
包阅导读总结
1. 关键词:WebGPU、GPGPU、加速计算、着色器、数据创建
2. 总结:
本文主要介绍了前端利用 WebGPU 的计算管线实现对鸟类群居行为的模拟加速计算。提到 WebGPU 相比 WebGL 的优势,讲解了创建上下文、着色器模块、管线和数据的过程,包括相关代码和配置细节。
3. 主要内容:
– 引入
– 提出前端使用 GPGPU 做加速计算及相关问题。
– WebGPU 介绍
– 性能提升,多了计算管线。
– 学习网站:WebGPU Samples 和 WebGPU API。
– WebGPU 实现过程
– 创建上下文
– 获取 GPU 对象、请求适配器和逻辑设备。
– 创建并配置 WebGPU 上下文。
– 创建着色器模块
– 实例化渲染的着色器模块。
– 计算着色器模块,用于模拟鸟类群居行为。
– 创建管线
– 渲染管线,复杂的配置项。
– 计算管线,相对简单。
– 创建数据
– 模拟小鸟的三角形数据。
– 模拟群居行为规则的数据。
– 所有鸟儿初始的位置数据。
思维导图: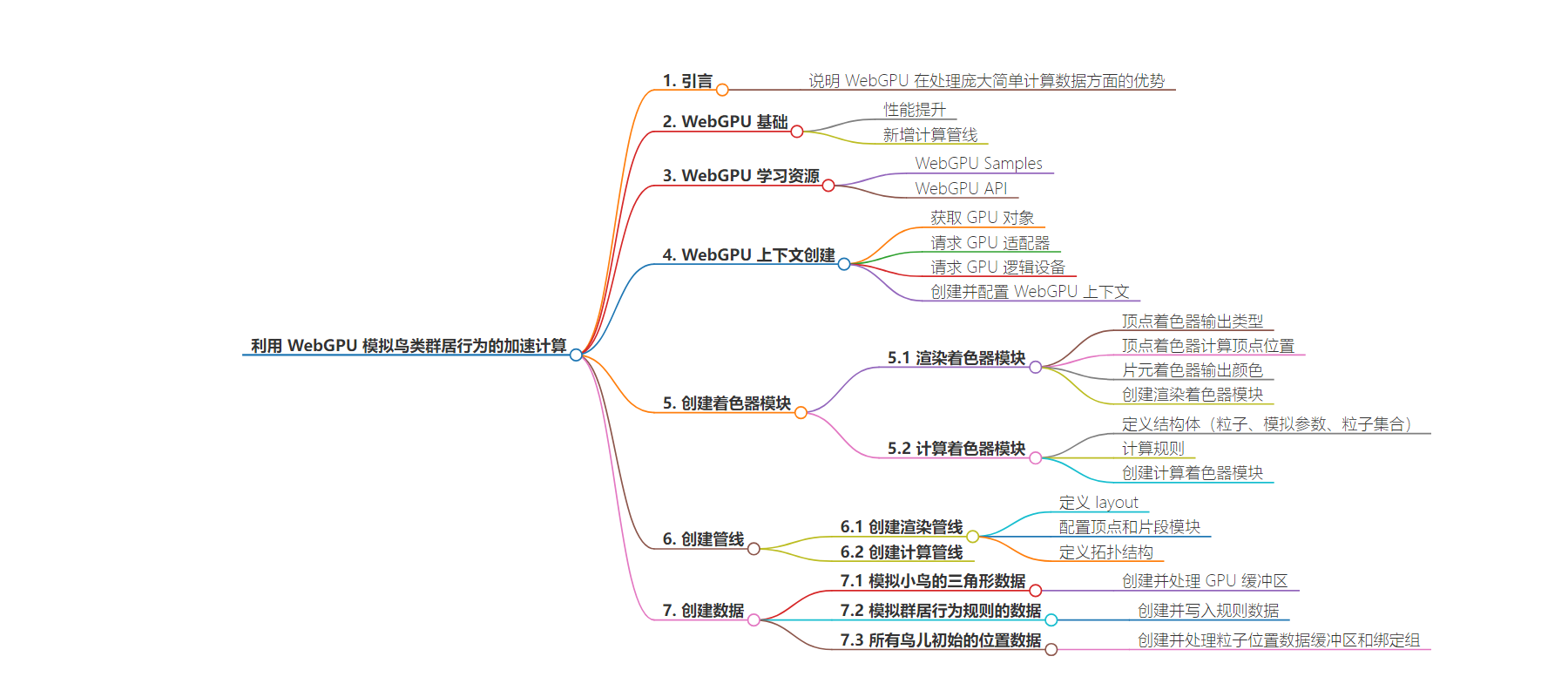
文章地址:https://mp.weixin.qq.com/s/8bIsOi3Mw–5ZmI-W8vkvA
文章来源:mp.weixin.qq.com
作者:你也向往长安城吗
发布时间:2024/7/12 7:36
语言:中文
总字数:3515字
预计阅读时间:15分钟
评分:85分
标签:WebGPU,GPGPU,前端技术,数据加速,计算管线
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
什么?业务上有千亿级数据需要计算?别着急,看完这篇文章!!!
阅读这篇文章,有webgl / glsl 基础会阅读更加顺利一些,其中有 wgsl 着色器部分,即使它与 glsl 完全不同
关于 WEBGPU
1. WebGPU 相比于 WebGL 性能上巨大提升
2. WebGPU 相比于 WebGL 多了一条计算管线
WebGPU 学习网站:WebGPU Samples和 WebGPU API
相信大家都知道显卡可以用于AI训练,挖矿,这离不开 GPGPU (通用计算,去除了GPU的图形显示部分)
如果说CPU是一支笔,可以一笔一笔写下《兰亭序》,那么GPU就是喷绘机器,可以在瞬间喷出《兰亭序》
这篇文章利用的就是 WEBGPU 的计算管线(compute pass)实现,庞大的数据量,但是简单的计算,模拟数万只鸟儿的群居行为,从下面的图一变换到图二,源码来自WebGPU Samples 针对这个demo我做了部分简化,以及增加了GPU的数据读取部分,毕竟计算的最终目的是拿到计算的结果供我们使用。


正文
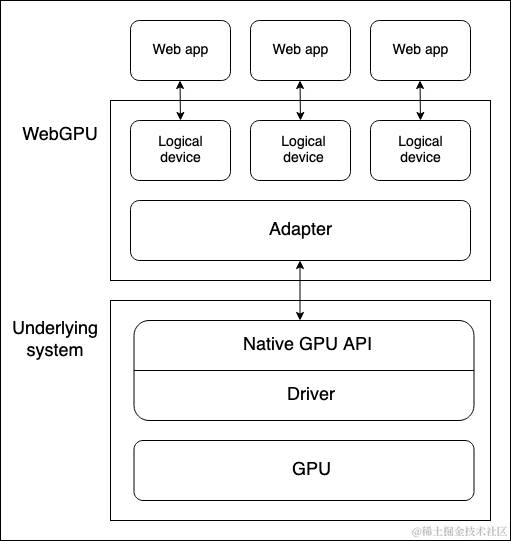
WEBGPU上下文的创建,GPU逻辑设备的请求
创建WebGPU上下文,需要获取GPU对象,请求GPU适配器,再通过GPU适配器请求GPU逻辑设备。
// 获取GPU对象
const gpu = navigator.gpu;
if ( !gpu ) throw new Error( "GPU is not available" );
// 请求GPU适配器,异步过程
const adapter = await gpu.requestAdapter();
if ( !adapter ) throw new Error( "COULD NOT REQUEST GPU ADAPTER" );
// 通过GPU适配器请求GPU逻辑设备
const device = await adapter.requestDevice();
if ( !device ) throw new Error( "COULD NOT REQUEST GPU DEVICE" );
// 创建WebGPU上下文
canvas.width = window.innerWidth;
canvas.height = window.innerHeight;
const context = canvas.getContext( "webgpu" );
if ( !context ) throw new Error( "COULD NOT GET GPU CONTEXT" );
// 配置WebGPU上下文
const presentationFormat = gpu.getPreferredCanvasFormat();
context.configure( {
device,
format: presentationFormat,
alphaMode: "premultiplied"
} );
创建着色器模块
1. 创建用于实例化渲染的着色器模块
自己学习了一段时间的wgsl,能够解释的有限,wgsl类rust语言,rust我也不会,哈哈哈。
在 wgsl 中 @builtin(n)***、***@location(n)***、***@group(n) 等关键字是描述结构体或者函数中的参数的位置,这个位置与我们在js中创建渲染管线的时候的配置相对应,其中 @location(n) 用于连接顶点着色器和片元着色器,在glsl中,是用***varying***传递;-> 符号表示函数的返回值;***:*** 描述变量类型,这个通用。
// 顶点着色器的输出类型,location 索引为 4 ,则在片元着色器可以通过 location(4) 获取到 color
struct VertexOutput {
@builtin(position) position : vec4f,
@location(4) color : vec4f,
}
// 顶点着色器,计算顶点位置,此处输入参数是 vec2f 类型的数据表示粒子位置
@vertex
fn main(
@location(0) a_particlePos : vec2f,
@location(1) a_particleVel : vec2f,
@location(2) a_pos : vec2f,
) -> VertexOutput{
let angle = -atan2(a_particleVel.x, a_particleVel.y);
let pos = vec2(
a_pos.x * cos(angle) - a_pos.y * sin(angle),
a_pos.x * sin(angle) + a_pos.y * cos(angle)
);
var output : VertexOutput;
output.position = vec4(pos + a_particlePos, 0.0, 1.0);
output.color = vec4(
1.0 - sin(angle + 1.0) - a_particleVel.y,
pos.x * 100.0 - a_particleVel.y + 0.1,
a_particleVel.x + cos(angle + 0.5),
1.0);
return output;
}
// 片元着色器,输出颜色
@fragment
fn frag_main(@location(4) color : vec4f) -> @location(0) vec4f {
return color;
}
根据上面写的着色器,创建着色器模块
const spriteShaderModule = device.createShaderModule( { code: spriteWGSL } );
2. 创建计算着色器模块
计算着色器模块,仅用于计算,对于鸟类的群居行为,可以通过计算模拟。针对每个鸟儿的下一个位置,我们遍历所有的鸟儿,找到距离这只鸟距离D以内的所有鸟儿的数据,根据这部分数据,计算出这只鸟儿下一刻的数据。
我们创建2个数组 particlesA 和 particlesB ,两个数组存放着相同的类型但是不同的时间下的数据。为什么需要两个呢?
假设 k 为时间 ,在 k 为整数时
k : N 个鸟儿开始的默认位置假设存放在***particlesA***
k + 1 : 在这个时间,计算着色器需要读取 particlesA ,也就是鸟儿上一次的位置数据,根据这个数据计算,得到***particlesB*** ,将鸟儿位置更新为***particlesB***
k + 2 :同理,取鸟儿上一次的位置,返回鸟儿计算后的位置
整个 wgsl 的代码就是在计算这个流程。
下述 wgsl 代码中: <\uniform> 描述数据来源 uniform ,学过 webgl 的应该知道。***<storage,read_write>*** 描述数据的可操作类型,***storage***可存储,***read_write***表示数据的可写入,可读取,
struct Particle {
pos : vec2f,
vel : vec2f,
}
// 鸟儿群居计算的规则
struct SimParams {
deltaT : f32,
rule1Distance : f32,
rule2Distance : f32,
rule3Distance : f32,
rule1Scale : f32,
rule2Scale : f32,
rule3Scale : f32,
}
struct Particles{
particles : array<Particle>
}
// <storage,read> 描述可以数据的操作类型
@binding(0) @group(0) var<uniform> params : SimParams;
@binding(1) @group(0) var<storage, read> particlesA : Particles;
@binding(2) @group(0) var<storage, read_write> particlesB : Particles;
// 描述每一个计算通道的大小
@compute @workgroup_size(64)
fn main(
@builtin(global_invocation_id) GlobalInvovationID : vec3u
)
{
var index = GlobalInvovationID.x;
var vPos = particlesA.particles[index].pos;
var vVel = particlesA.particles[index].vel;
var cMass = vec2(0.0);
var cVel = vec2(0.0);
var colVel = vec2(0.0);
var cMassCount = 0u;
var cVelCount = 0u;
var pos : vec2f;
var vel : vec2f;
for(var i = 0u; i < arrayLength(&particlesA.particles); i++)
{
if(i == index)
{
continue;
}
pos = particlesA.particles[i].pos.xy;
vel = particlesA.particles[i].vel.xy;
if(distance(pos, vPos) < params.rule1Distance)
{
cMass += pos;
cMassCount ++;
}
if(distance(pos, vPos) < params.rule2Distance)
{
colVel -= pos - vPos;
}
if(distance(pos, vPos) < params.rule3Distance)
{
cVel += vel;
cVelCount++;
}
}
if(cMassCount > 0)
{
cMass = (cMass / vec2(f32(cMassCount))) - vPos;
}
if(cVelCount > 0)
{
cVel /= f32(cVelCount);
}
vVel += (cMass * params.rule1Scale) + (colVel * params.rule2Scale) + (cVel * params.rule3Scale);
//clamp velocity for a more pleasing simulation
vVel = normalize(vVel) * clamp(length(vVel), 0.0, 0.1);
//kinematic update
vPos = vPos + (vVel * params.deltaT);
//Wrap around boundary
if (vPos.x < -1.0)
{
vPos.x = 1.0;
}
if (vPos.x > 1.0)
{
vPos.x = -1.0;
}
if (vPos.y < -1.0)
{
vPos.y = 1.0;
}
if (vPos.y > 1.0)
{
vPos.y = -1.0;
}
//Write back
particlesB.particles[index].pos = vPos;
particlesB.particles[index].vel = vVel;
}
根据计算着色器的代码,创建计算着色器模块
const spriteUpdateShaderModule = device.createShaderModule( { code: updateSpritesWGSL } );
创建管线
这个过程是根据着色器的模块创建的,里面涉及到很多的配置项,要写很多遍才会有印象。每个属性的类型,总之十分复杂,我也只能照葫芦画瓢,
1. 创建渲染管线
layout 定义了相关GPU资源的结构和用途
***location***对于 wgsl 代码中的 location
const renderPipeline = device.createRenderPipeline( {
layout: 'auto',
vertex: {
module: spriteShaderModule,
buffers: [
{
// instanced particles buffer
arrayStride: 4 * 4,
stepMode: 'instance',
attributes: [
{
// instance position 这里对于到 wgsl 中的 loaction
shaderLocation: 0,
offset: 0,
format: 'float32x2',
},
{
// instance velocity
shaderLocation: 1,
offset: 2 * 4,
format: 'float32x2',
},
],
},
{
// vertex buffer
arrayStride: 2 * 4,
stepMode: 'vertex',
attributes: [
{
// vertex positions
shaderLocation: 2,
offset: 0,
format: 'float32x2',
},
],
},
],
},
fragment: {
module: spriteShaderModule,
targets: [
{
format: presentationFormat,
},
],
},
primitive: {
// 拓扑结构,三角形
topology: 'triangle-list',
},
} );
2. 创建计算管线
计算管线的创建比较简单
const computePipeline = device.createComputePipeline( {
layout: 'auto',
compute: {
module: spriteUpdateShaderModule
},
} );
创建数据
做了那么多的准备工作,数据还没有创建,创建完数据之后,需要创建渲染通道和计算通道,将数据传入通道内
1. 模拟小鸟的三角形数据
将gpu数据的读取到js,并不是很麻烦,需要将gpu缓冲区特定区域数据映射到js中,然后再取消映射,取消映射之后gpu可再次使用这些数据
getMappedRange 返回一个ArrayBuffer,其中包含指定区域中 的映射内容
GPUBuffer.mapState只读属性,返回GPUBuffer的映射状态
const vertexBufferData = new Float32Array( [
-0.01, -0.02, 0.01,
-0.02, 0.0, 0.02,
] );
const spriteVertexBuffer = device.createBuffer( {
size: vertexBufferData.byteLength,
// 用于顶点着色器
usage: GPUBufferUsage.VERTEX,
mappedAtCreation: true,
} );
new Float32Array( spriteVertexBuffer.getMappedRange() ).set( vertexBufferData );
spriteVertexBuffer.unmap();
2. 模拟群居行为规则的数据
我了解到,针对uniform类型数据,可以直接写入队列,供各个管线使用。
GPUBufferUsage.UNIFORM描述 GPUBuffer 作为 uniform 提供使用GPUBufferUsage.COPY_DST 描述 GPUBuffer 可以作为拷贝的目的地(DST:destination)GPUBufferUsage.COPY_SRC 描述 GPUBuffer 可以作为拷贝源(SRC:source)
const simParams = {
deltaT: 0.04,
rule1Distance: 0.1,
rule2Distance: 0.025,
rule3Distance: 0.025,
rule1Scale: 0.02,
rule2Scale: 0.05,
rule3Scale: 0.005,
};
const simParamBufferSize = 7 * Float32Array.BYTES_PER_ELEMENT;
const simParamBuffer = device.createBuffer( {
size: simParamBufferSize,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
} );
device.queue.writeBuffer(
simParamBuffer,
0,
new Float32Array( [
simParams.deltaT,
simParams.rule1Distance,
simParams.rule2Distance,
simParams.rule3Distance,
simParams.rule1Scale,
simParams.rule2Scale,
simParams.rule3Scale,
] )
);
3. 所有鸟儿初始的位置数据
const numParticles = 1500;
const initialParticleData = new Float32Array( numParticles * 4 );
for ( let i = 0; i < numParticles; ++i ) {
initialParticleData[ 4 * i + 0 ] = 2 * ( Math.random() - 0.5 );
initialParticleData[ 4 * i + 1 ] = 2 * ( Math.random() - 0.5 );
initialParticleData[ 4 * i + 2 ] = 2 * ( Math.random() - 0.5 ) * 0.1;
initialParticleData[ 4 * i + 3 ] = 2 * ( Math.random() - 0.5 ) * 0.1;
}
const particleBuffers: GPUBuffer[] = new Array( 2 );
const particleBindGroups: GPUBindGroup[] = new Array( 2 );
for ( let i = 0; i < 2; ++i ) {
particleBuffers[ i ] = device.createBuffer( {
size: initialParticleData.byteLength,
// 因为准备将数据读取到 js ,所以新增了 GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC,
mappedAtCreation: true,
} );
// 将缓冲区映射到js,存入数据
new Float32Array( particleBuffers[ i ].getMappedRange() ).set(
initialParticleData
);
// 取消映射,供GPU再次使用数据
particleBuffers[ i ].unmap();
}
for ( let i = 0; i < 2; ++i ) {
// 用于给定索引的后续计算命令的[`GPUBindGroup`]
particleBindGroups[ i ] = device.createBindGroup( {
layout: computePipeline.getBindGroupLayout( 0 ),
entries: [
{
binding: 0,
resource: {
buffer: simParamBuffer,
},
},
{
binding: 1,
resource: {
buffer: particleBuffers[ i ],
offset: 0,
size: initialParticleData.byteLength,
},
},
{
binding: 2,
resource: {
buffer: particleBuffers[ ( i + 1 ) % 2 ],
offset: 0,
size: initialParticleData.byteLength,
},
},
],
} );
}
计算
巩固一下知识,我们需要将 gpu 数据读取到 js 中,那么需要创建一个 GPUBuffer 用于映射数据。
对于这个 buffer ,长度设置为鸟的长度,如果有其他需求,这个长度可以自定义。用于映射读取,以及作为拷贝目的地。所以在 usage 用了 COPY_DST 和 MAP_READ
const stagingBuffer = device.createBuffer( {
size: initialParticleData.byteLength,
usage: GPUBufferUsage.MAP_READ | GPUBufferUsage.COPY_DST
} );
创建渲染通道的配置对象,颜色附着
const renderPassDescriptor: GPURenderPassDescriptor = {
colorAttachments: [
{
view: undefined as GPUTextureView, // 稍后赋值
clearValue: [ 0, 0, 0, 1 ],
loadOp: 'clear',
storeOp: 'store',
},
],
};
执行动画帧函数,执行渲染管线和计算管线
async function frame () {
// 赋值视图
renderPassDescriptor.colorAttachments[ 0 ].view = context
.getCurrentTexture()
.createView();
// 创建GPU编码器
const commandEncoder = device.createCommandEncoder();
{
// 计算通道解析器
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline( computePipeline );
passEncoder.setBindGroup( 0, particleBindGroups[ t % 2 ] );
// 分配的组的数量,这个可以理解为,需要GPU同时进行多少计算。如果需要在 JS 中遍历 10000 次
// 那么在 GPU 中,只需要分配 10000个工作组,执行1次即可。
passEncoder.dispatchWorkgroups( Math.ceil( numParticles / 64 ) );
passEncoder.end();
}
{
// 渲染通道解析器
const passEncoder = commandEncoder.beginRenderPass( renderPassDescriptor );
passEncoder.setPipeline( renderPipeline );
passEncoder.setVertexBuffer( 0, particleBuffers[ ( t + 1 ) % 2 ] );
passEncoder.setVertexBuffer( 1, spriteVertexBuffer );
passEncoder.draw( 3, numParticles, 0, 0 );
passEncoder.end();
}
// 将存储鸟儿坐标数据的 GPUBuffer,拷贝到我们上面创建的 staginBuffer
commandEncoder.copyBufferToBuffer(
particleBuffers[ ( t + 1 ) % 2 ],
0, // Source offset
stagingBuffer,
0, // Destination offset
initialParticleData.byteLength,
);
device.queue.submit( [ commandEncoder.finish() ] );
// 映射 staginBuffer 的指定范围,以供 `getMappedRange` 使用
await stagingBuffer.mapAsync(
GPUMapMode.READ,
0, // Offset
initialParticleData.byteLength, // Length
);
// 读取GPUBuffer数据到js中
const copyArrayBuffer = stagingBuffer.getMappedRange( 0, initialParticleData.byteLength );
const data = copyArrayBuffer.slice( 0 );
stagingBuffer.unmap();
// 打印
console.log( new Float32Array( data ) );
++t;
requestAnimationFrame( frame );
}
frame()
总结
上述的例子,把渲染管线相关的代码全部删除,就是单纯的执行计算管线,纯纯的计算管线的代码我也会放在 gitee中
我用笔记本的3060的显卡,数据量设置为30000,可以流畅执行,每秒60次,如果在cpu中执行计算,需要 300003000060 = 540 0000 0000 次计算量。使用 gpgpu 每秒执行了 540亿次计算,模拟了鸟类群居行为,如果去掉渲染管线,那么计算速度还可以提升。
在业务中遇到大数据的处理,各位可以考虑一下这个方式哦!!!!!!