包阅导读总结
1. `WASM`、`性能分析`、`插桩方案`、`火焰图`、`调用开销`
2. 本文以 WebAssembly 为例,介绍性能分析方法,包括基于哈希表和树的插桩方案优化,讨论插桩过程、工具、在 LLVM IR 层面插桩的局限,还介绍了将调用开销图转化为火焰图的方法,并通过示例展示效果,最后指出方案存在的不足。
3.
– WASM 性能分析概述
– 结合代码插桩和性能火焰图技术
– 对 WebAssembly 代码性能分析实践
– 性能分析的插桩方案
– 基于哈希表的实现及问题
– 基于树实现的优化及效果
– 采样记录、限制插桩范围等优化
– 插桩过程
– C 代码和 WASM 对照的关键部分
– 具体的插桩步骤
– 插桩工具及核心代码
– 生成火焰图
– 原理和格式
– 核心代码实现
– 示例效果
– 不足
– 插桩后执行效率下降
– 性能分析流程复杂
思维导图: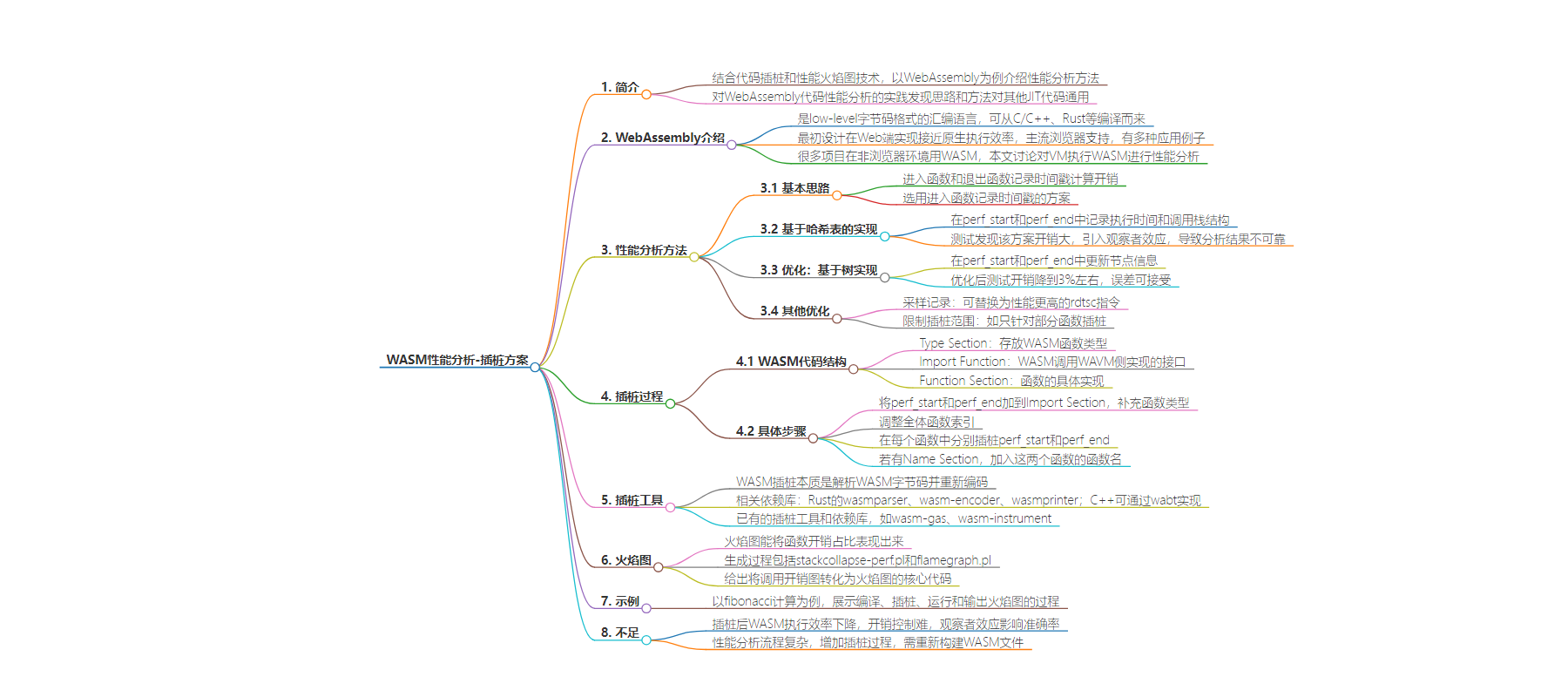
文章地址:https://mp.weixin.qq.com/s/GIIajCyMMzaJpPONLyoGVQ
文章来源:mp.weixin.qq.com
作者:贾缃
发布时间:2024/8/21 13:25
语言:中文
总字数:3294字
预计阅读时间:14分钟
评分:86分
标签:WebAssembly,性能分析,代码插桩,WAVM,火焰图
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

本文结合了代码插桩和性能火焰图的技术,以 WebAssembly 为例介绍了性能分析的方法和相关实现。
最近对 WebAssembly 代码性能分析(Profiling)做了一些实践,发现一些思路和方法对其他即时编译(JIT)代码也是通用的。本文以 WebAssembly 为例介绍一下性能分析的方法。
首先简单介绍一下WebAssembly(下简称 WASM)[1],WASM是一个 low-level 的字节码格式的汇编语言,可以从 C/C++,Rust 等高级语言编译而来,最初设计是在Web端实现接近原生的执行效率(目前主流浏览器都支持了),应用的例子[2]有 Web 版的 Unity,Tensorflow, AutoCAD,Google Earth 等。
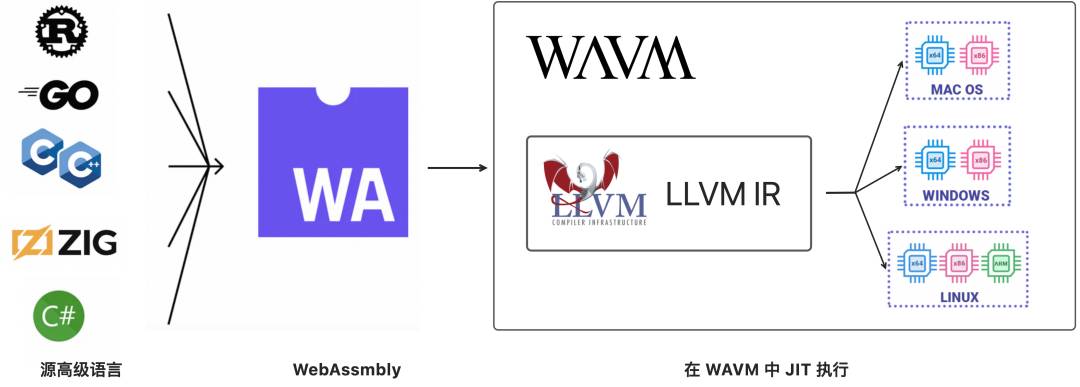
由于 WASM 可移植性好,很多项目也开始在非浏览器环境用 WASM,即通过 VM/Runtime 运行 WASM。本文讨论的就是对 VM 执行 WASM 进行性能分析,WASM 的 VM/Runtime 很多,近年也有一些陆续做了性能分析的支持,因此,我们就选暂无性能分析支持的 WAVM 做尝试。
WAVM 执行 WASM 是采用 JIT 的模式,如下图所示,开发者可以通过不同高级语言编译成 WASM ,然后 WAVM 通过 LLVM 将 WASM 编成 LLVM IR,最后编到不同平台的机器码。
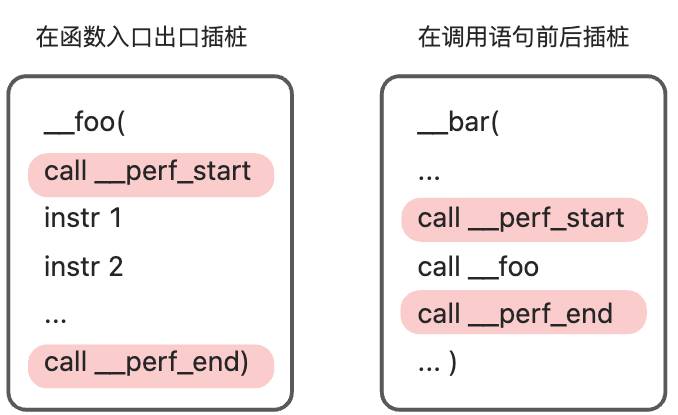
OK 回到我们最初的目的,如何对 WASM 进行性能分析?回归最原始的方法,进入函数先记个时间戳,退出时再记一个,二者相减即可;又或者在函数调用前后记个时间戳,一减就是开销。如下图,两种方案区别不大,为了方便,我们只选用第一种方案。
基于哈希表的实现
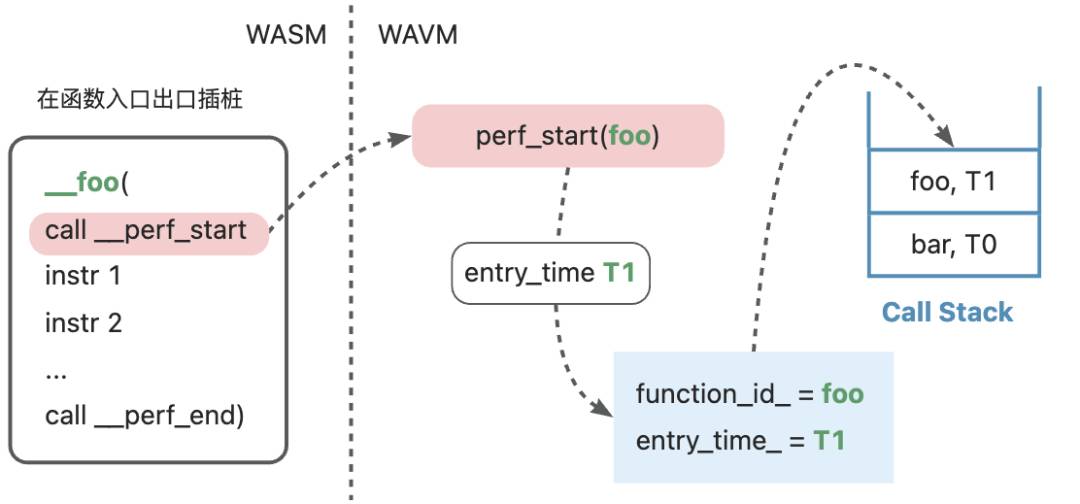
由于同一个函数可能被不同的函数调用,在perf_start和perf_end中不仅需要记录执行时间,也需要记录调用栈结构,对此,最直观的设计是在记录时维护一个调用栈,如下:
在perf_start时将当前函数名和入口时间入栈。
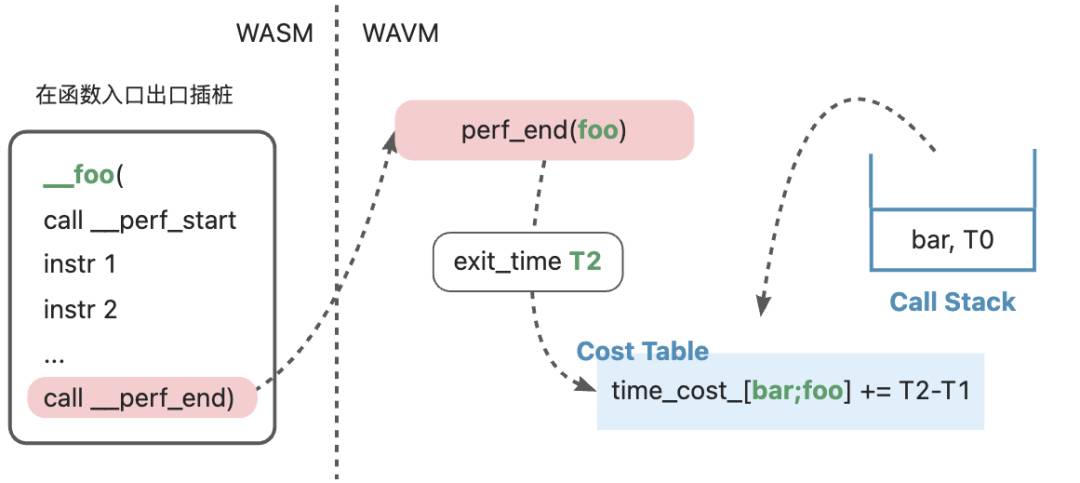
在perf_end时出栈,记录栈顶函数开销。同时对调用栈进行一次遍历,得到栈顶函数的执行路径,将二者存到哈希表中。
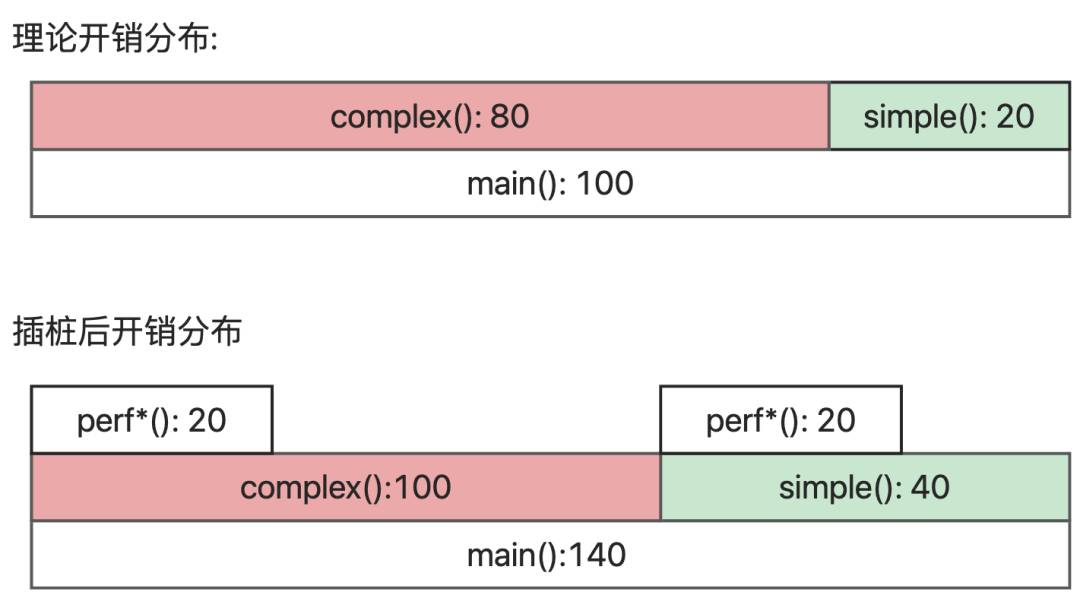
然而,在测试中,我们发现该方案虽然直观,但是在插桩函数中需要对栈进行遍历并进行字符串合并,开销较大。这会引入观察者效应,导致分析结果不可靠,如下图,对于一个程序,complex开销为 80,simple开销为 20,若上述插桩开销为 20,每个函数调用次数相同,则最终观测结果就成了complex100,simple40。
优化:基于树实现
为缩减开销,可以用树来记录调用图,如下:
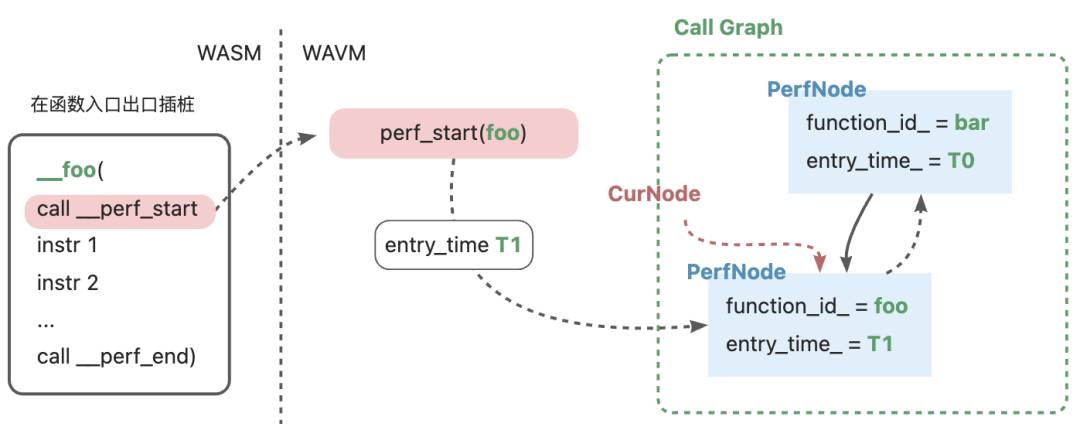
在perf_start时,查询已存在子节点或新建子节点,更新入口时间,全局节点指针转移到子节点。
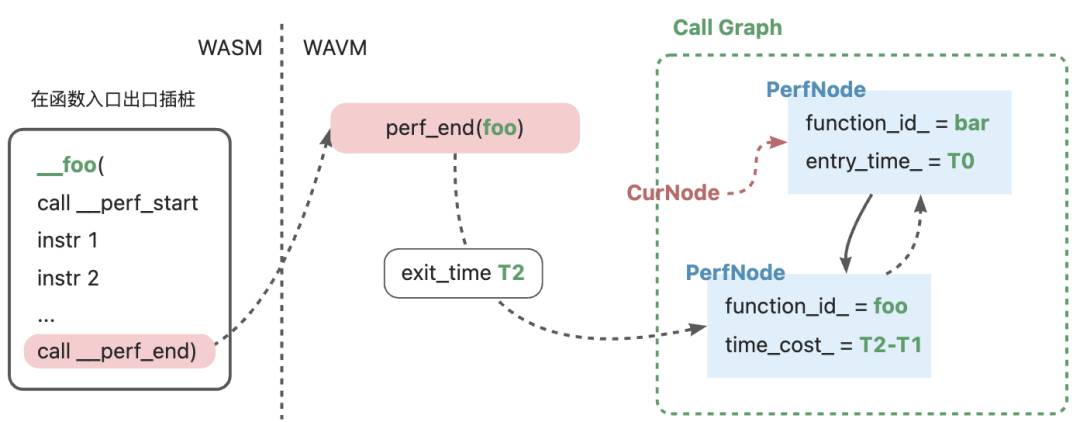
在perf_end时更新函数时间开销,全局节点指针转移到父节点。
如此一来,对于多次调用的函数,插桩函数的时间开销基本缩减到只有取时间。进行一系列优化后,最终我们测试出开销降到了 3% 左右,由此得来的误差是在可以接受范围之内的。
void perf_start(int32_t func_id) {PerfNode* cur_node = perf_data->perf_node();if (!cur_node) {return;}PerfNode* child_node = cur_node->GetChildNode(perf_data->buffer(), func_id);if (!child_node){perf_data->UpdatePerfNode(NULL);return;}child_node->RecordEntry();perf_data->UpdatePerfNode(child_node);}void perf_end() {PerfNode* cur_node = perf_data->perf_node();if (!cur_node) {return;}cur_node->RecordExit();perf_data->UpdatePerfNode(cur_node->parent());}2、采样记录:除了采用常规的时间函数,可以替换为性能更高rdtsc指令直接从寄存器中获取。附常用计时工具性能对比[3]。 3、限制插桩范围:如只针对一些函数进行插桩,而忽略开销极小的函数,如提供一个插桩清单,只对清单函数插桩。
插桩过程
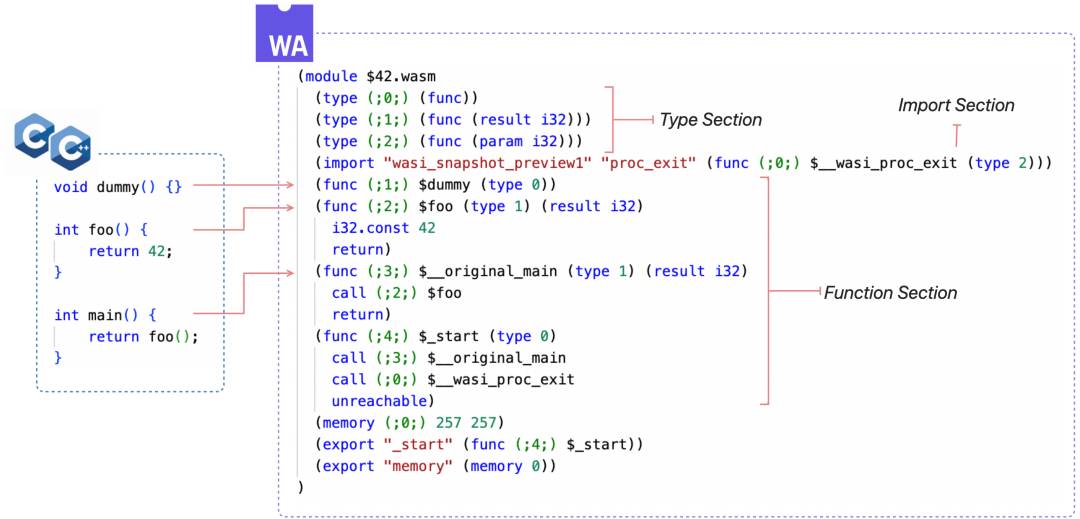
下面是一份 C 代码和文本格式的 WASM 对照,右侧我们需要关心三个部分:
Type Section:存放所有 WASM 的函数(包括 import 的函数)的类型。 Import Function:即 WASM 调用 WAVM 侧实现的接口。 Funtion Section:函数的具体实现。
具体的插桩过程包括以下四步。
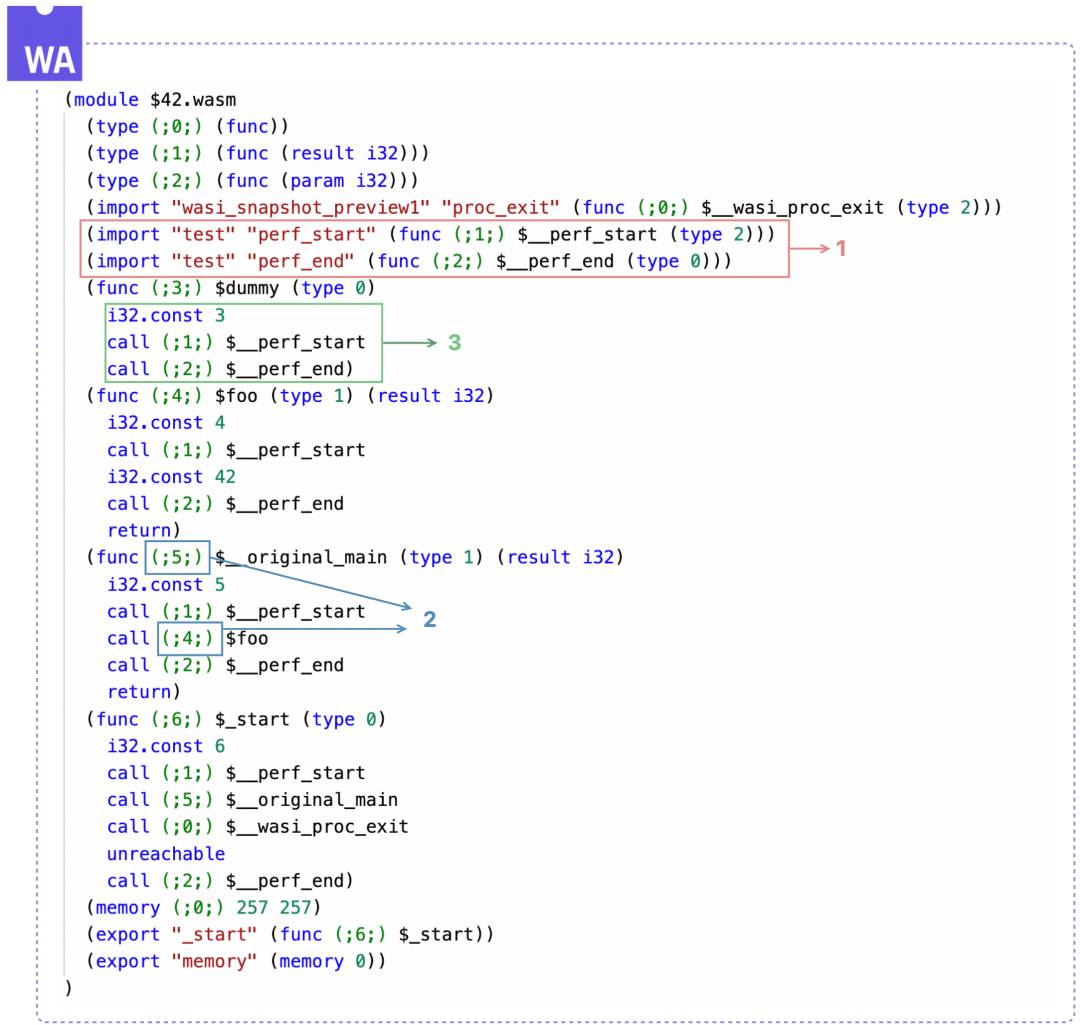
1、先把我们上面的perf_start和perf_end加到 Import Section,至于函数类型,基于上述插桩函数设计,perf_start需要当前函数的索引 ID(i32),而perf_end不需要参数,二者均没有返回值。若 Type Section 没有这两个函数类型,还需要补充上去。 2、由于 WASM 函数调用通过函数索引表示,因此添加 Import 函数后,全体函数的索引也需要跟随调整,包括每个函数定义前的索引和call指令的目标函数。 3、在每个函数中分别插桩:
perf_start和perf_end。perf_start需要当前函数索引作为参数,因此需要事先进行压栈,而perf_end需要插桩在所有return指令的前面或函数末尾。 4、若 WASM 包含 Name Section ,则还需要在 Name Section 中加入这两个函数的函数名。
插桩完成后对应的 WASM (文本格式)如下:
插桩工具
WASM 插桩本质上就是解析 WASM 字节码,然后重新编码。相关依赖库包括 Rust 的 wasmparser, wasm-encoder, wasmprinter。C++ 则可以通过wabt[4]实现。当前已经有一些对 WASM 进行插桩的工具和依赖库,比如 Ewasm 的wasm-gas[5],paritytech/wasm-instrument[6]等。我这里就是修改 wasm-instrument 做的插桩。
下面是 WASM 插桩的核心代码,包含上述 2、3 步,其他 WASM Section 的修改不在此赘述。
func_builder.instruction(&Instruction::I32Const((current_func_index+2) as i32));func_builder.instruction(&Instruction::Call(perf_start));let mut block_depth = 0;for op in operator_reader {let op = op?;match op {Operator::Call { function_index } => {handle_in_function_call(&mut func_builder, entry_func_index, exit_func_index, function_index)?;},Operator::Return => {func_builder.instruction(&Instruction::Call(exit_func_index));func_builder.instruction(&Instruction::Return);},Operator::Block { .. } | Operator::Loop { .. } | Operator::If { .. } | Operator::Try { .. } => {block_depth += 1;func_builder.instruction(&DefaultTranslator.translate_op(&op)?);},Operator::End => {if block_depth == 0 {func_builder.instruction(&Instruction::Call(exit_func_index));}func_builder.instruction(&DefaultTranslator.translate_op(&op)?);block_depth -= 1;},_ =>{func_builder.instruction(&DefaultTranslator.translate_op(&op)?);},}}code_section_builder.function(&func_builder);前面提到 WAVM 是 JIT 执行 WASM 的,后端采用的是 LLVM ,即先将 WASM 编译为 LLVM IR,然后从 IR 到各个平台的机器码。除了在 WASM 层面进行插桩,还可以在 LLVM IR 层面插桩。插桩原理与上面几乎相同,但不同 VM 对后端的实现不同,这样修改不仅工作量和复杂度更大,还难以移植,因此不作推荐。
火焰图是对性能分析做可视化的一个很好用的脚本,能将函数开销占比表现出来。其过程一般包括:
$FG_DIR/stackcollapse-perf.pl perf.unfold > perf.folded
$FG_DIR/flamegraph.pl perf.folded > perf.svg 我们现在已经通过插桩获得了调用开销图,如何将这个调用开销图转化为火焰图?我们分别看了 perf.unfold 和 perf.folded 的格式。
perf.unfold 包含 perf 工具每次采样的调用栈和采样周期,文件较大。
perf.folded 对上述采样进行统计,输出文件简单。
显然,perf.folded 更简单,而且调用栈不就是到叶节点的路径嘛,可以直接通过深度优先遍历调用树输出。下面是核心代码:
std::string call_stack = "wavm";while (!node_stack.empty()) {PerfNode* cur_node = node_stack.top();if (!cur_node->visited_) {uint64_t cur_cost = cur_node->time_cost_;for (size_t i = 0; i < cur_node->children_size_; i++) {node_stack.push(cur_node->children_[i]);cur_cost -= cur_node->children_[i]->time_cost_;}call_stack.append(";");call_stack.append(wasm_func_names.functions[cur_node->func_id_].name);call_length_stack.push(call_stack.size());fprintf(fp, "%s %ld\n", call_stack.c_str(), cur_cost);cur_node->visited_ = true;visited_node.push_back(cur_node);}else {node_stack.pop();call_length_stack.pop();call_stack.resize(call_length_stack.top());}}进行上述实现后,只需要打包一个PerfOutput接口,就可以在 WASM 执行完毕后输出火焰图所需的 .folded 文件了。
OK 接下来写个 Sample,一个简单的 fibonacci 计算。
#include <stdio.h>#include <stdlib.h>int fibonacci(int n) {if (n <= 0)return 0;if (n == 1)return 1;return fibonacci(n - 1) + fibonacci(n - 2);}int main(int argc, char **argv) {int n = atoi(argv[1]);printf("fibonacci(%d)=%d\n", n, fibonacci(n));return 0;}然后通过下面的命令编译成 WASM ,并从字节码格式转为可读的文本格式(WAT)。
# emcc 来自 Emscripten SDK ,是 WASM 的编译器# -O0 禁用优化,保持源码结构 -g 禁用优化,在 WASM 中加入 debug 信息emcc -O0 -g fib.c -o fib.wasm# wasm2wat 来自 WebAssembly Binary Toolkitwasm2wat fib.wasm > fib.watfib.wat 里可以找到 fibonacci函数: (func $fibonacci (type 3) (param i32) (result i32)(local i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32)global.get $__stack_pointer...global.set $__stack_pointerlocal.get 25return)其中, (func 表示这个括号内是一个函数,后面是函数签名和局部变量,第 3 行开始是函数内容,一直到最后 return 都是函数内容。
wasm-instrument instrument fib.wasm -o fib_i.wasmwasm2wat fib_i.wasm > fib_i.watfib_i.wat 内容,如下,可见插桩已经完成。
(func $fibonacci (type 3) (param i32) (result i32)(local i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32 i32)i32.const 7call $perf_startglobal.get $__stack_pointer...global.set $__stack_pointerlocal.get 25call $perf_endreturn)运行和输出。
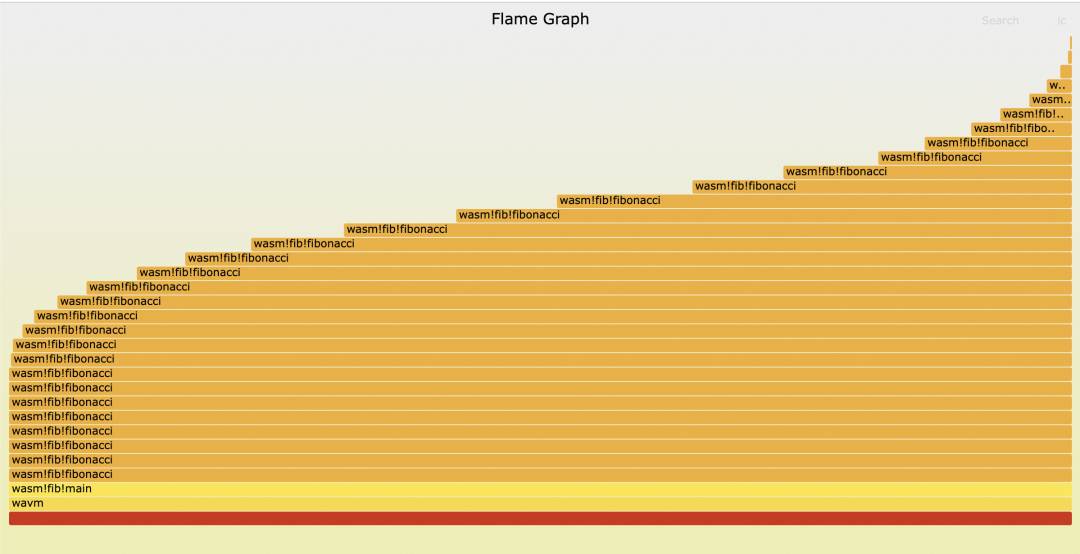
# 运行,产生 fib.foldedwavm run -o fib.folded fib.wasm 40# 转为火焰图$FG_DIR/flamegraph.pl fib.folded > fib.svg
从中可以清楚看到 fib_i.wasm 的调用流程和开销占比,达到了性能分析的目的。
总的来说,通过插桩计时对 WASM 进行性能分析是可行的,但是也存在一些不足:
插桩后 WASM 执行效率下降,上面我们通过缩小插桩范围等方式才将开销控制到 3%,若需要观测到每个小函数,开销就会超出预期,而开销一旦超出预期,观察者效应就导致准确率下降了,这是最大的痛点。 性能分析流程复杂,直观来说,增加了一个插桩的过程,对 WASM 文件需要重新构建,加大了实际分析的复杂性。
参考链接:
[1]https://webassembly.org/ [2]https://madewithwebassembly.com/ [3]https://zsummer.github.io/2021/02/19/2021-04-02-perf-clock/ [4]https://github.com/WebAssembly/wabt [5]https://github.com/ewasm/sentinel-rs [6]https://github.com/paritytech/wasm-instrument
本方案介绍如何使用向量检索服务(DashVector)结合通义千问大模型来打造基于垂直领域专属知识的问答服务。解决大模型本身在处理特定领域的知识表示和应用时的局限性,为企业提供部署简单、便于集成、实时高效、专业稳定的应用服务。
点击阅读原文查看详情。