
包阅导读总结
1. 关键词:AI 技术、模型开发、开源工具、多智能体、视觉任务
2. 总结:
本文涵盖了多种 AI 相关技术和模型的信息,包括视觉任务的解决、文本语音模型、多智能体系统框架等,还介绍了一些开源工具和新的流程、研究成果。
3. 主要内容:
– Vision Agent 开源:帮助利用代理框架生成代码解决视觉任务
– 适用于多种图像和视频处理领域
– 为不同技术背景用户提供工具和资源
– Llama Agents:异步构建多智能体系统的框架
– 包含多智能体通信等功能
– 目标是提供强大、灵活且易用的框架
– DEX-TTS:新型富表现力的文本转语音模型
– 采用参考语音改善风格和泛化
– 为语音交互提供新可能
– AutoCodeRover 开源:自动化软件改进工具
– 结合大型语言模型和代码搜索技术
– 提高软件开发效率和质量,使用简单
– Web2Code 开源:网页代码生成新流程
– 涉及创建新配对、优化现有数据等
– 提高生成效率和精度
– Composio:为 Agent 提供处理复杂任务的工具
– 包括数据分析等
– 基于需求设计,有帮助
– ScreenPipe:用 LLM 将屏幕转化为动作的开源软件
– 提供新交互方式
– 改变工作和生活方式
– LosslessCut:无损视频/音频编辑工具
– 免费开源,不影响原始质量
– 支持多种功能和平台
– Lambda Labs 训练 Open Sora 视频模型用于乐高电影
– 改变乐高动画制作方式
– 展示技术实力和研发能力
– MUMU 视觉模型:将文本和图像交织生成
– 超越纯文本条件化模型
– 增强理解和表达能力
– Mosaic 团队与 PyTorch 合作扩展 MoEs 模型
– MoEs 是一种深度学习模型结构
– 利用 PyTorch 提升性能和准确性
– 生成式 AI 投资:有潜力但存在弱点和挑战
– 改进 QMIX:多智能体强化学习方法
– 增加局部 Q 价值学习方法
– 提升探索效率和任务表现
思维导图: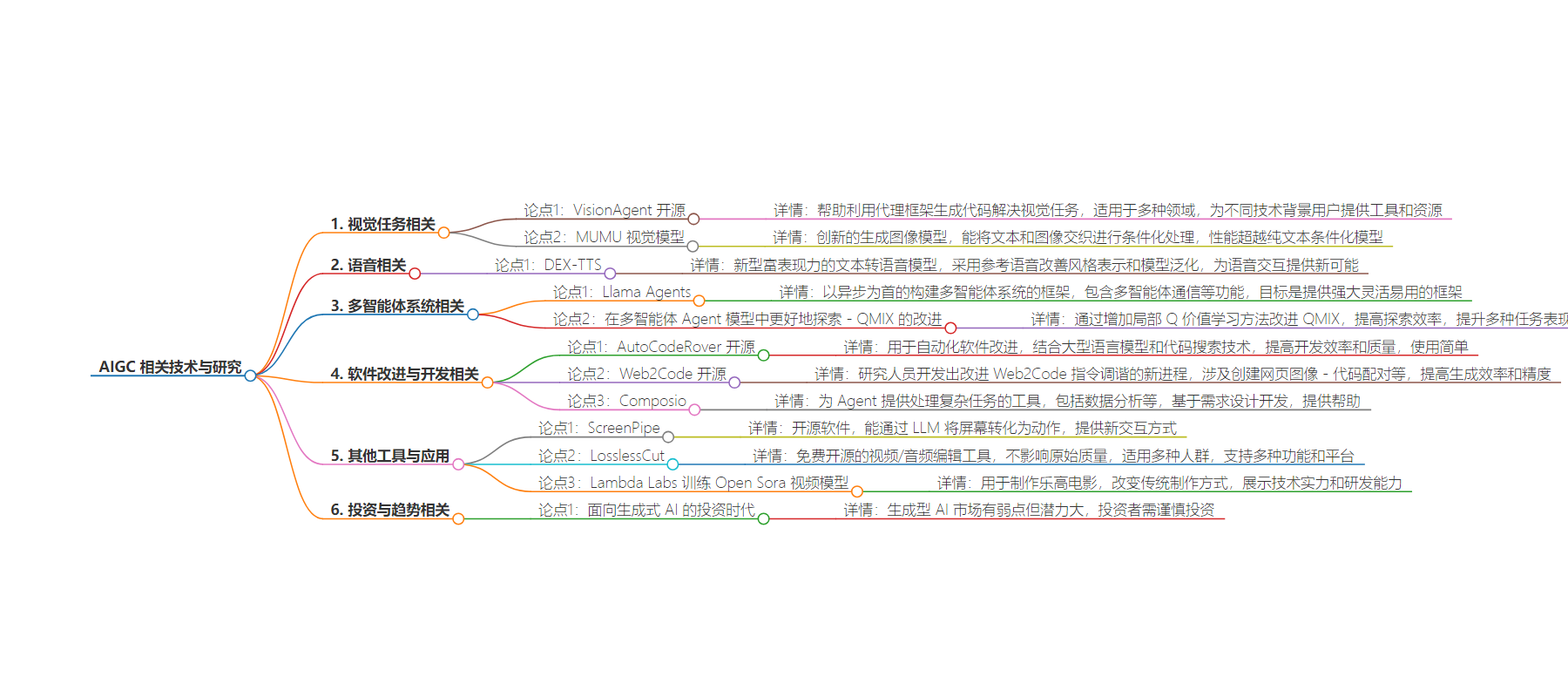
文章地址:https://mp.weixin.qq.com/s/5A4fk9tpqQ6Oij5Qxsmn8w
文章来源:mp.weixin.qq.com
作者:漫话开发者
发布时间:2024/7/2 17:23
语言:中文
总字数:5035字
预计阅读时间:21分钟
评分:89分
标签:AI,计算机视觉,多智能体系统,文本转语音,软件改进
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
1. Vision Agent开源:专注解决视觉任务
Vision Agent是一个强大的库,旨在帮助您利用代理框架生成代码,以解决您的视觉任务。该库可用于各种需要处理图像和视频的应用场景,包括但不限于计算机视觉、机器学习、人工智能等领域。借助Vision Agent,您可以轻松地创建和训练代理,让它们能够理解和解析图像数据,从而完成各种复杂的视觉任务。无论您是一个经验丰富的开发者,还是刚刚接触计算机视觉的新手,Vision Agent都能为您提供强大的工具和资源,帮助您快速高效地解决视觉任务。
划重点
-
Vision Agent是一个帮助用户利用代理框架生成代码的库 -
Vision Agent为所有用户提供了强大的工具和资源,无论他们的技术背景如何
标签:Vision Agent, GitHub Repo, 计算机视觉
原文链接见文末/1[1]
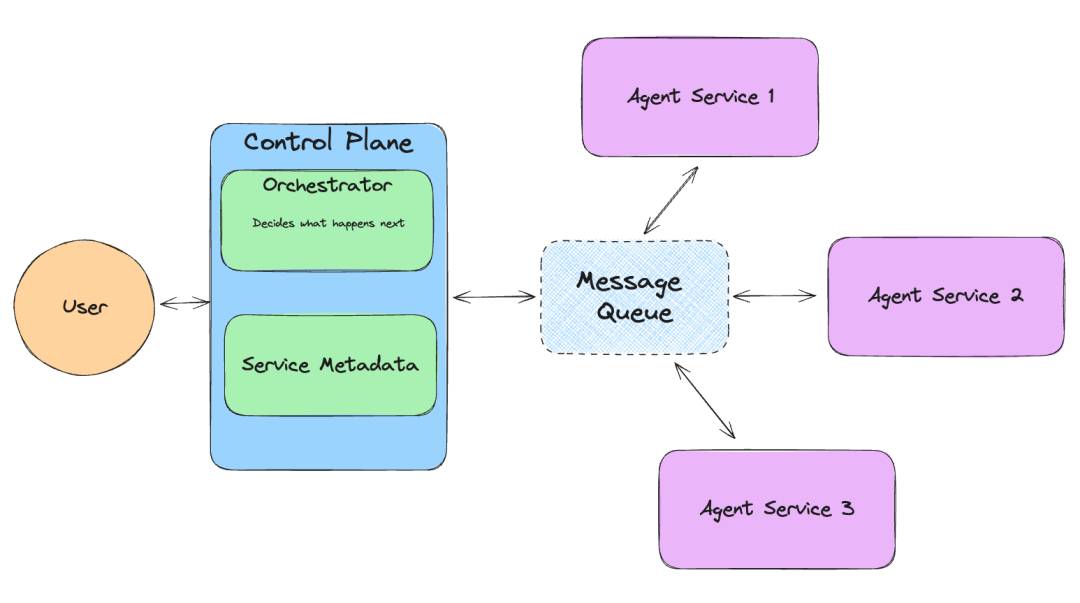
2. Llama Agents-新一代多智能体系统构建框架
Llama Agents是一个以异步为首的框架,用于构建、迭代和生产多智能体系统,包括多智能体通信,分布式工具执行,人在环中等等。Llama Agents的目标是提供一个强大、灵活且易于使用的框架,以支持开发者在各种场景中快速实现多智能体系统的构建和优化。该框架的出现,解决了传统多智能体系统在构建过程中可能遇到的一系列问题,如复杂的通信管理、分布式执行的协调等,使得开发者可以更加专注于智能体的设计和性能优化。
划重点
-
Llama Agents是一个以异步为首的构建多智能体系统的框架。 -
该框架包含多智能体通信,分布式工具执行,人在环中等功能。 -
Llama Agents的目标是提供一个强大、灵活且易于使用的框架,以支持开发者在各种场景中快速实现多智能体系统的构建和优化。
标签:Llama Agents, 多智能体系统, GitHub Repo
原文链接见文末/2[2]
3. DEX-TTS:一种新型富表现力的文本转语音模型
DEX-TTS是一种全新的富有表现力的文本转语音(TTS)模型,它采用参考语音来改善风格表示和模型泛化。这种新型技术的出现,为语音技术领域开创了新的可能性。DEX-TTS模型通过参考语音,能够更准确地捕捉到语音风格的细微差异,从而在转化成语音时,保持其原有的表现力。这不仅能够提高语音的自然度,同时也能大幅度提升语音的可理解性。这种技术的实现,为未来的人工智能语音交互提供了新的可能。未来,我们可以期待更多的应用将采用这种技术,为我们的日常生活带来更多的便利。
划重点
-
DEX-TTS是一种全新的富有表现力的文本转语音(TTS)模型 -
DEX-TTS模型采用参考语音来改善风格表示和模型泛化 -
DEX-TTS模型的应用将为未来的人工智能语音交互提供新的可能
标签:DEX-TTS, TTS, AI
原文链接见文末/3[3]
4. AutoCodeRover-自动化软件改进工具开源
AutoCodeRover是一款新的工具,专门用于自动化软件改进,包括修复漏洞和添加功能。该工具结合了大型语言模型(LLM)和先进的代码搜索技术,以实现优化和提升。通过使用这款工具,开发者可以更有效地进行代码的修改和优化,大大提高了软件开发的效率和质量。这不仅可以节省大量的人力物力,还可以在短时间内完成大量的代码改进工作。此外,AutoCodeRover的使用非常简单,即使是初级开发者也能快速上手。在未来的软件开发领域,AutoCodeRover将成为一个不可或缺的重要工具。
划重点
-
AutoCodeRover是一款新的自动化软件改进工具。 -
结合了大型语言模型(LLM)和先进的代码搜索技术,提高了软件开发的效率和质量。 -
AutoCodeRover的使用简单,初级开发者也能快速上手。
标签:AutoCodeRover, 软件改进, 大型语言模型
原文链接见文末/4[4]
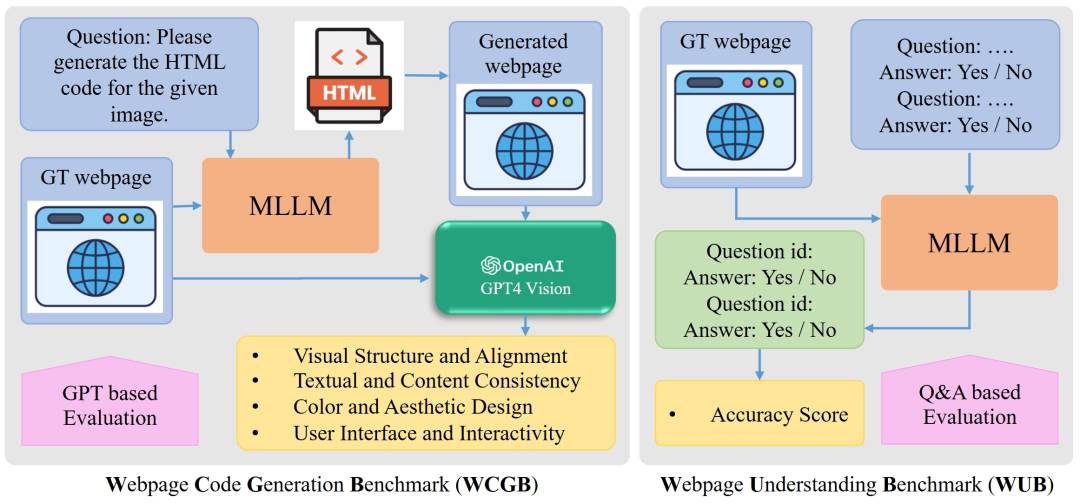
5. Web2Code开源-网页代码生成的新流程
研究人员已经开发出一种新的流程,以改进Web2Code指令调谐。这个过程涉及到创建新的网页图像-代码配对,优化现有的网页代码生成数据,创建新的文本问题-回答配对,以及优化现有的网页理解数据。这个新进程的开发,不仅有利于提高网页代码生成的效率,也有助于提升网页理解和代码生成的精度。通过创新的方式,研究人员能够把网页图像与代码紧密配对,同时也能更准确地回答文本问题,从而实现对网页的更深层次理解。这一新的进程,无疑将为网页代码生成领域带来一场革新。
划重点
-
研究人员开发出改进Web2Code指令调谐的新进程 -
新进程涉及到创建新的网页图像-代码配对,优化现有网页代码生成数据 -
新进程有利于提高网页代码生成的效率,提升网页理解和代码生成的精度
标签:Web2Code, 网页代码生成, 网页理解
原文链接见文末/5[5]
6. Composio:赋能Agent,挑战复杂任务
Composio,这是一个在GitHub Repo上的项目,其主要目标是为Agent提供精心制作的工具,使他们能够处理复杂的任务。这些工具不仅易于使用,而且具有高度的灵活性和可定制性。Agent在使用这些工具时,可以更加有效地完成工作,同时也可以提高他们的工作效率。Composio的工具包括但不限于数据分析、项目管理和任务自动化等。这些工具都是基于Agent的实际需求进行设计和开发的,因此它们在实际使用中可以提供极大的帮助。
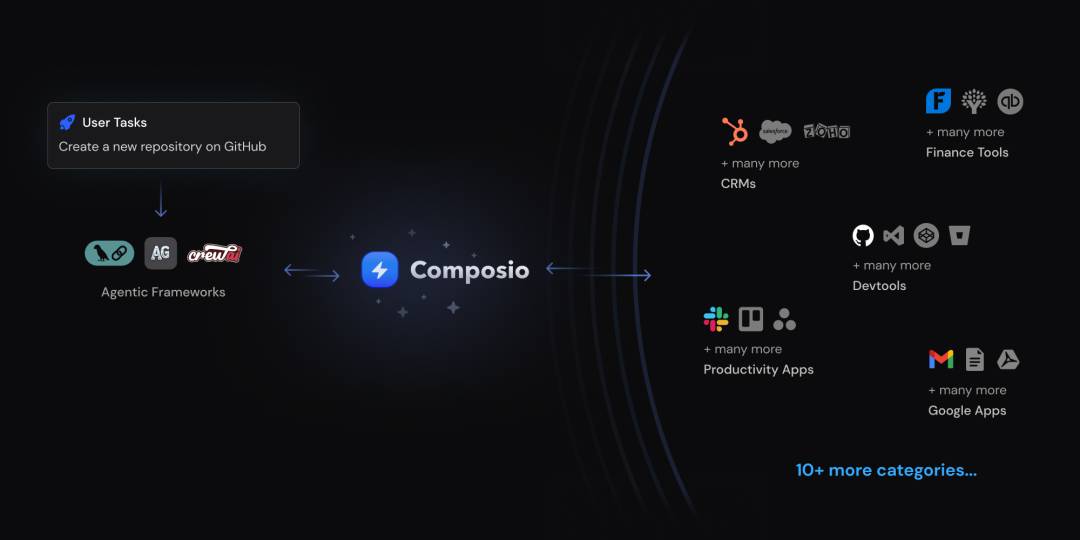
划重点
-
Composio为Agent提供工具以处理复杂任务 -
Composio的工具包括数据分析、项目管理和任务自动化等 -
这些工具基于Agent的实际需求进行设计和开发,提供极大的帮助
标签:Composio, Agent, GitHub Repo
原文链接见文末/6[6]
7. ScreenPipe:用LLM将屏幕转化为动作
最新的技术开发,现在可以通过LLM将您的屏幕转化为一系列的动作。这是一款开源软件,已经在GitHub Repo上发布。它允许用户通过简单的编程语言将屏幕上的动态信息转化为操作,打开了一个全新的交互方式。它提供了新的可能性,使得我们能够更好地利用屏幕进行各种复杂的操作。这个工具的发布,不仅将改变我们的工作方式,也将为我们的日常生活带来便利。
划重点
-
这是一款开源软件,已经在GitHub Repo上发布 -
它提供了新的可能性,使得我们能够更好地利用屏幕进行各种复杂的操作
标签:LLM, GitHub Repo, Screen Pipe
原文链接见文末/7[7]
8. LosslessCut:无损视频/音频编辑的瑞士军刀
LosslessCut是一款免费、开源的视频/音频编辑工具,可以快速剪辑、裁剪、分离、合并视频/音频文件,而且完全不会影响文件的原始质量。它非常适用于需要快速剪辑视频/音频的人,比如YouTuber、播客、视频爱好者等等。除了剪辑功能之外,它还支持批量处理、调整音量、添加字幕、提取帧等功能。LosslessCut使用 Electron 技术开发,支持 Windows、macOS、Linux 三个平台。
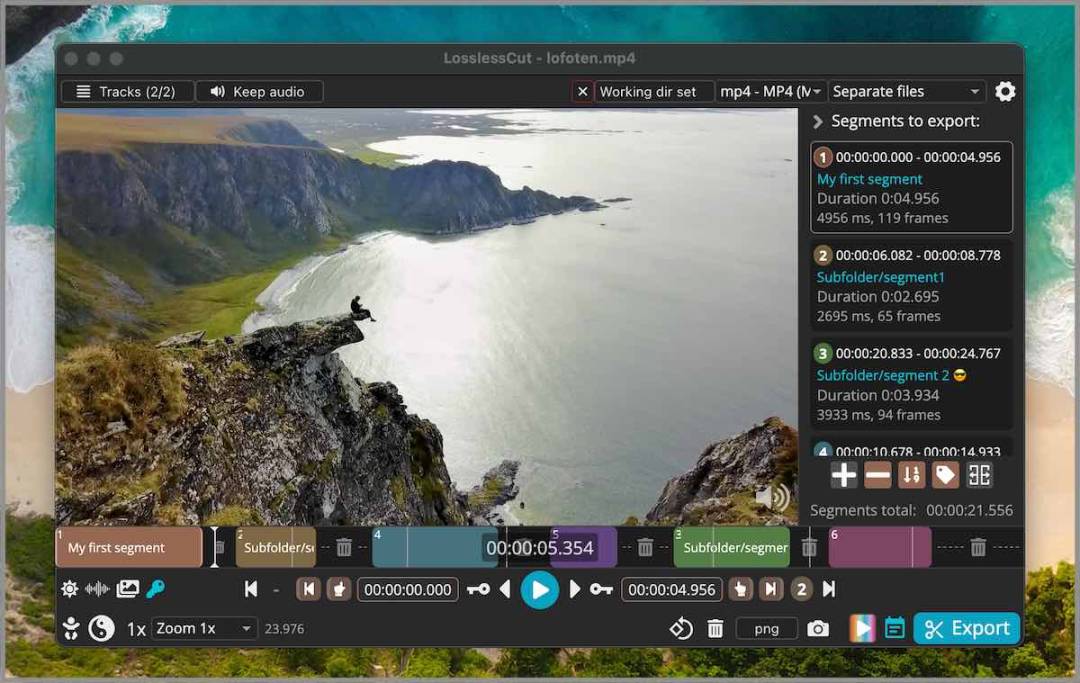
划重点
-
LosslessCut是一款免费、开源的视频/音频编辑工具 -
完全不会影响文件的原始质量,非常适用于需要快速剪辑视频/音频的人
标签:视频编辑, 音频编辑, 无损编辑
原文链接见文末/8[8]
9. Lambda Labs训练Open Sora视频模型,一键生成乐高电影
Lambda Labs最近在其1-click集群上训练了一个名为Open Sora的视频模型,用于制作乐高电影。这一技术的出现,不仅改变了乐高动画制作的传统方式,也为AI技术在创新应用中开辟了新的道路。利用这一模型,制作者可以方便快捷地生成乐高电影,无需繁琐的手动搭建和拍摄过程。这一技术的出现,使得乐高电影的制作更加便捷和高效。此外,此模型的训练也充分展示了Lambda Labs在AI领域的技术实力和研发能力。在未来,我们有理由相信,AI技术将在更多的领域发挥重要的作用,打开新的应用可能。
划重点
-
Lambda Labs在其1-click集群上训练了一个Open Sora视频模型,用于制作乐高电影。 -
此模型的训练展示了Lambda Labs在AI领域的技术实力和研发能力。
标签:Lambda Labs, Open Sora, 乐高电影
原文链接见文末/9[9]
10. MUMU视觉模型:强势引领图像和文本的交织生成
MUMU视觉模型是一种创新的生成图像模型,它的特点在于能够将文本和图像交织在一起进行更强的条件化处理。这种独特的方法使得MUMU视觉模型在性能上超越了纯文本条件化模型。MUMU视觉模型的核心优势在于,它不仅仅是将文本作为一种简单的输入,而是将其与图像紧密结合,形成一个整体的生成过程。这种结合方式增强了模型对图像和文本信息的理解和表达能力,从而提高了生成图像的准确性和质量。总的来说,MUMU视觉模型通过高效地结合文本和图像,实现了更高的性能和更强的条件化能力,是一种具有广泛应用潜力的技术。
划重点
-
MUMU视觉模型是一种能够将文本和图像交织在一起进行更强的条件化处理的生成图像模型 -
MUMU视觉模型通过高效地结合文本和图像,实现了更高的性能和更强的条件化能力
标签:MUMU视觉模型, 生成图像模型, 文本图像交织
原文链接见文末/10[10]
11. 深入探讨:训练MoEs模型
Mosaic团队已与PyTorch合作,撰写关于如何扩展他们的MoEs模型至数千个GPU的文章。MoEs,全称Mixture of Experts,是一种深度学习的模型结构,其核心思想是将复杂的问题分解为若干个相对简单的子问题,然后由专家系统进行处理。PyTorch是一个开源的深度学习平台,提供了从研究原型到具有GPU支持的生产部署的广泛功能。Mosaic团队利用PyTorch的高效性能,使MoEs模型能够在数千个GPU上进行扩展和训练,进一步提升了模型的性能和准确性。
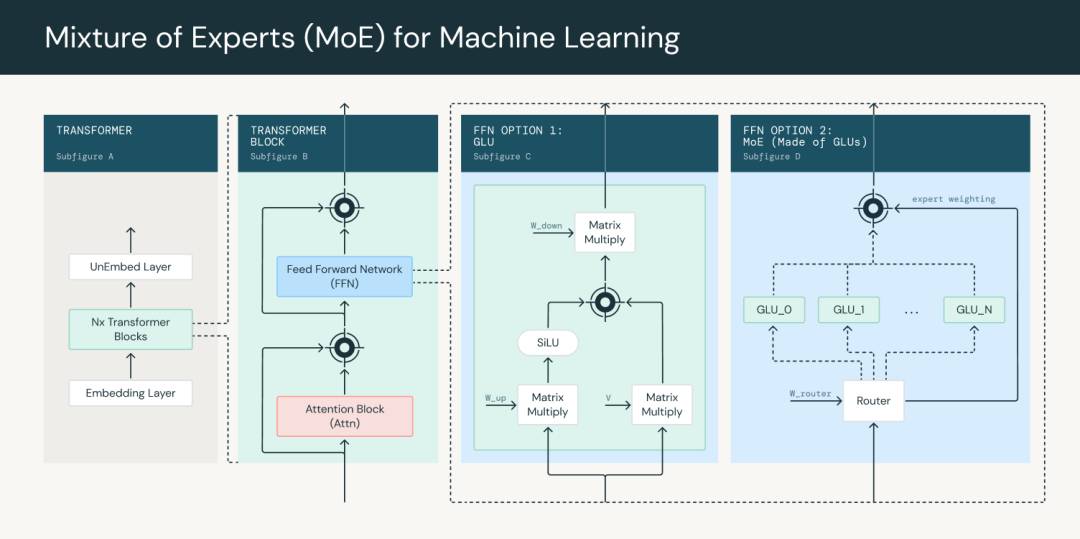
划重点
-
Mosaic团队与PyTorch合作,共同探讨扩展MoEs模型 -
利用PyTorch的高效性能,进一步提升了MoEs模型的性能和准确性
标签:Mosaic, PyTorch, MoEs
原文链接见文末/11[11]
12. 面向生成式AI的投资时代
尽管目前处在一种资金“狂热”的状态,但生成型AI市场已经开始出现了一些弱点。这种新型的AI技术正在迅速发展,吸引了大量的投资者关注。然而,由于市场竞争激烈,许多初创公司面临着巨大的挑战。尽管如此,投资者们依然对这个领域充满了信心,认为生成型AI有着巨大的发展潜力。在接下来的几年里,我们可以预见到生成型AI将会在许多行业中发挥重要的作用,包括制造业、医疗保健、娱乐业等等。然而,投资者需要小心翼翼地进行投资,以避免可能出现的风险。
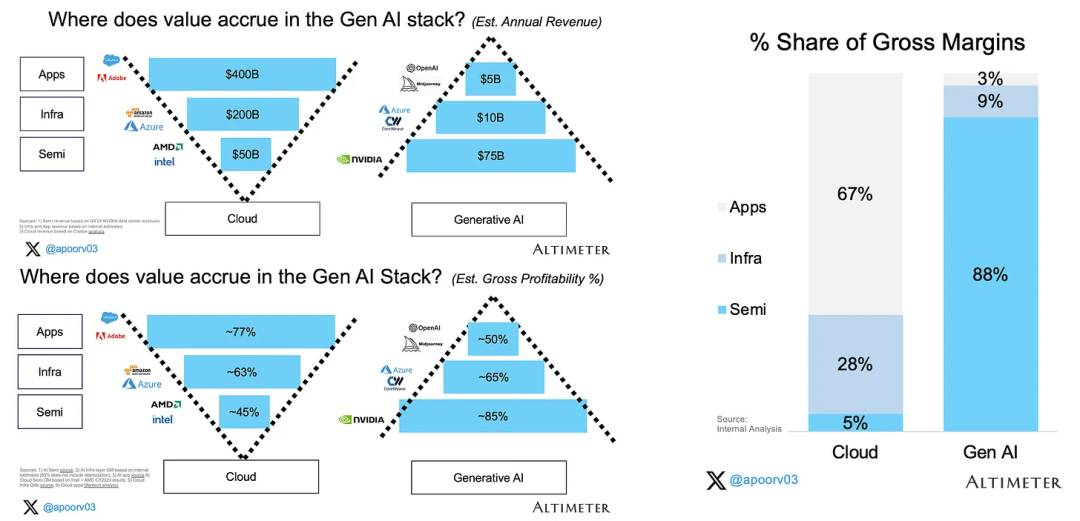
划重点
标签:AI, Investment, Market Trends
原文链接见文末/12[12]
13. 论文:在多智能体Agent模型中更好地探索-QMIX的改进
科研人员已经通过在最大熵框架内增加了一个局部Q价值学习方法,改进了被广泛应用的多智能体强化学习方法QMIX。QMIX是一个众所周知的多代理强化学习方法,它能有效地解决多代理学习中的挑战,如策略的协调和通信难题。然而,QMIX在探索空间中的效率仍然有待提高。为了解决这个问题,研究人员引入了局部Q价值学习方法,该方法可以更准确地估计每个代理的Q价值,从而在更大范围内进行更有效的探索。这一改进使得QMIX在多种任务中的表现都有所提升。这项新的研究为多智能体系统提供了更有效的学习方法,有望推动多智能体强化学习领域的进一步发展。
划重点
-
科研人员通过在最大熵框架内增加局部Q价值学习方法,改进了多智能体强化学习方法QMIX。 -
这种改进使QMIX在探索空间的效率得到提高,并在多种任务中的表现有所提升。 -
这项新研究为多智能体系统提供了更有效的学习方法,有望推动多智能体强化学习领域的进一步发展。
标签:QMIX, 强化学习, 多智能体模型
原文链接见文末/13[13]
每日AIGC
如果觉得内容有帮助,欢迎分享转发有需要的朋友。如果想第一时间跟踪AI前沿或者交个朋友,也可扫码添加微信(还请备注来意)。

👉关注「漫话开发者」,精选全球AI前沿科技资讯以及高质量AI开源工具,帮你给每天AI前沿划重点!👀
– END –
参考资料
原文链接见文末/1: https://github.com/landing-ai/vision-agent?utm_source=uwl.me
[2]原文链接见文末/2: https://github.com/run-llama/llama-agents?utm_source=uwl.me
[3]原文链接见文末/3: https://arxiv.org/abs/2406.19135v1?utm_source=uwl.me
[4]原文链接见文末/4: https://github.com/nus-apr/auto-code-rover?utm_source=uwl.me
[5]原文链接见文末/5: https://mbzuai-llm.github.io/webpage2code/?utm_source=uwl.me
[6]原文链接见文末/6: https://github.com/ComposioHQ/composio?utm_source=uwl.me
[7]原文链接见文末/7: https://github.com/louis030195/screen-pipe?utm_source=uwl.me
[8]原文链接见文末/8: https://github.com/mifi/lossless-cut?utm_source=uwl.me
[9]原文链接见文末/9: https://wandb.ai/lambdalabs/lego/reports/Text2Bricks-Fine-tuning-Open-Sora-in-1-000-GPU-Hours–Vmlldzo4MDE3MTky?utm_source=uwl.me
[10]原文链接见文末/10: https://arxiv.org/abs/2406.18790?utm_source=uwl.me
[11]原文链接见文末/11: https://pytorch.org/blog/training-moes/?utm_source=uwl.me
[12]原文链接见文末/12: https://eastwind.substack.com/p/investing-in-the-age-of-generative?utm_source=uwl.me
[13]原文链接见文末/13: https://arxiv.org/abs/2406.13930v1?utm_source=uwl.me