
包阅导读总结
1.
“`
多模型预测、Databricks、预测框架、模型评估、提高精度
“`
2.
总结:本文介绍了用于多模型预测的MMF框架,能在Databricks上对大量时间序列进行多模型训练和预测,其优势包括缩短上市时间、提高预测精度、支持生产就绪等,还标准化了模型输出以利比较评估,能与Databricks平台无缝集成,方便模型管理。
3.
主要内容:
– 多模型预测框架(MMF)简介
– 是时间序列预测的基础,企业不断探索提高预测精度的方法。
– 面临多种预测技术选择的挑战。
– MMF框架特点
– 支持大规模多模型训练和预测。
– 涵盖数据准备、回测、交叉验证等。
– 强调配置而非编码。
– 框架中的模型
– 包含 40 多种模型。
– 可同时评估多个模型,加快上市时间。
– 模型输出与评估
– 生成两个 UC 表用于评估和选择。
– 可创建自定义指标。
– 模型管理
– 与 Databricks 平台集成。
– 通过 MLflow 自动记录参数等。
– 便于模型复用和部署。
– 总结与展望
– 是热门客户用例,希望支持预测工作。
– 感谢相关开源社区贡献。
思维导图: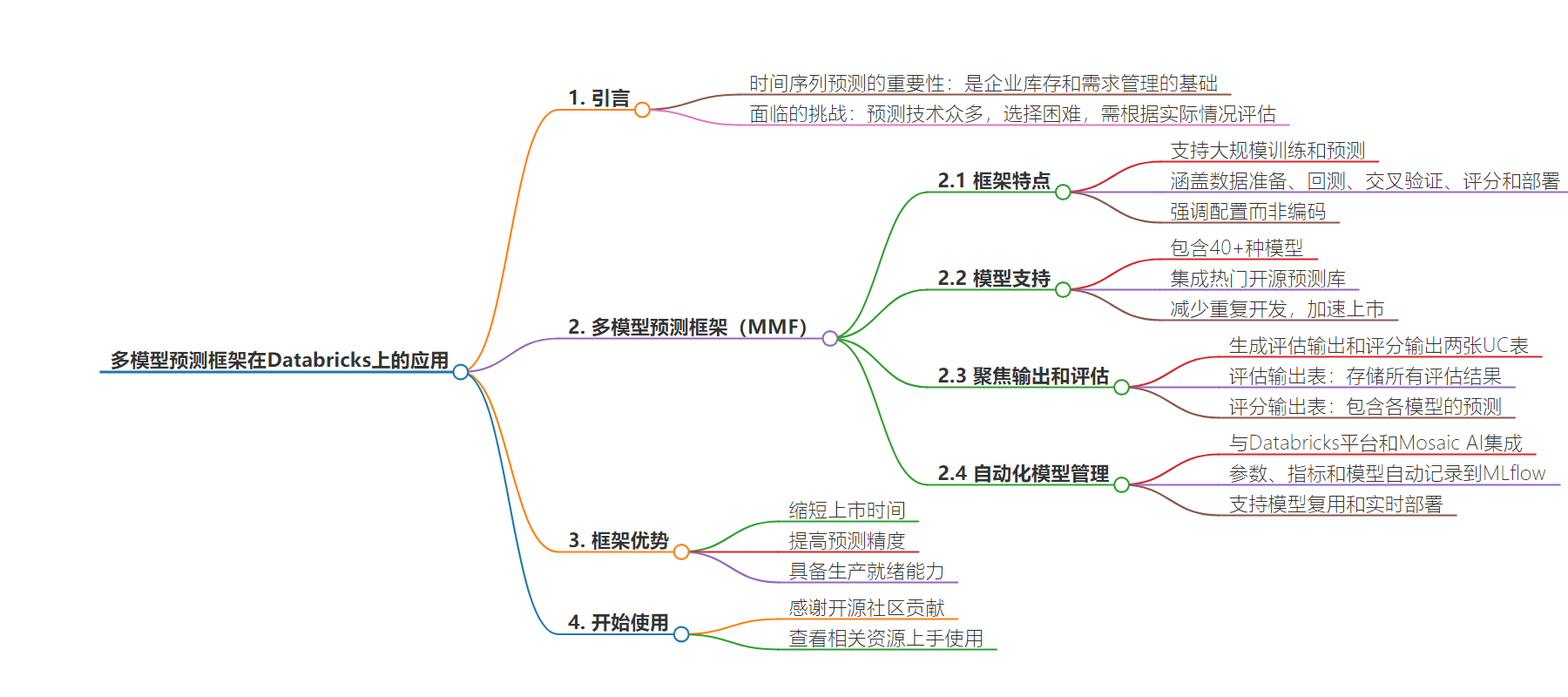
文章地址:https://www.databricks.com/blog/framework-multi-model-forecasting-databricks
文章来源:databricks.com
作者:Databricks
发布时间:2024/7/26 11:31
语言:英文
总字数:1127字
预计阅读时间:5分钟
评分:91分
标签:时间序列预测,Databricks,机器学习,模型评估,开源
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Introduction
Time series forecasting serves as the foundation for inventory and demand management in most enterprises. Using data from past periods along with anticipated conditions, businesses can predict revenues and units sold, allowing them to allocate resources to meet expected demand. Given the foundational nature of this work, businesses are constantly exploring ways to improve forecasting accuracy, allowing them to put just the right resources in the right place at the right time while minimizing capital commitments.
The challenge for most organizations is the wide range of forecasting techniques at their disposal. Classic statistical techniques, generalized additive models, machine learning and deep learning-based approaches and now pre-trained generative AI transformers provide organizations with an overwhelming number of choices, some of which work better in some scenarios than in others.
While most model creators claim improved forecasting accuracy against baseline datasets, the reality is that domain knowledge and business requirements typically narrow the number of model choices to a few handful and then only practical application and evaluation against an organization’s datasets can determine which performs best. And what’s “best” often varies from forecasting unit to forecasting unit and even over time, forcing organizations to perform on-going comparative evaluations between techniques to determine what works best in the moment.
In this blog, we will introduce the framework Many Model Forecasting (MMF) for the comparative evaluation of forecasting models. MMF enables users to train and predict using multiple forecasting models at scale on hundreds of thousands to many millions of time series at their finest granularity. With support for data preparation, backtesting, cross-validation, scoring and deployment, the framework allows forecasting teams to implement a complete forecast-generation solution using classic and state of the art models with an emphasis on configuration over coding, minimizing the effort required to introduce new models and capabilities into their processes. We have found in numerous customer implementations this framework:
- Reduces time to market: With many well-established and cutting-edge models already integrated, users can quickly evaluate and deploy solutions.
- Improves forecast accuracy: Through extensive evaluation and fine-grained model selection, MMF enables organizations to efficiently uncover forecasting approaches that provide enhanced precision.
- Enables production readiness: By adhering to MLOps best practices, MMF integrates natively with Databricks Mosaic AI, ensuring seamless deployment.
Access 40+ Models Using the Framework
The Many Model Forecasting (MMF) framework is delivered as a Github repository with fully accessible, transparent and commented source code. Organizations can use the framework as-is or extend it to add functionality needed by their specific organization.
The MMF includes built-in support for over 40+ models through integration of some of the most popular open source forecasting libraries available today, including statsforecast, neuralforecast, sktime, r fable, chronos, moirai, and moment. And as our customers explore newer models, we intend to support even more.
With these models already integrated into the framework, users can eliminate the redundant development of data preparation and model training specific to each model and instead focus on evaluation and deployment, significantly speeding up the time to market. This is particularly advantageous for teams of data scientists and machine learning engineers with limited resources and business stakeholders eager for results.
Using the MMF, forecasting teams can evaluate multiple models simultaneously, allowing both built-in and customized logic to select the best model for each time series and enhancing the overall accuracy of the forecasting solution. Deployed to a Databricks cluster, the MMF leverages the full resources made available to it to speed model training and evaluation through automated parallelism. Teams simply configure the resources they wish to use for the forecasting exercise and the MMF takes care of the rest.
Focus on Model Outputs & Comparative Evaluations
The key to the MMF is the standardization of the model outputs. When running forecasts, MMF generates two UC tables: evaluation_output and scoring_output. The evaluation_output (Figure 1) table stores all evaluation results from every backtesting period, across all time series and models, providing a comprehensive overview of each model’s performance. This includes forecasts alongside actuals, enabling users to construct custom metrics that align with specific business needs. While MMF offers several out-of-the-box metrics, i.e.MAE, MSE, RMSE, MAPE, and SMAPE, the flexibility to create custom metrics facilitates detailed evaluation and model selection or ensembling, ensuring optimal forecasting outcomes.
The second table, scoring_output (Figure 2), contains forecasts for each time series from each model. Using the comprehensive evaluation results stored in the evaluation_output table, you can select forecasts from the best-performing model or a combination of models. By choosing the final forecasts from a pool of competing models or ensemble of selected models, you can achieve superior accuracy and stability compared to relying on a single model, thereby enhancing the overall accuracy and stability of your large-scale forecasting solution.
Ease Model Management through Automation
Built on the Databricks platform, the MMF seamlessly integrates with its Mosaic AI capabilities, providing automated logging of parameters, aggregated metrics, and models (for global and foundation models) to MLflow (Figure 3). Secured as part of Databricks’ Unity Catalog, forecasting teams can employ fine-grained access control and proper management of their models, not just their model output.
Should a team need to re-use a model (as is common in machine learning scenarios), they can simply load them onto their cluster using MLflow’s load_model method or deploy them behind a real-time endpoint using Databricks Mosaic AI Model Serving (Figure 4). With time series foundation models hosted in Model Serving, you can generate multi-step ahead forecasts at any given time, provided you supply the history at the correct resolution. This capability significantly enhances applications in on-demand forecasting, real-time monitoring, and tracking.
Get Started Now
At Databricks, forecast generation is one of the most popular customer use cases. The foundational nature of forecasting for so many business processes means that organizations are constantly seeking improvements in forecast accuracy.
With this framework, we hope to provide forecasting teams with easy access to the most scalable, robust and extensive functionality needed to support their work. Through the MMF, teams can now focus on generating results and less on all the development work required to evaluate new approaches and bring them to production readiness.
Acknowledgments
We thank the teams behind statsforecast and neuralforecast (Nixtla), r fable, sktime, chronos, moirai, moment, and timesfm for their contributions to the open source communities, which have provided us with access to their outstanding tools.
Check out the MMF repository and sample notebooks showing how organizations can get started using it within their Databricks environment.