
包阅导读总结
1. 关键词:Kubeflow 1.9、CNCF、Red Hat、MLOps、Open Source
2. 总结:
– Kubeflow 1.9 得益于 CNCF 和 Red Hat 的支持。
– 将于 7 月 8 日发布,带来新功能,如模型注册表等。
– 存在稳定性、安装和文档等方面的问题待解决。
3. 主要内容:
– Kubeflow 1.9 受益情况
– 自去年起,Kubeflow 受益于 CNCF 开放治理和 Red Hat 工程帮助。
– Kubeflow 1.9 新功能
– 基于 Google 的 ML Metadata 库的模型注册表。
– 能用 CNCF Argo 项目创建构建流,修订笔记本格式。
– 带来 Kubeflow Notebooks 2.0 等。
– Red Hat 对 Kubeflow 的兴趣
– 类似 OpenShift 基于 Kubernetes,Red Hat Open Data Hub 基于 Kubeflow。
– 待解决的问题
– 用户希望管道和笔记本功能更稳定。
– 安装体验差,需更多一致性测试。
– 部分文档过时或缺失。
思维导图: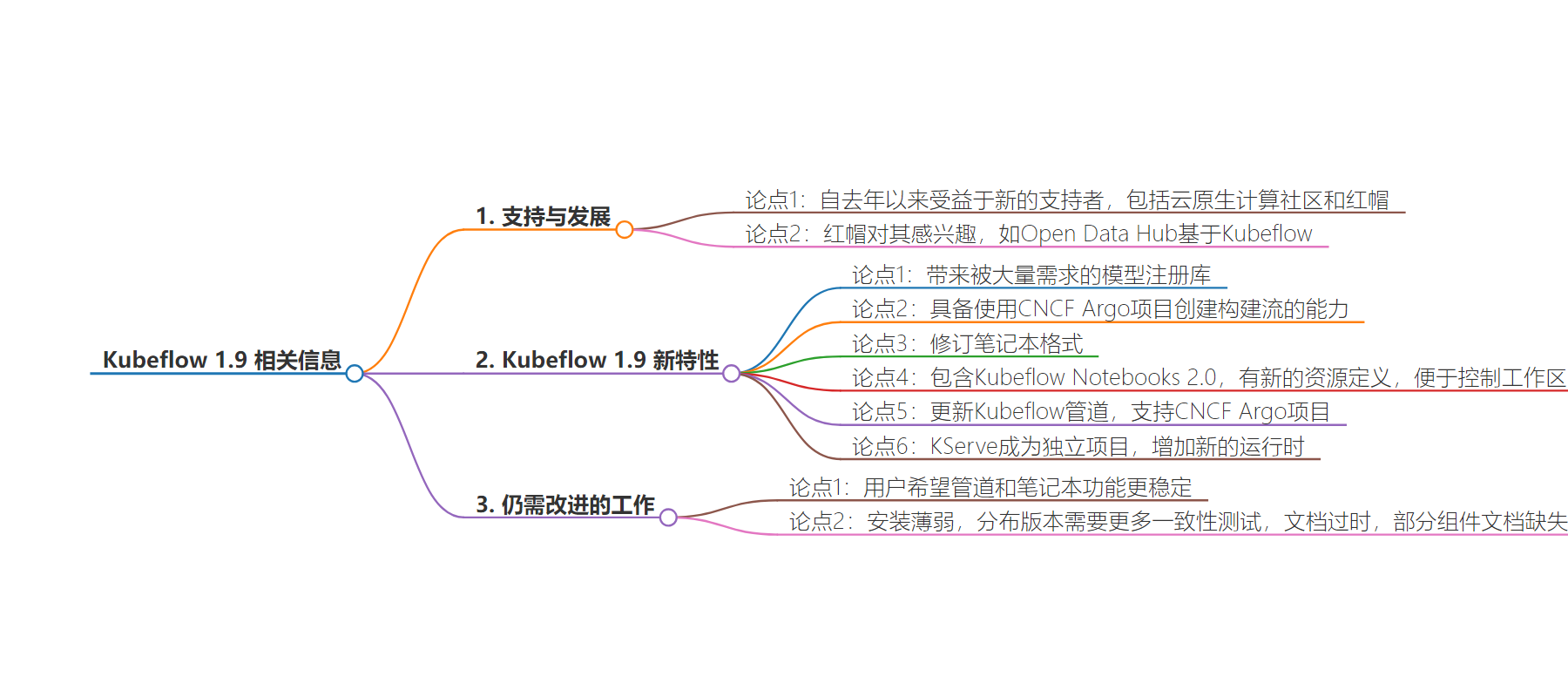
文章地址:https://thenewstack.io/smooth-sailing-for-kubeflow-1-9-thanks-to-cncf-red-hat-support/
文章来源:thenewstack.io
作者:Joab Jackson
发布时间:2024/7/1 16:29
语言:英文
总字数:855字
预计阅读时间:4分钟
评分:81分
标签:人工智能,开源
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Since last year, the open source MLOps platform Kubeflow has benefitted from a number of powerful new benefactors, including the Cloud Native Computing Community for open governance, and Red Hat, which has contributed considerable engineering help.
And next month, users will begin to see the fruits of this support. Scheduled for release in July 8, the next version of Kubeflow will bring a much-requested model registry, based on Google’s ML Metadata library. It also brings the capability of creating build flows using the CNCF Argo projectand a revised notebook format.
Debuting in 2018, Kubeflow runs on Kubernetes, so it can be run in the cloud or on in-house servers. Kubeflow uses existing open source projects when available. Components include notebooks for experimentation (based on Jupyter Notebooks), pipelines, a user console, and a training operator.
Why Is Red Hat Interested in Kubeflow?
Much like OpenShift is based on the Kubernetes container orchestrator, so too is Red Hat Open Data Hub built on Kubeflow, noted Jeremy Eder, distinguished engineer at Red Hat, in an interview with TNS. It is also used for the company’s commercially supported OpenShift AI, based on the Open Data Hub.
In keeping with the rest of the company’s software portfolio, Red Hat did not build an MLOps tool in-house but instead adopted software already well-supported in the open source community and then allocated engineering help upstream.
While the open source enterprise software company had been supporting Kubeflow for a while — Red Hat customers were already running AI and ML workloads on OpenShift, thanks in art because of its support for GPUs — Red Hat ramped up its investment last year when Kubeflow was moved under the CNCF, Eder noted.
Kubeflow 1.9 will be the first release that has benefitted from Red Hat’s increased investment, he said.
“We’re off and running, man,” Eder said. “The engineers on the ground are represented in almost every workstream.”
What Is New in Kubeflow 1.9?
Red Had had a lot of customers running AI operation on-premises so, they required a local storage system to build and store models and other build artifacts. That was the first Red Hat-led feature for Kubeflow, a registry to hold models and other build artifacts, such as datasets and metric logs.
If you run a MLops system, you need a registry, and while you could use a stock container registry such as Red Hat Quay though “there’s subtly different and important workload ways and we want it to cater very specifically to a data science persona,” Eder said.
This registry implements the Open Container Interface 1.1 standard, which is also implemented by Quay. The registry is integrated with Kubeflow pipelines, allowing users to deploy directly from the registry.
The model registry will be available as an alpha, though there are some lingering questions about how a model registry should work. So a newly-formed working group is looking for more input from the user community.
This release will come with Kubeflow Notebooks 2.0, which comes with a pair of Kubernetes-friendly custom resource definitions (Workspace and WorkspaceKind) to provide more control over workspaces.
Once the user is done experimenting in a Notebook, they will be able to move the code over to a pipeline to prepare the software for production use.
The new release also updates Kubeflow pipelines. This feature was originally built from the Tekton Pipelines, With the 1.9 release, the pipeline will also support the CNCF Argo project in order to “align with the upstream community,” Eder said.
“Being able to express your operational parameters as a pipeline code is hugely enabling from an automation standpoint,” Eder said.
The pipeline feature stitches together two users of Kubeflow: the data scientist and the machine learning engineer.
One ancillary project that Kubeflow community has been working on is KServe, a serverless-based inference front end, which recently graduated Kubeflow incubation as its own project. Out-of-box runtimes have recently been added for HuggingFace and vLLM.
“KServe will allow us to auto-serve inference,” Eder said, adding that this is a difficult problem that hasn’t been fully solved yet.
What Work Needs To Be Done on Kubeflow?
In a Kubeflow Summit talk earlier this year, “The Good, Bad and Missing Parts of Kubeflow,” Red Hat Senior Software Engineer,Ricardo Martinelli de Oliveira, who served as the release manager for Kubeflow 1.9, discussed the work that still needs to be done.
In a recent user survey, Kubeflow users said they enjoyed the use of pipelines and notebooks but wanted for more stability with these features. In that same survey, users grumbled about the weak installation — many installed from the raw manifests. There are distributions (such as Red Hat’s), but there needs to be more conformance testing. The documentation on the distributions available are out of date. Some components are barely documented, or not documented at all.
“There are some parts of the [installation documentation] that don’t look good for users,” Martinelli de Oliveira admitted.
This post has been updated with the appropriate Kubeflow capitalization.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.