
包阅导读总结
1.
– 向量数据库
– 语义聚类
– 隐藏知识
– 数据挖掘
– 组织改进
2.
本文介绍了向量数据库中的语义聚类技术,阐述其在挖掘隐藏知识、优化数据处理等方面的作用,并强调其能促进组织改进和决策优化。
3.
– 向量数据库的重要性
– 对生成式 AI 应用的关键作用
– 福雷斯特预测 2024 年其采用率大幅增加
– 语义向量聚类挖掘隐藏知识
– 传统数据挖掘的挑战
– 语义向量聚类改善数据挖掘的方式
– 语义向量聚类促进组织改进
– 分析文本数据
– 变革知识管理
– 打破数据孤岛
– 语义向量聚类的实现方式
– 发现语义结构
– 基于聚类降低数据复杂性
– 语义自动聚合
– 语义聚类在向量数据库中的价值
– 解锁隐藏关系和模式
– 提取有价值的见解以优化决策等
思维导图: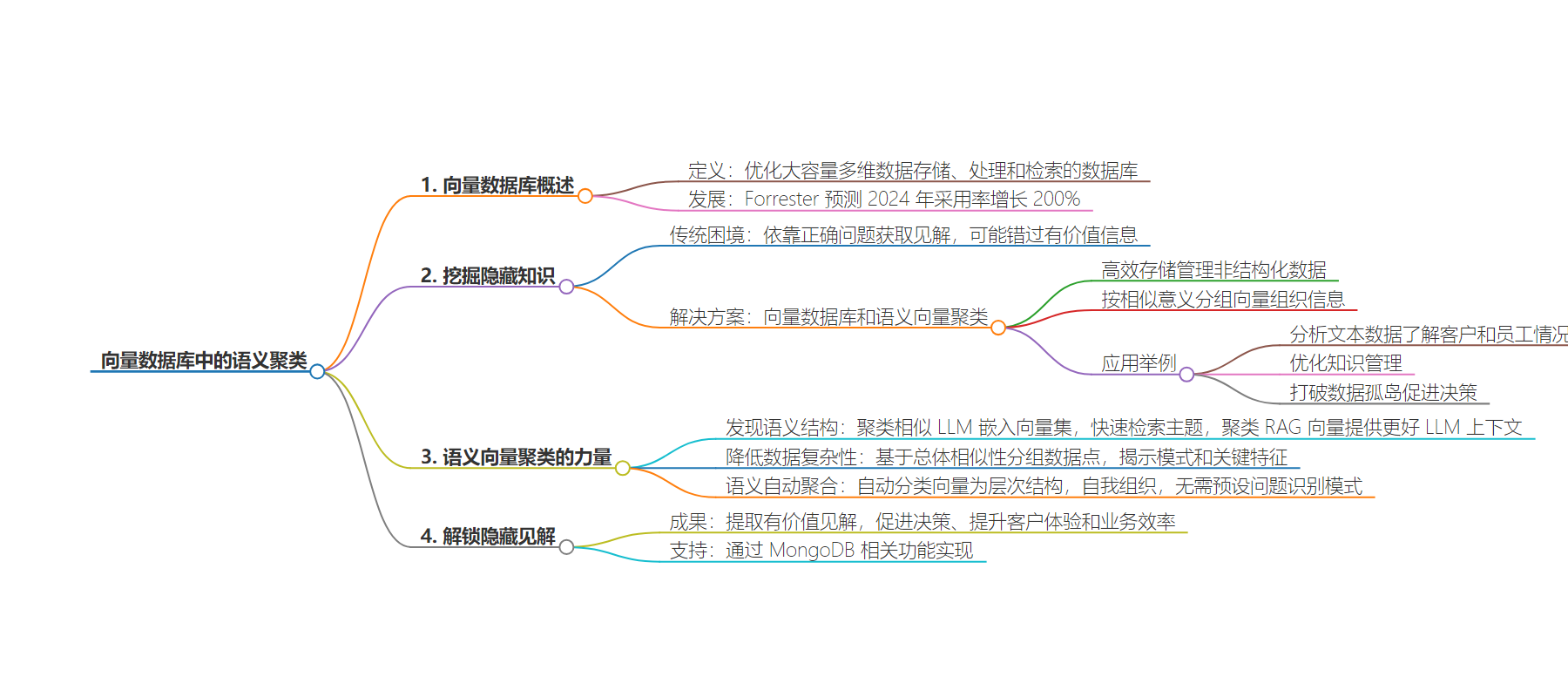
文章地址:https://www.mongodb.com/blog/post/find-hidden-insights-vector-databases-semantic-clustering
文章来源:mongodb.com
作者:Mai Nguyen
发布时间:2024/8/19 13:21
语言:英文
总字数:703字
预计阅读时间:3分钟
评分:88分
标签:向量数据库,语义聚类,数据挖掘,AI 应用,MongoDB
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Vector databases, a powerful class of databases designed to optimize the storage, processing, and retrieval of large volume, multi-dimensional data, have increasingly been instrumental to generative AI (gen AI) applications, with Forrester predicted a 200% increase in the adoption of vector databases in 2024. But their power extends far beyond these applications. Semantic vector clustering, a technique within vector databases, can unlock hidden knowledge within your organization’s data, democratizing insights across teams.
Mining diverse data for hidden knowledge
Imagine your organization’s data as a library of diverse knowledge—a treasure trove of information waiting to be unearthed. Traditionally, uncovering valuable insights from data often relied on asking the right questions, which can be a challenge for developers, data scientists, and business leaders alike. They might spend vast amounts of time sifting through limited, siloed datasets, potentially missing hidden gems buried within the organization’s vast data troves. Simply put, without knowing the right questions to ask, these valuable insights often remain undiscovered, leading to missed opportunities or losses.
Enter vector databases and semantic vector clustering. A vector database is designed to store and manage unstructured data efficiently. Within a vector database, semantic vector clustering is a technique for organizing information by grouping vectors with similar meaning together. Text analysis, sentiment analysis, knowledge classification, and uncovering semantic connections between data sets—these are just a few examples of how semantic vector clustering empowers organizations to vastly improve data mining.
Semantic vector clustering offers a multifaceted approach to organizational improvement. By analyzing text data, it can illuminate customer and employee sentiments, behaviors, and preferences, informing strategic decisions, enhancing customer service, and optimizing employee satisfaction. Furthermore, it revolutionizes knowledge management by categorizing information into easily accessible clusters, thereby boosting collaboration and efficiency. Finally, by bridging data silos and uncovering hidden relationships, semantic vector clustering facilitates informed decision-making and breaks down organizational barriers.
For example, the business can gain significant insights from its customer interaction data which is routinely kept, classified, or summarized. Those data points (texts, numbers, images, videos, etc.) can be vectorized and semantic vector clustering applied to identify the most prominent customer patterns (the densest vector clusters) from those interactions, classifications, or summaries. From the identified patterns, the business can take further actions or make more informed decisions that they wouldn’t have been able to do otherwise.
The power of semantic vector clustering
So, how does semantic vector clustering achieve all this?
-
Discover semantic structures: Clustering groups similar LLM-embedded vector sets together. This allows for fast retrieval of themes. Beyond clustering regular vectors (individual data points or concepts), clustering RAG vectors (summarization of themes and concepts) can provide superior LLM contexts compared to basic semantic search.
-
Reduce data complexity via clustering: Data points are grouped based on overall similarity, effectively reducing the complexity of the data. This reveals patterns and summarizes key features, making it easier to grasp the bigger picture. Imagine organizing the library by theme or genre, making it easier to navigate vast amounts of information.
-
Semantic auto-aggregation: Here is the coolest part. We can classify groups of vectors into hierarchies by effectively semantically “auto-aggregating” them. This means that the data itself “figures out” these groups and “self-organizes.” Imagine a library with an efficient automated catalog system, allowing researchers to find what they need quickly and easily. Vector clustering can be used to create hierarchies, essentially “auto-aggregating” groups of vectors semantically. Think of it as automatically organizing sections of the library based on thematic connections without a set of pre-built questions. This allows you to identify patterns within a vast, semantically-diverse data within your organization.
Unlock hidden insights in your vector database
The semantic clustering of vector embeddings is a powerful tool to go beyond the surface of data and identify meanings that otherwise would not have been discovered. By unlocking hidden relationships and patterns, you can extract valuable insights that drive better decision-making, enhance customer experiences, and improve overall business efficiency—all enabled through MongoDB’ secure, unified, and fully-managed vector database capabilities.