
包阅导读总结
1. 关键词:RLHF、性能优化、大语言模型、搜索领域、训练效率
2. 总结:本文介绍了RLHF在大语言模型中的应用,指出其能提升搜索结果质量,但训练效率受限。以PPO为例探讨其性能优化,包括文本生成速度、动态显存、系统并行等优化手段,经优化后系统性能大幅提升。
3. 主要内容:
– RLHF的背景与问题:
– OpenAI提出RLHF,将人类偏好引入大模型对齐。
– 作者在搜索领域应用,发现能提升搜索结果但训练效率低,公开优化资料少。
– 优化手段与案例:
– 以PPO为例,包括文本生成速度优化(引入TRT-LLM)、动态显存优化(重算技术、序列并行、按micro_batch padding)、系统并行优化。
– 详细介绍了参数更新、显存优化等方案及效果。
– 实验与效果:
– 实验设置为全参数RLHF训练,采用16A100(80G)训练。
– 优化后性能大幅提升,支持业务快速迭代和发展,效果良好。
思维导图: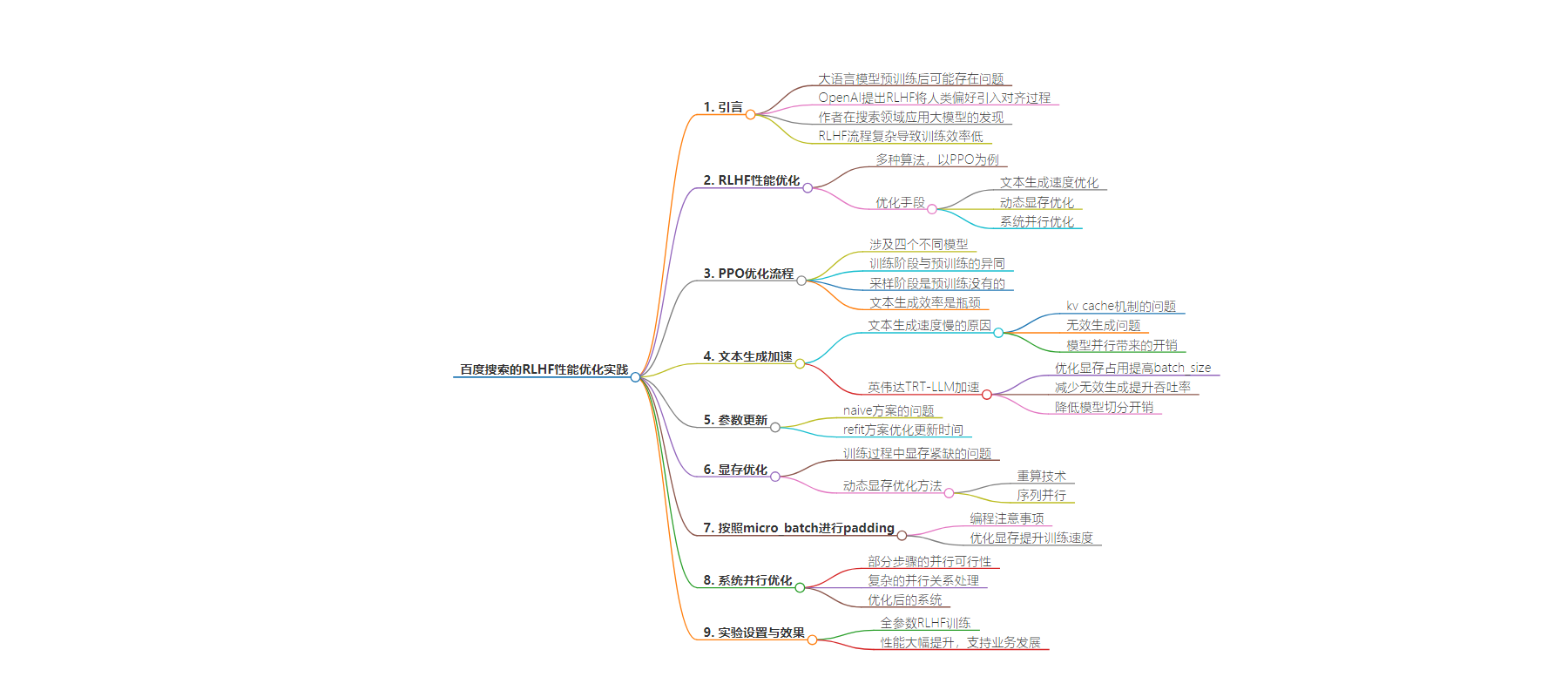
文章地址:https://mp.weixin.qq.com/s/XTU-kRZKOEAn71QwCFpSzQ
文章来源:mp.weixin.qq.com
作者:欢迎关注的
发布时间:2024/8/26 1:59
语言:中文
总字数:7085字
预计阅读时间:29分钟
评分:87分
标签:RLHF,性能优化,大模型,搜索质量,人类反馈
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

全文6565字,预计阅读时间17分钟。
PPO的训练阶段同预训练几乎一样,都是先前向计算损失函数,而后进行反向传播。唯一不同的是PPO训练涉及两个模型。PPO的采样阶段是预训练没有的,采样阶段只有纯粹的前向推理计算,包括文本生成和奖励计算等。由于逐token生成的特性,文本生成的效率一直是业界关注的焦点,在PPO流程中更是超过训练时间而成为整个系统的瓶颈。
为简化讨论,本文以下表中所列的软硬件配置为基准进行讨论。但是本文所提到的优化手段并不受限于下述条件。
|
模型大小 |
||||
|
prompt_length |
generate_length |
generate_batch_size |
global_batch_size |
micro_batch_size |
ppo_iter |
|
1K左右 |
200左右 |
32 |
256 |
2 |
2 |
其中:
-
prompt_length是prompt数据集的最大长度,prompt的长度分布应该较为均匀,其平均长度也应该接近这个值; -
generate_lenght是生成文本的最大长度,当生成超过这个阈值时文本会被截断; -
generate_batch_size是生成文本时的batch_size,这个值越大则GPU利用率越高,但同时会带来更高的显存占用; -
global_batch_size和micro_batch_size最初由梯度累积概念引入,详情可在网上搜索,这里需要重点说明的是,micro_batch_size是决定系统吞吐率以及显存占用最关键的参数,global_batch_size理论上同系统吞吐率以及显存占用关系不大,也就是说可以无限制的扩大。但如果处理不好,梯度聚合过程也可能导致大量的显存消耗,从而导致global_batch_size无法连续调节,后面会有一个案例具体说明; -
ppo_iter指的是ppo算法每轮在全量采样数据上迭代几次。
这种分配方式的好处如下:
|
采样 |
训练 |
||||||
|
文本生成 |
数据集构造 |
actor训练 |
critic训练 |
||||
|
reward计算 |
value计算 |
log_probs计算 |
ref_log_probs计算 |
||||
|
1000s |
45s |
45s |
20s |
10s |
64s |
64s |
|
系统各关键部分全部为串行执行,一次ppo迭代的耗时为:
|
采样时间 |
训练时间 |
总耗时时间 |
|
1000s + (45s + 45s + 20s + 10s) = 1120s |
(64s + 64s) * 2 = 256s(乘2是由于配置了ppo_iter=2) |
1120s + 256s = 1376s |
可以计算得到系统吞吐率为 256 sample / 1376 s / 16 gpu = 0.012 sample / gpu / s。
文本生成大约占了百分之八十左右的耗时,根据阿姆达尔定律:
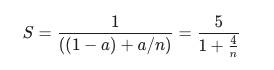
1. 为避免重复计算,文本生成接口均采用kv cache机制,这种机制将文本生成切分成两个阶段,既context阶段和decode阶段。其中context阶段就是对prompt计算kv,因此该阶段也被称作prefill阶段。decode阶段则是逐token生成的过程,由于kv cache大大减少了计算量,该阶段变成访存密集型任务,GPU计算单元的利用率较低。且kv-cache需要额外消耗大量的显存,限制了batch_size的大小,这又进一步降低了GPU计算单元的利用率;
-
对于问题1,TRT-LLM通过引入paged attention机制优化显存占用,从而提高batch_size,改善吞吐率; -
对于问题2,TRT-LLM通过引入inflight batching机制替换已完成的生成任务,大大减少了无效生成,对于序列长度分布极不均匀的场景,甚至观察到了5倍左右的吞吐率提升; -
对于问题3,部署TRT-LLM可以无需遵照训练时的模型切分方式,因此也可以降低模型切分带来的开销。
很显然,TRT-LLM也需要消耗显卡的计算和存储资源,不过由于文本生成和训练在时间上是错开的,可以通过offload的方式错峰使用显存,使得训练和文本生成在显卡使用上互不影响。
3.3.2参数更新
3.3.2.1 naive方案
1.actor保存checkpoint到磁盘(训练框架所支持的格式);
2.再t转换为HuggingFace格式的checkpoint;
3.将HuggingFace格式的checkpoint转换成trtllm格式的checkpoint;
4.将TRT-LLM格式的checkpoint转换为TensorRT engine;
5.TRT-LLM Runtime从磁盘中加载TensorRT engine。
3.3.2.2 refit方案
TRT engine需开启refit选项(开启方法可参考TRT-LLM文档,此选项会导致dump的TensorRT engine大10M左右,但不会影响性能)
1.(训练进程)将Actor模型的参数转换成TensorRT engine的参数格式,并拷贝到共享内存中(逐Tensor转换和拷贝,主要涉及到一些Tensor的拆分、合并以及转置操作等);
2.(训练进程)将Actor模型的参数和优化器状态等固定显存占用unload到cpu内存中(为TRT-LLM推理腾退显存,可unload部分参数),通知(RPC方式)TRTLLM进程加载最新参数;
3.(TRT-LLM进程)加载cpu内存中保存的TensorRT engine;
4.(TRT-LLM进程)遍历共享内存中的参数并改写TensorRT engine (逐Tensor改写)
相比于共享内存,显卡间的NCCL通讯速度极快,参数拷贝时间几乎可以忽略不计。
1. 系统关键部分耗时
|
采样 |
训练 |
||||||
|
文本生成 |
优势计算 |
actor训练 |
critic训练 |
||||
|
参数更新 |
文本生成 |
reward计算 |
value计算 |
log_probs计算 |
ref_log_probs计算 |
||
|
20s |
60s |
45s |
45s |
20s |
10s |
64s |
64s |
2. 吞吐率计算
系统各关键部分全部为串行执行,一次ppo迭代的耗时时间为:
|
采样时间 |
训练时间 |
总耗时时间 |
|
20s + 60s + (45s + 45s + 20s + 10s) = 200s |
(64s + 64s) * 2 = 256s(乘2是由于配置了ppo_iter=2) |
200s + 256s = 456s |
RLHF训练过程中显存常常是紧缺资源,显存会造成两个问题,一是训练过程中突然出现的OOM警告,使得跑了很长时间的任务失败;二是为了避免OOM刻意调小batch_size,使得显卡计算单元的利用率下降,训练时间延长。大模型训练过程中的显存占用分为固定显存占用以及动态显存占用。固定显存主要包括参数、梯度和优化器状态,对于类Megatron-LM框架来说,固定显存通过模型并行切分之后,继续优化的空间较小,因此需要开发人员关注的是动态显存优化。动态显存主要包括前向的激活以及临时变量等,下面将介绍这两种显存的优化方法。另外对于推理框架来说,激活和临时变量相比kv cache几乎可以忽略不计,而通过引入paged attention技术,kv cache显存占用已经得到了很好的优化,因此这里不多做讨论。
另一种激活显存优化技术是序列并行,这个技术由Megatron-LM引入,其核心思想仍然是使用通讯换取显存。具体而言,Megatron-LM的作者观察到那些TP无法切分的区域,在序列轴的维度上是相互独立的,因此可以在序列轴上进行切分,如下图所示:
实验中观察到,在PP=8的条件下,使用序列并行+选择性重算能够优化掉50%左右的激活显存,但是会带来20%左右的速度退化。可以将batch_size提升至原先的两倍,最终的训练速度相比之前提升接近15%。同时对于更长的文本,预期会有更大的改进。
4.2按照micro_batch进行padding
通过提前计算mbs,尽早释放中间显存,可以将峰值显存从gbs * N优化到mbs * N。
对mbs的计算中也申请了一块2GB左右的显存,通过将计算的粒度控制在单条样本,还可以进一步降低峰值显存占用,代价是计算效率会有所降低,这点需要权衡。
由于优化了显存,系统可以使用更大的global_batch_size,降低了流水并行的空泡率(如果开PP的话),从而提高了训练速度。按照micro_batch进行padding由于节省了计算,又进一步提升了训练速度。总的提升大约在10%左右。
|
采样 |
训练 |
||||||
|
文本生成 |
优势计算 |
actor训练 |
critic训练 |
||||
|
参数更新 |
文本生成 |
reward计算 |
value计算 |
log_probs计算 |
ref_log_probs计算 |
||
|
20s |
60s |
45s |
45s |
20s |
10s |
58s |
58s |
2.吞吐率计算
|
采样时间 |
训练时间 |
总耗时时间 |
|
20s + 60s + (45s + 45s + 20s + 10s) = 200s |
(58s + 58s) * 2 = 232s(乘2是由于配置了ppo_iter=2) |
200s + 232s = 432s |
可以计算得到系统吞吐率为 256 sample / 432 s / 16 gpu = 0.037 sample / gpu / s,相较于基线吞吐率提升了将近208%。
PPO是一个典型的多阶段流程,所包含的步骤中有些有前后依赖关系,需要串行执行,也有一些步骤则没有依赖关系,可以并行执行,如下图所示:
Actor的训练和Critic的训练任务在不同节点并且相互独立时,可以很容易进行并行计算。ref_logp和logp的计算任务虽然相互独立,但由于在同一节点需要共享显卡,且单个任务既可打满利用率,此时任务并行的意义不大(虽然cuda通过stream机制很容易支持并发任务)。观察到对于ref_logp计算这种仅做推理的任务,将其移动到critic所在的节点也几乎没有影响,之后便可以进行并行计算ref_logp和logp。比较复杂的是文本生成与reward计算之间的并行,两者虽分布在不同的节点,但是任务之间存在依赖关系,即reward计算所需要的句子是文本生成的结果。观察到文本生成按照batch计算并返回,可以通过下述方法重叠两者的计算。
优化后的系统如下所示:
系统中还存在其他一些可以并行的部分,例如actor模型的加载/卸载,共享内存拷贝和TRT-LLM模型的卸载/加载与refit_engine等,其优化方法与上述提到的思想大同小异,这里不再详细介绍。
|
采样 |
训练 |
||||||
|
文本生成/reward/value计算 |
log_probs/ref_log_probs计算 |
actor/critic训练 |
|||||
|
参数更新 |
文本生成 |
reward计算 |
value计算 |
log_probs计算 |
ref_log_probs计算 |
||
|
20s |
60s |
45s |
45s |
20s |
10s |
58s |
58s |
|
总时间 |
总时间 |
总时间 |
|||||
|
130s |
25s |
70s |
|||||
2.吞吐率计算
|
采样时间 |
训练时间 |
总耗时时间 |
|
130s+25s=155s |
70s * 2 = 140s(乘2是由于配置了ppo_iter=2) |
155s + 140s = 295s |
实验设置:
全参数RLHF训练,采用16*A100(80G)训练。
综上,我们在广泛实验、对比和学习了业界主流框架的情况下,通过分析RLHF任务的特点并采用先进的大模型预训练及推理性能优化手段,使得RLHF任务性能大幅提升,能够以相对少的资源支持了业务的快速迭代和发展,取得了良好的业务效果。