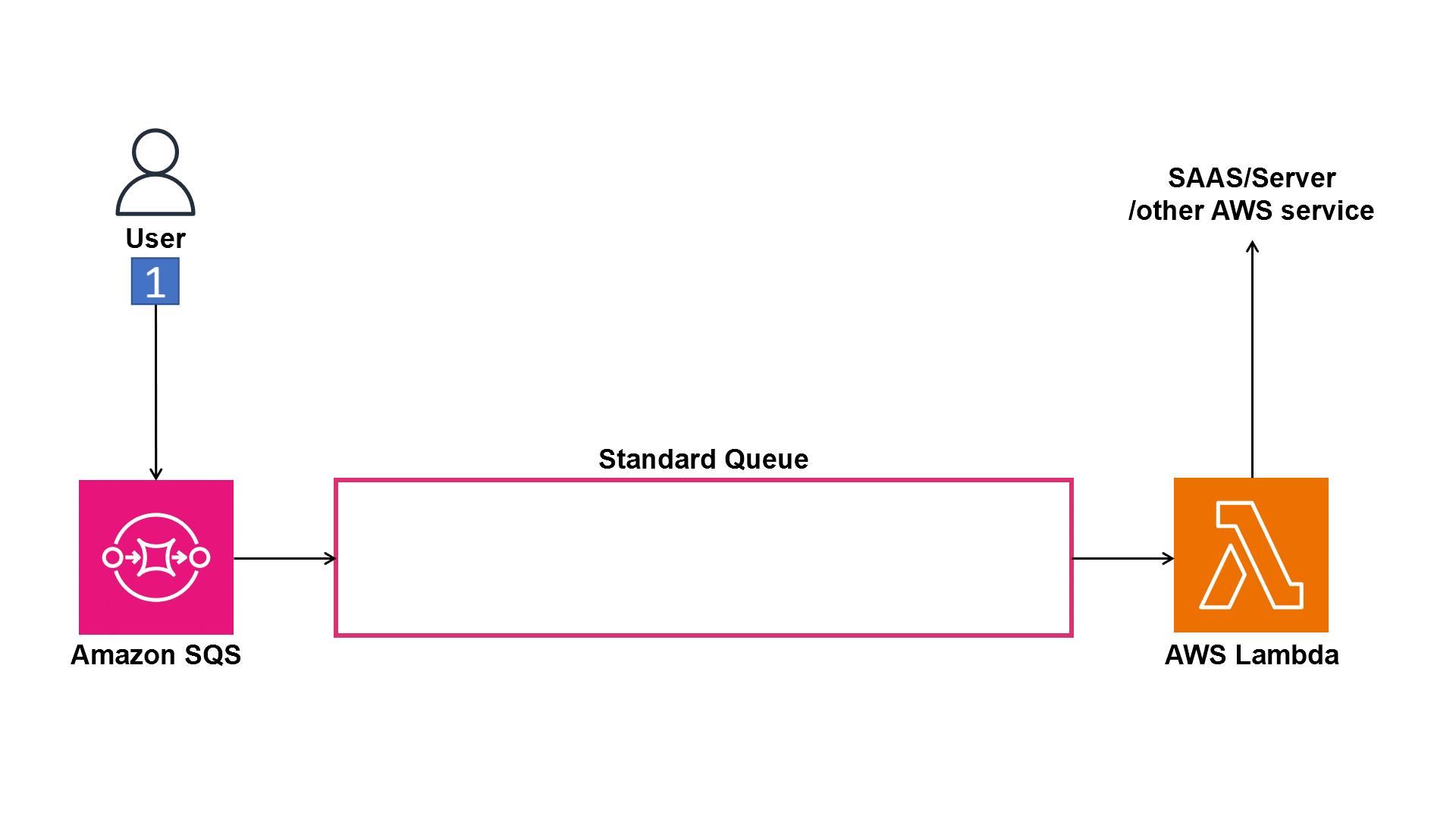
Figure 1. Animation showing messages processed in the wrong order
Scenario 2 – events processed multiple times
In this scenario, perhaps due to the load, Event 1 was transmitted twice, once before and once after Event 2, due to at least once processing. In this scenario, the user’s record could be updated three times, first with Event 1 with “yes,” then Event 2 with “no,” then again with retransmitted Event 1 with “yes,” which ultimately ends up with a “yes,” also considered a non-compliant consent capture.
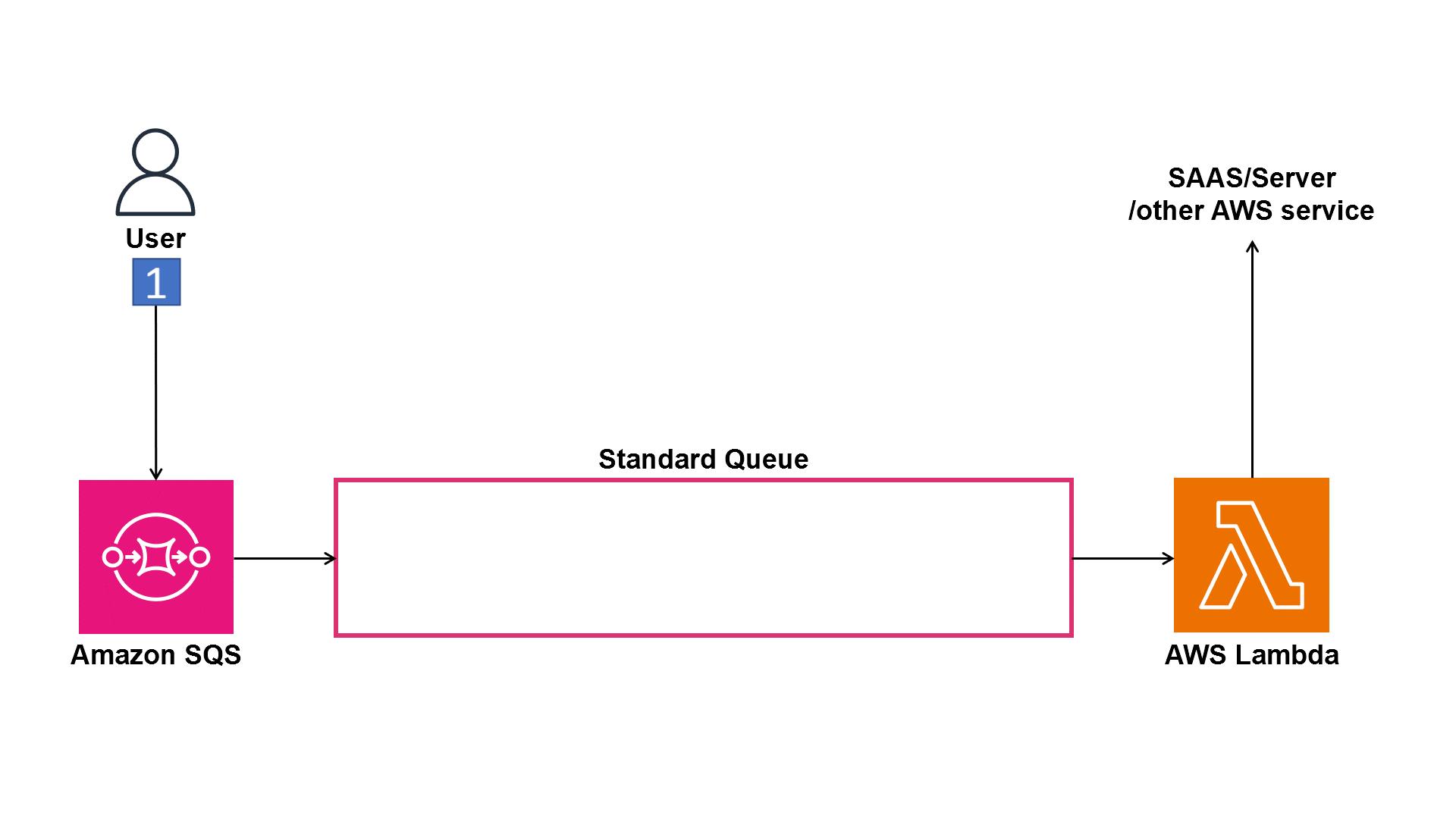
Figure 2. Animation showing messages processed multiple times
How did Amazon SQS and Amazon DynamoDB help with order?
With Amazon Amazon Simple Queue Service (Amazon SQS), queues come in two flavors: standard and first-in-first-out (FIFO). Standard queues provide best effort ordering and at-least once processing with high throughput, whereas FIFO delivers order and processes exactly once with relatively low throughput, as shown in Figure 3.
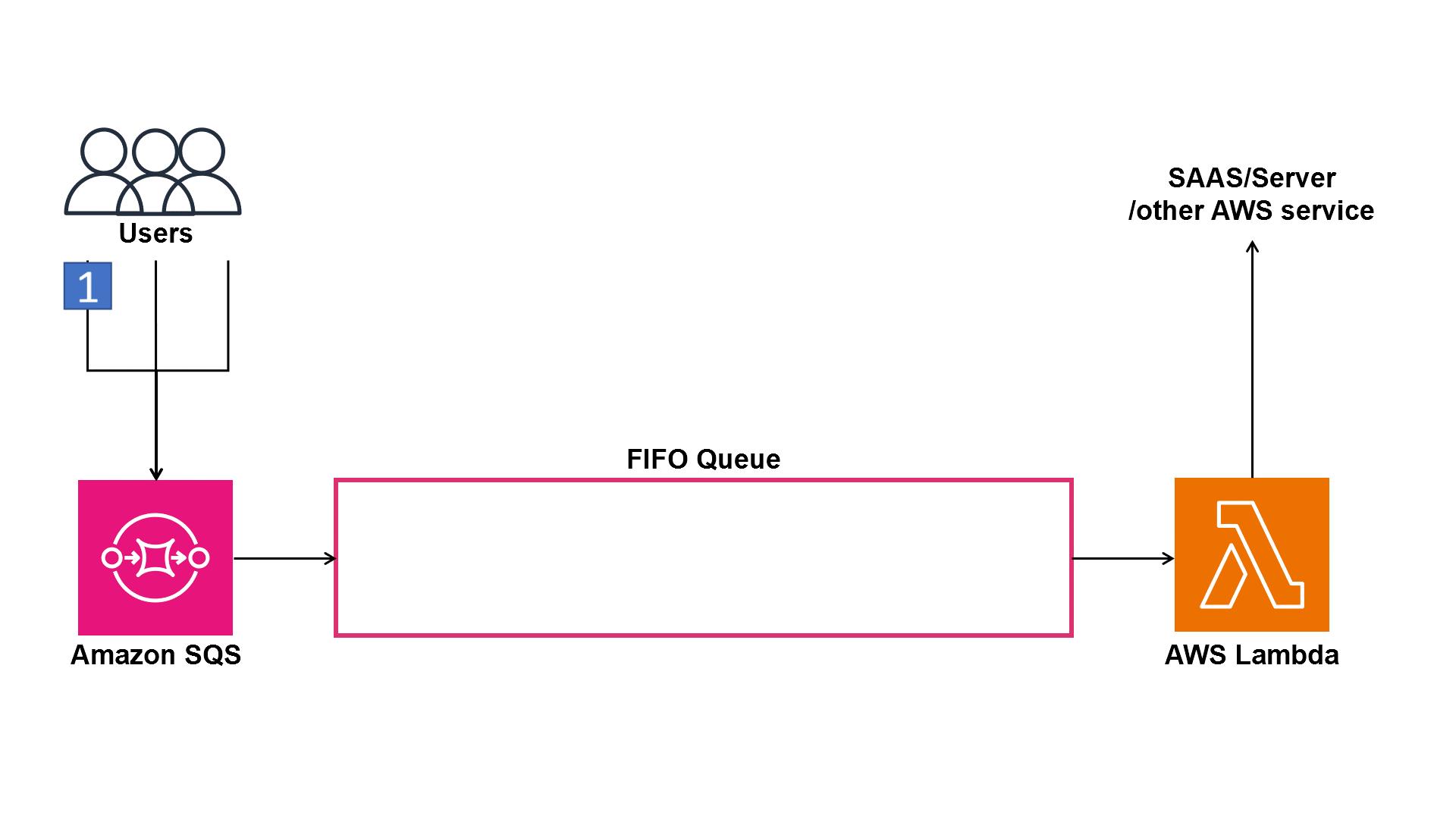
Figure 3. Animation showing FIFO queue processing in the correct order
In Wesfarmers Health’s scenario with relatively few events per user, it made sense to deploy a FIFO queue to deliver messages in the order they arrived and also have them delivered once for each event (see more details on quotas at Amazon SQS FIFO queue quotas).
Wesfarmers Health also employed the use of message group IDs to parallelize all users using a unique userID. This means that they can guarantee order and exactly-once processing at the user level, while processing all users in parallel, as shown in Figure 4.
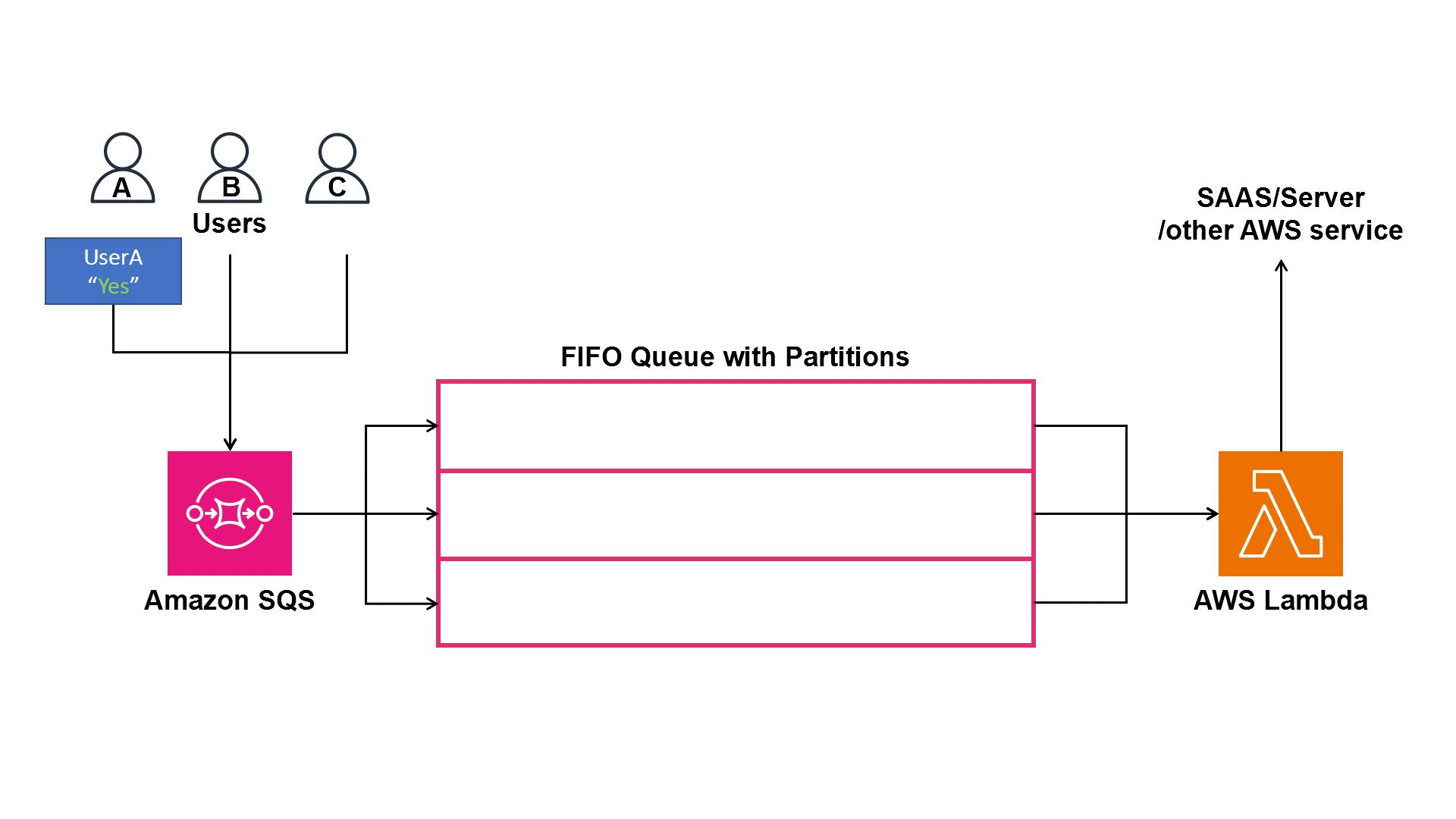
Figure 4. Animation showing a FIFO queue partitioned per user, in the correct order per user
The buffer implementation
Wesfarmers Health also opted to buffer messages for the same user in order to minimize race conditions. This was achieved by employing an Amazon DynamoDB table to capture the timestamp of the last message that was processed. For this, Wesfarmers Health designed the DynamoDB table shown in Figure 5.
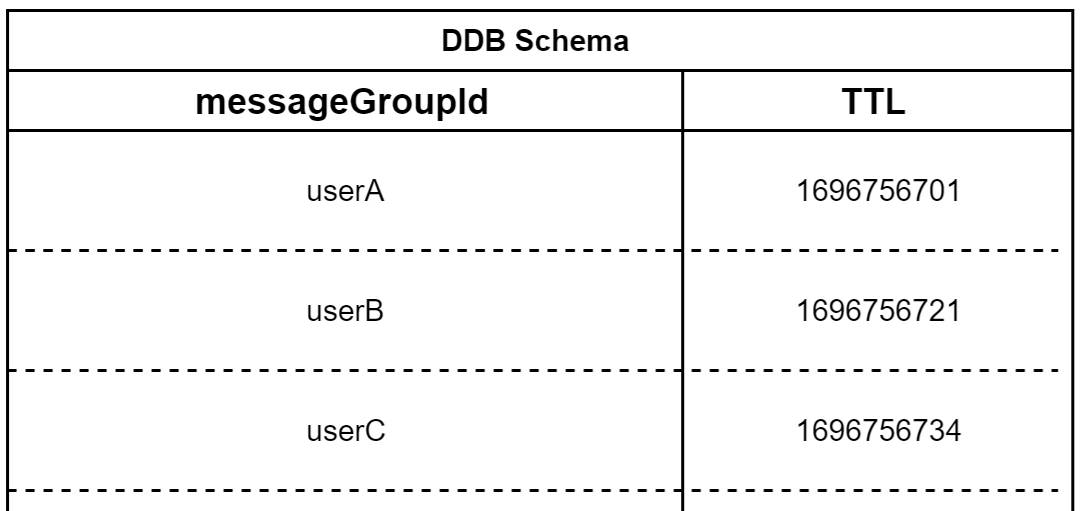
Figure 5. Example DynamoDB schema with messageGroupId based on user, and TTL
The messageGroupId value corresponds to a unique identifier for a user. The time-to-live (TTL) value serves dual functions. First, the TTL is the value of the Unix timestamp for the last time a message from a specific user was processed, plus the desired message buffer interval (for example, 60 seconds). It also serves a secondary function of allowing DynamoDB to remove obsolete entries to minimize table size, thus improving cost for certain DynamoDB operations.
In between the Amazon SQS FIFO queue and the Amazon DynamoDB table sits an AWS Lambda function that listens to all events and transmits to the downstream SaaS solution. The main responsibility of this Lambda function is to check the DynamoDB table for the last processed timestamp for the user before processing the event. If, by chance, a user event for the user was already processed within the buffer interval, then that event is sent back to the queue with a visibility timeout that matches the interval, so that the user events for that user is not processed until the buffer interval is passed.
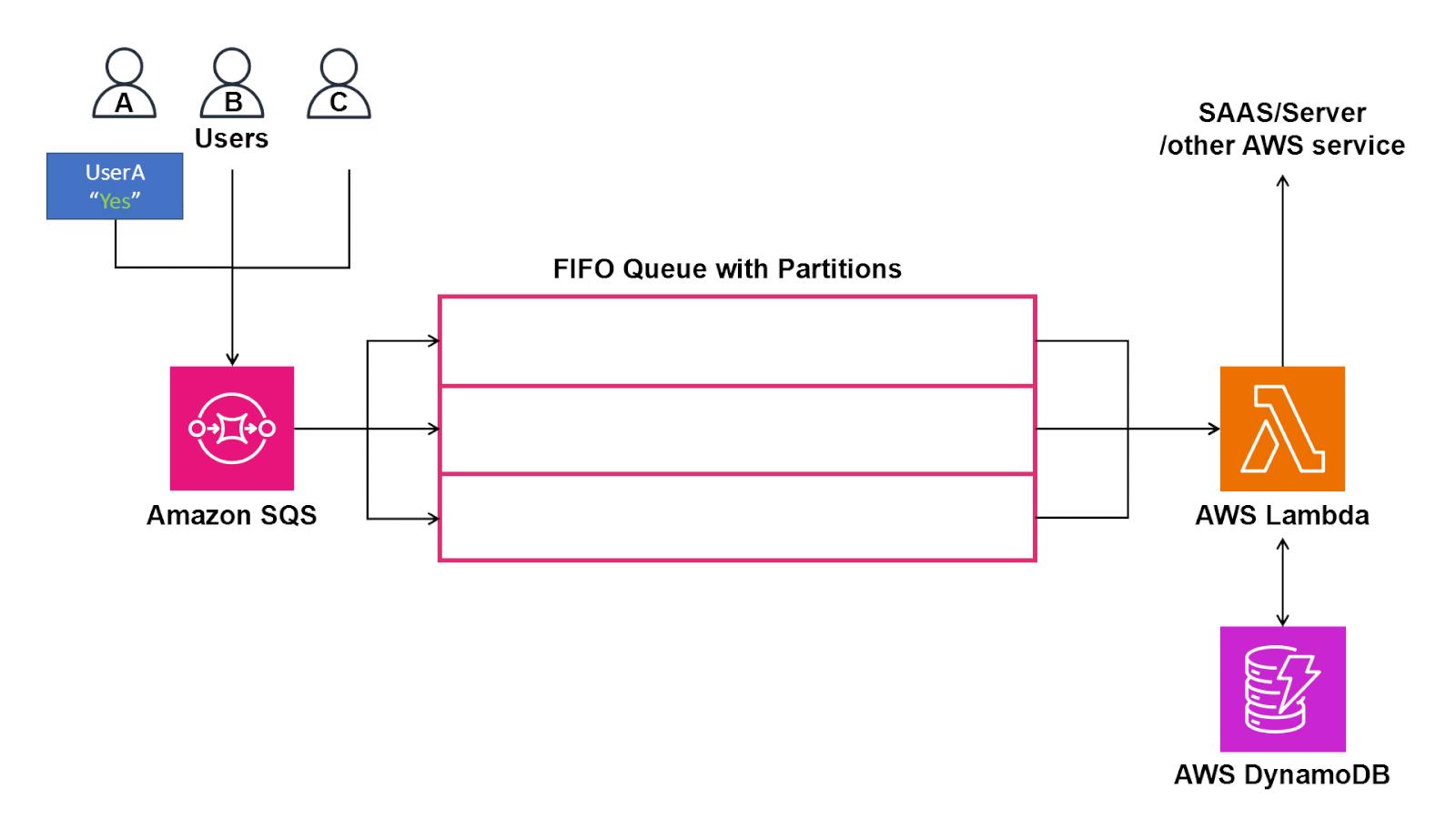
Figure 6. Amazon DynamoDB table and AWS Lambda function introducing the buffer
Final architecture
Figure 7 shows the high-level architecture diagram that powers this integration. When users send their consent events, it is sent to the SQS FIFO queue first. The AWS Lambda function determines, based on the timestamp stored in the DynamoDB table, whether to process it or delay the message. Once the outcome is determined, the function passes through the event downstream.
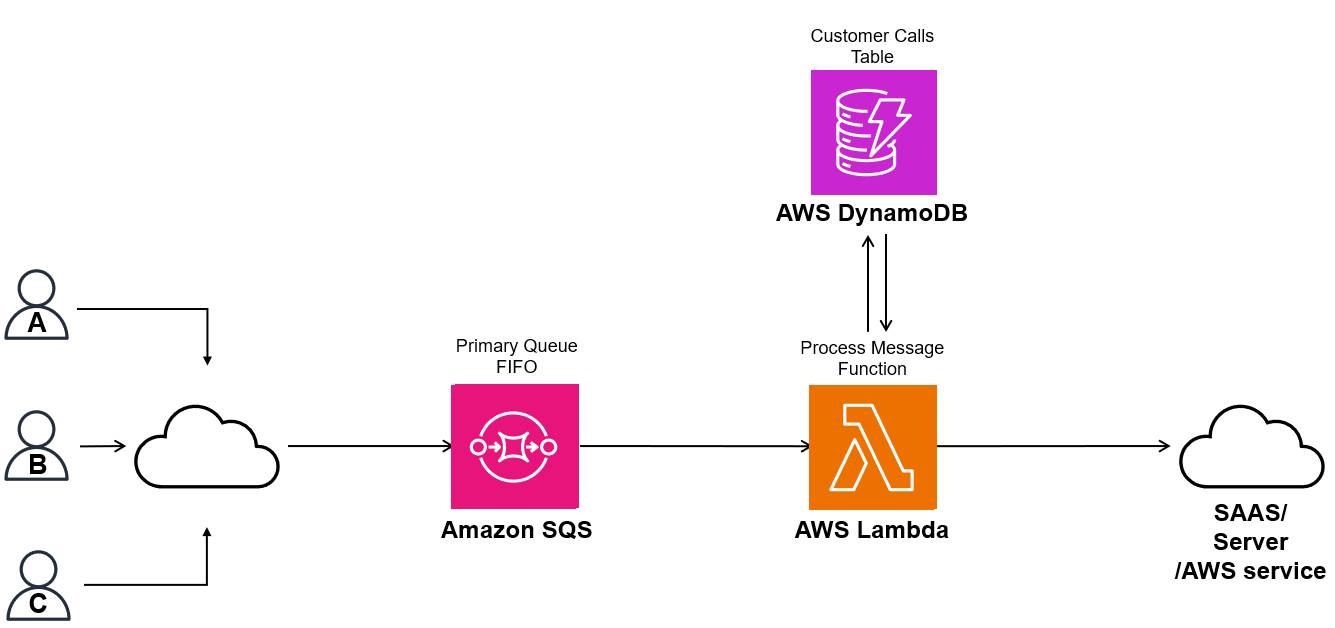
Figure 7. Final architecture diagram
Why serverless services were used
The Wesfarmers Health Digital Innovations team is strategically aligned towards a serverless first approach where appropriate. This team builds, maintains, and owns these solutions end-to-end. Using serverless technologies, the team gets to focus on delivering business outcomes while leaving the undifferentiated heavy lifting of managing infrastructure to AWS.
In this specific scenario, the number of requests for consent is sporadic. With serverless technologies, you pay as you go. This is a great use case for workloads that have requests fluctuate throughout the day, providing the customer a great option to be cost efficient.
The team at Wesfarmers Health has been on the serverless journey for a while, and are quite mature in developing and managing these workloads in a production setting using best practices mentioned above and employing the AWS Well Architected Framework to guide their solutions.
Conclusion
SaaS solutions are a great mechanism to move fast and reduce the undifferentiated heavy lifting of building and maintaining solutions. However, integrations play a crucial part as to how these solutions work with your existing ecosystem.
Using AWS services, you can build these integration patterns that is fit for purpose, for your unique requirements.
AWS Serverless Patterns is a great place to get started to see what other patterns exist for your use case.
Next steps
Check out the repository hosted on AWS Patterns that sets up this architecture. You can review, modify, and extend it for your own use case.