
包阅导读总结
1.
关键词:`pandas`、`Polars`、`数据科学`、`迁移`、`差异`
2.
总结:本文是关于从 `pandas` 迁移到 `Polars` 的介绍。指出 `Polars` 在速度和安全性上有优势,其与 `pandas` 有相似的 API 但存在差异,并提供了迁移的工具、示例、技巧及探索性数据分析的相关内容。
3.
主要内容:
– 引言
– 介绍从 `pandas` 迁移到 `Polars` 的背景及常见担忧。
– `Polars` 与 `pandas` 的不同
– `Polars` 因采用 `Rust` 和 `Apache Arrow` 而在速度和安全性上出色。
– 虽后端架构不同,但 `Python` API 与 `pandas` 相似,不过仍需注意差异。
– 使用 `Polars` 的优势
– 其懒加载 `API` 可节省内存。
– 因 `Rust` 编写,能更好利用并发。
– 使迁移更容易的工具
– 如 `PyCharm` 提供相似体验,具备优秀功能,包括自动完成方法、快速访问文档等。
– 从 `pandas` 到 `Polars` 的迁移
– 相似性:提供类似的 `API` 及数据操作函数。
– 迁移技巧:包括选择和过滤数据、使用 `with_columns` 、利用 `with_columns` 替代 `groupby` 、使用 `scan_csv` 等。
– 缺失数据:`Polars` 中缺失数据为 `null` 而非 `NaN` 。
– 用 `Polars` 进行探索性数据分析
– 提供类似 `pandas` 的 `API` ,结合 `hvPlot` 可进行简单的绘图和分析。
思维导图:
文章地址:https://blog.jetbrains.com/pycharm/2024/06/how-to-move-from-pandas-to-polars/
文章来源:blog.jetbrains.com
作者:Evgenia Verbina
发布时间:2024/6/19 11:48
语言:英文
总字数:1955字
预计阅读时间:8分钟
评分:84分
标签:数据科学,教程,pandas,polars
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
How to Move From pandas to Polars
This is a guest post from Cheuk Ting Ho, a data scientist who contributes to multiple open-source libraries, such as pandas and Polars.

You’ve probably heard about Polars – it is now firmly in the spotlight in the data science community.
Are you still using pandas and would like to try out Polars? Are you worried that it will take a lot of effort to migrate your projects from pandas to Polars? You might be concerned that Polars won’t be compatible with your existing pipeline or the other tools you are currently using.
Fear not! In this article, I will answer these questions so you can decide whether to migrate to using Polars or not. I will also provide some tips for those of you who have already decided to migrate.
How is Polars different from pandas?
Polars is known for its speed and security, as it is written in Rust and based on Apache Arrow. For details about Polars vs. pandas, you can see our other blog post here. In short, while Polars’ backend architecture is different from pandas’, the creator and community around Polars have tried to maintain a Python API that is very similar to pandas’. At first glance, Polars code is very similar to pandas code. Fun fact – some contributors to pandas are also contributors to Polars. Due to this, the barrier for pandas users to start using Polars is relatively low. However, as it is still a different library, it is worth double-checking the differences between the two.
Advantages of using Polars
Have you struggled when using pandas for a relatively large data set? Do you think pandas is using too much RAM and slowing your computer down while working locally? Polars may solve this problem by using its lazy API. Intermediate steps won’t be executed unless needed, saving memory for the intermediate steps in some cases.
Another advantage Polars has is that, since it is written in Rust, it can make use of concurrency much better than pandas.Python is traditionally single-threaded, and although pandas uses the NumPy backend to speed up some operations, it is still mainly written in Python and has certain limitations in its multithreading capabilities.
Tools that make the switch easy
As Polars’ popularity grows, there is more and more support for Polars in popular tools for data scientists, including scikit-learn and HoloViz.
PyCharm, the most popular IDE used by data scientists, provides a similar experience when you work with pandas and Polars. This makes the process of migration smoother. For example, interactive tables allow you to easily see the information about your DataFrame, such as the number of rows and columns.
Try PyCharm for free
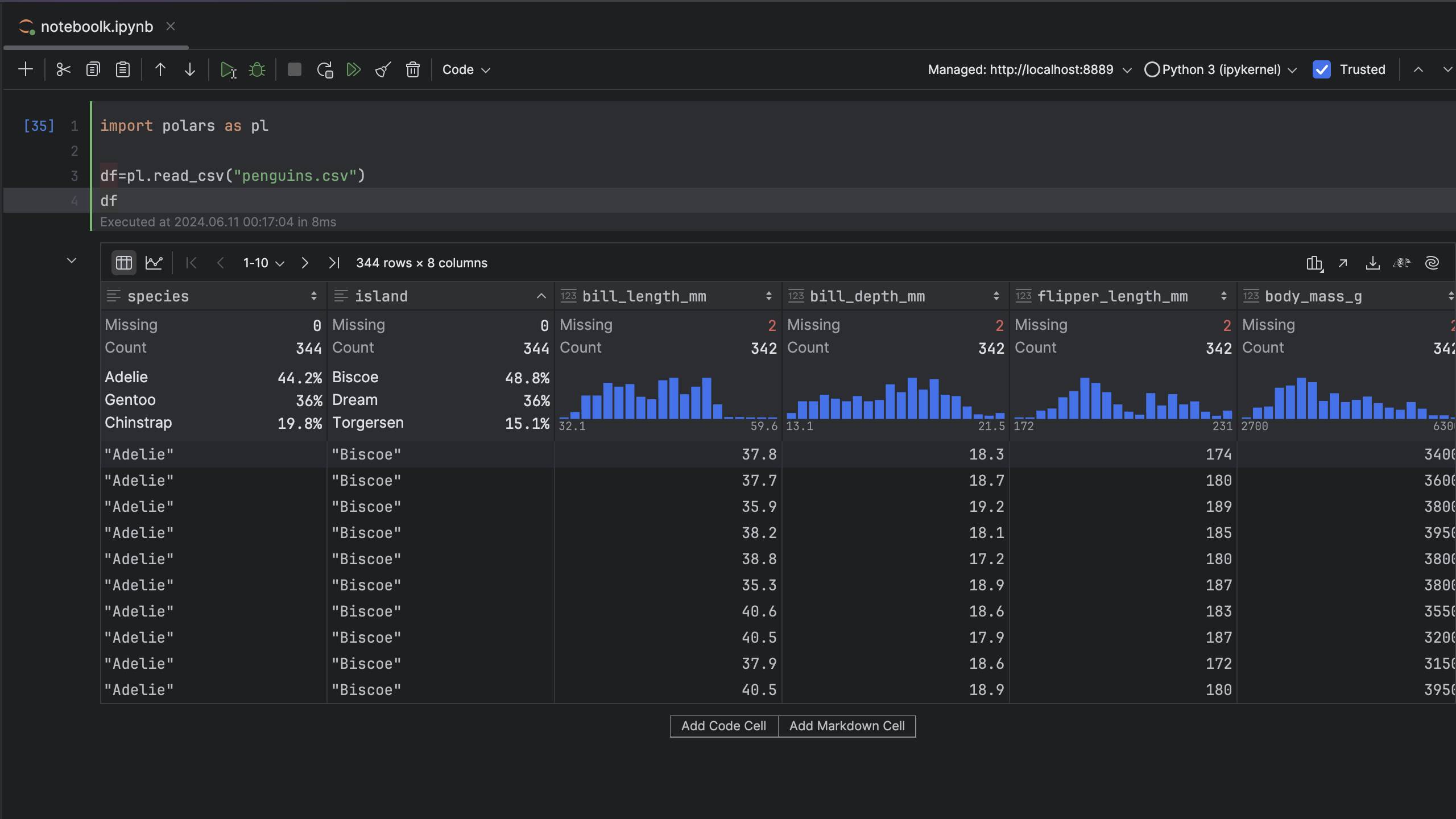
PyCharm has an excellent pagination feature – if you want to see more results per page, you can easily configure that via a drop-down menu:
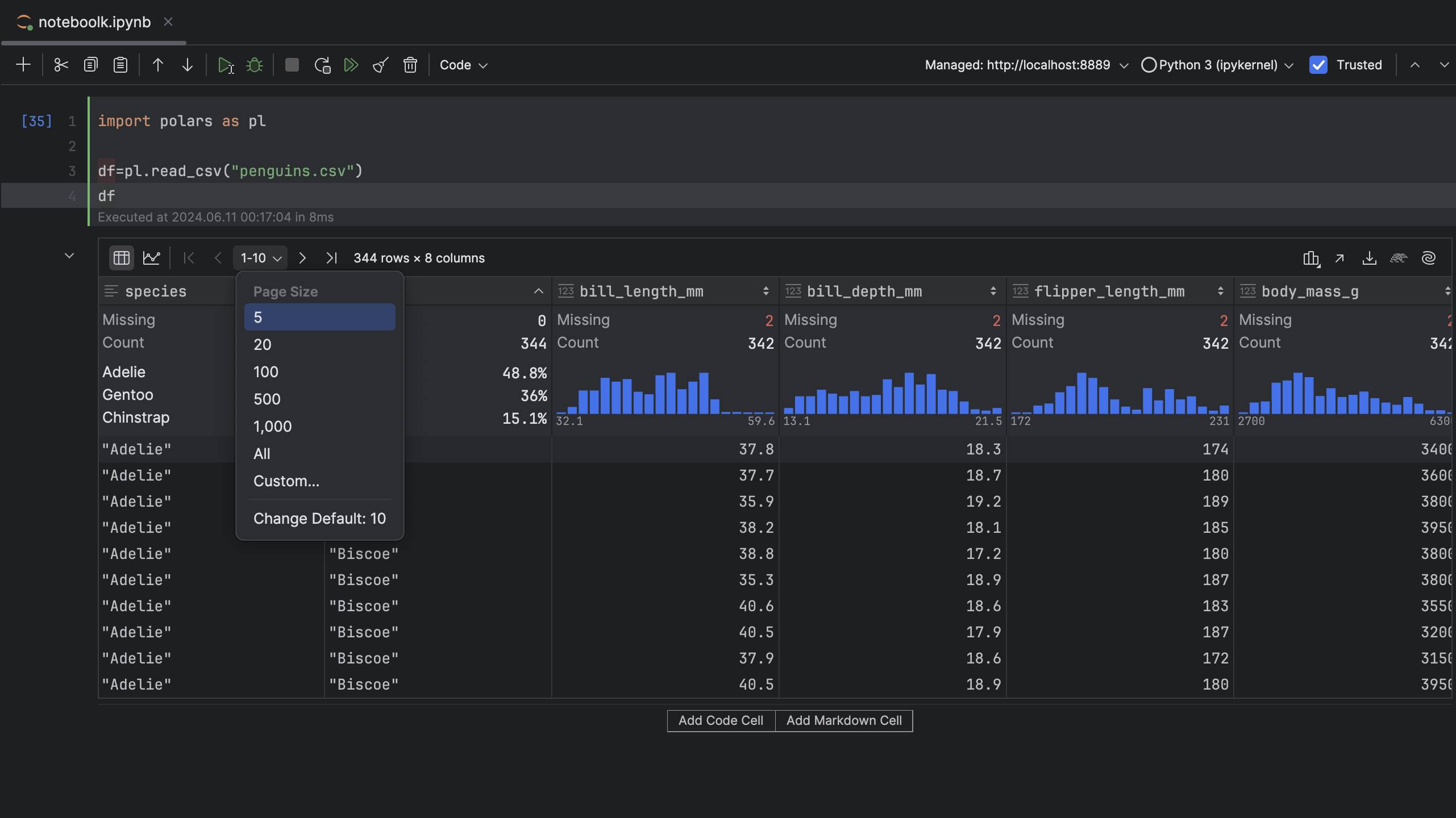
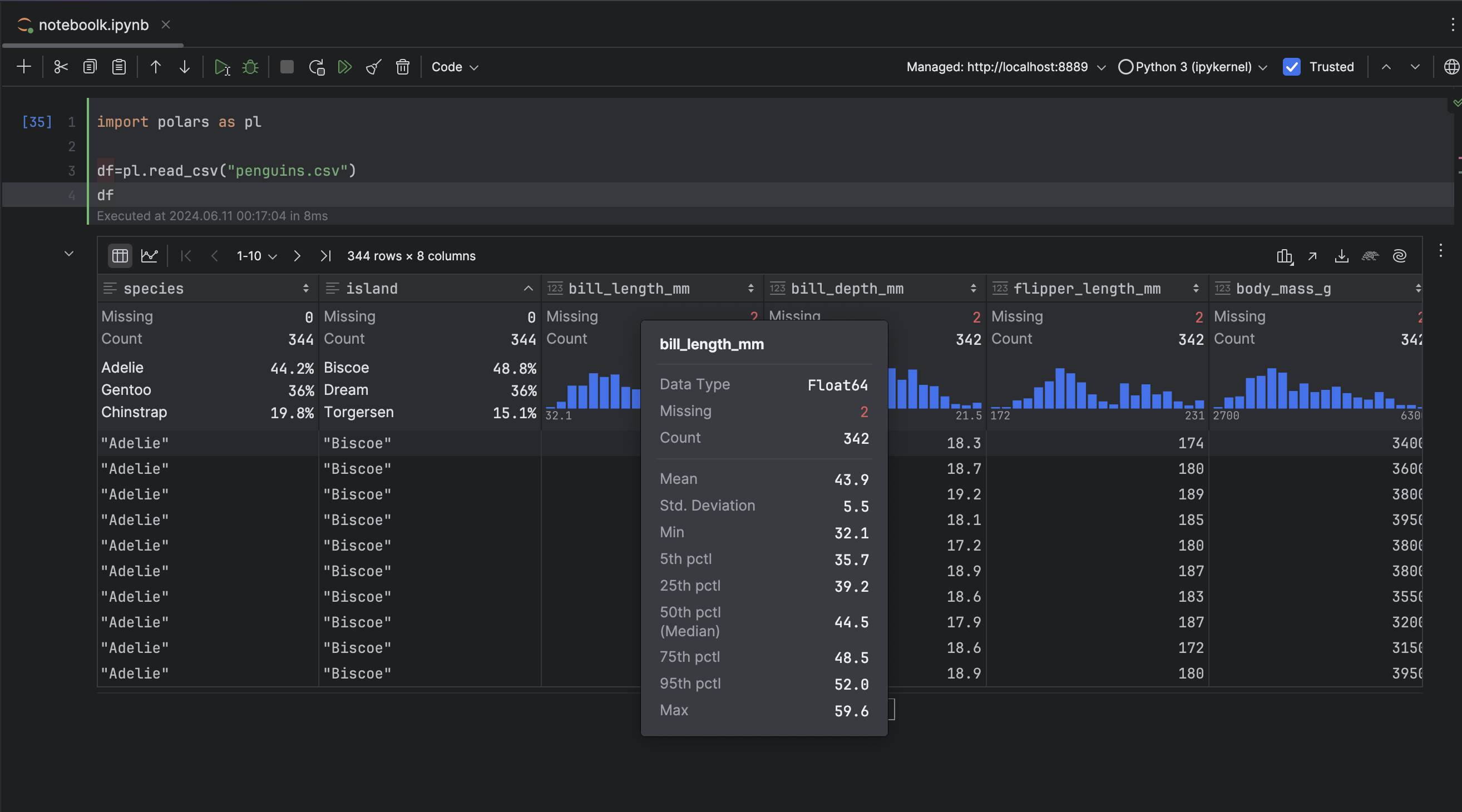
You can see the statistical summary for the data when you hover the cursor over the column name:
You can also sort the data for inspection with a few clicks in the header. You can also use the multi-sorting functionality – after sorting the table once, press and hold ⌥ (macOS) or Alt (Windows) and click on the second column you want the table to be sorted by. For example, here, we can sort by island and bill_length_mm in the table.
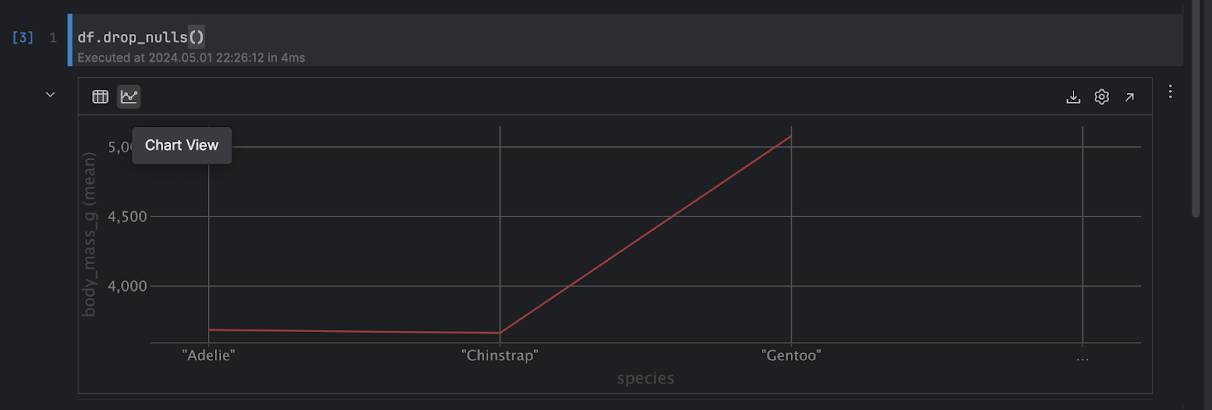
To get more insights from the DataFrame, you can switch to chat view with the icon on the left:
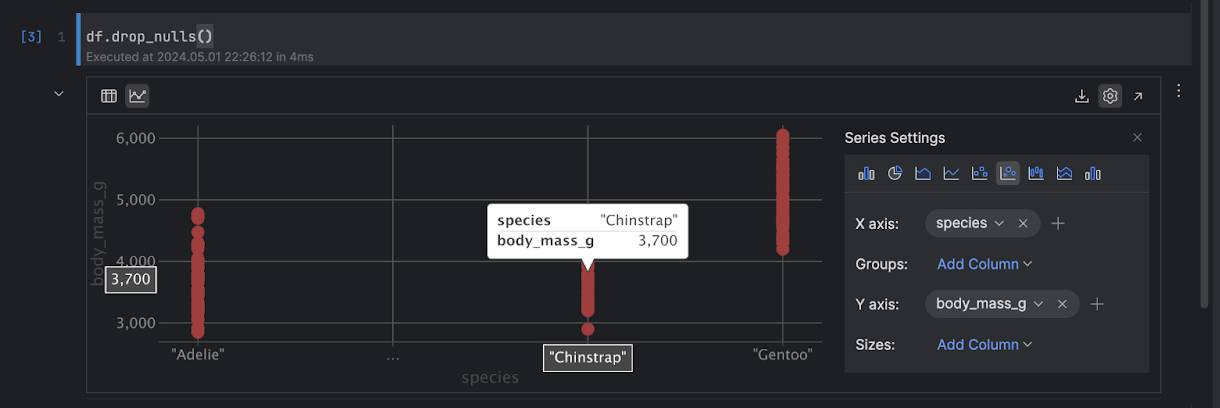
You can also change how the data is shown in the settings, showing different columns and using different graph types:
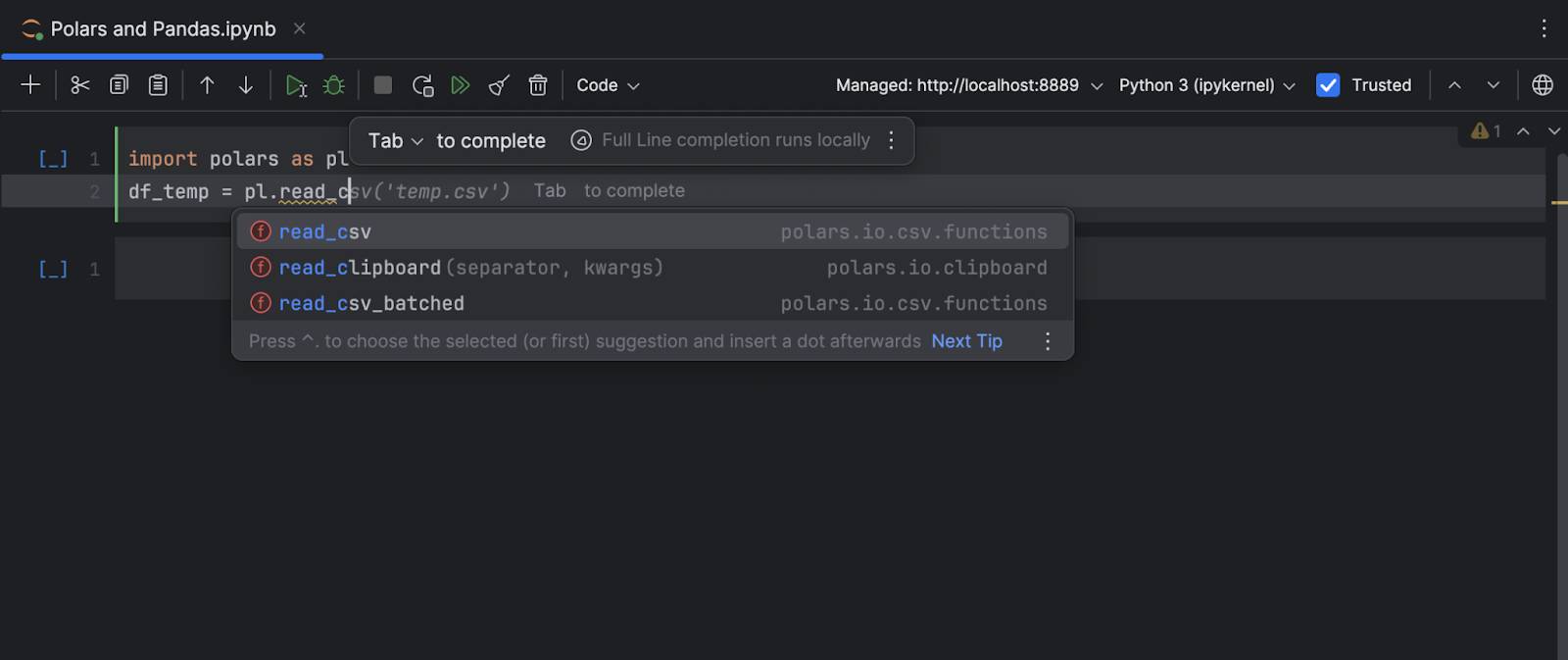
It also helps you to auto-complete methods when using Polars, very handy when you are starting to use Polars and not familiar with all of the methods that it provides. To understand more about full line code completion in JetBrains IDEs, please check out this article.
You can also access the official documentation quickly by clicking the Polars icon in the top-right corner of the table, which is really handy.
How to migrate from pandas to Polars
If you’re now convinced to migrate to Polars, your final questions might be about the extent of changes needed for your existing code and how easy it is to learn Polars, especially considering your years of experience and muscle memory with pandas.
Similarities between pandas and Polars
Polars provides APIs similar to pandas, most notably the read_csv(), head(), tail(), and describe() for a glance at what the data looks like. It also provides similar data manipulation functions like join() and groupby()/ group_by(), and aggregation functions like mean() and sum().
Before going into the migration, let’s look at these code examples in Polars and pandas.
Example 1 – Calculating the mean score for each class
pandas
import pandas as pddf_student = pd.read_csv("student_info.csv")print(df_student.dtypes)df_score = pd.read_csv("student_score.csv")print(df_score.head())df_class = df_student.join(df_score.set_index("name"), on="name").drop("name", axis=1)df_mean_score = df_class.groupby("class").mean()print(df_mean_score)
Polars
import polars as pldf_student = pl.read_csv("student_info.csv")print(df_student.dtypes)df_score = pl.read_csv("student_score.csv")print(df_score.head())df_class = df_student.join(df_score, on="name").drop("name")df_mean_score = df_class.group_by("class").mean()print(df_mean_score)
Polars provides similar io methods like read_csv. You can also inspect the dtypes, do data cleaning with drop, and do groupby with aggregation functions like mean.
Example 2 – Calculating the rolling mean of temperatures
pandas
import pandas as pddf_temp = pd.read_csv("temp_record.csv", index_col="date", parse_dates=True, dtype={"temp":int})print(df_temp.dtypes)print(df_temp.head())df_temp.rolling(2).mean()
Polars
import polars as pldf_temp = pl.read_csv("temp_record.csv", try_parse_dates=True, dtypes={"temp":int}).set_sorted("date")print(df_temp.dtypes)print(df_temp.head())df_temp.rolling("date", period="2d").agg(pl.mean("temp"))
Reading with date as index in Polars can also be done with read_csv, with a slight difference in the function arguments. Rolling mean (or other types of aggregation) can also be done in Polars.
As you can see, these code examples are very similar, with only slight differences. If you are an experienced pandas user, I am sure your journey using Polars will be quite smooth.
Tips for migrating from pandas to Polars
As for code that was previously written in pandas, how can you migrate it to Polars? What are the differences in syntax that may trip you up? Here are some tips that may be useful:
Selecting and filtering
In pandas, we use .loc / .iloc and [] to select part of the data in a data frame. However, in Polars, we use .select to do so. For example, in pandas df["age"] or df.loc[:,"age"] becomes df.select("age") in Polars.
In pandas, we can also create a mask to filter out data. However, in Polars, we will use .filter instead. For example, in pandas df["age" > 18] becomes df.filter(pl.col("a") > 18) in Polars.
All of the code that involves selecting and filtering data needs to be rewritten accordingly.
Use .with_columns instead of .assign
A slight difference between pandas and Polars is that, in pandas we use .assign to create new columns by applying certain logic and operations to existing columns. In Polars, this is done with .with_columns. For example:
In pandas
df_rec.assign(diameter = lambda df: (df.x + df.y) * 2,area = lambda df: df.x * df.y)
becomes
df_rec.with_columns(diameter = (pl.col("x") + pl.col("y")) * 2,area = pl.col("x") * pl.col("y"))
in Polars.
.with_columns can replace groupby
In addition to assigning a new column with simple logic and operations, .with_columns offers more advanced capabilities. With a little trick, you can perform operations similar to groupby in pandas by using window functions:
In pandas
df = pd.DataFrame({"class": ["a", "a", "a", "b", "b", "b", "b"],"score": ["80", "39", "67", "28", "77", "90", "44"],})df["avg_score"] = df.groupby("class")["score"].transform("mean")
becomes
df.with_columns(pl.col("score").mean().over("class").alias("avg_score"))
in Polars.
Use scan_csv instead of read_csv if you can
Although read_csv also works in Polars, by using scan_csv instead of read_csv it will turn to lazy evaluation mode and benefit from the lazy API mentioned above.
Building pipelines properly with lazy API
In pandas, we usually use .pipe to build data pipelines. However, since Polars works a bit differently, especially when using the lazy API, we want the pipeline to be executed only once. So, we need to adjust the code accordingly. For example:
Instead of this pandas code snippet:
def discount(df):df["30_percent_off"] = df["price"] * 0.7return dfdef vat(df):df["vat"] = df["price"] * 0.2return dfdef total_cost(df):df["total"] = df["30_percent_off"] + df["vat"]return df(df.pipe(discount).pipe(vat).pipe(total_cost))
We will have the following one in Polars:
def discount(input_col)r:return pl.col(input_col).mul(0.7).alias("70_percent_off")def vat(input_col):return pl.col(input_col).mul(0.2).alias("vat")def total_cost(input_col1, input_col2):return pl.col(input_col1).add(pl.col(input_col2).alias("total")df.with_columns(discount("price"),val("price"),total_cost("30_percent_off", "vat"),)
Missing data: No more NaN
Do you find NaN in pandas confusing? There is no NaN in Polars! Since NaN is an object in NumPy and Polars doesn’t use NumPy as the backend, all missing data will now be null instead. For details about null and NaN in Polars, check out the documentation.
Exploratory data analysis with Polars
Polars provides a similar API to pandas, and with hvPlot, you can easily create a simple plotting function with exploratory data analysis in Polars. Here I will show two examples, one creating simple statistical information from your data set, and the other plotting simple graphs to understand the data.
Summary statistics from dataset
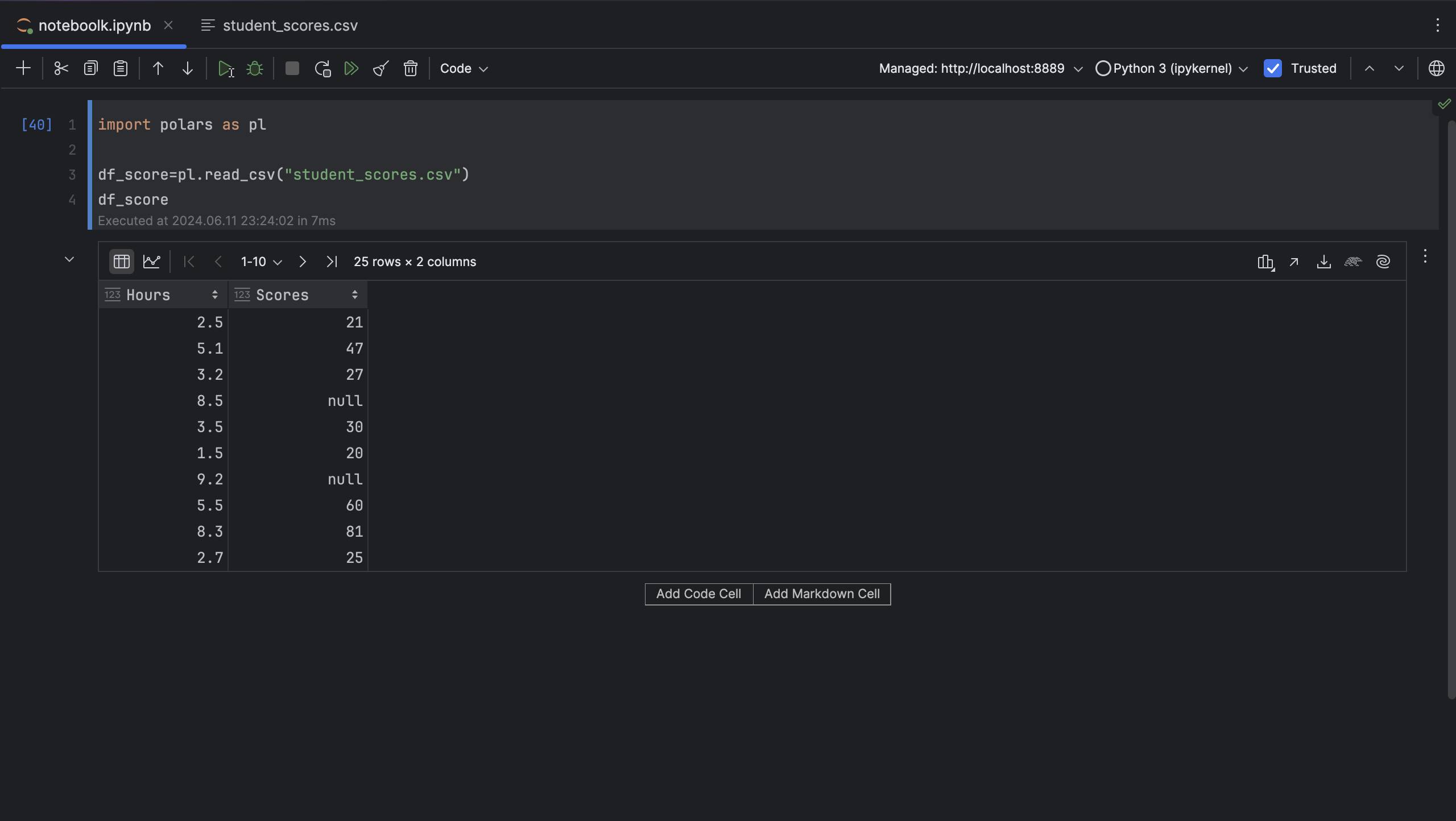
When using pandas, the most common way to get a summary statistic is to use describe. In Polars, we can also use describe in a similar manner. For example, we have a DataFrame with some numerical data and missing data:
We can use describe to get summary statistics:
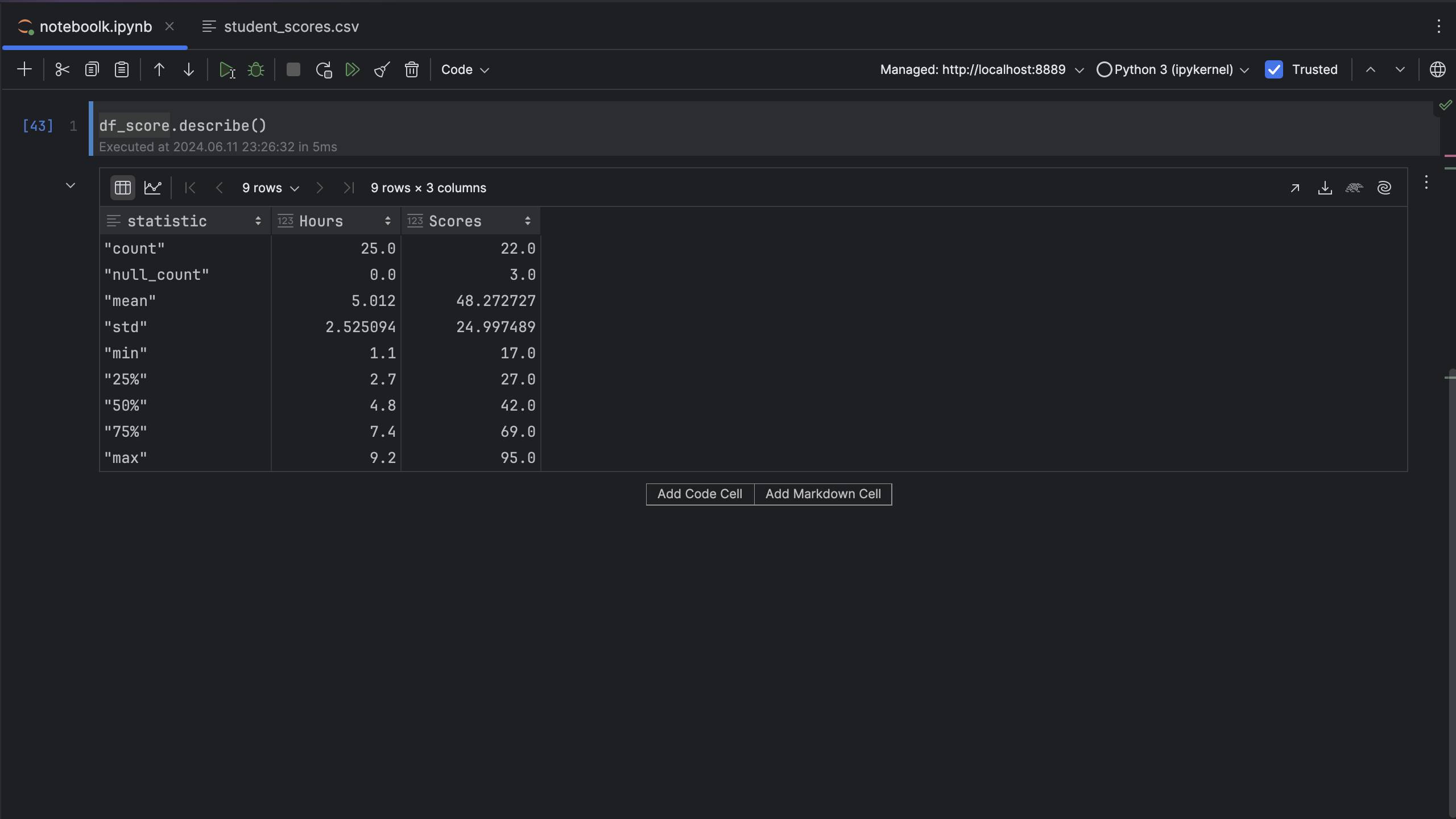
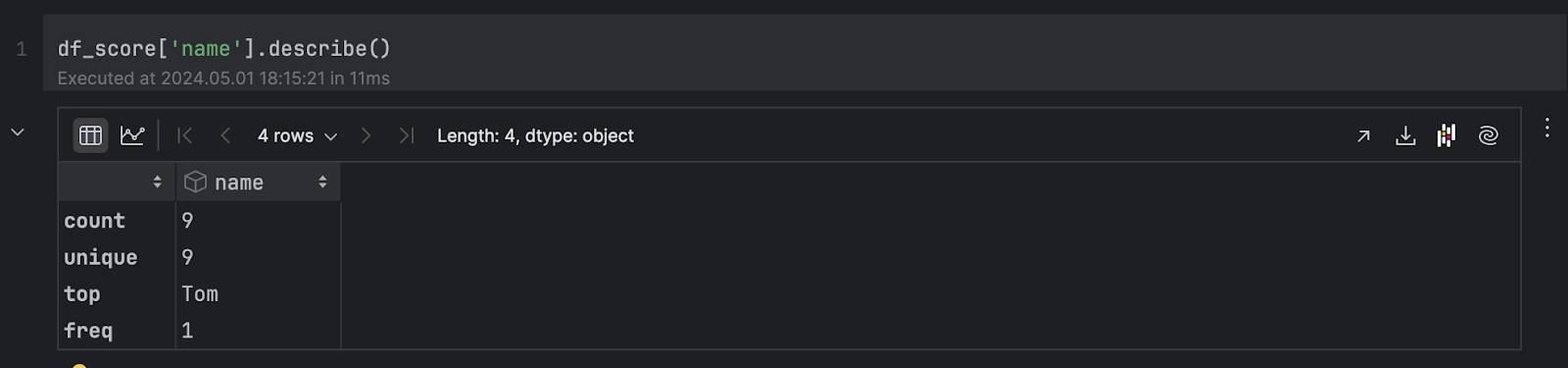
Notice how object types are treated – in this example, the column name gives a different result compared to pandas. In pandas, a column with object type will result in categorical data like this:
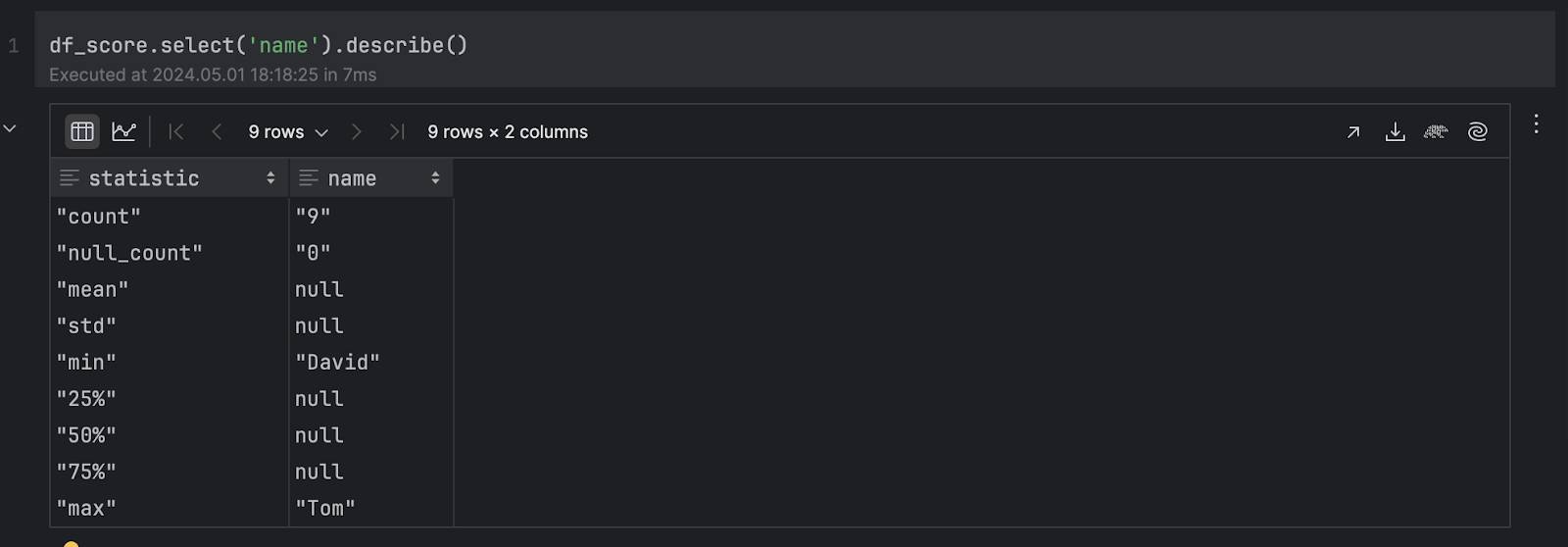
In Polars, the result is similar to numeric data, which makes less sense:
Simple plotting with Polars DataFrame
To better visualize of the data, we might want to plot some graphs to help us evaluate the data more efficiently. Here is how to do so with the plot method in Polars.
First of all, since Polars uses hvPlot as backend, make sure that it is installed. You can find the hvPlot User Guide here. Next, since hvPlot will output the graph as an interactive Bokeh graph, we need to use output_notebook from bokeh.plotting to make sure it will show inline in the notebook. Add this code at the top of your notebook:
from bokeh.plotting import output_notebookoutput_notebook()
Also, make sure your notebook is trusted. This is done by simply checking the checkbox in the top-right of the display when using PyCharm.

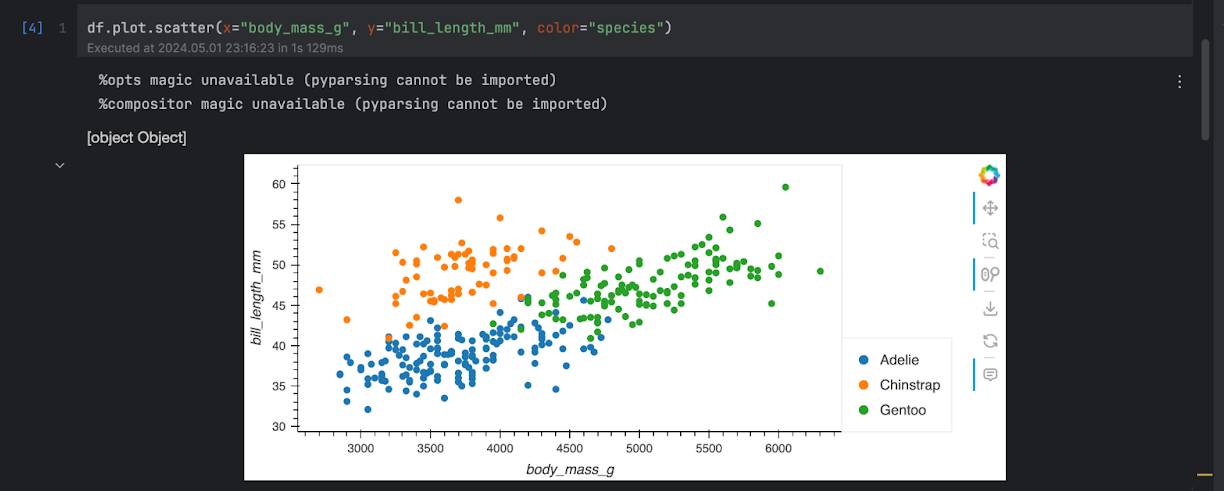
Next, you can use the plot method in Polars. For example, to make a scatter plot, you have to specify the columns to be used as the x- and y-axis, and you can also specify the column to be used as color of the points:
df.plot.scatter(x="body_mass_g", y="bill_length_mm", color="species")
This will give you a nice plot of the different data points of different penguin species for inspection:
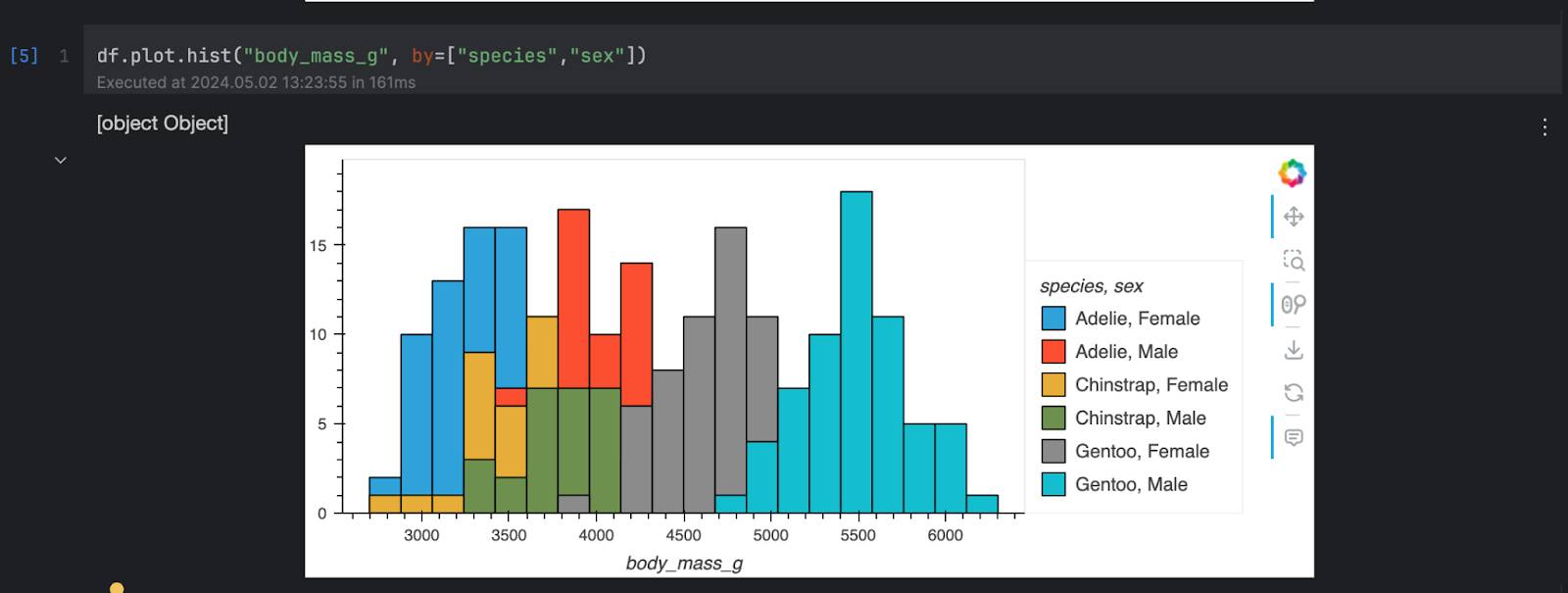
Of course, scatter plots aren’t your only option. In Polars, you can use similar steps to create any type of plot that is supported by hvPlot. For example, hist can be done like this:
df.plot.hist("body_mass_g", by=["species","sex"])
For a full list of plot types supported by hvPlot, you can have a look at the hvPlot reference gallery.
Conclusion
I hope the information provided here will help you on your way with using Polars. Polars is an open-source project that is actively maintained and developed. If you have suggestions or questions, I recommend reaching out to the Polars community.
About the author
Cheuk Ting Ho
Cheuk has been a Data Scientist at various companies – a job that demands high numerical and programming skills, especially in Python. Following her passion for the tech community, Cheuk has been a Developer Advocate for three years. She also contributes to multiple open-source libraries like Hypothesis, Pytest, pandas, Polars, PyO3, Jupyter Notebook, and Django. Cheuk is currently a consultant and trainer at CMD Limes.