
包阅导读总结
1. 关键词:Supergraph、API 集成、API 聚合、企业数据、架构框架
2. 总结:本文探讨在企业数据/API 复杂环境中面临的问题,介绍了 Supergraph 架构框架,阐述其核心概念,包括解决 API 集成和聚合的挑战,如格式不优、缺乏规范等,并指出 Supergraph 在应对这些挑战中的作用。
3. 主要内容:
– 企业 API 环境复杂,具有多数据域和多应用,协作困难
– Supergraph 架构框架旨在解决常见问题
– 核心概念包括联邦式 API 平台、关键活动和标准化高质量域 API
– 采用域优先方法生成高质量协议无关的 API
– 以企业数据和 API 示例说明情况
– API 集成面临输出格式、类型模式、文档等挑战
– API 聚合存在处理难、所有权模糊等挑战
– Supergraph 解决上述挑战
– 解决 API 集成的格式等问题
– 针对 API 聚合实现自动化,无需操作模型和昂贵协作
思维导图: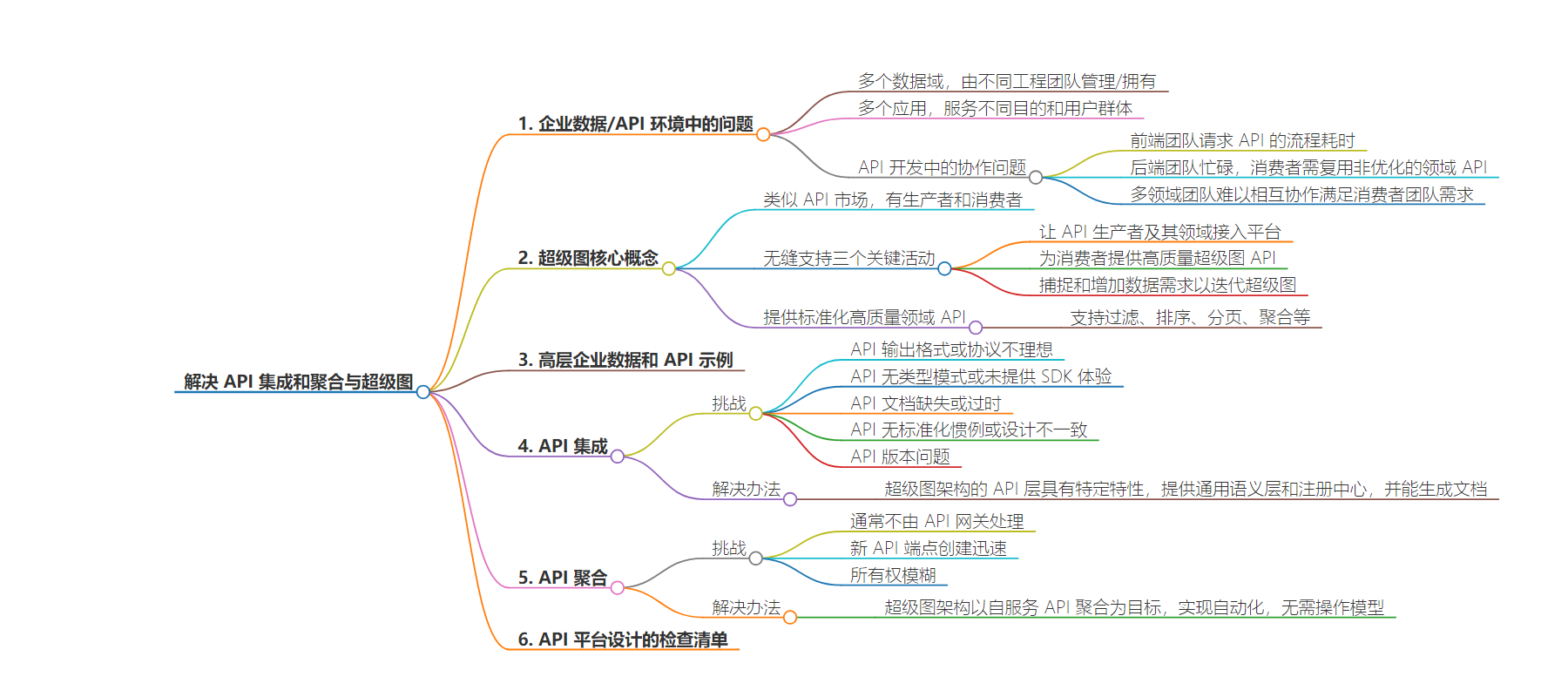
文章地址:https://thenewstack.io/solving-api-integration-and-aggregation-with-supergraph/
文章来源:thenewstack.io
作者:Sandip Devarkonda
发布时间:2024/7/31 13:13
语言:英文
总字数:2017字
预计阅读时间:9分钟
评分:89分
标签:API 集成,API 聚合,超级图架构,GraphQL,企业数据管理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
It’s hard to be in the business of building or consuming APIs in enterprise data/API landscapes. These complex landscapes typically have the following characteristics:
- Multiple data domains, each managed/owned by one engineering team (multiple producers of APIs).
- Multiple applications, each serving a different purpose and/or set of users (multiple consumers of APIs).
APIs are a collaborative affair. Though typically built by full-stack developers or by backend engineers, in multi-stakeholder enterprise-data landscapes with several parallel initiatives, there’s always tension in the system due to constrained bandwidth and conflicting goals. For instance:
- The frontend team requests APIs -> contract is agreed upon -> APIs are built. New data/use cases trigger such cycles, which takes time.
- The domain team builds domain APIs. As the backend team is busy with other efforts, API consumers are expected to reuse a domain’s canonical APIs, even if they are not optimized for consumption.
- It’s hard to get multiple domain teams to collaborate with each other to support the requirements of one or more consumer teams.
Crafting new application experiences in such a complex environment is complicated. The benchmark for new architecture models is their efficacy in handling such an environment and the agility they are able to generate for engineering teams working in complex data domains.
Supergraph is an architecture framework that’s evolved from years of supporting GraphQL federation architectures in enterprise organizations. It aims to address the commonly seen problems in this landscape by positing certain approaches to building domain API (subgraphs) and data-access API platforms (supergraphs). In this series, we will look at the core tenets of this architecture and how it benefits the API integration, aggregation and orchestration use cases. This first article will focus on API integration and aggregation.
Supergraph Core Concepts
The Supergraph architecture framework goes beyond proposing an architecture model by articulating an operating model for teams to collaborate. Here are some of the key tenets of the framework:
- A federated API platform is akin to an API marketplace with two key stakeholders: API producers and API consumers.
- A supergraph must seamlessly enable three key activities to kick off a flywheel of data delivery and consumption:
- Onboard an API producer and its domains to the API platform.
- Provide a high-quality supergraph API for consumers.
- Capture and increase data demand to iterate on the supergraph.
- A standardized high-quality domain API must be provided to enable efficient/effective consumption:
- A domain API must support filtering, sorting, pagination, aggregation, etc., to provide high-quality data interactions.
The Supergraph architecture enables an operating model for federated ownership of domains in an API platform. It uses a domain-first approach (that is source-aware) to generate a compiler-style API on any data domain (databases, REST, gRPC, etc.) to handle any CRUD requirements. This generated API is high-quality and protocol-agnostic — it can be configured to be one or more of REST, GraphQL or gRPC, etc. Here’s a quick example of a GraphQL schema generated on a table in a database:
Note: Notice how this type supports filtering, sorting and pagination.
The supergraph also allows for business logic, like commands from the CQRS (command query responsibility segregation) pattern, to be used in conjunction with domain models and repurposed to any output protocol. For instance, you can write TypeScript functions to implement some business logic and the unified API layer will expose this function as GraphQL or REST. With this, the supergraph is capable of delivering data/actions from/on domain models as well as associated business logic in the consumer protocol of choice with the least effort (that is spent on differentiated business logic and not on undifferentiated CRUD boilerplate).
Let’s focus on supergraph capabilities that allow “composition” over subgraphs as well as the quality of the subgraphs. Before we do this, let’s paint a better picture of this API landscape through an example so that we can subsequently use it as a reference in different use cases.
High-Level Enterprise Data and API Example
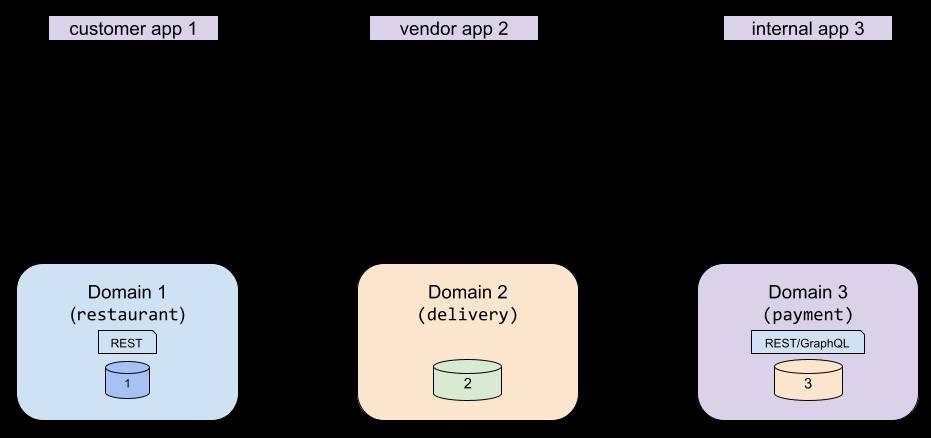
This landscape represents the aforementioned context:
- multiple producers (of data/APIs)
- multiple consumer applications, each of which depends on one or more producers.
In the next few sections, we’ll see how this context makes it challenging for API producers and consumers, and how using the Supergraph architecture, a data delivery layer can help address these challenges.
API Integration
API integration is the process of calling an API to fetch new information (read) or to trigger an action (create/update/delete). From our initial context, think of the diverse needs of each API consumer and how hard it is to integrate with different domains given the heterogeneity of the data/API landscape.
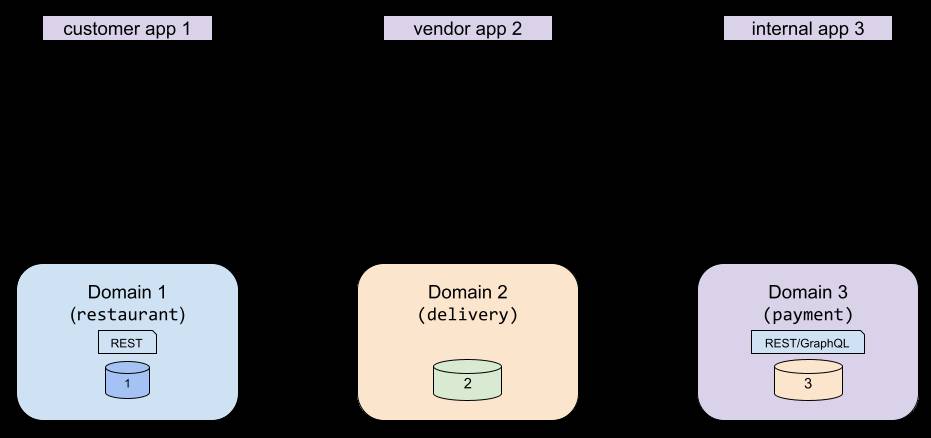
Challenges with API Integration
From the API integration spaghetti above, it’s easy to visualize the following common challenges with API integration:
- The API output format or protocol is not ideal or optimal for a consumer. For instance, gRPC might make sense for service-to-service communication, but might not be best suited for consuming from a React application. This is a problem that’s compounded by different consumers, each of whom can have different requirements. One team might be ready to integrate with a GraphQL API, but another team might not have the bandwidth to learn a new format.
- The API does not have a typed schema and/or does not provide an SDK experience for the API consumer. For instance, typical REST APIs without a spec like Open API do not provide the safety of a type system through an SDK.
- The API’s documentation is missing or out of date.
- The API does not have standardized conventions or follow a consistent design. Some domain APIs might support filtering, batching, etc., for instance, but others’ APIs migh have lower quality. So each integration needs a custom approach, a problem compounded by a lack of good documentation. In some cases, this problem is so dire that there are no APIs of any kind in a domain, usually because the domain’s source has thus far been accessed via some application code, typically the controller in an MVC (model–view–controller) framework with no need for generic domain APIs. Our domain 2 is an example of this situation.
- API versioning creates tension with high-velocity development. Not only must you keep track of different kinds of APIs, but you also need to be aware of the version history.
Solving API Integration Challenges
Any API layer that implements the Supergraph architecture is source-aware and output protocol-agnostic. This API layer also provides a common semantic layer and registry for the underlying domains and their APIs and makes these domains work interoperable. In addition to generating type-driven API protocols like GraphQL, gRPC, etc. this semantic layer allows it to generate documentation. See this reference GraphQL schema that a supergraph API platform can generate regardless of the underlying source. Learn more about my preferred API integration solution.
API Aggregation
API aggregation refers to the process of combining multiple API requests into a single unified response. This technique is useful for optimizing data retrieval from multiple sources (it helps integrate with APIs faster), reducing the number of API calls when iterating on the consumer application and improving the performance of client applications.
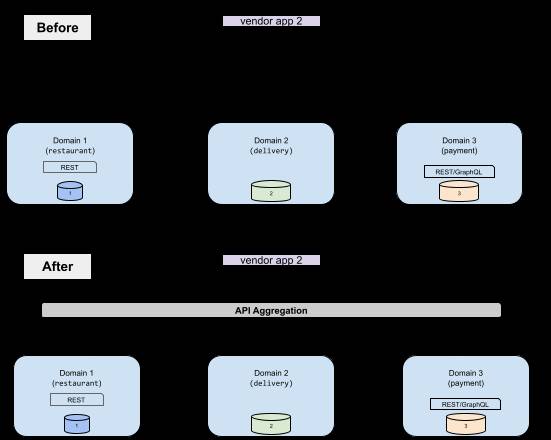
Challenges with API Aggregation
API aggregation is typically not handled by API gateways — one request is sent to only one upstream API. To support API aggregation, you need to write “glue” code or aggregate endpoints that can split the request to upstream APIs and then aggregate their responses for the consumer. But then you run into the operational challenge of ownership: Who owns this glue service(s)? Especially when the aggregation needs to span multiple domains, you also need to iterate on this glue code for every aggregation permutation you want to support.
Note: One way to avoid these iterations is to write a generic smart aggregation service, but that’s a very hard problem to solve: This smart service will need to double up as a service catalog for all upstream services that any new domain API will need to register with. Now you have an even bigger ownership problem.
To summarize, the following challenges make it hard to implement API aggregation in a complex data landscape:
- Explosive creation of new API endpoints to aggregate over: Different consumers have different needs, and their needs evolve rapidly in a high-velocity environment. How does the central API aggregation layer keep up?
- Fuzzy ownership: Domain APIs are owned and designed by domain owners, but often it’s not clear who builds, designs and operates API endpoints that aggregate data across these endpoints.
Solving API Aggregation Challenges
The Supergraph architecture solves these challenges by targeting a self-serve API aggregation end state. For instance, domain data is onboarded into the supergraph (which is our API aggregation layer, among other things) in a way that allows the supergraph to use domain/source information (modeled as a graph) to automatically split an incoming request into individual upstream requests without requiring the development and maintenance of new aggregate endpoints. With this automation, there’s no need for an operating model for API aggregation, removing the need for expensive collaboration. (All collaboration is expensive!) You can read more about API aggregation.
Conclusion: Checklist for an API Platform Design
We can now compile the following checklist for any API platform (referred to as a supergraph) design that seeks to address the challenges of API integration and API aggregation:
Measuring the effectiveness of a platform’s design to meet these criteria and the time/effort investment required to build these capabilities will provide any architect with a clear indication of the likely success of their platform initiative.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.