
包阅导读总结
1. 关键词:渲染树、DOM 树、CSSOM 树、JavaScript、浏览器渲染
2. 总结:
本文主要讲解了渲染树的形成原理,包括 DOM 树、CSSOM 树的构建,JavaScript 对其的影响,以及渲染树的构建优化等。通过实例和流程分析,阐述了浏览器渲染过程中的关键环节和要点。
3. 主要内容:
– 渲染树形成原理
– DOM 树
– 概念:对 HTML 文档结构化的表述
– 构建:HTML 解析器将字节流转换为 DOM 树,经历字符转换、令牌化、分词、解析节点添加到树中等阶段
– CSSOM 树
– 目的:构建树以计算页面样式
– 构建流程:与 DOM 树相似
– JavaScript 的影响
– DOM 树构建遇脚本暂停,先执行脚本,可能操作已生成的 DOM 节点
– 页面同时有 HTML、JavaScript、CSS 且非外部引入时,脚本执行需判断 CSSOM 是否解析完成
– 外部引入时,预解析线程提前下载数据,后续同情况 2
– 渲染树构建优化
– CSS 资源先于 JavaScript 资源引入
– 样式文件放 head 标签,脚本文件在 body 结束前
– 减少 JavaScript 中的 DOM 操作
– 简化优化 CSS 选择器,减少嵌套层
思维导图: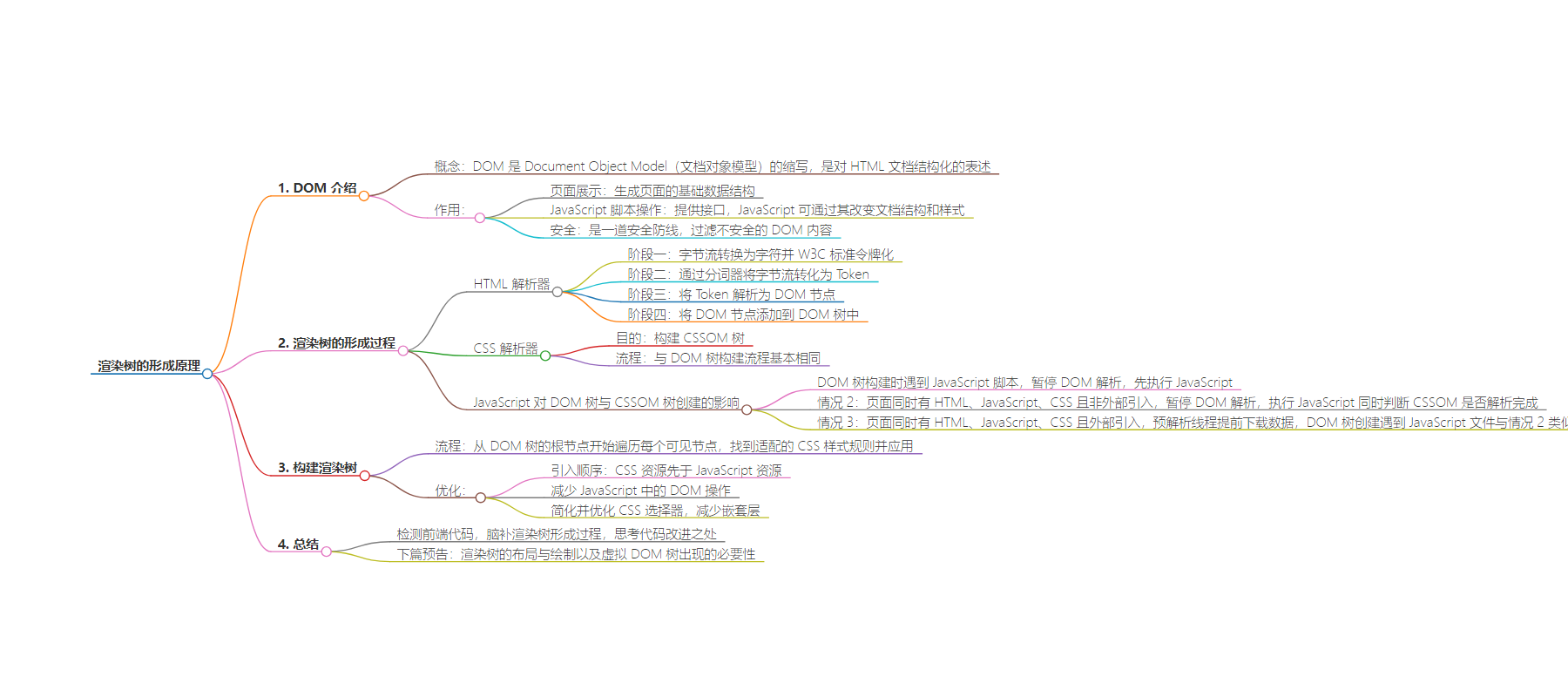
文章地址:https://mp.weixin.qq.com/s/8w2LBudgZ7XtgMgjK0P7dw
文章来源:mp.weixin.qq.com
作者:kaola
发布时间:2024/7/3 9:32
语言:中文
总字数:3521字
预计阅读时间:15分钟
评分:91分
标签:浏览器渲染,DOM,HTML解析,CSS解析,JavaScript
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
浏览器系列文章
说一下为什么写这个系列?
什么是DOM
DOM是Document Object Model(文档对象模型)的缩写
W3C 文档对象模型 (DOM) 是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。-这是W3Cschool给的概念
看了上面的概念好像太“官方”,解释就是 DOM 是对 HTML 文档结构化的表述,后端服务器返回给浏览器渲染引擎的 HTML 文件字节流是无法直接被浏览器渲染引擎理解的,要转化为渲染器引擎可以理解的内部结构,这个结构就是 DOM。W3C 那个概念我好像还没有把它全部翻译完,“允许程序和脚本动态地访问和更新文档的内容、结构和样式”。这里其实就是DOM的作用了
-
页面展示: DOM 是生成页面的基础数据结构
-
JavaScript 脚本操作: DOM 提供给 JavaScript 脚本操作的接口,JavaScript 可以通过这些接口对 DOM 结构进行访问,从而改变文档的结构和样式
-
安全: DOM 是一道安全防线,DOM 解析阶段会过滤掉一些不安全的 DOM 内容。
本文我主要以 Webkit 渲染引擎来讲解,Safari 和 Chrome 都使用 Webkit。Webkit 是一款开源渲染引擎,它本来是为 linux 平台研发的,后来由 Apple 移植到 Mac 及 Windows 上。
渲染树最终形成经历了哪些
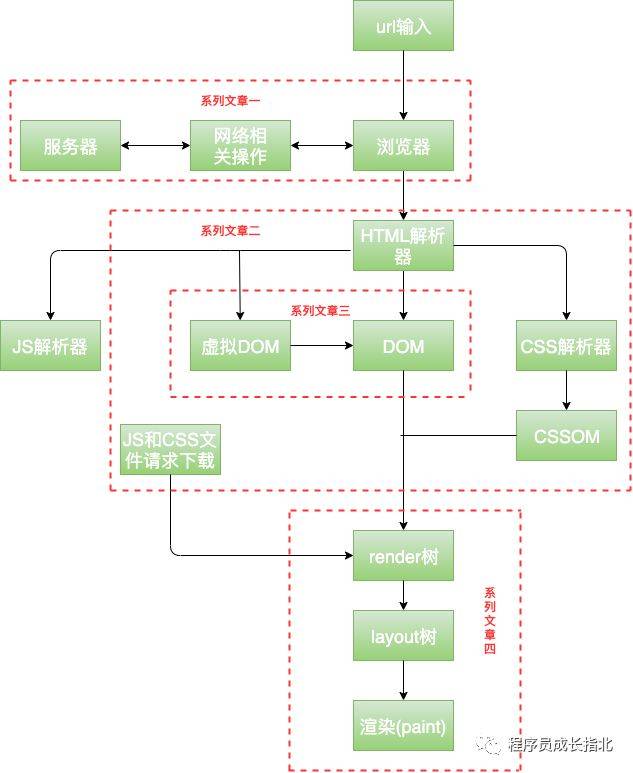
先看一张整体的流程图
 下面围绕这张图和不同代表性对例子进行讲解。
下面围绕这张图和不同代表性对例子进行讲解。
HTML解析器
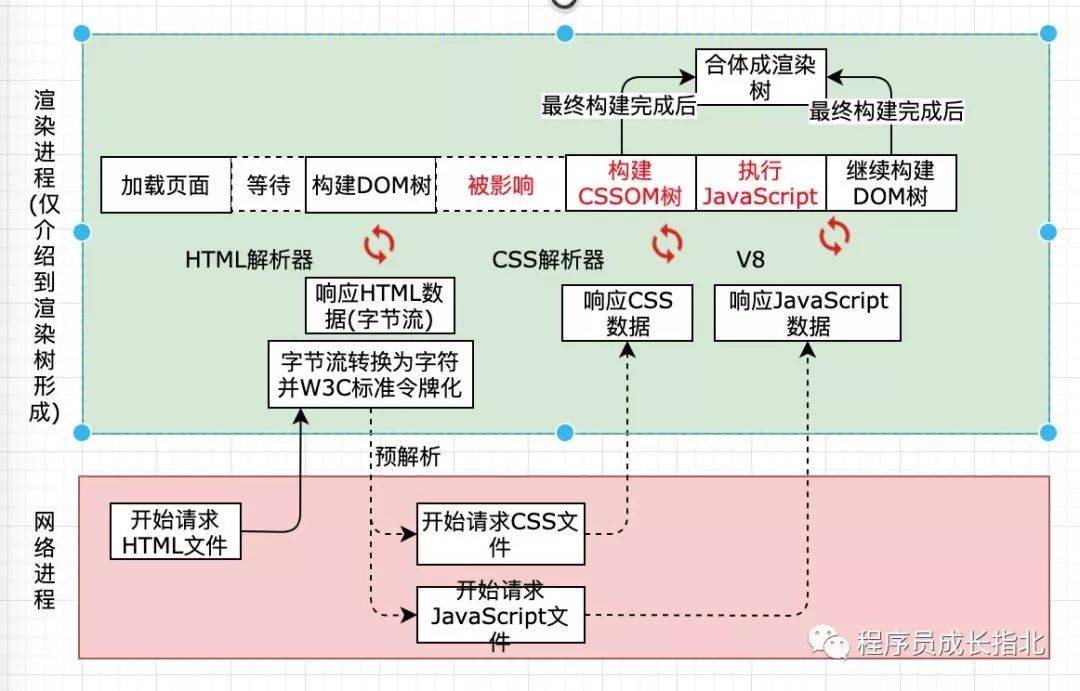
从后端返回给浏览器渲染引擎 HTML 文件字节流,第一步要经过的就是渲染引擎中的 HTML 解析器。它实现了将 HTML 字节流转换为 DOM树 结构。HTML 文件字节流返回的过程中 HTML 解析器就一直在解析,边加载边解析哦(这里注意下,有些文章写的有问题)。
例子1:最简单的不带 CSS 和 JavaScript 的 HTML 代码讲解 HTML 解析器
<html>
<body>
<div>程序员成长指北</div>
</body>
</html>
根据这段代码具体分析 HTML 解析器做了哪些事
阶段一 字节流转换为字符并W3C标准令牌化
读取 HTML 的原始字节流,并根据文件的指定编码(例如 UTF-8)将它们转换成各个字符。并将字符串转换成 W3C HTML5 标准规定的各种令牌,例如,“”、“”,以及其他尖括号内的字符串。每个令牌都具有特殊含义和一组规则。
一堆字节流 bytes
3C 62 6F ...
转成正常的html文件
<html>
<body>
<div>
koala
<p>
程序员成长指北
</P>
</div>
</body>
</html>
阶段二 通过分词器将字节流转化为 Token
分词器将字节流转换为一个一个的 Token,Token 分为 Tag Token和文本 Token,上面这段代码最后分词器转化后的结果是:

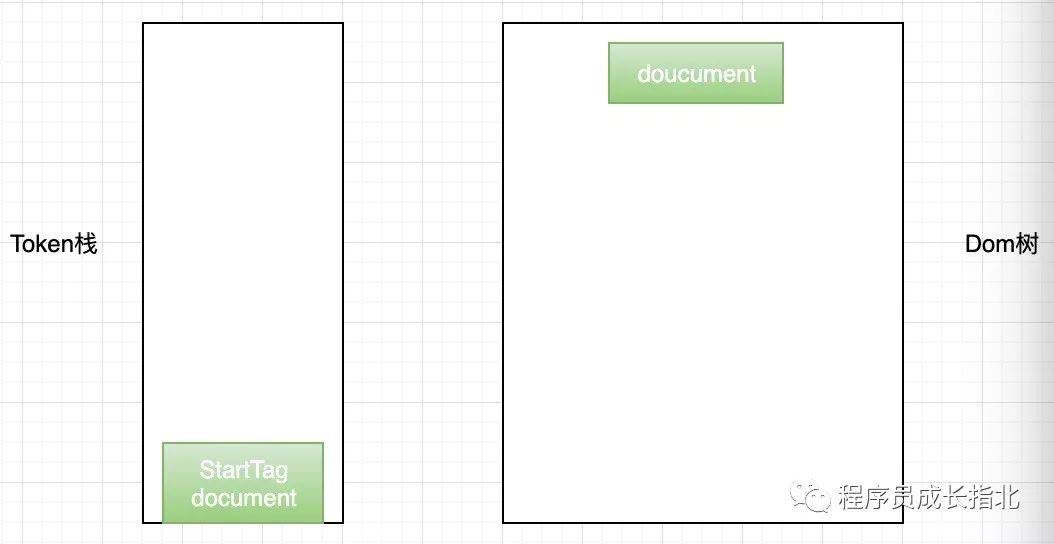
阶段三和阶段四 将 Token 解析为 DOM 节点,并将 DOM 节点添加到 DOM 树中
HTML 解析器维护了一个 Token 栈结构(数据结构真是个好东西),这个栈结构的目的就是用来计算节点间的父子关系,在上一个阶段生成的 Token 会被顺序压到这个栈中,以下是具体规则:
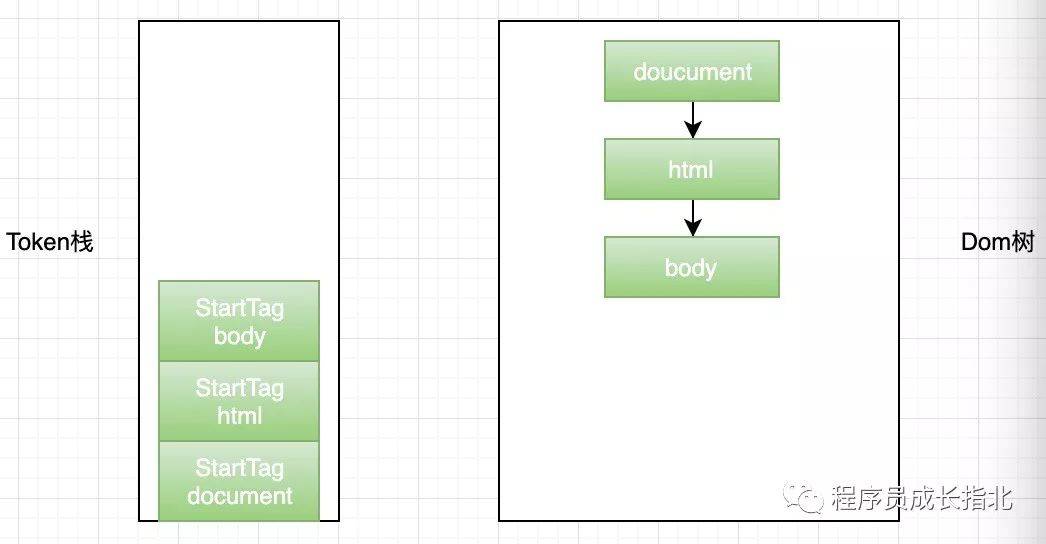
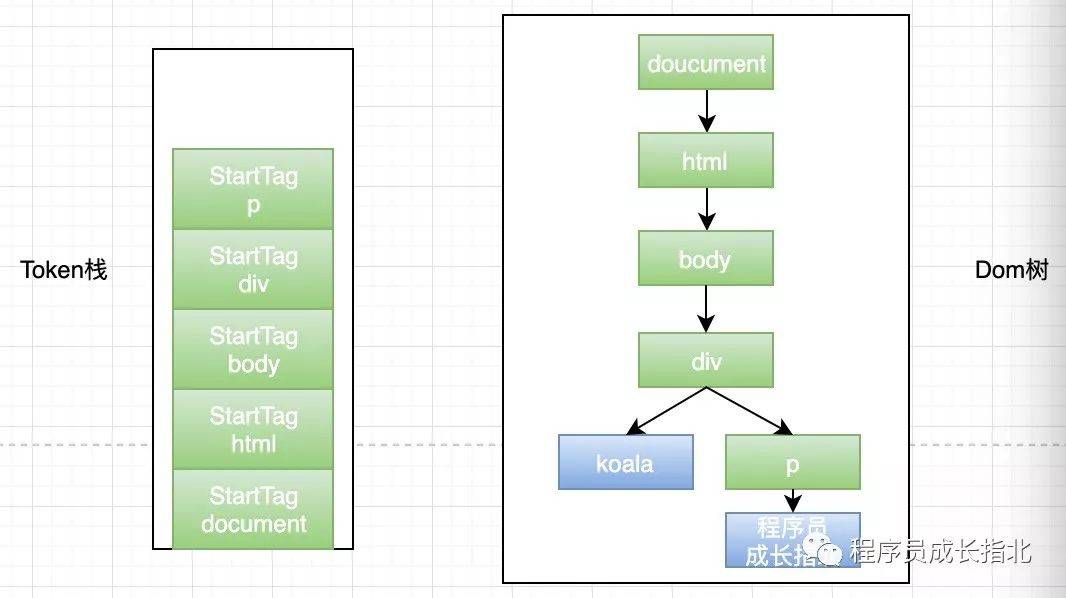
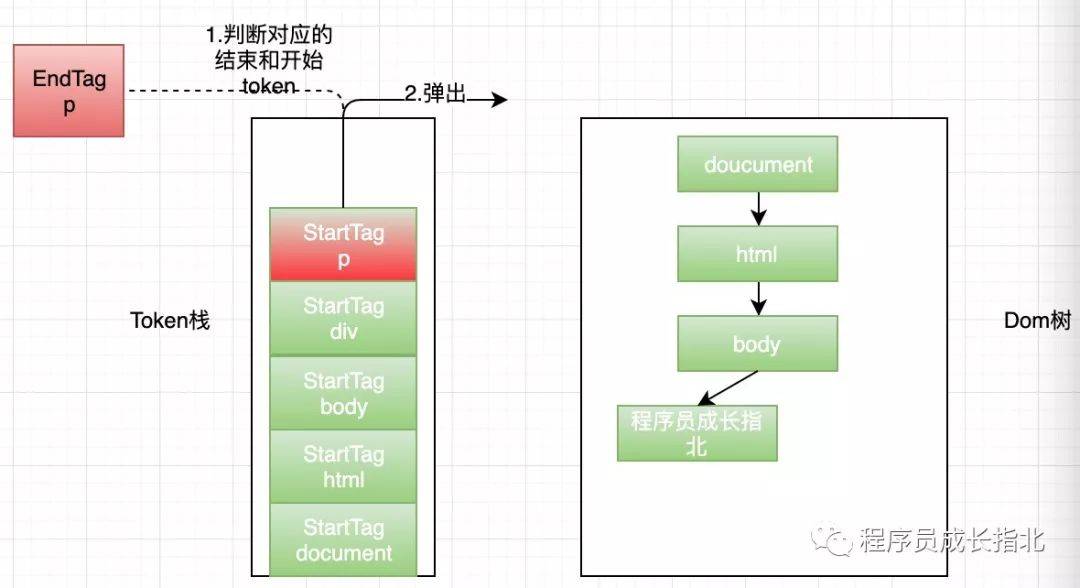
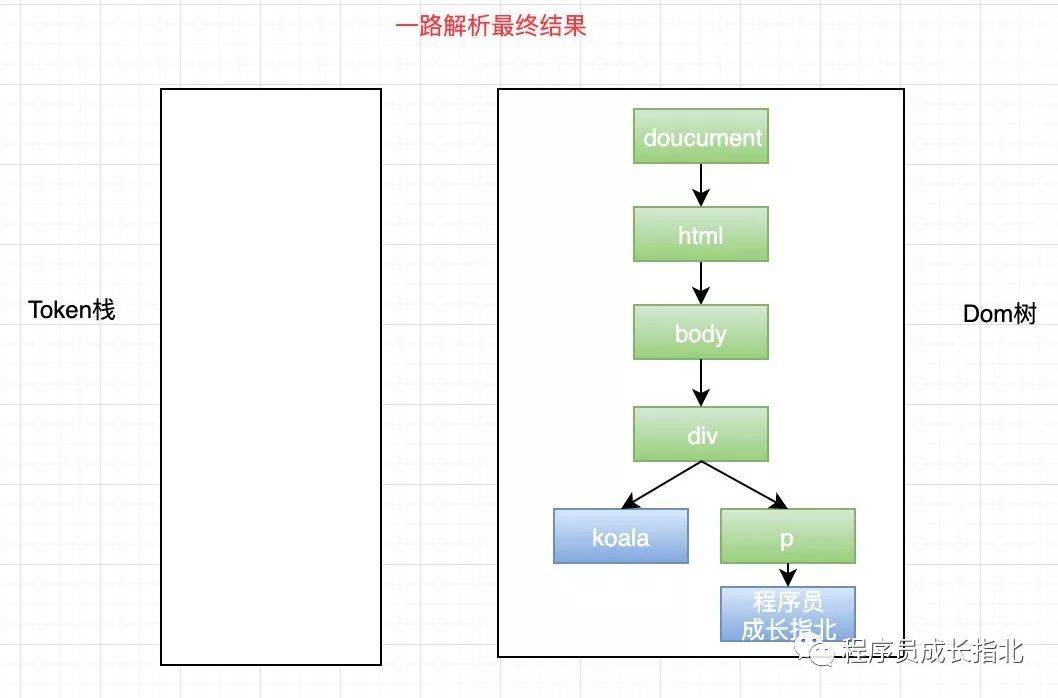
此时应该搞懂了核心图中 HTML 解析器的部分,和 DOM 树的基本绘制流程,但是现实很残酷,哪里有这么简单的前端代码,还有有 JavaScript 和 CSS 呢!继续往下看
CSS解析器
CSS 解析器最终的目的也是构建树不过它构建的树是 CSSOM 树树的构建流程和 DOM 树的构建流程基本相同

还是那张图,具体我就不一一讲解一遍了。直接用这个简单例子
body { font-size: 16px }
div { font-weight: bold }
div p { display: none }
看下最后构造的 CSSOM 树
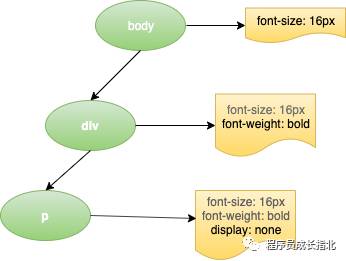
CSSOM 为何具有树结构?为页面上的任何对象计算最后一组样式时,浏览器都会先从适用于该节点的最通用规则开始(例如,如果该节点是 body 元素的子项,则应用所有 body 样式),然后通过应用更具体的规则(即规则“向下级联”)以递归方式优化计算的样式。
以上面的 CSSOM 树为例进行更具体的阐述。span 标记内包含的任何置于 body 元素内的文本都将具有 16 像素字号,并且颜色为红色 — font-size 指令从 body 向下级联至 span。不过,如果某个 span 标记是某个段落 (p) 标记的子项,则其内容将不会显示。
注意点:
CSS解析可以与DOM解析同进行
如果只有 CSS 和 HTML 的页面,CSS 不会影响 DOM 树的创建,但是如果页面中还有 JavaScript,结论就不一样了,请继续往下看。
javascript对DOM树与CSSOM树创建的影响
上面两个例子中都还没有javascript的出现,接下来说下JavaScript 对 DOM 树和 CSSOM 树构建的影响。
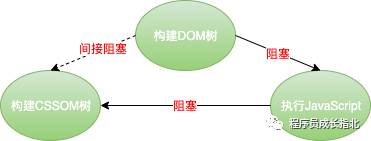
DOM 树构建时当遇到JavaScript脚本,就要暂停 DOM 解析,先去执行 Javascript,因为在JavaScript可能会操作当前已经生成的DOM节点。
有一点需要注意:javascript是可能操作当前已经生成的DOM节点,如果是后 面还未生成的DOM节点是不生效的,比如这段代码:
<html><body><div>1</div><script>let div1 = document.getElementsByTagName('div')[0]div1.innerText = '程序员成长指北'let div2 = document.getElementsByTagName('div')[1]div2.innerText = 'kaola'</script><div>test</div></body></html>
显示结果为两行:
第一行结果是程序员成长指北 第二行记过是test 因为在执行第三行和第四行 script 脚本的时候,DOM树中还没有生成第二个 div对应的dom节点。
-
情况2:当页面中同时有Html JavaScript CSS ,而且都非外部引入
DOM 树构建时当遇到 JavaScript 脚本,就要暂停 DOM 解析,先去执行 JavaScript,同时 JavaScript 还要判断 CSSOM 是否解析完成,因为在 JavaScript 可能会操作 CSSOM 节点,CSSOM 节点确认解析完成,执行 JavaScript 再次回到 DOM 树创建。(所以这里也可以理解为CSS解析间接影响DOM树创建)
-
情况3:当页面中同时有Html,JavaScript, CSS ,而且外部引入
Webkit渲染引擎有一个优化,当渲染进程接收HTML文件字节流时,会先开启一个预解析线程,如果遇到 JavaScript 文件或者 CSS 文件,那么预解析线程会提前下载这些数据。当渲染进程接收 HTML 文件字节流时,会先开启一个预解析线程,如果遇到 JavaScript 文件或者 CSS 文件,那么预解析线程会提前下载这些数据。DOM树在创建过程中如果遇到JavaScript文件,接下来就和情况2类型一样了。
影响关系图:画了一张影响关系图希望大家更好的记忆:
构建渲染树
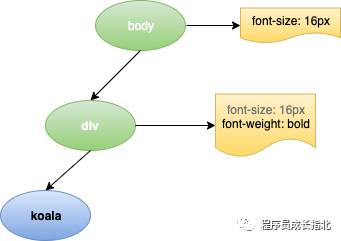
通过 DOM 树和 CSSOM 树,浏览器就可以通过二者构建渲染树了。浏览器会先从 DOM 树的根节点开始遍历每个可见节点,然后对每个可见节点找到适配的CSS样式规则并应用。具体的规则有以下几点需要注意:
看一下前文中提到的 DOM 树和 CSSOM 树最终合成的渲染树结果是:
本文渲染树形成过程可以做哪些优化
看完了渲染树的形成,在开发过程中我们能做哪些优化?(注意这里的优化只是针对渲染树形成部分,其他的优化会在系列文章之后继续讲)
-
在引入顺序上,CSS 资源先于 JavaScript 资源。样式文件应当在 head 标签中,而脚本文件在 body 结束前,这样可以防止阻塞的方式。
-
尽量减少在 JavaScript 中进行DOM操作。
-
简化并优化CSS选择器,尽量将嵌套层减少到最小。
总结
看完这篇文章赶紧检测一下你写的前端代码,脑补一下渲染树形成过程,想想自己代码有没有需要改善的地方,系列文章会继续分享,下篇该系列文章渲染树的布局与绘制以及虚拟DOM树出现的必要性,感谢观看。
参考文章
极客时间浏览器专栏浏览器渲染原理 https://srtian96.gitee.io/blog/2018/06/01/浏览器渲染原理/
交流学习
大家好,我是koala,公众号「程序员成长指北」作者。公众号为您打造优质Node与前端学习路线,并且会推送超级优质文章。加入我们一起学习吧!博客地址:https://github.com/koala-coding/goodBlog

在看你最美