
包阅导读总结
1.
关键词:Java 虚拟线程、平台线程、吞吐量、调度、性能解析
2.
总结:本文主要探讨了 Java 虚拟线程,对比其与传统平台线程的区别,介绍其能提高服务器应用程序的吞吐量,解决线程资源问题,阐述了其原理、实现方式、使用方法及调度机制。
3.
主要内容:
– Java 虚拟线程
– 定义:由 Java 运行时实现,可大量运行在同一进程中。
– 优势:能有效运行以“每个请求一个线程”方式编写的服务器应用,提高吞吐量,减少硬件浪费。
– 引入原因:解决平台线程资源昂贵和操作系统线程数量限制的问题。
– 原理与实现
– 原理:切断与操作系统线程的一对一对应关系,类似虚拟内存,将大量虚拟线程映射到少量操作系统线程。
– 实现:虚拟线程是 `java.lang.Thread` 的实例,调用阻塞 I/O 操作时会被挂起,适用于 IO 密集型操作。
– 使用
– 通过 `Thread` 类创建。
– 通过 `Executors` 创建,为每个任务创建新的虚拟线程。
– 实现服务端,监听客户端连接时创建虚拟线程处理。
– 调度
– 平台线程由操作系统调度,虚拟线程由 Java 运行时调度。
思维导图:
文章地址:https://mp.weixin.qq.com/s/G1-qLXqHva193LBJ6pSbgg
文章来源:mp.weixin.qq.com
作者:颜洵
发布时间:2024/8/28 10:07
语言:中文
总字数:7963字
预计阅读时间:32分钟
评分:91分
标签:Java,虚拟线程,并发编程,高吞吐量,IO密集型
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
引入虚拟线程是为了减少编写、维护和观察高吞吐量并发应用程序的工作量。
对于应用提供的接口,其响应时间一定,那么此时其吞吐量与应用程序能够同时处理的请求数量(即并发数量)成正比。假设一个接口的响应耗时为50ms,而应用程序可以同时并发处理10个请求,那么每秒就有200(1s/50ms*10)个请求的吞吐量。此时如果应用程序可以将并发处理请求的能力提升到100,那么每秒则能达到2000的吞吐量。显然提高并发处理的线程数可以显著提高应用的吞吐量,然而Java中平台线程是昂贵的资源,默认每个平台线程消耗1MB栈内存,即 JVM 中运行的平台线程数量有上限。此外操作系统对于支持的最大线程也是有限制的,并不能无限制的增加内核线程的数量。下图为系统支持的最大线程数:

在大多数JVM的实现中,Java线程是和操作系统线程是一对一映射的(如下图),如果我们使用thread-per-request的形式(常见的如Tomcat、Jetty都是这样的模型),即为每个请求创建一个线程进行处理,那么很快便会到达操作系统线程数上限。

如果请求是IO密集型,那么大多线程都是处于阻塞等待IO返回的情况,会出现线程资源已经耗尽,而CPU利用率却很低。因此,若一个平台线程专用于用户请求,对高并发用户的应用程序,就非常容易出现线程池打满,后续请求进入阻塞的情况。
一些希望充分利用硬件的开发人员放弃了thread-per-request的形式,转而采用响应式编程。即请求处理代码不是从头到尾都在一个线程上进行,而是在等待 I/O 操作完成时将其线程返回到池中,以便线程可以为其他请求提供服务。这种细粒度的线程共享(在这种共享中,代码仅在线程执行计算时保留在线程上,而不是在等待 I/O 时保留线程)允许大量并发操作,而不会长时间占用线程。
然而这种方式虽然消除了操作系统线程稀缺性对吞吐量的限制,但它显著提高程序的理解成本和调试成本。它采用一组单独的 I/O 方法,这些方法不等待 I/O 操作完成,而是稍后向回调发出完成信号。开发人员必须将其请求处理逻辑分解为小阶段,然后将它们组合到一个顺序管道中。在响应式编程中,请求的每个阶段都可能在不同的线程上执行,并且每个线程都以交错方式运行属于不同请求的阶段,这种方式非常的复杂,创建响应式通道、调试以及理解它们的执行流程都非常的困难,更别说遇到异常时的排查。
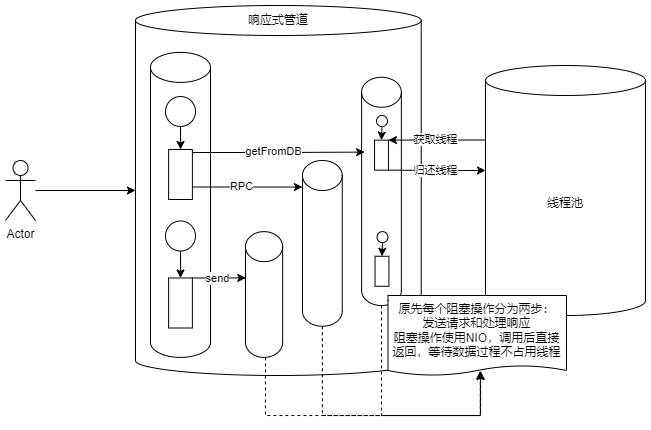
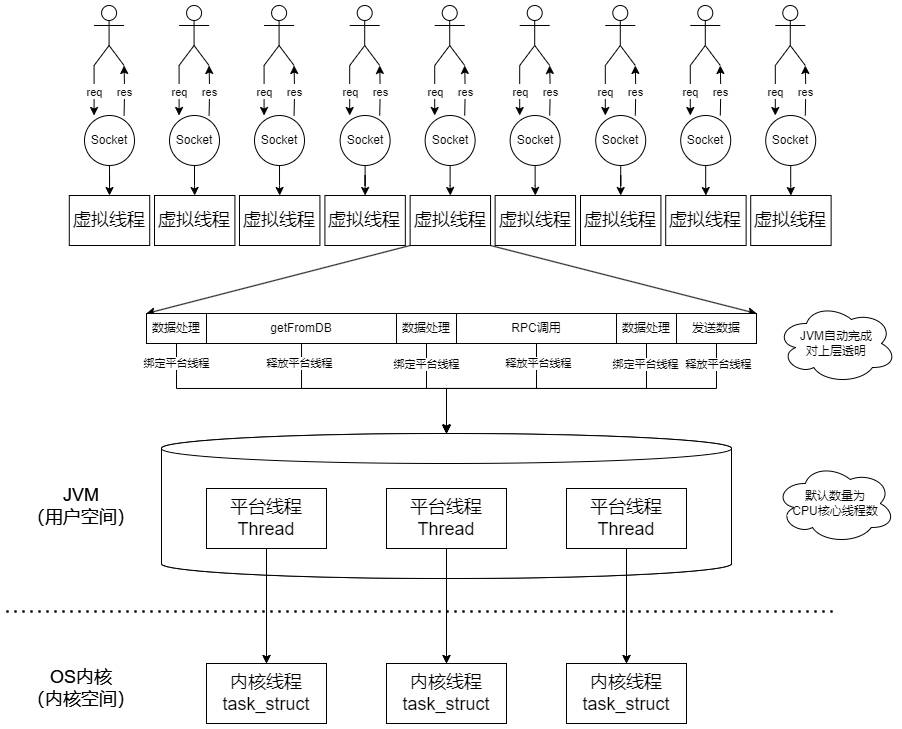
虚拟线程的引入解决了上述的问题。Java 运行时以一种切断 Java 线程与操作系统线程的一对一对应关系的方式来实现 Java 线程,即虚拟线程。正如操作系统通过将大型虚拟地址空间映射到有限数量的物理 RAM 来给人一种内存充足的错觉一样,Java 运行时可以通过将大量虚拟线程映射到少量的操作系统线程来给人一种线程充足的错觉。
平台线程(java.lang.Thread) 是以传统方式实现的实例,作为操作系统线程的薄包装器,与系统线程一一映射,而虚拟线程不绑定到特定操作系统线程的实例。“thread-per-request”样式的应用程序代码可以在请求的整个持续时间内在虚拟线程中运行,但虚拟线程仅在 CPU 上执行计算时使用操作系统线程。虚拟线程具备与异步样式相同的可伸缩性,只是它的实现是透明的,不需要我们额外的理解和开发成本。当在虚拟线程中运行的代码进行阻塞的 I/O 操作时,运行时将自动挂起虚拟线程,直到以后可以恢复为止。对于 Java 开发人员来说,虚拟线程只是创建成本低廉且几乎无限丰富的线程。硬件利用率接近最佳状态,允许高并发性,从而实现高吞吐量,同时应用程序与 Java 平台及其工具的多线程设计保持和谐。
实现

▐定义
▐原理
final class VirtualThread extends BaseVirtualThread {private static final ForkJoinPool DEFAULT_SCHEDULER = createDefaultScheduler();private final Executor scheduler;private final Continuation cont;private final Runnable runContinuation;private volatile Thread carrierThread;VirtualThread(Executor scheduler, String name, int characteristics, Runnable task) {super(name, characteristics, false);Objects.requireNonNull(task);if (scheduler == null) {Thread parent = Thread.currentThread();if (parent instanceof VirtualThread vparent) {scheduler = vparent.scheduler;} else {scheduler = DEFAULT_SCHEDULER;}}this.scheduler = scheduler;this.cont = new VThreadContinuation(this, task);this.runContinuation = this::runContinuation;}private static ForkJoinPool createDefaultScheduler() {ForkJoinWorkerThreadFactory factory = pool -> {PrivilegedAction<ForkJoinWorkerThread> pa = () -> new CarrierThread(pool);return AccessController.doPrivileged(pa);};PrivilegedAction<ForkJoinPool> pa = () -> {int parallelism, maxPoolSize, minRunnable;String parallelismValue = System.getProperty("jdk.virtualThreadScheduler.parallelism");String maxPoolSizeValue = System.getProperty("jdk.virtualThreadScheduler.maxPoolSize");String minRunnableValue = System.getProperty("jdk.virtualThreadScheduler.minRunnable");if (parallelismValue != null) {parallelism = Integer.parseInt(parallelismValue);} else {parallelism = Runtime.getRuntime().availableProcessors();}if (maxPoolSizeValue != null) {maxPoolSize = Integer.parseInt(maxPoolSizeValue);parallelism = Integer.min(parallelism, maxPoolSize);} else {maxPoolSize = Integer.max(parallelism, 256);}if (minRunnableValue != null) {minRunnable = Integer.parseInt(minRunnableValue);} else {minRunnable = Integer.max(parallelism / 2, 1);}Thread.UncaughtExceptionHandler handler = (t, e) -> { };boolean asyncMode = true;return new ForkJoinPool(parallelism, factory, handler, asyncMode,0, maxPoolSize, minRunnable, pool -> true, 30, SECONDS);};return AccessController.doPrivileged(pa);}private void runContinuation() {if (Thread.currentThread().isVirtual()) {throw new WrongThreadException();}int initialState = state();if (initialState == STARTED || initialState == UNPARKED || initialState == YIELDED) {if (!compareAndSetState(initialState, RUNNING)) {return;}if (initialState == UNPARKED) {setParkPermit(false);}} else {return;}mount();try {cont.run();} finally {unmount();if (cont.isDone()) {afterDone();} else {afterYield();}}}}
虚拟线程有几个核心的对象:
-
Continuation:译为“续延”,是用户真实任务的包装器,虚拟线程会把任务包装到一个Continuation实例中,当任务需要阻塞挂起的时候,会调用Continuation的yield操作进行阻塞
-
Scheduler:译为“调度器”,会把任务提交到一个平台线程池中执行,虚拟线程中维护了一个默认的调度器DEFAULT_SCHEDULER,这是一个 ForkJoinPool 实例,最大线程数默认是系统核心线程数,最大为 256,可以通过 jdk.virtualThreadScheduler.maxPoolSize 进行设置。
-
carrier:载体线程(Thread对象),指的是负责执行虚拟线程中任务的平台线程。
-
runContinuation:一个Runnable对象,用于在任务运行或继续之前,虚拟线程将装载到当前线程上。当任务完成或完成时,将其卸载。
具体虚拟线程的工作流程后续可能会再深入源码进行分析。
使用

▐使用Thread类创建虚拟线程
Thread.Builder.OfVirtual virtualThreadBuilder = Thread.ofVirtual().name("worker-", 0);Thread worker0 = virtualThreadBuilder.start(this::doSomethings);worker0.join();System.out.print("finish worker-0 running");Thread worker1 = virtualThreadBuilder.start(this::doSomethings);worker1.join();System.out.print("finish worker-1 running");
调用 Thread.ofVirtual() 方法会创建一个用于创建虚拟线程的 Thread.Builder 实例。
▐使用Executors创建虚拟线程
try (ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor()) {Future<?> submit = executorService.submit(this::doSomethings);submit.get();System.out.print("finish running");}
虚拟线程既便宜又丰富,因此永远不应该被池化,应该为每个应用程序任务创建一个新的虚拟线程。使用 newVirtualThreadPerTaskExecutor 创建的是一个没有线程数量限制的线程池(并不是一个典型的线程池,并不是为了复用线程而存在),其会为每个提交的任务创建一个新的虚拟线程进行处理。
▐使用虚拟线程实现服务端
public class Server {public static void main(String[] args) {Set<String> platformSet = new HashSet<>();new Thread(() -> {try {Thread.sleep(10000);System.out.println(platformSet.size());} catch (InterruptedException e) {throw new RuntimeException(e);}}).start();try (ServerSocket serverSocket = new ServerSocket(9999)) {Thread.Builder.OfVirtual clientThreadBuilder = Thread.ofVirtual().name("client", 1);while (true) {Socket clientSocket = serverSocket.accept();clientThreadBuilder.start(() -> {String platformName = Thread.currentThread().toString().split("@")[1];platformSet.add(platformName);try (BufferedReader in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));PrintWriter out = new PrintWriter(clientSocket.getOutputStream(), true);) {String inputLine;while ((inputLine = in.readLine()) != null) {System.out.println(inputLine + "(from:" + Thread.currentThread() + ")");out.println(inputLine);}} catch (IOException e) {System.err.println(e.getMessage());}});}} catch (IOException e) {System.err.println("Exception caught when trying to listen on port 999");System.err.printf(e.getMessage());}}}
监听客户端连接,每次有客户端连接则创建一个虚拟线程进行处理,并在虚拟线程运行时将其平台线程的名称加入到Set中,另外有一个线程睡眠10秒后打印出Set的大小,则可以看出这些虚拟线程实际上用了多少个平台线程。
public class Client {public static void main(String[] args) throws InterruptedException {Thread.Builder.OfVirtual builder = Thread.ofVirtual().name("client", 1);for (int i = 0; i < 100000; i++) {builder.start(() -> {try (Socket serverSocket = new Socket("localhost", 9999);BufferedReader in = new BufferedReader(new InputStreamReader(serverSocket.getInputStream()));PrintWriter out = new PrintWriter(serverSocket.getOutputStream(), true);) {out.println("hello");String inputLine;while ((inputLine = in.readLine()) != null) {System.out.println(inputLine);}} catch (UnknownHostException e) {System.err.println("Don't know about localhost");} catch (IOException e) {System.err.println("Couldn't get I/O for the connection to localhost");}});}Thread.sleep(1000000000);}}
创建10w个客户端连接服务端并发送消息,主线程长时间睡眠避免程序直接结束。
服务端最终使用了19个平台线程(与CPU核心线程数有关)用于处理10w个客户端连接。
▐虚拟线程调度和固定
当平台线程运行时,由操作系统进行调度,而当虚拟线程运行时,由 Java 运行时进行调度。当 Java 运行时调度一个虚拟线程时,会将这个虚拟线程挂载在一个平台线程上,之后同样由操作系统内核进行调度。这里被挂载的平台线程被称为 carrier(搬运工)。当虚拟线程被阻塞时,会从 carrier 上取消挂载,此时 carrier 是空闲的,Java 运行时可以调度其他虚拟线程挂载在其上。这个过程对于内核线程是无感知的,可以避免使用平台线程遇到阻塞时出现内核态与用户态切换带来的开销,并且充分利用 CPU 计算性能,提高应用程序的吞吐量。
当虚拟线程被固定(pinned)在 carrier 上时,即使遇到阻塞也不会取消挂载。在以下场景虚拟线程会被固定:
1. 虚拟线程执行的方法或块被 synchronized 关键字标识时
2. 虚拟线程运行外部函数时
固定不会使应用程序出错,但可能会阻碍其可伸缩性。可以尝试通过使用java.util.concurrent.locks.ReentrantLock.synchronized 来修改频繁运行的块和方法以及保护可能长时间的I/O操作,以避免频繁和长时间的固定。

注意事项
由于虚拟线程是Java.lang.Thread的实现,并且遵循自Java SE 1.0以来指定Java.lang.Thread的相同规则,因此开发人员不需要学习使用它们的新概念。然而,由于无法生成非常多的平台线程(多年来Java中唯一可用的线程实现),因此产生了旨在应对其高成本的实践。当应用于虚拟线程时,这些做法会适得其反,必须摒弃。
▐写简单的同步代码,使用阻塞的API
虚拟线程可以显著提高以thread-per-request的方式编写的服务器的吞吐量(而不是延迟)。在这种风格中,服务器在整个持续时间内专用一个线程来处理每个传入请求。
阻塞平台线程的代价很高,因为它占用了系统线程(相对稀缺的资源),而并没有做多少有意义的工作,因而在过去我们可能会使用异步非阻塞的方式来实现一些功能,然而虚拟线程可以有很多,所以阻塞它们的成本很低,因此我们应该以直接的同步风格编写代码,并使用阻塞I/O api。
例如,下面以非阻塞、异步风格编写的代码不会从虚拟线程中获得太多好处。
CompletableFuture.supplyAsync(info::getUrl, pool).thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofString())).thenApply(info::findImage).thenCompose(url -> getBodyAsync(url, HttpResponse.BodyHandlers.ofByteArray())).thenApply(info::setImageData).thenAccept(this::process).exceptionally(t -> { t.printStackTrace(); return null; });
下面以同步风格编写并使用简单阻塞IO的代码将受益匪浅:
try {String page = getBody(info.getUrl(), HttpResponse.BodyHandlers.ofString());String imageUrl = info.findImage(page);byte[] data = getBody(imageUrl, HttpResponse.BodyHandlers.ofByteArray());info.setImageData(data);process(info);} catch (Exception ex) {t.printStackTrace();}
这样的代码也更容易在调试器中进行调试,在分析器中进行概要分析,或者使用线程转储进行观察。以这种风格编写的堆栈越多,虚拟线程的性能和可观察性就越好。用其他风格编写的程序或框架,如果没有为每个任务指定一个线程,就不应该期望从虚拟线程中获得显著的好处。避免将同步、阻塞代码与异步框架混在一起。
▐不要共用虚拟线程
虚拟线程虽然具有与平台线程相同的行为,但它们不应该表示相同的程序概念。平台线程是稀缺的,因此是一种宝贵的资源。需要管理宝贵的资源,管理平台线程的最常用方法是使用线程池。接下来需要回答的问题是,池中应该有多少线程?
但是虚拟线程非常多,因此每个线程不应该代表一些共享的、池化的资源,而应该代表一个任务,线程从托管资源转变为应用程序域对象。我们应该有多少个虚拟线程的问题变得很明显,就像我们应该使用多少个字符串在内存中存储一组用户名的问题一样:虚拟线程的数量总是等于应用程序中并发任务的数量。
为了将每个应用程序任务表示为一个线程,不要像下面的例子那样使用共享线程池执行器:
Future<ResultA> f1 = sharedThreadPoolExecutor.submit(task1);Future<ResultB> f2 = sharedThreadPoolExecutor.submit(task2);// ... use futures
应该采用以下的方式:
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {Future<ResultA> f1 = executor.submit(task1);Future<ResultB> f2 = executor.submit(task2);}
代码仍然使用ExecutorService,但是
Executors.newVirtualThreadPerTaskExecutor()返回的实例并不会复用虚拟线程。相反,它为每个提交的任务创建一个新的虚拟线程。
void handle(Request request, Response response) {var url1 = ...var url2 = ...try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {var future1 = executor.submit(() -> fetchURL(url1));var future2 = executor.submit(() -> fetchURL(url2));response.send(future1.get() + future2.get());} catch (ExecutionException | InterruptedException e) {response.fail(e);}}String fetchURL(URL url) throws IOException {try (var in = url.openStream()) {return new String(in.readAllBytes(), StandardCharsets.UTF_8);}}
此外,ExecutorService本身是轻量级的,我们可以创建一个新的,就像处理任何简单的对象一样。并不用将这个对象保存起来每次使用相同的这个实例,而是在需要的时候创建一个就行了。
您应该创建一个新的虚拟线程,如上所示,即使是小型的、短暂的并发任务也是如此。根据经验,如果应用程序从来没有10,000个或更多的虚拟线程,那么它不太可能从虚拟线程中获益。要么它的负载太轻,不需要更好的吞吐量,要么没有向虚拟线程表示足够多的任务。
▐使用信号量限制并发
有时需要限制某个操作的并发性。例如,某些外部服务可能无法处理十个以上的并发请求。使用平台线程时可以用线程池的大小来限制并发的数量,而在使用虚拟线程时,如果希望限制访问某些服务的并发性,则应该使用专门为此目的设计的Semaphore类。下面的例子演示了这个类:
Semaphore sem = new Semaphore(10);Executors.newVirtualThreadPerTaskExecutor().submit(() -> {try {sem.acquire();doSomething();} catch (InterruptedException e) {throw new RuntimeException(e);} finally {sem.release();}});
▐不要在线程局部变量中缓存昂贵的可重用对象
虚拟线程支持线程局部变量,就像平台线程一样。通常,线程局部变量用于将一些特定于上下文的信息与当前运行的代码相关联,例如当前事务和用户ID。对于虚拟线程,使用线程局部变量是完全合理的。而线程局部变量的另一个作用是缓存可重用对象,这些对象缓存在线程局部变量中,供不同时间运行在线程上的多个任务重用,目的是减少实例化的次数和内存中的实例数量。
这与虚拟线程的设计完全不符,只有当多个任务共享并重用线程(因此是缓存在线程本地的昂贵对象)时,这种缓存才有用,就像平台线程被池化时一样。在线程池中运行时,可能会调用许多任务,但由于线程池只包含几个线程,因此对象只会被实例化几次(每个线程池一次),然后缓存并重用。但是,虚拟线程永远不会被池化,也不会被不相关的任务重用。因为每个任务都有自己的虚拟线程,所以来自不同任务的每次调用都会触发这个缓存变量的实例化。此外,由于可能有大量的虚拟线程并发地运行,昂贵的对象可能会消耗相当多的内存。这些结果与线程局部缓存想要实现的目标完全相反。
▐避免长时间和频繁的固定
当前虚拟线程实现的一个限制是,在synchronized块或方法内部执行阻塞操作会导致JDK的虚拟线程调度器阻塞宝贵的操作系统线程,而在块或方法外部执行阻塞操作则不会,我们称这种情况为pinning。如果阻塞操作既长又频繁,那么固定可能会对服务器的吞吐量产生不利影响。保护短期操作,比如内存操作,或者不经常使用synchronized块或方法的操作。
如果固定存在时间较长且频繁的地方,那么在这些特定的地方用ReentrantLock代替synchronized(不需要在synchronized保护时间较短或不频繁的操作的地方替换synchronized)。下面是一个长时间且频繁使用同步块的例子。
synchronized(lockObj) {frequentIO();}
采用以下的实现替换:
lock.lock();try {frequentIO();} finally {lock.unlock();}
JDK:OpenJDK21.0.4
物理机:Win11 & i5-14600KF(14核20线程)
▐平台线程与虚拟线程简单对比示例
public class PerformanceTest {private static final int REQUEST_NUM = 10000;public static void main(String[] args) {long vir = 0, p1 = 0, p2 = 0, p3 = 0, p4 = 0;for (int i = 0; i < 3; i++) {vir += testVirtualThread();p1 += testPlatformThread(200);p2 += testPlatformThread(500);p3 += testPlatformThread(800);p4 += testPlatformThread(1000);System.out.println("--------------");}System.out.println("虚拟线程平均耗时:" + vir / 3 + "ms");System.out.println("平台线程[200]平均耗时:" + p1 / 3 + "ms");System.out.println("平台线程[500]平均耗时:" + p2 / 3 + "ms");System.out.println("平台线程[800]平均耗时:" + p3 / 3 + "ms");System.out.println("平台线程[1000]平均耗时:" + p4 / 3 + "ms");}private static long testVirtualThread() {long startTime = System.currentTimeMillis();ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();for (int i = 0; i < REQUEST_NUM; i++) {executorService.submit(PerformanceTest::handleRequest);}executorService.close();long useTime = System.currentTimeMillis() - startTime;System.out.println("虚拟线程耗时:" + useTime + "ms");return useTime;}private static long testPlatformThread(int poolSize) {long startTime = System.currentTimeMillis();ExecutorService executorService = Executors.newFixedThreadPool(poolSize);for (int i = 0; i < REQUEST_NUM; i++) {executorService.submit(PerformanceTest::handleRequest);}executorService.close();long useTime = System.currentTimeMillis() - startTime;System.out.printf("平台线程[%d]耗时:%dms\n", poolSize, useTime);return useTime;}private static void handleRequest() {try {Thread.sleep(300);} catch (InterruptedException e) {throw new RuntimeException(e);}}}
测试结果:
虚拟线程耗时:654ms平台线程[200]耗时:15551ms平台线程[500]耗时:6241ms平台线程[800]耗时:4069ms平台线程[1000]耗时:3137ms--------------虚拟线程耗时:331ms平台线程[200]耗时:15544ms平台线程[500]耗时:6227ms平台线程[800]耗时:4047ms平台线程[1000]耗时:3126ms--------------虚拟线程耗时:326ms平台线程[200]耗时:15552ms平台线程[500]耗时:6228ms平台线程[800]耗时:4054ms平台线程[1000]耗时:3151ms--------------虚拟线程平均耗时:437ms平台线程[200]平均耗时:15549ms平台线程[500]平均耗时:6232ms平台线程[800]平均耗时:4056ms平台线程[1000]平均耗时:3138ms
由于虚拟线程可以无限制的创建,而平台线程受线程池大小约束,因而1万个请求并不能同时处理,后续的请求需要等待前面的请求处理完成释放线程后才能进行,所以明显耗时远高于使用虚拟线程。
▐简单的Web服务测试
springboot-web版本(Tomcat/10.1.19):3.2.3 / springboot-webflux版本(Netty):3.2.3
编写简单的测试程序,使用Thread.sleep模拟300ms的阻塞,使用Jmeter模拟3000个用户的并发请求。
web版本程序:
@RestControllerpublic class TestController {@GetMapping("get")public String get() {try {Thread.sleep(300);} catch (InterruptedException e) {throw new RuntimeException(e);}return "ok";}}
通过application.yaml配置文件控制线程数量和是否启用虚拟线程:
server:tomcat:threads:max: 200spring:threads:virtual:enabled: false # 是否启用虚拟线程
webflux版本程序:
@Configurationpublic class TestWebClient {@Beanpublic RouterFunction<ServerResponse> routes() {return route(GET("/get"),request -> ok().contentType(MediaType.APPLICATION_JSON).body(fromPublisher(Mono.just("ok").delayElement(Duration.ofMillis(300)), String.class)));}}
测试结果:
|
使用平台线程数 |
吞吐量(req/s) |
平均响应时间(ms) |
90% |
95% |
99% |
|
|
虚拟线程 |
20 |
5217 |
316 |
311 |
344 |
354 |
|
平台线程 |
200 |
624.5 |
2660 |
4407 |
4782 |
4801 |
|
平台线程 |
512 |
1564.1 |
984 |
1683 |
1693 |
1787 |
|
平台线程 |
800 |
2340 |
661 |
1067 |
1070 |
1075 |
|
WebFlux |
5281.3 |
310 |
314 |
321 |
325 |
可以看到使用虚拟线程和WebFlux响应式时的吞吐量远超使用普通线程池,且虚拟线程的吞吐量并不比WebFlux差,而使用虚拟线程不需要进行复杂的响应式编程,只需要配置启用虚拟线程即可实现高吞吐量。

结语
总之,Java虚拟线程的引入是对现代并发编程模型的一次革新,它不仅简化了并发编程的复杂度,还极大地提升了应用的并发处理能力和资源利用率,为构建高性能、可扩展的服务器端应用提供了新的思路和工具。随着技术的成熟和普及,虚拟线程有望成为未来Java并发编程的标准实践之一。
-
Virtual Threads:
https://docs.oracle.com/en/java/javase/21/core/virtual-threads.html#GUID-DC4306FC-D6C1-4BCC-AECE-48C32C1A8DAA
-
JEP 444: Virtual Threads :
https://openjdk.org/jeps/444#Thread-local-variables
-
Spring Webflux :
https://springdoc.cn/spring-webflux/