
包阅导读总结
1. 关键词:Bot 攻击、住宅代理、机器学习、模型训练、特征检测
2. 总结:本文主要讲述利用机器学习检测利用住宅代理的 Bot 攻击,介绍了此类攻击的特点、防御难点,以及新的 Bot 管理机器学习模型的训练和特征检测方法。
3. 主要内容:
– 背景:
– Bot 利用住宅代理发动攻击让安全工程师困扰,Cloudflare 的 Bot 检测模型不断进化。
– 住宅 IP 代理:
– 允许攻击者隐藏身份和分发攻击,绕过传统防御。
– 攻击者通过住宅代理伪装成合法用户,代理提供商获取大量 IP 地址。
– ML 模型训练:
– 从 Clickhouse 数据存储获取和准备训练与验证数据集。
– 训练 Catboost 模型并调优超参数,评估新模型性能。
– 完成一系列准备检查后部署模型。
– ML 特征用于 Bot 检测:
– 基于单请求和多请求计算特征,分为全球、高基数和单请求特征。
– 通过网络和行为信号检测住宅代理。
思维导图:
文章地址:https://blog.cloudflare.com/residential-proxy-bot-detection-using-machine-learning
文章来源:blog.cloudflare.com
作者:Bob AminAzad
发布时间:2024/6/24 14:00
语言:英文
总字数:2299字
预计阅读时间:10分钟
评分:84分
标签:产品新闻,机器学习,人工智能,代理,机器人
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Bots using residential proxies are a major source of frustration for security engineers trying to fight online abuse. These engineers often see a similar pattern of abuse when well-funded, modern botnets target their applications. Advanced bots bypass country blocks, ASN blocks, and rate-limiting. Every time, the bot operator moves to a new IP address space until they blend in perfectly with the “good” traffic, mimicking real users’ behavior and request patterns. Our new Bot Management machine learning model (v8) identifies residential proxy abuse without resorting to IP blocking, which can cause false positives for legitimate users.
Background
One of the main sources of Cloudflare’s bot score is our bot detection machine learning model which analyzes, on average, over 46 million HTTP requests per second in real time. Since our first Bot Management ML model was released in 2019, we have continuously evolved and improved the model. Nowadays, our models leverage features based on request fingerprints, behavioral signals, and global statistics and trends that we see across our network.
Each iteration of the model focuses on certain areas of improvement. This process starts with a rigorous R&D phase to identify the emerging patterns of bot attacks by reviewing feedback from our customers and reports of missed attacks. In v8, we mainly focused on two areas of abuse. First, we analyzed the campaigns that leverage residential IP proxies, which are proxies on residential networks commonly used to launch widely distributed attacks against high profile targets. In addition to that, we improved model accuracy for detecting attacks that originate from cloud providers.
Residential IP proxies
Proxies allow attackers to hide their identity and distribute their attack. Moreover, IP address rotation allows attackers to directly bypass traditional defenses such as IP reputation and IP rate limiting. Knowing this, defenders use a plethora of signals to identify malicious use of proxies. In its simplest forms, IP reputation signals (e.g., data center IP addresses, known open proxies, etc.) can lead to the detection of such distributed attacks.
However, in the past few years, bot operators have started favoring proxies operating in residential network IP address space. By using residential IP proxies, attackers can masquerade as legitimate users by sending their traffic through residential networks. Nowadays, residential IP proxies are offered by companies that facilitate access to large pools of IP addresses for attackers. Residential proxy providers claim to offer 30-100 million IPs belonging to residential and mobile networks across the world. Most commonly, these IPs are sourced by partnering with free VPN providers, as well as including the proxy SDKs into popular browser extensions and mobile applications. This allows residential proxy providers to gain a foothold on victims’ devices and abuse their residential network connections.
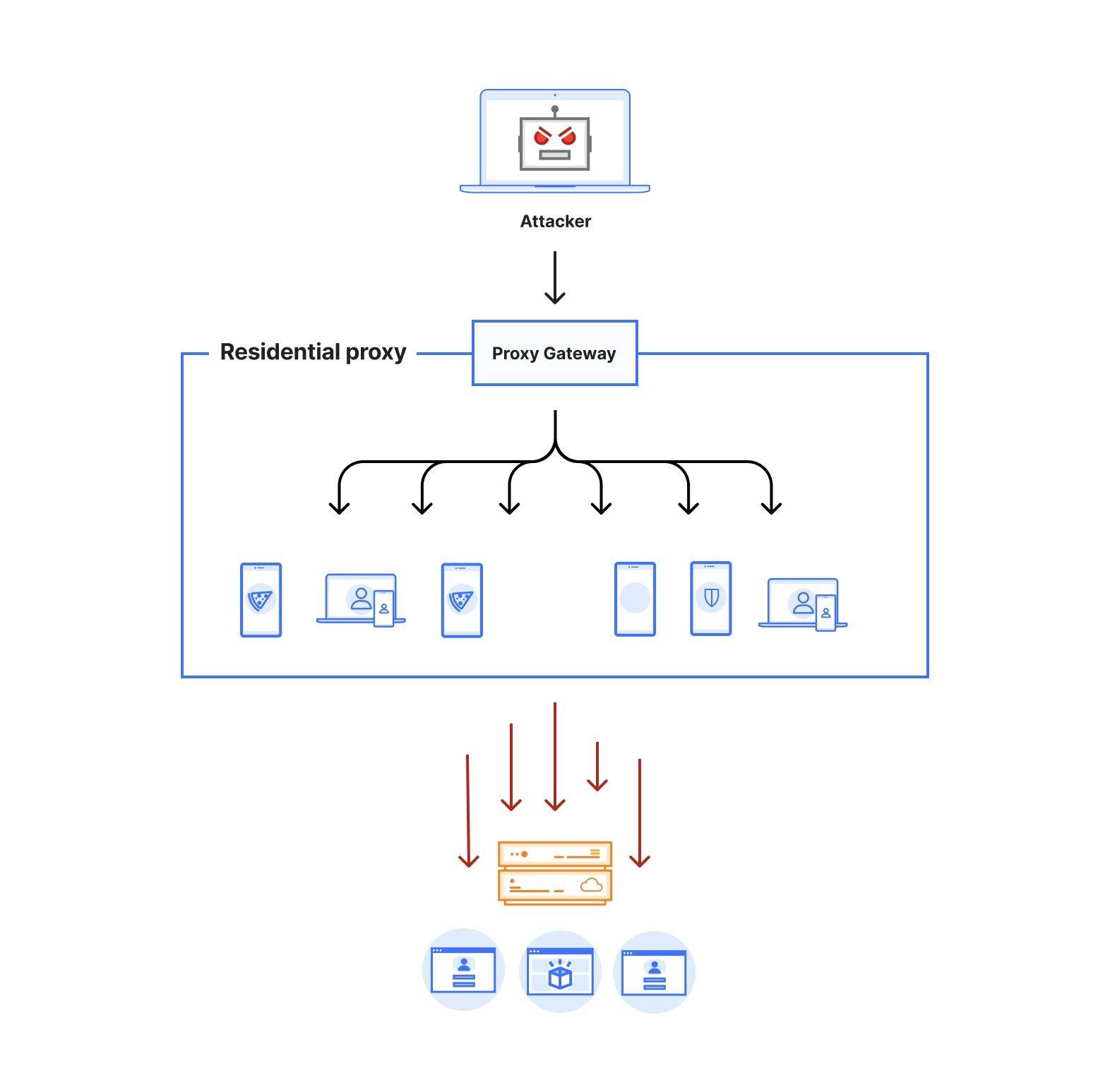
Figure 1: Architecture of a residential proxy network
Figure 1 depicts the architecture of a residential proxy. By subscribing to these services, attackers gain access to an authenticated proxy gateway address commonly using the HTTPS/SOCKS5 proxy protocol. Some residential proxy providers allow their users to select the country or region for the proxy exit nodes. Alternatively, users can choose to keep the same IP address throughout their session or rotate to a new one for each outgoing request. Residential proxy providers then identify active exit nodes on their network (on devices that they control within residential networks across the world) and route the proxied traffic through them.
The large pool of IP addresses and the diversity of networks poses a challenge to traditional bot defense mechanisms that rely on IP reputation and rate limiting. Moreover, the diversity of IPs enables the attackers to rotate through them indefinitely. This shrinks the window of opportunity for bot detection systems to effectively detect and stop the attacks. Effective defense against residential proxy attacks should be able to detect this type of bot traffic either based on single request features to stop the attack immediately, or identify unique fingerprints from the browsing agent to track and mitigate the bot traffic regardless of the IP source. Overly broad blocking actions, such as IP block-listing, by definition, would result in blocking legitimate traffic from residential networks where at least one device is acting as a residential proxy node.
ML model training
At its heart, our model is built using a chain of modules that work together. Initially, we fetch and prepare training and validation datasets from our Clickhouse data storage. We use datasets with high confidence labels as part of our training. For model validation, we use datasets consisting of missed attacks reported by our customers, known sources of bot traffic (e.g., verified bots), and high confidence detections from other bot management modules (e.g., heuristics engine). We orchestrate these steps using Apache Airflow, which enables us to customize each stage of the ML model training and define the interdependencies of our training, validation, and reporting modules in the form of directed acyclic graphs (DAGs).
The first step of training a new model is fetching labeled training data from our data store. Under the hood, our dataset definitions are SQL queries that will materialize by fetching data from our Clickhouse cluster where we store feature values and calculate aggregates from the traffic on our network. Figure 2 depicts these steps as train and validation dataset fetch operations. Introducing new datasets can be as straightforward as writing the SQL queries to filter the desired subset of requests.
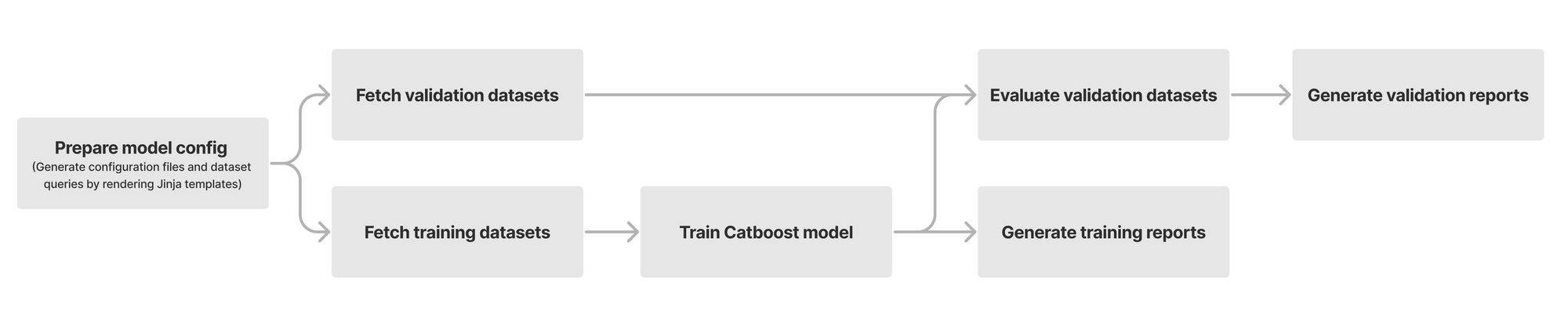
Figure 2: Airflow DAG for model training and validation
After fetching the datasets, we train our Catboost model and tune its hyper parameters. During evaluation, we compare the performance of the newly trained model against the current default version running for our customers. To capture the intricate patterns in subsets of our data, we split certain validation datasets into smaller slivers called specializations. For instance, we use the detections made by our heuristics engine and managed rulesets as ground truth for bot traffic. To ensure that larger sources of traffic (large ASNs, different HTTP versions, etc.) do not mask our visibility into patterns for the rest of the traffic, we define specializations for these sources of traffic. As a result, improvements in accuracy of the new model can be evaluated for common patterns (e.g., HTTP/1.1 and HTTP/2) as well as less common ones. Our model training DAG will provide a breakdown report for the accuracy, score distribution, feature importance, and SHAP explainers for each validation dataset and its specializations.
Once we are happy with the validation results and model accuracy, we evaluate our model against a checklist of steps to ensure the correctness and validity of our model. We start by ensuring that our results and observations are reproducible over multiple non-overlapping training and validation time ranges. Moreover, we check for the following factors:
-
Check for the distribution of feature values to identify irregularities such as missing or skewed values.
-
Check for overlaps between training and validation datasets and feature values.
-
Verify the diversity of training data and the balance between labels and datasets.
-
Evaluate performance changes in the accuracy of the model on validation datasets based on their order of importance.
-
Check for model overfitting by evaluating the feature importance and SHAP explainers.
After the model passes the readiness checks, we deploy it in shadow mode. We can observe the behavior of the model on live traffic in log-only mode (i.e., without affecting the bot score). After gaining confidence in the model’s performance on live traffic, we start onboarding beta customers, and gradually switch the model to active mode all while closely monitoring the real-world performance of our new model.
ML features for bot detection
Each of our models uses a set of features to make inferences about the incoming requests. We compute our features based on single request properties (single request features) and patterns from multiple requests (i.e., inter-request features). We can categorize these features into the following groups:
-
Global features: inter-request features that are computed based on global aggregates for different types of fingerprints and traffic sources (e.g., for an ASN) seen across our global network. Given the relatively lower cardinality of these features, we can scalably calculate global aggregates for each of them.
-
High cardinality features: inter-request features focused on fine-grained aggregate data from local traffic patterns and behaviors (e.g., for an individual IP address)
-
Single request features: features derived from each individual request (e.g., user agent).
Our Bot Management system (named BLISS) is responsible for fetching and computing these feature values and making them available on our servers for inference by active versions of our ML models.
Detecting residential proxies using network and behavioral signals
Attacks originating from residential IP addresses are commonly characterized by a spike in the overall traffic towards sensitive endpoints on the target websites from a large number of residential ASNs. Our approach for detecting residential IP proxies is twofold. First, we start by comparing direct vs proxied requests and looking for network level discrepancies. Revisiting Figure 1, we notice that a request routed through residential proxies (red dotted line) has to traverse through multiple hops before reaching the target, which affects the network latency of the request.
Based on this observation alone, we are able to characterize residential proxy traffic with a high true positive rate (i.e., all residential proxy requests have high network latency). While we were able to replicate this in our lab environment, we quickly realized that at the scale of the Internet, we run into numerous exceptions with false positive detections (i.e., non-residential proxy traffic with high latency). For instance, countries and regions that predominantly use satellite Internet would exhibit a high network latency for the majority of their requests due to the use of performance enhancing proxies.
Realizing that relying solely on network characteristics of connections to detect residential proxies is inadequate given the diversity of the connections on the Internet, we switched our focus to the behavior of residential IPs. To that end, we observe that the IP addresses from residential proxies express a distinct behavior during periods of peak activity. While this observation singles out highly active IPs over their peak activity time, given the pool size of residential IPs, it is not uncommon to only observe a small number of requests from the majority of residential proxy IPs.
These periods of inactivity can be attributed to the temporary nature of residential proxy exit nodes. For instance, when the client software (i.e., browser or mobile application) that runs the exit nodes of these proxies is closed, the node leaves the residential proxy network. One way to filter out periods of inactivity is to increase the monitoring time and punish each IP address that exhibits residential proxy behavior for a period of time. This block-listing approach, however, has certain limitations. Most importantly, by relying only on IP-based behavioral signals, we would block traffic from legitimate users that may unknowingly run mobile applications or browser extensions that turn their devices into proxies. This is further detrimental for mobile networks where many users share their IPs behind CGNATs. Figure 3 demonstrates this by comparing the share of direct vs proxied requests that we received from active residential proxy IPs over a 24-hour period. Overall, we see that 4 out of 5 requests from these networks belong to direct and benign connections from residential devices.
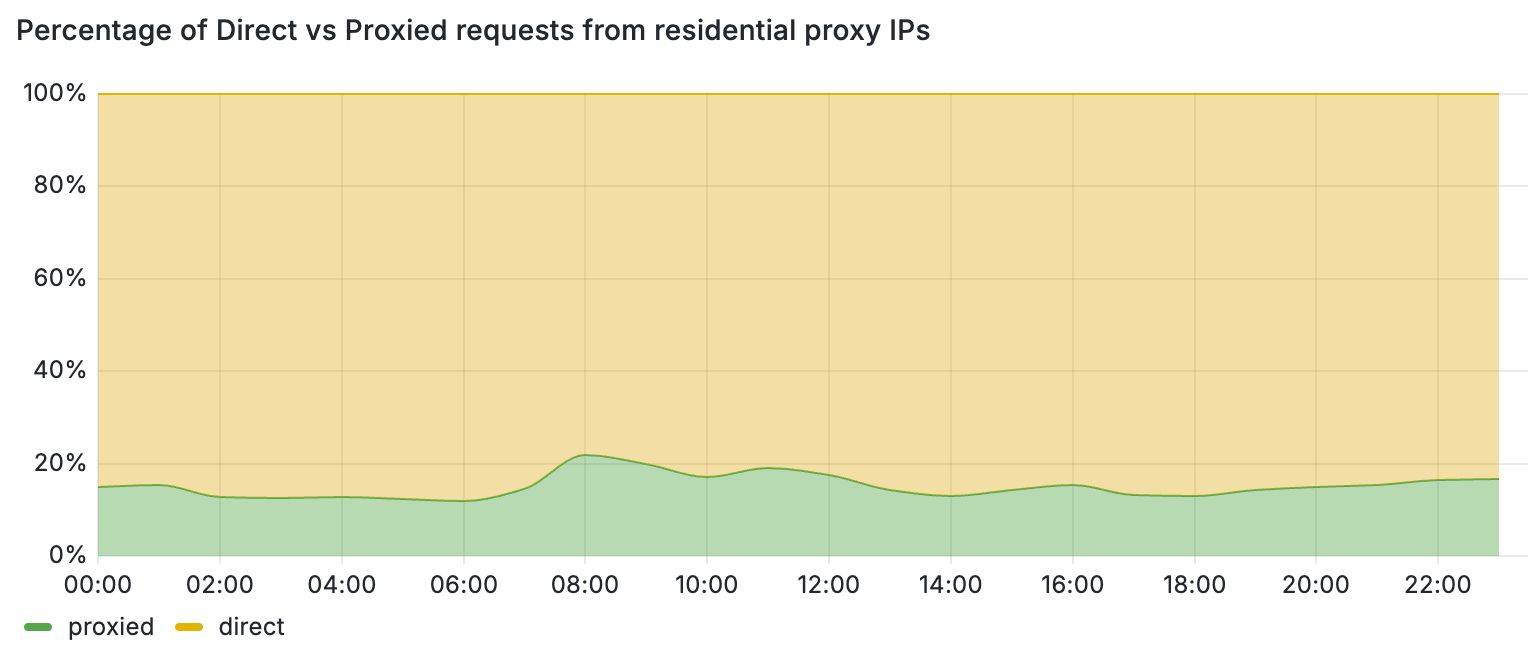
Figure 3: Percentage of direct vs proxied requests from residential proxy IPs.
Using this insight, we combined behavioral and latency-based features along with new datasets to train a new machine learning model that detects residential proxy traffic on a per-request basis. This scheme allows us to block residential proxy traffic while allowing benign residential users to visit Cloudflare-protected websites from the same residential network.
Detection results and case studies
We started testing v8 in shadow mode in March 2024. Every hour, v8 is classifying more than 17 million unique IPs that participate in residential proxy attacks. Figure 4 shows the geographic distribution of IPs with residential proxy activity belonging to more than 45 thousand ASNs in 237 countries/regions. Among the most commonly requested endpoints from residential proxies, we observe patterns of account takeover attempts, such as requests to /login, /auth/login, and /api/login.
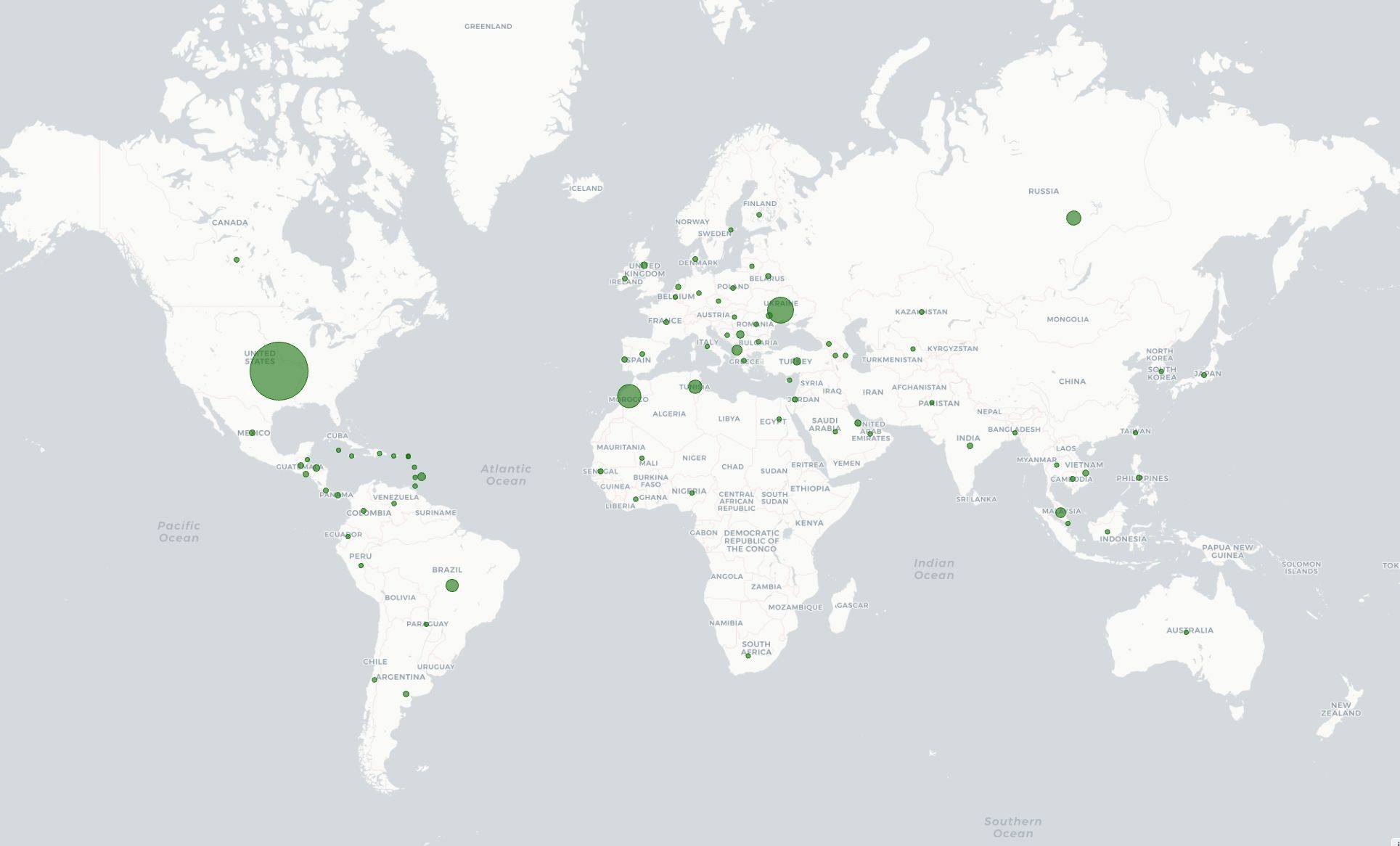
Figure 4: Countries and regions with residential network activity. Size of markers are proportionate to the number of IPs with residential proxy activity.
Furthermore, we see significant improvements when evaluating our new machine learning model on previously missed attacks reported by our customers. In one case, v8 was able to correctly classify 95% of requests from distributed residential proxy attacks targeting the voucher redemption endpoint of the customer’s website. In another case, our new model successfully detected a previously missed content scraping attack evident by increased detection during traffic spikes depicted in Figure 5. We are continuing to monitor the behavior of residential proxy attacks in the wild and work with our customers to ensure that we can provide robust detection against these distributed attacks.
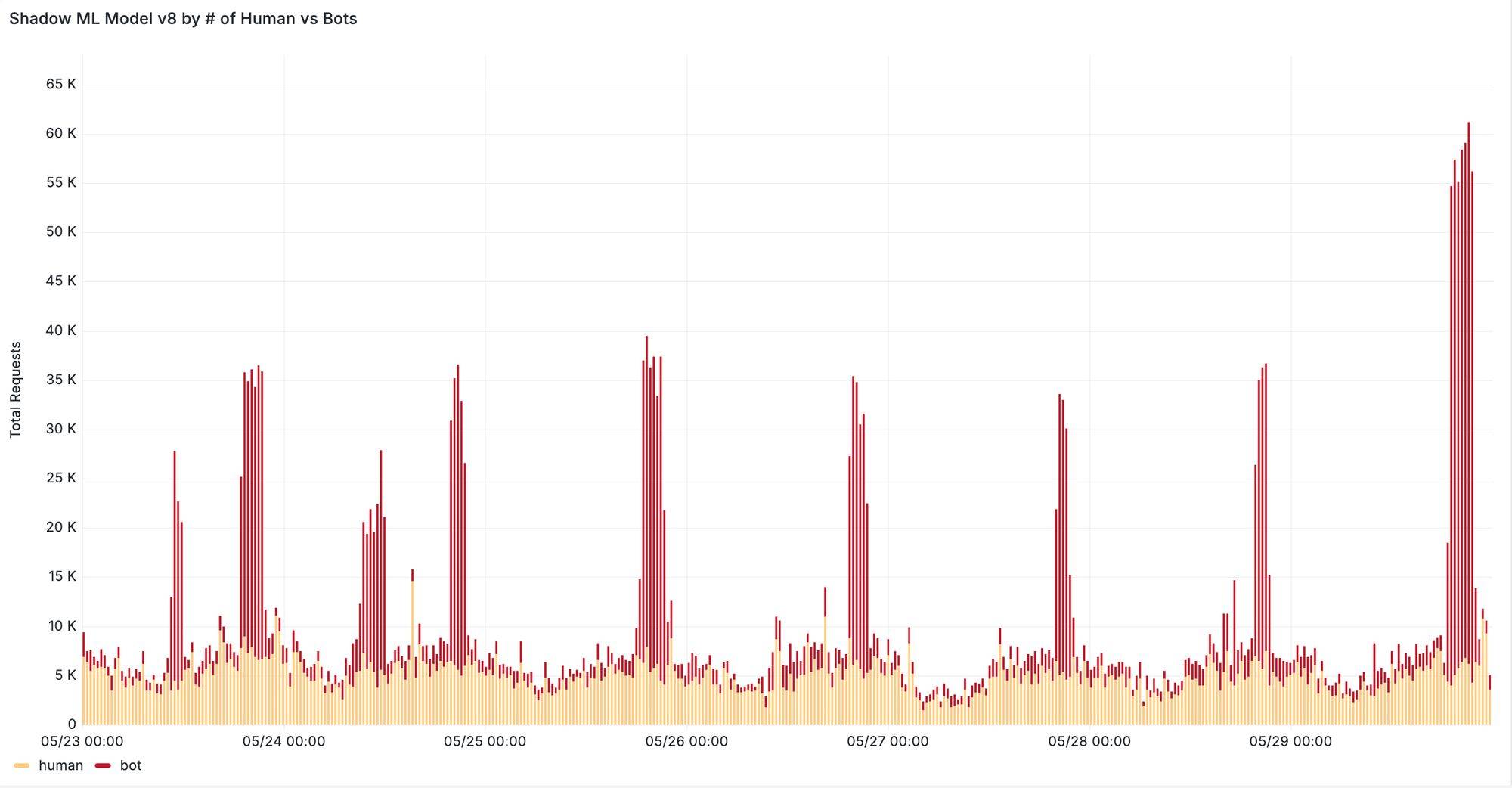
Figure 5: Spikes in bot requests from residential proxies detected by ML v8
Improving detection for bots from cloud providers
In addition to residential IP proxies, bot operators commonly use cloud providers to host and run bot scripts that attack our customers. To combat these attacks, we improved our ground truth labels for cloud provider attacks in our latest ML training datasets. Early results show that v8 detects 20% more bots from cloud providers, with up to 70% more bots detected on zones that are marked as under attack. We further plan to expand the list of cloud providers that v8 detects as part of our ongoing updates.
Check out ML v8
For existing Bot Management customers we recommend toggling “Auto-update machine learning model” to instantly gain the benefits of ML v8 and its residential proxy detection, and to stay up to date with our future ML model updates. If you’re not a Cloudflare Bot Management customer, contact our sales team to try out Bot Management.