
包阅导读总结
1. 关键词:时间序列语言模型、预测分析、数据处理、异常检测、应用优势
2. 总结:本文介绍了时间序列语言模型在预测分析中的应用,阐述了其与传统LLMs的区别,列举了其优势,如零样本性能、处理复杂模式、高效等,并列举了几个流行的模型,指出其在各行业有巨大潜力。
3. 主要内容:
– 背景
– 大型语言模型改变工作等方式,数据科学家将其用于时间序列预测。
– 时间序列语言模型(Time Series LM)
– 定义:用于处理时间序列数据而非文本等。
– 与传统LLMs的区别
– 数据类型和训练:训练于序列数值数据。
– 标记化:将数据分解为补丁。
– 输出生成:生成未来数据点序列。
– 架构调整:包含特定设计以处理时间特性。
– 优势
– 零样本性能:对新数据集无需额外训练或微调。
– 复杂模式处理:捕捉传统模型易忽略的关系和模式。
– 效率:并行处理数据,加快训练和推理。
– 应用实例
– 列举了Google的TimesFM、IBM的TinyTimeMixer、AutoLab的MOMENT等模型。
– 总结
– 时间序列语言模型是预测分析的重大进步,在各行业有广阔应用前景。
思维导图:
文章地址:https://thenewstack.io/transform-predictive-analytics-with-time-series-language-models/
文章来源:thenewstack.io
作者:Anais Dotis Georgiou
发布时间:2024/8/20 16:39
语言:英文
总字数:1316字
预计阅读时间:6分钟
评分:89分
标签:时间序列预测,语言模型,预测分析,Google,IBM
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
It’s no secret that the rise of large language models (LLMs) like ChatGPT and Bard has dramatically changed how many work, communicate, and learn. But LLMs have applications other than replacing search engines. Most recently, data scientists have repurposed LLMs for time series forecasting.
Time series data is ubiquitous across domains, from financial markets to climate science. Meanwhile, powered by advancements in artificial intelligence, LLMs are revolutionizing the way we process and generate human language. Here, we dive into how time series LMs provide innovative forecasting and anomaly detection models.
What Is a Time Series LM?
At a high level, time series LMs are repurposed to handle time series data rather than text, video, or image data. They combine the strengths of traditional time series analysis methods with the advanced capabilities of LMs to make predictions. Strong forecasts can be used to detect anomalies when data deviates significantly from the predicted or expected result. Some other notable differences between time series LMs and traditional LLMs include:
- Data Type and Training: While traditional LLMs like ChatGPT are trained on text data, time series LMs are trained on sequential numerical data. Specifically, pre-training is performed on large, diverse time series datasets (both real-world and synthetic), which enables the model to generalize well across different domains and applications.
- Tokenization: Time series LMs break down data into patches instead of text tokens (a patch refers to a contiguous segment, chunk, or window of the time-series data).
- Output Generation: Time series LMs generate sequences of future data points rather than words or sentences.
- Architectural Adjustments: Time series LMs incorporate specific design choices to handle the temporal nature of time-series data, such as variable context and horizon lengths.
Time series language models (LMs) offer several significant benefits over traditional methods for analyzing and predicting time series data. Unlike conventional approaches, such as ARIMA, which often require extensive domain expertise and manual tuning, time series LMs leverage advanced machine learning techniques to learn from the data automatically. This makes them robust and versatile tools for many applications where traditional models might fall short.
Zero-shot performance: Time series LMs can make accurate predictions on new, unseen datasets without requiring additional training or fine-tuning. This is particularly useful for rapidly changing environments where new data emerges frequently. A zero-shot approach means users don’t have to spend extensive resources or time training their model.
Complex pattern handling: Time series LMs can capture complex, non-linear relationships and patterns in data that traditional statistical models like ARIMA or GARCH might miss, especially for data that hasn’t been seen or preprocessed. Additionally, tuning statistical models can be tricky and require deep domain expertise.
Efficiency: Time series LMs process data in parallel. This significantly speeds up training and inference times compared to traditional models, which often process data sequentially. Additionally, they can predict longer sequences of future data points in a single step, reducing the number of iterative steps needed.
Time Series LMs in Action
Some of the most popular time series LMs for forecasting and predictive analytics include Google’s TimesFM, IBM’s TinyTimeMixer, and AutoLab’s MOMENT.
Google’s TimesFM is probably the easiest to use. Install it with pip, initialize the model, and load a checkpoint. You can then perform a forecast on input arrays or Pandas DataFrames. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<span style=“font-weight: 400;”>“`python</span> import pandas as pd # e.g. input_df is # unique_id ds y # 0 T1 1975-12-31 697458.0 # 1 T1 1976-01-31 1187650.0 # 2 T1 1976-02-29 1069690.0 # 3 T1 1976-03-31 1078430.0 # 4 T1 1976-04-30 1059910.0 # … … … … # 8175 T99 1986-01-31 602.0 # 8176 T99 1986-02-28 684.0 # 8177 T99 1986-03-31 818.0 # 8178 T99 1986-04-30 836.0 # 8179 T99 1986-05-31 878.0
forecast_df = tfm.forecast_on_df( inputs=input_df, freq=“M”, # monthly value_name=“y”, num_jobs=-1, ) |
Google’s TimesFM also supports fine-tuning and covariate support, which refers to the model’s ability to incorporate and utilize additional explanatory variables (covariates) alongside the primary time series data to improve the accuracy and robustness of its predictions. You can learn more about how Google’s TimesFM works in this paper.
IBM’s TinyTimeMixer contains models and examples for performing various forecasts on multivariate time series data. This notebook highlights how to use the TTM (TinyTimMixer) to perform both zero-shot and few-shot forecasts on data. The screenshot below shows some of the estimates that TTM produced:
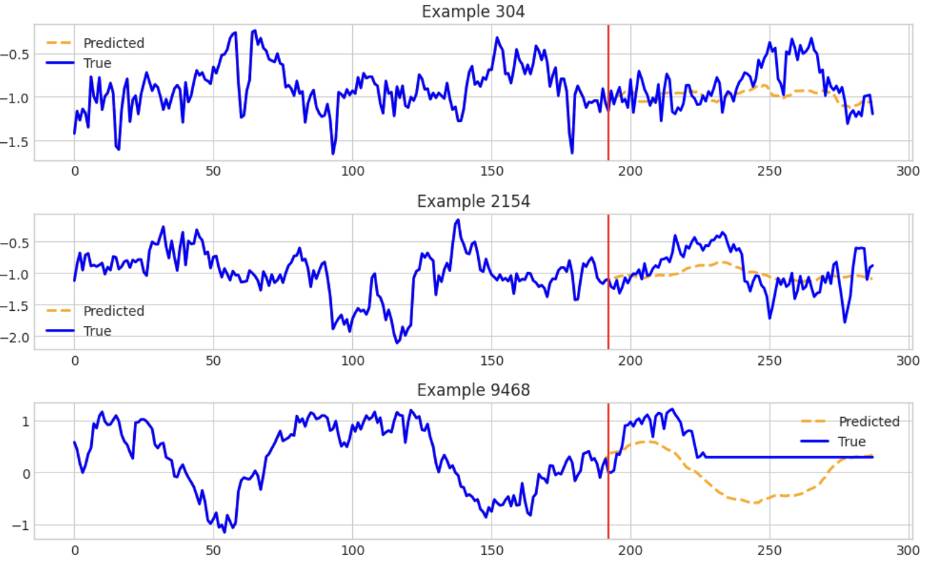
Finally, AutoLab’s MOMENT has methods of forecasting and anomaly detection with easy-to-follow examples. It specializes in long-horizon forecasting. As an example, this notebook highlights how to forecast univariate time series data by first importing the model:
|
“`python from momentum import MOMENTPipeline
model = MOMENTPipeline.from_pretrained( “AutonLab/MOMENT-1-large”, model_kwargs={ ‘task_name’: ‘forecasting’, ‘forecast_horizon’: 192, ‘head_dropout’: 0.1, ‘weight_decay’: 0, ‘freeze_encoder’: True, # Freeze the patch embedding layer ‘freeze_embedder’: True, # Freeze the transformer encoder ‘freeze_head’: False, # The linear forecasting head must be trained }, ) “` |
The next step is training the model on your data for proper initialization. After each training epoch, the model is evaluated on the test dataset. Within the evaluation loop, the model makes predictions with the line output = model(timeseries, input_mask).
|
“`python while cur_epoch < max_epoch: losses = [] for timeseries, forecast, input_mask in tqdm(train_loader, total=len(train_loader)): # Move the data to the GPU timeseries = timeseries.float().to(device) input_mask = input_mask.to(device) forecast = forecast.float().to(device)
with torch.cuda.amp.autocast(): output = model(timeseries, input_mask) “` |
Final thoughts
Time series LMs represent a significant advancement in predictive analytics. They marry the power of deep learning with the intricate demands of time series forecasting. Their ability to perform zero-shot learning, incorporate covariate support, and efficiently process large volumes of data positions them as a transformative tool across various industries. As we witness rapid progress in this area, the potential applications and benefits of time series LMs will only expand.
To store time series data, check out InfluxDB Cloud 3.0, the leading time series database. You can leverage the InfluxDB v3 Python Client Library with InfluxDB to store and query your time series data and apply a time series LLM for forecasting and anomaly detection. You can check out the following resources to get started:
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.