
包阅导读总结
1. 关键词:Redis、数据结构、底层实现、时间复杂度、内存优化
2. 总结:本文介绍了 Redis 常见数据结构的进化史,包括字符串、List、Set、Map、Sorted Set 等,解释了不同数据结构的特点、优缺点、适用场景,以及 Redis 数据类型有多种底层实现的原因,还提及了读写数据的时间复杂度和扩缩容机制。
3. 主要内容:
– 字符串
– 自定义 SDS 结构体解决 C 语言字符串的问题。
– 定义三种编码:int、embstr、raw。
– List
– 3.2 版本前底层结构有 linkedlist 和 ziplist。
– linkedlist 存在指针占用空间多和查询效率低的问题。
– ziplist 节省内存但查询仍为 O(N)且有更新等问题。
– 3.2 版本引入结合二者优缺点的 quicklist,查询复杂度为 O(logN)。
– 5.0 版本推出 listpack,7.0 版本替换 ziplist。
– Set
– 底层由 map 和 intset 实现。
– intset 存储特定整数且数量有限,可二分法查询。
– map 中 key 是 set 值,value 为 null。
– Map
– 底层由 dict 和 ziplist/listpack 组成。
– dict 由数组和链表构成,存在扩容和缩容机制。
– Sorted Set
– 底层结构由 dict+skiplist、ziplist/listpack 组成。
– dict 存储 member 和 score,skiplist 是多层级有序链表。
– 总结
– 不同数据结构有不同时间复杂度。
– 不同 Redis 版本底层实现更改原因。
– 一种数据类型多种底层实现是为内存优化。
思维导图: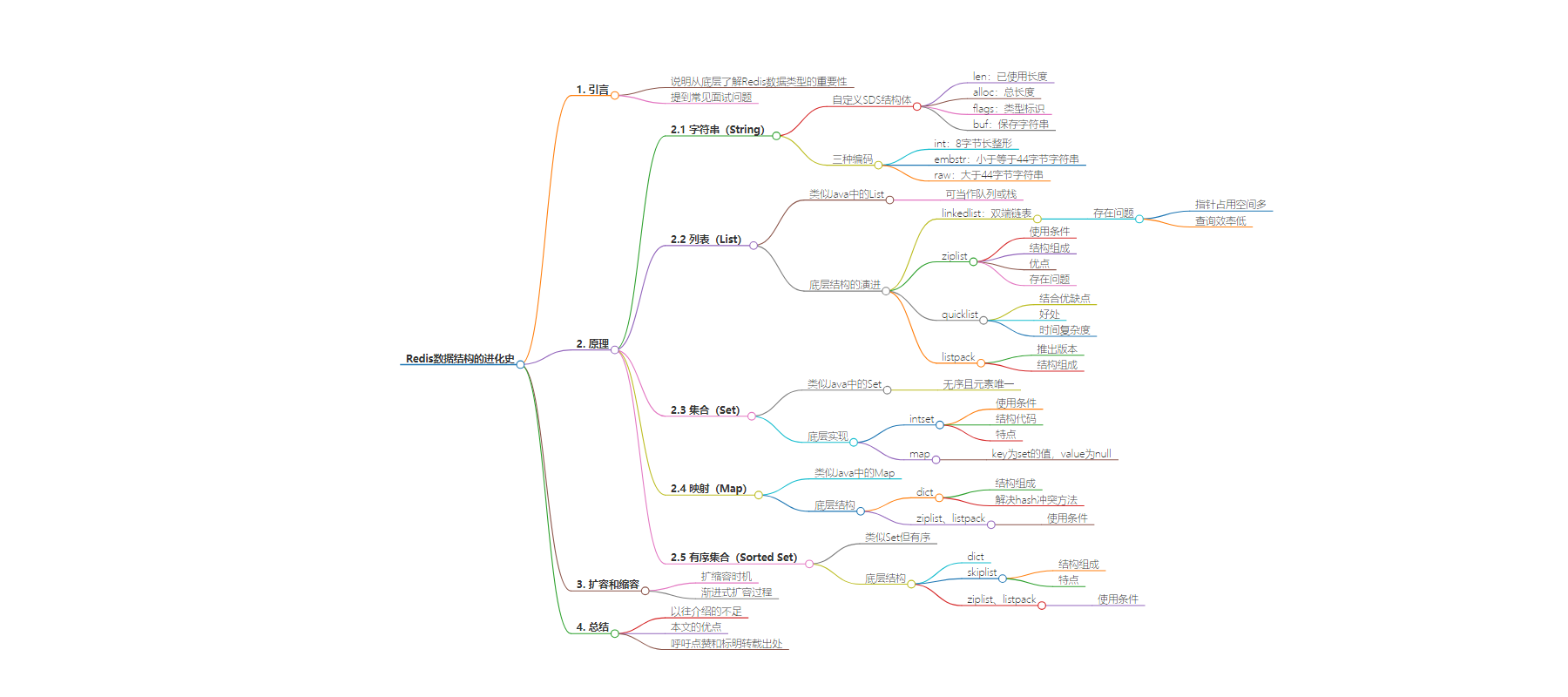
文章地址:https://juejin.cn/post/7407275971903422518
文章来源:juejin.cn
作者:想打游戏的程序猿
发布时间:2024/8/27 2:07
语言:中文
总字数:6295字
预计阅读时间:26分钟
评分:90分
标签:Redis,数据结构,内存优化,性能提升,数据库
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
介绍
redis是一种常用的内存数据库,对于使用者如果能从底层了解到各种数据类型的底层原理,可以让我们能在特定的业务场景下选择正确的数据类型。同时redis数据类型也是面试中频繁出现的面试题,接下来大家可以带着以下几个问题来阅读整篇文章。
- 各种结构,读写一条数据的时间复杂度是多少?
- 为什么不同redis版本有不同的底层实现?
- 为什么一种数据类型有多种底层实现?
原理
字符串
字符串类型是我用过最多的类型,使用的场景有:缓存数据信息、分布式锁、计数器等。在Redis实现中并没有直接采用C语言的字符串,而是自定义了一个SDS(简单动态字符串)的结构体来标识字符串。
在C语言中定义字符串 char *str = "message"它会存储如下图的样子:
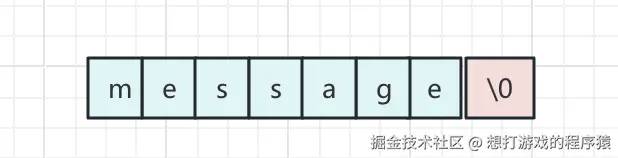 以“\0”代表结束。这样就会产生以下问题:
以“\0”代表结束。这样就会产生以下问题:
- 无法存储“\0”这种特殊字符,因为“\0”代表结束;
- 每次字符串扩容和缩容,都需要使用新的char数组;
- 没有记录字符串的长度,每次都需要进行遍历到结束才能知道长度。
redis要解决上述问题,就自定义了一个SDS结构,如下图:
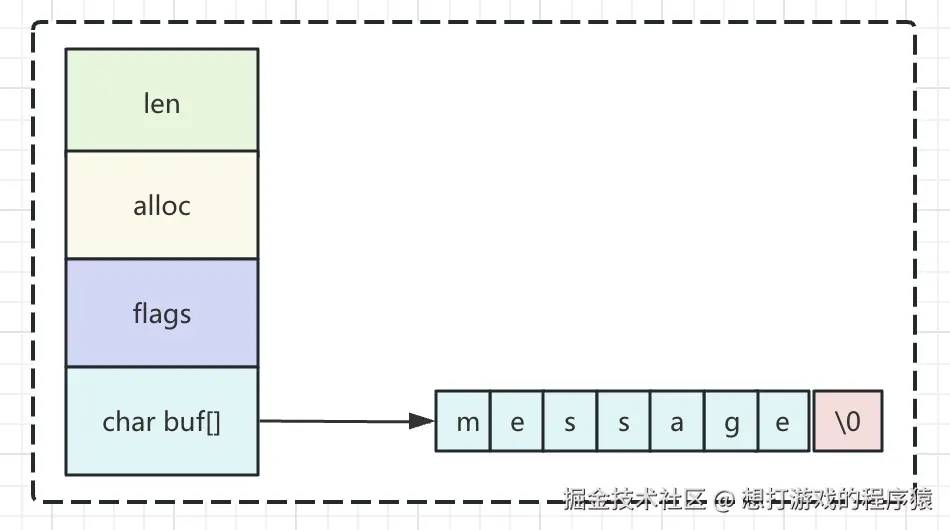
- len:目前已使用的长度;
- alloc:buf的总长度,就是已经分配空间的长度;
- flags:sds的类型,用低三位标识,高5位暂时不用。sdshdr5这种类型该字段为空;sdshdr8、sdshdr16、sdshdr32、sdshdr64用标识进行表示。
- buf:保存具体的字符串。注意这里也会以\0结尾,但它不会计算在len中。
可以看到redis可以根据字符串的大小使用不同类型的sds,这样可以进一步的节省内存。这里不需要担心buf的长度不够用,2的64次幂是一个非常巨大的数字,同时redis默认也会限制最大的字符为512M,在6.3版本开始可以对最大限制字符大小进行配置。注意:使用不同类型的sds并不是一次性分配这么多空间,而是逐步分配的,例如:使用sdshdr16这种类型,存入一个长度为14的字符串,那么会根据存入的字符串长度预留空闲长度,这里是14;如果字符串大小超过1M,那么预留空间就是1M。
redis除了自定义了SDS类型来存储字符串,还定义了三种编码:
- int:8字节的长整形,值时数字类型,并且数字长度小于20;
- embstr:长度小于等于44字节的字符串;(3.2版本之前是39字节)
- raw:长度大于44字节的字符串。
List
List与java中的list类似,是一种线性有序的数据结构,可以通过:
LINDEX listKey 0获取头元素;LINDEX listKey -1获取尾部元素。
这里我们既可以把它当作队列,也可以当作栈来使用。在C语言中并没有线程的list,redis只好自己来实现一个list结构;对于list的底层结构,redis的不同版本采用的并不完全相同,它是从linkedlist、ziplist、quicklist、listpack一点点演进出来的。
linkedlist
它是3.2版本之前的实现,以下是它的部分代码定义:
typedef struct list { listNode *head; listNode *tail; unsigned long len;} list;typedef struct listNode { struct listNode *prev; struct listNode *next; void *value;} listNode;通过上述代码可以知道,这就是一个双端链表;为了大家看的更清晰,这里我画了一张图来表示:
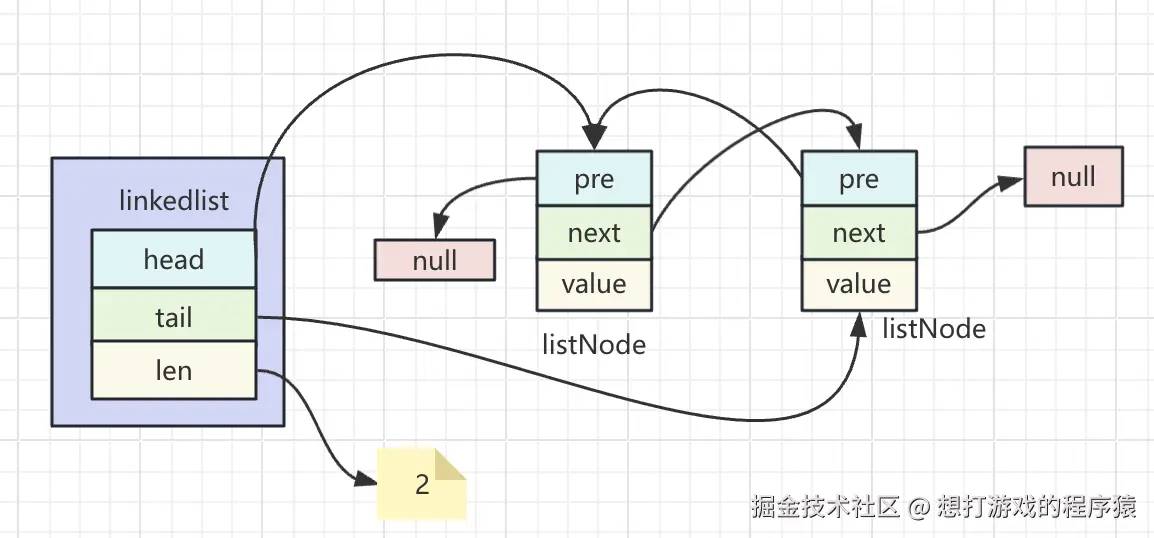
根据图大家可以看的更清晰会发现两个问题:
- 就想存一个值,结果还要存储各种指针,如果值比较小的话,指针占用的空间比值还多;
- 找一个值需要逐个遍历,但整个链表空间不是连续的这样查询的效率很低。
ziplist
为了解决linkedlist存在的问题,redis还定义了另一个数据结构ziplist,在3.2版本之前,List的底层数据类型就由这两个数据结构组成,当满足以下两种情况就会使用ziplist数据结构:
- list中的每个元素占用的字节数都小于64;
- list中的元素数量小于512个。
它的结构代码如下:
struct ziplist<T> { int32 zlbytes; int32 zltail_offset; int16 zllength; T[] entries; int8 zlend; } struct entry { int<var> prevlen; int<var> encoding; optional byte[] content; } 让我们来看一下ziplist的结构图:
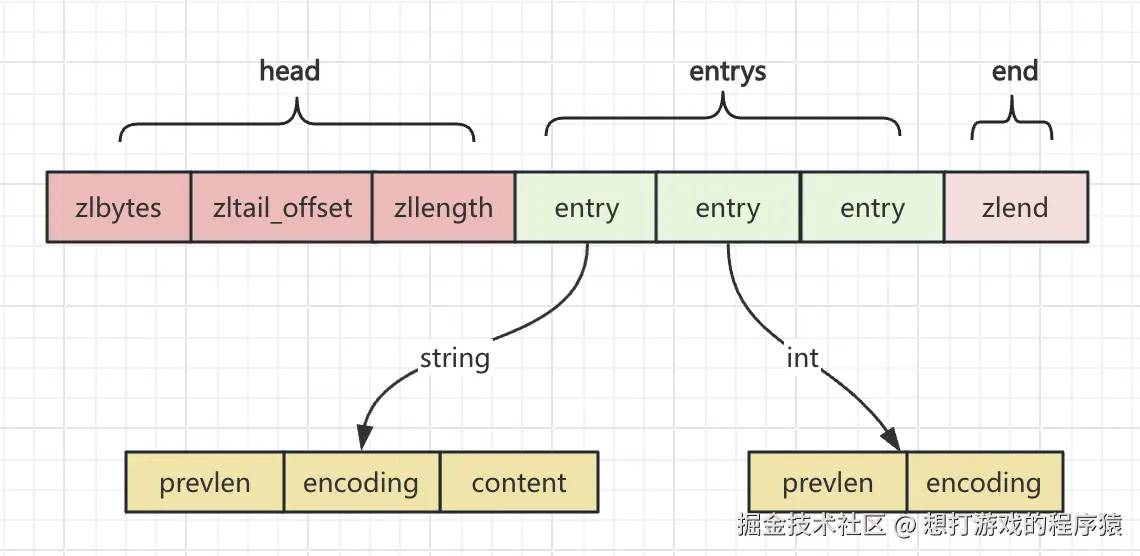
- zlbytes:整个ziplist占用的字节数;(占用4字节空间)
- zltail_offset:指向最后一个entry的偏移量;(占用4字节)
- zllength:entry的总数;(占用2字节)
- entry:存放的元素;
- zlend:结束表示(值为255)。(占用1字节)
- prevlen:记录前一个entry占用的字节数,它占用的字节会根据上一个entry的长度改变而改变;
- encoding:表示当前entry的类型和长度;当前两位为11时,标识int类型数据,此时content中的数据内容也会存储在encoding中;
- content:实际存放数据的区域。
通过上图可以了解到ziplist占用一定的连续空间。这样可以节省linkedlist中前后指针消耗的内存;同时记录了上一个节点的prevlen,这样每次都可以查找上一个节点,上一个节点的开头就是prevlen,可以节约查询时间;同时对于int、string采用了不同的编码进一步节约内存。
但ziplist查询第k个数据还是需要进行全部遍历,它的时间复杂度还是O(N);由于空间是连续的插入新的entry时,如果没有足够连续的空间就需要再重新分配一块连续的内存空间;prevlen还会随着前一个entry的大小的改变而改变,当最前面的entry大小改变了还可能会导致连锁更新把后面的entry全部更新了。
quicklist
quicklist是在3.2版本引进的,它结合了linkedlist和ziplist的优缺点,把他们两个合并起来,整体上是一个linkedlist,每个节点是一个ziplist,
代码如下:
typedef struct quicklist { quicklistNode *head; quicklistNode *tail; unsigned long count; unsigned long len; ......省略......} quicklist;typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *entry; size_t sz; unsigned int count : 16; unsigned int encoding : 2; ......省略...... } quicklistNode;下图只是简单的把linkedlist和ziplist合并起来的,和真实的quicklist有些差别如图:
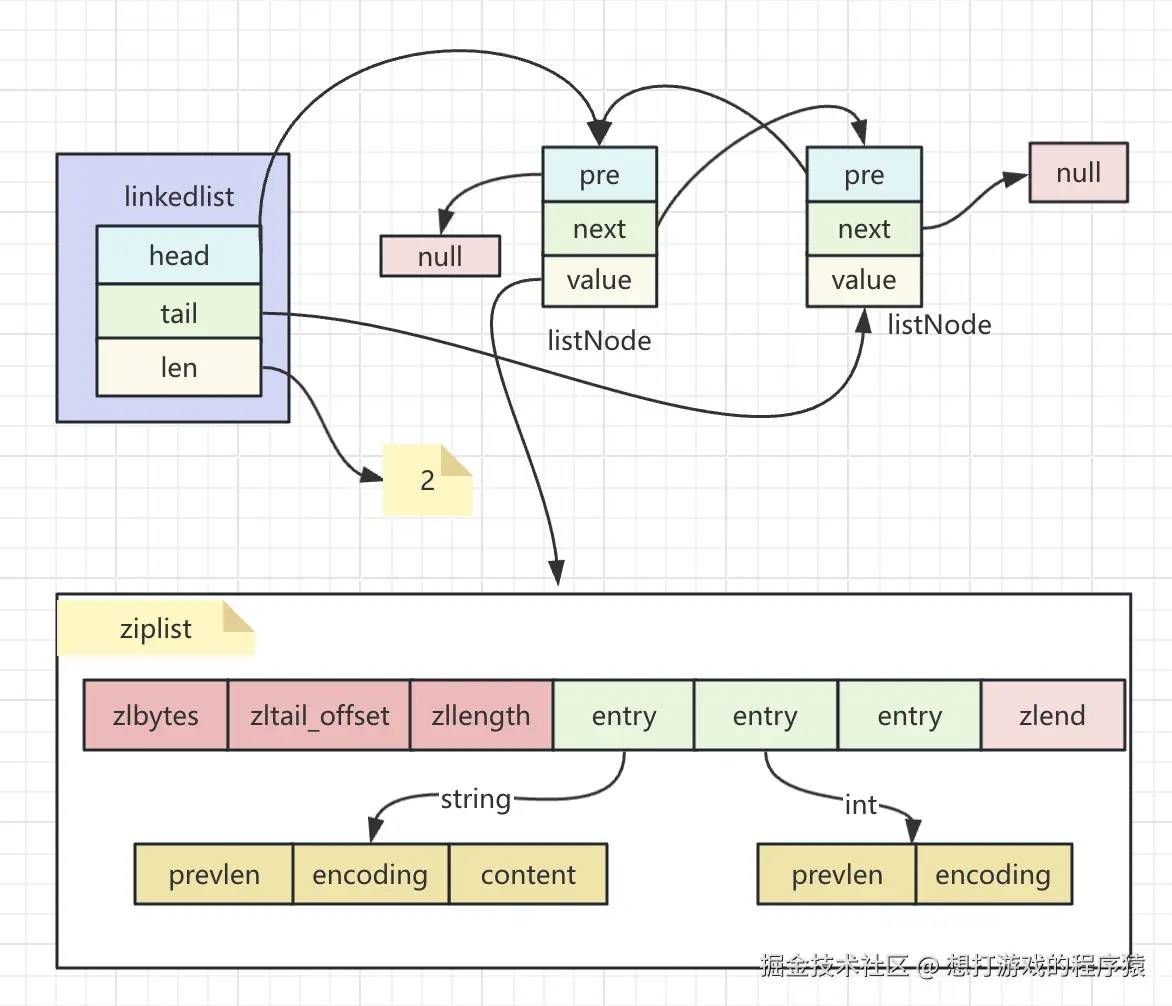
这样的好处是可以控制每个ziplist的元素个数,控制好个数发生ziplist存在的问题时可以把影响降低;我们可以根据list-max-ziplist-size来控制ziplist的元素个数。同时每个quicklistNode还存储了当前节点包含元素的总数,这样查询第k个元素时的时间复杂度就时O(logN)。
listpack
quicklist只能降低ziplist带来的影响,但依旧无法解决这些问题,所以在5.0版本时推出了listpack,并且在7.0版本中替换掉了ziplist,它也是一种使用连续内存空间来保存数据的数据结构,并且使用多种编码来节省内存空间。它的内部结构如下图:
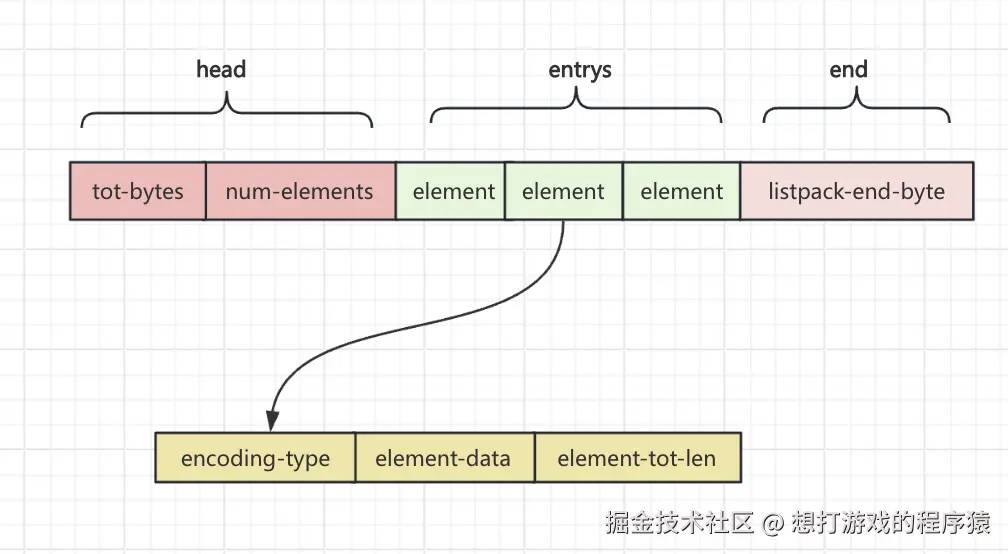
- tot-bytes:记录listpack占用的总字节数(占用4字节);
- num-elements:记录element的个数(占用2字节);
- elements:存储的元素;
- listpack-end-byte:结束标识(1字节);
- encoding-type:存放data部分的编码类型和长度;
- element-data:实际存放的数据;
- element-tot-len:encoding-type + element-data的长度,不包含自身。
上述就是redis中list类型的进化过程。
Set
set结构类似java中的set,是一个无序并且元素唯一的集合。它的底层是通过map和intset来实现的。
intset
当set中的元素都是64位以内的整数,并且元素的数量不超过512就会使用intset结构来存储。元素数量可以通过set-max-intset-entries来调整。intset结构代码:
typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset;这个结构相对简单,这里就不画图描述了。要注意encoding分为int16_t、int32_t、int64_t,如果之前的元素都是int16_t,此时插入一个int64_t会导致所有的元素的类型都升级为int64_t,只能升级不能降级。而存储的内容是连续的,这样就可以通过二分法进行查询,它的时间复杂度就可以优化到O(logN)。
map
map中的key就是set的值,map中的value为null。
Map
它类似于java的map集合,存储的是N对fieId-value集合,它的底层由dict和ziplist(7.0之前)以及listpack三种数据结构组成。
ziplist、listpack
上面已经介绍过ziplist、listpack了,这里不再详细介绍。redis会把fieId和value组成一个entry进行存储的,同时redis会对这两个值前面加标识位的以便区分entry中哪一段是fieId哪一段是value。使用这两种数据结构时需要满足如下条件:
- 每个fieId-value中的fieId和value的字节都要小于
hash-max-listpack-value(默认64); - 存储的fieId-value数量小于
hash-max-listpack-entries(默认512)。
dict
由数组和链表构成,数组元素占用的槽位叫做hash桶,当出现hash冲突时就在这个桶下面挂链表;
解决hash冲突的三种方法:链表法,开放地址法,再hash法。
dict实体代码如下:
struct dict { dictType *type; dictEntry **ht_table[2]; unsigned long ht_used[2]; long rehashidx; int16_t pauserehash;} dict;typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry;为了方便大家理解,我画了一张图可以先看一下:

- type:存放函数的结构体(计算哈希值函数、复制键的函数、复制值的函数等);
- ht_table:存放大小为2的散列表数组,每个指针指向一个dictEntry数组(默认初始大小为4);
- ht_used:记录每个dictEntry用了多少槽位;
- rehashidx:rehash标记位;
- pauserehas:表示rehash的状态;
- key:fieId,是一个SDS类型;
- v:具体的值;其中val是非数字类型时使用该指针存储;u64是无符号整数时使用的存储;s64是由符号整数时使用的存储;d是浮点数时使用的存储;
- next:当为链表时指向下一个dictEntry。
扩容和缩容
熟悉java的都知道hashMap和currentHashMap的扩容、缩容,那么redis肯定也有扩容和缩容。扩缩容时机:
- 当前没有执行备份命令
bgsave或bgrewriteaof时,负载因子大于等于1;- 当前执行备份命令
bgsave或bgrewriteaof时,负载因子大于等于5;- 负载因子 = dictEntry总数 / 哈希桶个数;
- 每次扩容,扩容后的容量是使用桶数的2倍往上找到第一个接近2的N次幂的数字;缩容同理。例如现在使用数量为17,那么扩容后的数组为32。
- 当databaseCron定时执行时检测到元素个数低于哈希桶分配的个数的10%时,进行缩容。
- 当前执行备份命令
bgsave或bgrewriteaof等操作时不可缩容。
对于redis扩容,是一个渐进式扩容,它的扩容过程:
1、rehashidx设置为0,表示正在扩容;
2、在rehash时,每次处理对dict散列表执行命令时都会检查是否处于扩容状态,如果是就把ht_table[0]上的元素rehash到ht_table[1]中,并将rehashidx的值加1。
3、上述操作直至全部迁移完成,把rehashidx设置为-1,并把ht_table[0]指向ht_table[1],同时清空原table。
4、redis也有一个定时函数,用于帮助迁移防止一直漏掉一些entry导致无法迁移完成,此时会一直维护两个table,进而影响redis性能。
Sorted Set
sorted set和set类似,都是存储一堆不可重复的集合,他们的区别在于sorted set是有序的,它由两部分member和score组成,如果score相同,则按照member字符串的字典顺序排序。它的底层结构分为dict+skiplist、ziplist(7.0之前)和listpack组成。
ziplist、listpack
ziplist、listpack这两个数据结构上面有介绍,这里就不再详细介绍它俩了。zset会把member和score组成一个entry,redis会对这两个值前面加标识位的以便区分entry中哪一段是member哪一段是score;同时还会按照score对entry进行排序;当符合以下两个条件会使用ziplist、listpack:
- 集合元素小于等于zset-max-listpack-entries(默认为128);
- member占用字节数小于等于zset-max-listpack-value(默认为64)。
skiplist + dict
sorted set在这里是采用两种类型存储,其实是一种以空间换时间的优化。它会分别在skiplist和dict中存储数据。
dict
把member存储在key中,把score存储在value中;这样对于ZSCORE key member命令而言就是O(1)时间复杂度的。
skiplist
skiplist(跳表)就是多层级有序链表(最多32层),上层是下层的索引,相比B-树,b+ 树等更消耗内存,但它实现起来更简单不需要维护复杂的树形结构。代码如下:
typedef struct zskiplistNode { sds ele; double score; struct zskiplistNode *backward; struct zskiplistLevel { struct zskiplistNode *forward; unsigned long span; } level[]; } zskiplistNode; typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level; } zskiplist;结构图如下:
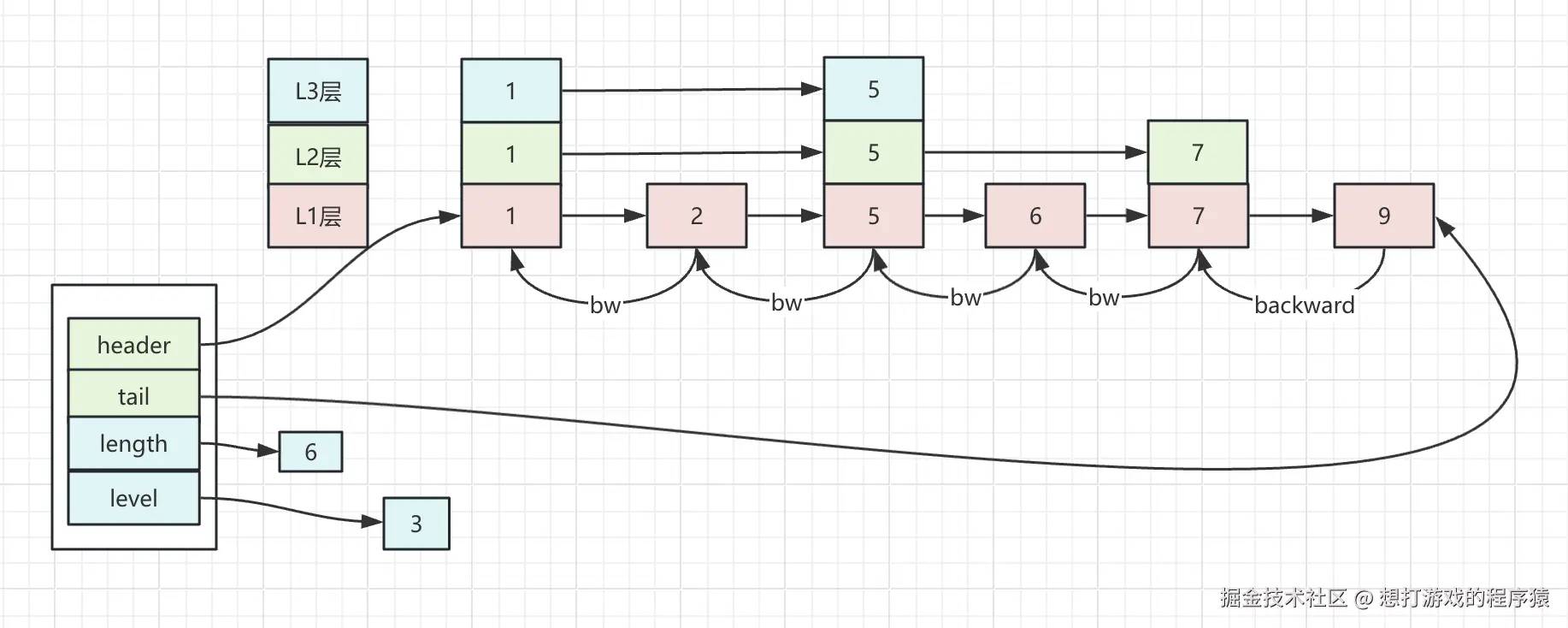 当想查询节点6时,先从l3层查询,查询节点1、节点5,第3层后面是null,第2层后面是7,此时查询第1层就查询到节点6了。注意:一个节点是存在于多层的。
当想查询节点6时,先从l3层查询,查询节点1、节点5,第3层后面是null,第2层后面是7,此时查询第1层就查询到节点6了。注意:一个节点是存在于多层的。
redis中不会严格要求跳表中两层的数量比例,这样在插入的过程中维护层级比较消耗性能,它是采用随机的方式来告诉节点要出现在哪层,如果没有则创建一层,如果删除节点刚好该层没有节点则删除该层。同时在zskiplistLevel中会记录下来span跨度,这样我们在查询数据时只需要把经过的跨度都加起来就知道这条数据在整体中的排名了。
总结
以前看过很多篇介绍redis数据类型的,但几乎都是描述一下哪些数据类型用了哪些数据类型,并没有详细说明为什么以及每个数据结构是什么样子的,这样就很难形成长期记忆,读完本文了解了每个数据结构也就很容易记住redis的这些数据类型都采用了什么数据结构了。
各种数据类型,读写一条数据的时间复杂度是多少?
每种数据类型采用的数据结构不同,当使用不同数据结构时他们的时间复杂度也不同,具体可以参考文章描述。
为什么不同redis版本有不同的底层实现?
其实底层实现更改的只有linkedlist以及ziplist,因为ziplist会导致连锁更新,linkedlist中前后指针占用太多内容,同时内存不连续查询性能慢,时间复杂度为O(n).
为什么一种数据类型有多种底层实现?
因为redis是一种内存型数据库,比较吃内存,多种底层实现可以节约内存使用。
创作不易,觉得文章写得不错帮忙点个赞吧!如转载请标明出处~