
包阅导读总结
1. 关键词:容器构建、Dockerfile、优化流程、构建速度、性能提升
2. 总结:
本文探讨了改善容器构建过程的方法,包括正确安排 Dockerfile 步骤顺序、使用多阶段构建以及利用特定工具只重写特定层,强调这些优化对构建速度和性能的重要性,尤其在大规模和生产环境中。
3. 主要内容:
– 容器构建的重要性
– Kubernetes 十周年,容器图像是现代基础设施核心,其构建时间增加。
– 改善容器构建过程的方法
– 步骤排序
– 正确排序可利用 Docker 缓存机制,加快构建速度,如 Python 应用示例。
– 使用多阶段
– 多阶段构建可优化流程,分离构建和运行环境,减小镜像大小,如 Java 应用示例。
– 仅重写特定层
– 利用 pack CLI 工具的重写特性,快速更新 OS 层,适用于紧急应用 OS 安全补丁。
– 结论
– 开发时构建速度对开发管道重要,小的改进在大规模时意义重大,可提升性能、降低成本和加快更新。
思维导图: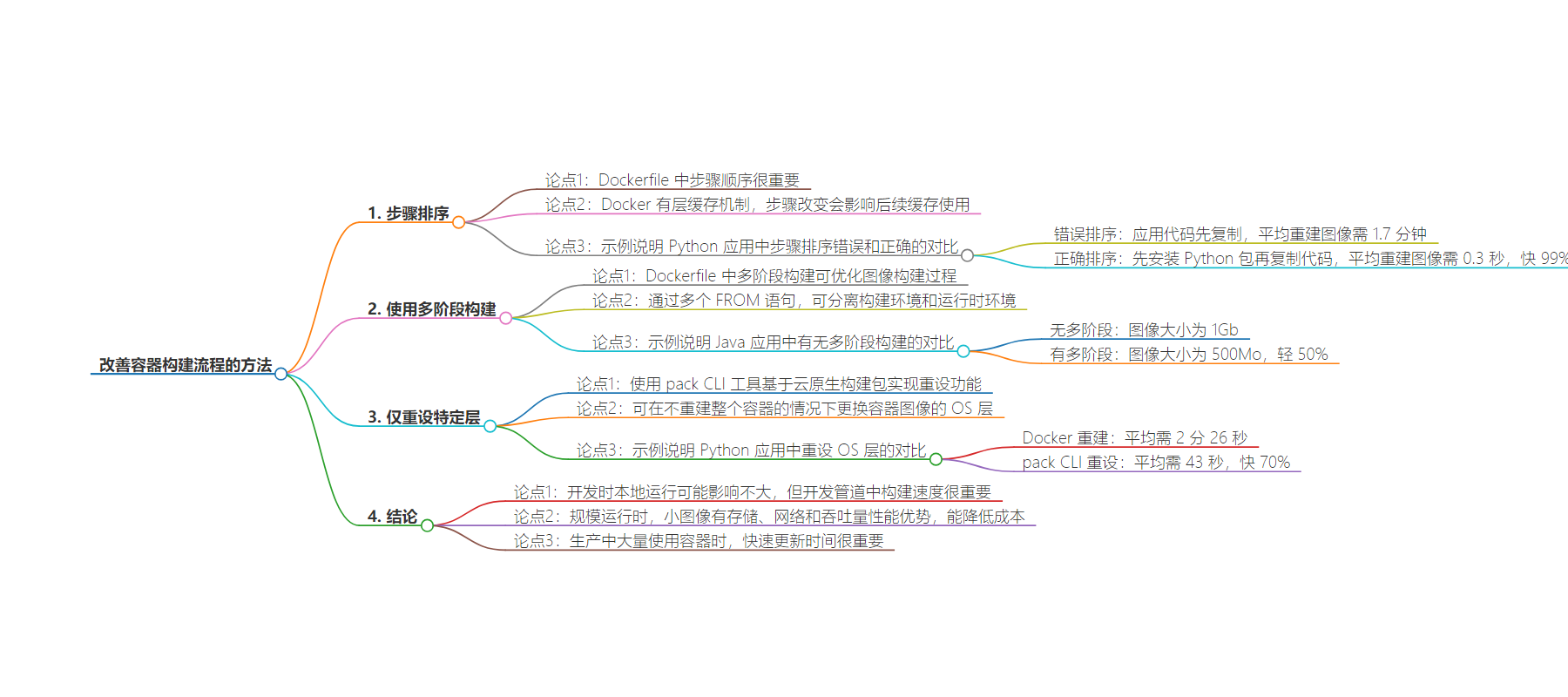
文章地址:https://thenewstack.io/3-ways-to-improve-your-container-build-process/
文章来源:thenewstack.io
作者:Sylvain Kalache
发布时间:2024/7/24 15:40
语言:英文
总字数:1232字
预计阅读时间:5分钟
评分:88分
标签:容器化,Dockerfile 优化,构建效率,多阶段构建,Pack CLI
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
As Kubernetes recently celebrated its 10-year anniversary, container images are at the heart of modern-day infrastructure. These container images tend to become more complicated and heavy; a report found that responded reporting that build time had increased by 15.9% between 2020 and 2021.
In this article, I will explore the gains that can come from managing containers well, which will allow us to build lighter images, faster. Two of these tips will be specific to Dockerfile, while the last one uses Pack, which is a CLI tool that supports the use of buildpacks.
Step Ordering
The order of the steps matters when writing a Dockerfile. Docker has a built-in caching mechanism — called layer caching — that caches each step in your file when you build a container image. So, the next time you build an image from the same Dockerfile, it will reuse the cached layers.
However, as soon as a step changes and the cache cannot be used — for example, because the application code has changed — all the following steps will also need to be run again.
Let’s take a look at a section of a Python app Dockerfile. Here, we start with an Ubuntu base image, copy the application code, and then install system packages.
|
FROM ubuntu:22.04
# Copy the current directory contents into the container at /app COPY . /app
# Install Python and pip RUN apt–get update && apt–get install –y python3–pip python3–dev |
The issue with this ordering is that every time the application code changes, Docker cannot use its cache for the package installation part and will need to download and install the packages again. What should take less than a second might end up taking minutes.
Therefore the right ordering here would be to flip the instructions simply:
|
FROM ubuntu:22.04
# Install Python and pip RUN apt–get update && apt–get install –y python3–pip python3–dev
# Copy the current directory contents into the container at /app COPY . /app |
I ran an example on a modest server with 16G of memory and 4 vCores with the following Python application. To mimic the size of enterprise applications, I added numpy, scipy, and pandas as dependencies.
When using the Dockerfile with a wrong ordering — when the application code is copied before Python packages are installed — it took an average of 1.7 minutes to rebuild an image after a code change.
When using the Dockerfile with the correct ordering — when the application code is copied before Python packages are installed — it took an average of 0.3 seconds to rebuild an image after a code change, which is 99% faster.
So don’t forget the rule of thumb for Dockerfile, place what is unlikely to change at the top of your Dockerfile and what is more likely to change at the bottom.
Use Multistages
Multistage builds in Dockerfiles optimize the process of building images by allowing multiple FROM statements in the same Dockerfile. This feature helps create smaller, more efficient Docker images. For example, it can be used to separate the build environment from the runtime environment.
Again, I ran an example to see what improvements we could expect. This time, we use a sample Java application with Spring, Spark, and Kafka as dependencies.
Here is the Dockerfile using multistage:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Multi-Stage Dockerfile
## Stage 1: Build Stage FROM maven:3.8.1–openjdk–16 AS build
# Set working directory WORKDIR /app
# Copy the application source code and pom.xml COPY pom.xml . COPY src ./src
# Build the application RUN mvn clean package
## Stage 2: Runtime Stage FROM openjdk:16–jdk–slim
# Set working directory WORKDIR /app |
As you can see, I have two FROM statements, one that I use to build my jar, and the second one that I use to build my images.
When using the Dockerfile without multistage — when compilation and container installation are part of the same stage — the image size ended up being 1Gb.
When using the Dockerfile with multistage — when compilation and container installation are part of the same stage — the image size ended up being 500Mo or 50% lighter. Depending on how many container instances need to load this image, this can provide a massive deployment time gain, and this is especially true if you have a geographically distributed infrastructure.
Only Rebase a Specific Layer
This last tip is less well-known than the other two tips we discussed. Here we will use an additional tool — the pack CLI — which is based on the cloud native buildpacks implementation.
Thanks to the way images are generated with Buildpack, the rebase feature allows you to swap out the OS layers (run image) of a container image with a newer version of the run image without re-building the entire container.
To rebase an image, the command is the following:
|
pack rebase name–of–container–image |
Here, again, I ran an experiment using a simple Python application, Dockerfile. When rebuilding a new container image using docker build, I went from Ubuntu 22.04 to the latest, which at the time of writing is 24.04. Rebuilding the image with the latest OS version took, on average, two minutes and 26 seconds.
When using the pack CLI rebase feature, rebuilding the container image with the latest OS version took, on average, 43 seconds, or 70% faster.
This is especially useful when you must urgently apply an OS security patch to your images, which will especially matter for companies with thousands or even hundreds of thousands of images to patch.
Conclusion
All these may not matter when running things locally as a developer; however, build speeds matter when working with development pipelines. What might seem trivial gains when small will matter at scale. When you work in an engineering organization with many pipelines — especially with the proliferation of microservices — build and rebuild speeds will be essential to maintaining high shipping velocity. It could mean shifting dev cycles to happen in minutes instead of hours.
Smaller images will offer storage, network, and throughput performance gains and reduce cost when operating at scale.
Finally, faster update times matter when organizations are using a large amount of containers in production. The ability to replace an image layer on a central registry and have all the running images update individual layers is a handy protocol, especially when the alternative is to individually build and redeploy images.
VIDEO
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.