
包阅导读总结
1.
关键词:Spring AI、NVIDIA LLM API、集成、配置、开发
2.
总结:
Spring AI 现支持 NVIDIA 的大语言模型 API,本文介绍了如何配置和使用,包括创建账号、选择模型获取 API 密钥,添加依赖和环境变量等,还提供了代码示例和注意事项。
3.
主要内容:
– Spring AI 与 NVIDIA LLM API 集成
– 支持多种模型
– 可通过熟悉的 Spring AI API 使用 NVIDIA 的 LLMs
– 配置步骤
– 前置条件:创建 NVIDIA 账号,选择模型,获取 API 密钥
– 依赖:添加 Spring AI OpenAI 启动器
– 环境变量或应用属性配置
– 代码示例
– ChatController 类中的生成和流生成端点
– NvidiaLlmApplication 类中的工具/函数调用示例
– 关键考虑点
– 模型选择
– API 兼容性
– 性能
– 特殊模型
– API 限制
– 参考资料和结论
– 参考文档
– 强调集成带来新可能,要关注更新和适配自身需求
思维导图: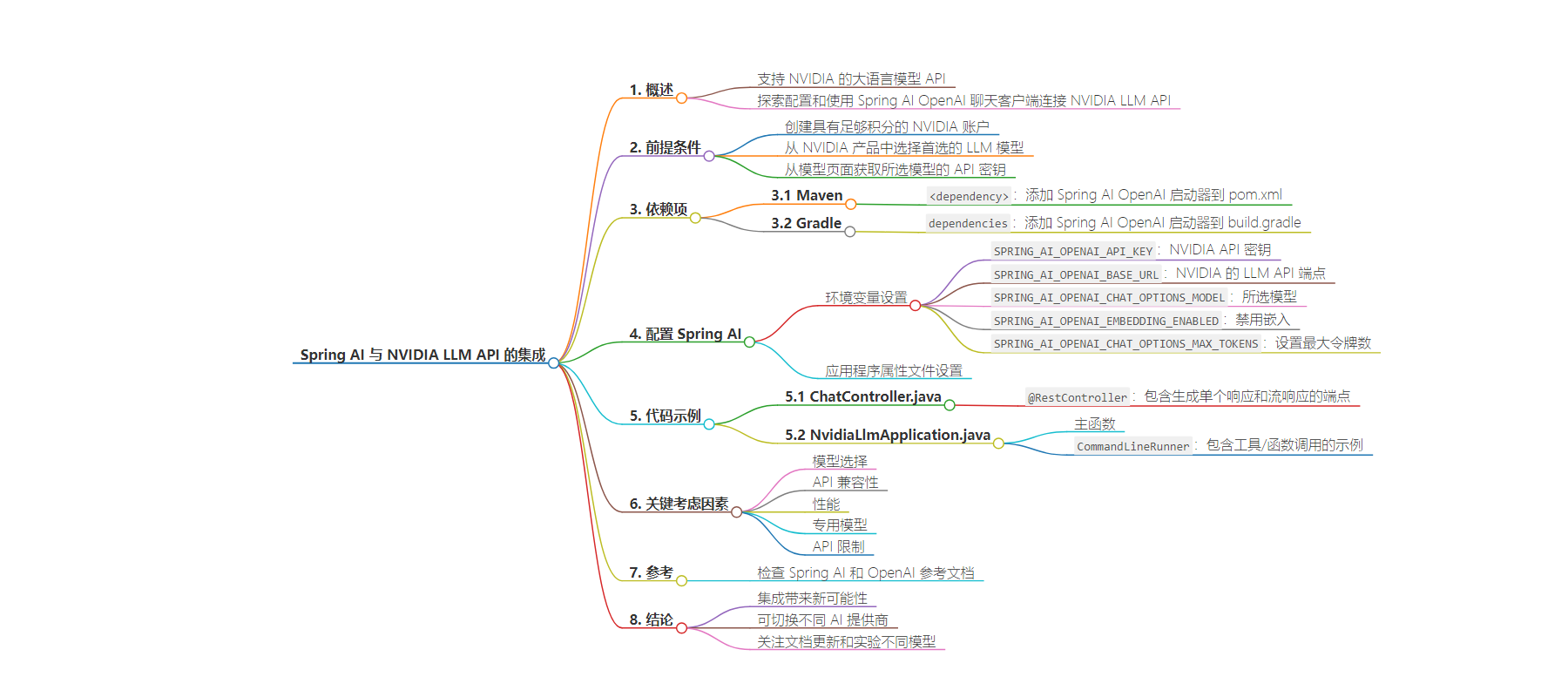
文章地址:https://spring.io/blog/2024/08/20/spring-ai-with-nvidia-llm-api
文章来源:spring.io
作者:Christian Tzolov
发布时间:2024/8/20 0:00
语言:英文
总字数:1020字
预计阅读时间:5分钟
评分:84分
标签:春天 AI,NVIDIA 大语言模型 API,大语言模型,AI 集成,Java 开发
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Spring AI now supports NVIDIA’s Large Language Model API, offering integration with a wide range of models. By leveraging NVIDIA’s OpenAI-compatible API, Spring AI allows developers to use NVIDIA’s LLMs through the familiar Spring AI API.

We’ll explore how to configure and use the Spring AI OpenAI chat client to connect with NVIDIA LLM API.
- The demo application code is available in the nvidia-llm GitHub repository.
- The SpringAI / NVIDIA integration documentation.
Prerequisite
- Create NVIDIA account with sufficient credits.
- Select your preferred LLM model from NVIDIA’s offerings. Like the
meta/llama-3.1-70b-instructin the screenshot below. - From the model’s page, obtain the API key for your chosen model.

Dependencies
To get started, add the Spring AI OpenAI starter to your project.For Maven, add this to your pom.xml:
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency>For Gradle, add this to your build.gradle:
gradleCopydependencies { implementation 'org.springframework.ai:spring-ai-openai-spring-boot-starter'}Ensure you’ve added the Spring Milestone and Snapshot repositories and add the Spring AI BOM.
Configuring Spring AI
To use NVIDIA LLM API with Spring AI, we need to configure the OpenAI client to point to the NVIDIA LLM API endpoint and use NVIDIA-specific models.
Add the following environment variables to your project:
export SPRING_AI_OPENAI_API_KEY=<NVIDIA_API_KEY>export SPRING_AI_OPENAI_BASE_URL=https://integrate.api.nvidia.comexport SPRING_AI_OPENAI_CHAT_OPTIONS_MODEL=meta/llama-3.1-70b-instructexport SPRING_AI_OPENAI_EMBEDDING_ENABLED=falseexport SPRING_AI_OPENAI_CHAT_OPTIONS_MAX_TOKENS=2048Alternatively, you can add these to your application.properties file:
spring.ai.openai.api-key=<NVIDIA_API_KEY>spring.ai.openai.base-url=https://integrate.api.nvidia.comspring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct# The NVIDIA LLM API doesn't support embeddings.spring.ai.openai.embedding.enabled=false# The NVIDIA LLM API requires this parameter to be set explicitly or error will be thrown.spring.ai.openai.chat.options.max-tokens=2048Key points:
- The
api-keyis set to your NVIDIA API key. - The
base-urlis set to NVIDIA’s LLM API endpoint: https://integrate.api.nvidia.com - The
modelis set to one of the models available on NVIDIA’s LLM API. - The NVIDIA LLM API reuquires the
max-tokensto be explicitly set or a server error will be thrown. - Since the NVIDIA LLM API is LLM only we can disable the embedding endpong:
embedding.enabled=false.
Check the reference documentation for the complete list of configuration properties.
Code Example
Now that we’ve configured Spring AI to use NVIDIA LLM API, let’s look at a simple example of how to use it in your application.
@RestControllerpublic class ChatController { private final ChatClient chatClient; @Autowired public ChatController(ChatClient.Builder builder) { this.chatClient = builder.build(); } @GetMapping("/ai/generate") public String generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { return chatClient.prompt().user(message).call().content(); } @GetMapping("/ai/generateStream") public Flux<String> generateStream( @RequestParam(value = "message", defaultValue = "Tell me a joke") String message) { return chatClient.prompt().user(message).stream().content(); }}In the ChatController.java example, we’ve created a simple REST controller with two endpoints:
/ai/generate: Generates a single response to a given prompt./ai/generateStream: Streams the response, which can be useful for longer outputs or real-time interactions.
NVIDIA LLM API endpoints support tool/function calling when selecting one of the Tool/Function supporting models.

You can register custom Java functions with your ChatModel and have the provided LLM model intelligently choose to output a JSON object containing arguments to call one or many of the registered functions.This is a powerful technique to connect the LLM capabilities with external tools and APIs.
Find more about SpringAI/OpenAI Function Calling support.
Here’s a simple example of how to use too/function calling with Spring AI:
@SpringBootApplicationpublic class NvidiaLlmApplication { public static void main(String[] args) { SpringApplication.run(NvidiaLlmApplication.class, args); } @Bean CommandLineRunner runner(ChatClient.Builder chatClientBuilder) { return args -> { var chatClient = chatClientBuilder.build(); var response = chatClient.prompt() .user("What is the weather in Amsterdam and Paris?") .functions("weatherFunction") // reference by bean name. .call() .content(); System.out.println(response); }; } @Bean @Description("Get the weather in location") public Function<WeatherRequest, WeatherResponse> weatherFunction() { return new MockWeatherService(); } public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> { public record WeatherRequest(String location, String unit) {} public record WeatherResponse(double temp, String unit) {} @Override public WeatherResponse apply(WeatherRequest request) { double temperature = request.location().contains("Amsterdam") ? 20 : 25; return new WeatherResponse(temperature, request.unit); } }}In the NvidiaLlmApplication.java example, when the model needs weather information, it will automatically call the weatherFunction bean, which can then fetch real-time weather data.The expected response looks like this:
The weather in Amsterdam is currently 20 degrees Celsius, and the weather in Paris is currently 25 degrees Celsius.
Key Considerations
When using NVIDIA LLM API with Spring AI, keep the following points in mind:
- Model Selection: NVIDIA offers a wide range of models from various providers. Choose the appropriate model for your use case.
- API Compatibility: The NVIDIA LLM API is designed to be compatible with the OpenAI API, which allows for easy integration with Spring AI.
- Performance: NVIDIA’s LLM API is optimized for high-performance inference. You may notice improved response speeds, especially for larger models.
- Specialized Models: NVIDIA offers models specialized for different tasks, such as code completion, math problems, and general chat. Select the most appropriate model for your specific needs.
- API Limits: Be aware of any rate limits or usage quotas associated with your NVIDIA API key.
References
For further information check the Spring AI and OpenAI reference documentations.
Conclusion
Integrating NVIDIA LLM API with Spring AI opens up new possibilities for developers looking to leverage high-performance AI models in their Spring applications.By repurposing the OpenAI client, Spring AI makes it straightforward to switch between different AI providers, allowing you to choose the best solution for your specific needs.
As you explore this integration, remember to stay updated with the latest documentation from both Spring AI and NVIDIA LLM API, as features and model availability may evolve over time.
We encourage you to experiment with different models and compare their performance and outputs to find the best fit for your use case.
Happy coding, and enjoy the speed and capabilities that NVIDIA LLM API brings to your AI-powered Spring applications!