
包阅导读总结
1. 关键词:Federated Language Models、SLMs、LLMs、Edge、Cloud
2. 总结:本文介绍了结合边缘 SLM 和云端 LLM 的 Federated Language Models,阐述其利用两种趋势并解决企业保密、隐私和安全问题,还指出语言模型的近期趋势及实现该架构面临的挑战。
3. 主要内容:
– Federated Language Models
– 利用边缘 SLM 生成,云端 LLM 映射提示到工具和参数
– 目标是实现 RAG 代理,不向公共领域 LLMs 发送敏感信息
– LLM Trends
– 小型语言模型能力提升但功能调用等仍受限
– 大型语言模型无法部署在边缘设备
– 敏感数据多在数据中心,RAG 需注意合规与安全
– 代理工作流依赖多个语言模型
– Implementing Federated Language Models
– 用户向代理发送提示
– 代理将提示发给云端 LLM
– LLM 回复工具列表
– 代理执行工具并构建上下文
– 代理将用户查询和上下文发给边缘 SLM
– SLM 回复信息
– 代理向用户发送最终响应
– FLM Challenges
– 需精心管理边缘 SLM 和云端 LLM 的协调
– SLM 生成任务性能可能受限
– 边缘与云端通信可能引入延迟
思维导图:
文章地址:https://thenewstack.io/federated-language-models-slms-at-the-edge-plus-cloud-llms/
文章来源:thenewstack.io
作者:Janakiram MSV
发布时间:2024/7/10 16:32
语言:英文
总字数:1574字
预计阅读时间:7分钟
评分:83分
标签:联邦语言模型,生成式人工智能,语言模型,联邦学习,边缘计算
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
There have been two significant developments in the field of generative AI: the rise of small language models (SLM) that can run on devices; and the increased capability of large language models (LLM) in terms of context length, integration of tools, multimodality, and complex reasoning running in the cloud. “Federated Language Models” is an idea that takes advantage of these two trends, while enabling enterprises to adhere to confidentiality, privacy and security.
With federated LMs, we deal with two language models — one running at the edge and the other running in the cloud. An SLM running at the edge is primarily used for generation, while an LLM in the cloud is leveraged for mapping the prompt into a set of tools and the associated parameters. The below diagram depicts the architecture and flow of federated LMs:
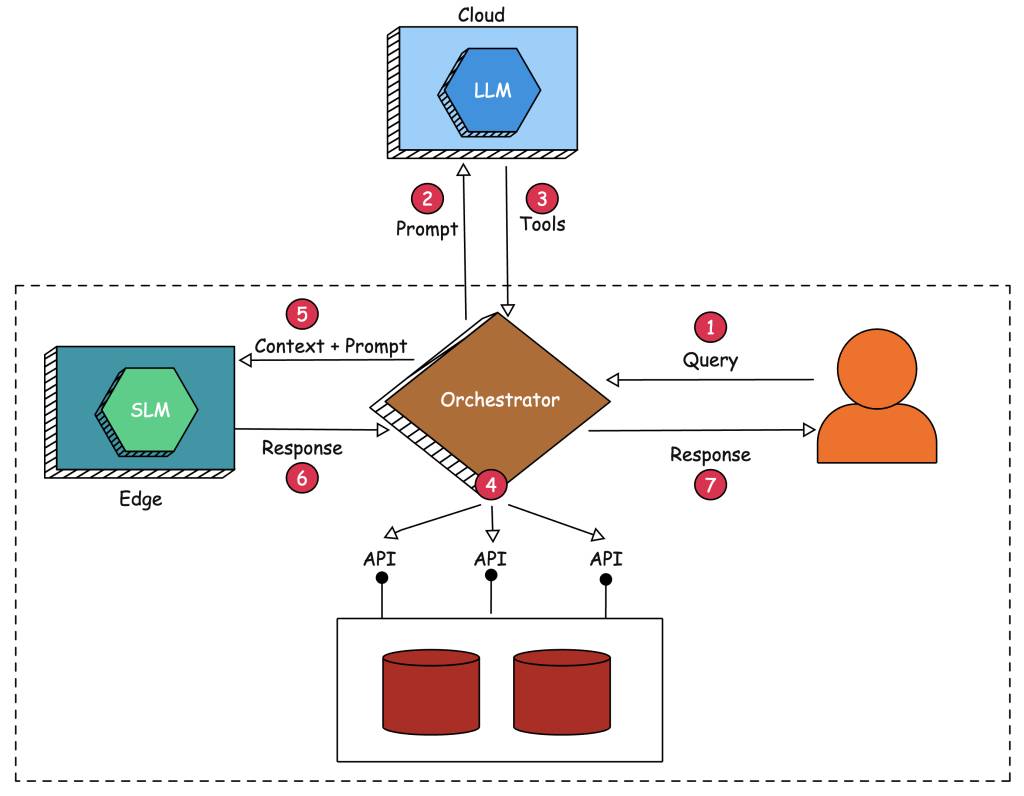
The objective is to implement a Retrieval Augmented Generation (RAG) agent without the need to send sensitive context to the capable LLMs running in the public domain. The capable LLM is leveraged to map the prompt to appropriate tools that have access to sensitive internal data and applications. The application that’s orchestrating the calls to the language models executes the tools identified by the LLM to extract the context, which is sent to the less capable SLM running on an inexpensive edge device locally. This architecture hides sensitive data from the LLM by delegating the actual generation to the SLM.
Before we take a closer look at implementing this architecture, let’s highlight some of the recent trends in the evolving landscape of language models.
LLM Trends
1. Small Language Models are becoming increasingly capable and mature
SLMs are becoming increasingly capable and mature, demonstrating significant advancements in performance and efficiency. Recent developments such as Gemini Nano and Microsoft Phi-3 exemplify this trend.
Gemini Nano, developed by Google DeepMind, is designed to operate efficiently on edge devices, providing powerful language processing capabilities without the need for extensive computational resources. Similarly, Microsoft Phi-3 leverages innovative architecture and training techniques to deliver high accuracy and contextual understanding in a compact form. These models, alongside others in the SLM category, showcase enhanced capabilities in natural language understanding, generation, and translation, making them suitable for a wide range of applications — from mobile devices to enterprise solutions.
The progress in SLMs indicates a shift towards more accessible and versatile AI solutions, reflecting a broader trend of optimizing AI models for efficiency and practical deployment across various platforms.
2. Function calling and tools are still restricted to Large Language Models
Function calling and tools remain predominantly restricted to LLMs, as SLMs lack the necessary capabilities to perform these advanced tasks.
LLMs, such as OpenAI’s GPT-4o, Anthropic Claude 3.5 Sonnet, and Google’s Gemini 1.5 Pro, possess extensive contextual understanding and reasoning capabilities, enabling them to handle complex function calls and integrate with various tools seamlessly. In contrast, SLMs, despite their increasing sophistication, are still limited by their smaller parameter sizes and reduced computational capacities. This limitation hinders their ability to process intricate instructions and interact with external systems effectively.
While models like Gemini Nano and Microsoft Phi-3 have made strides in improving the efficiency and accuracy of SLMs, they still fall short in executing advanced functions and tool integrations, which require the robust performance and extensive training data characteristic of LLMs. As a result, the use of function calling and sophisticated tool interactions continues to be a domain where LLMs excel and dominate.
3. Large Language Models cannot be deployed on edge devices like Nvidia Jetson
Language models cannot be effectively deployed on edge devices like Nvidia Jetson, due to the inherent limitations in computational resources and the challenges associated with quantization. While quantizing LLMs to reduce their size and computational requirements is a common approach, it often results in a significant loss of precision and capability. These quantized models struggle to maintain the same level of accuracy and contextual understanding as their full-precision counterparts, leading to degraded performance in tasks requiring nuanced language comprehension.
Additionally, the memory and processing power of edge devices like Nvidia Jetson are insufficient to handle the complexity of LLMs, even in a quantized form. As a result, deploying LLMs on these devices remains impractical, as the trade-offs in performance and precision outweigh the benefits. This limitation underscores the need for continued development of more efficient models and algorithms that can balance the demands of advanced language processing with the constraints of edge computing environments.
4. Most of the sensitive data needed for RAG lives inside the data center
The majority of the sensitive data required for RAG resides within secure data centers, highlighting the significant compliance and security concerns associated with sending this data to LLMs operating in the public domain.
Transmitting private data to external LLMs can violate stringent compliance regulations, such as GDPR and HIPAA, which mandate strict controls over data access and processing. Additionally, there is a risk that this sensitive information could be inadvertently used in the pretraining and fine-tuning phases of LLMs, leading to potential data breaches or unauthorized use. Furthermore, the latency involved in transmitting local data to cloud-based LLMs can significantly impact performance and responsiveness, making real-time applications less viable.
These concerns are compounded by the inherent lack of control over data once it leaves the protected environment of the data center, increasing the vulnerability to cyber threats and misuse. Therefore, organizations must prioritize keeping sensitive data within their secure infrastructure, leveraging on-premise or private cloud solutions for RAG, to ensure compliance and mitigate risks associated with data privacy and security.
5. Agentic workflows rely on more than one language model
Agentic workflows, which involve autonomous agents performing complex tasks through a series of interdependent steps, rely on more than one language model to achieve optimal results.
An agentic workflow is designed to mimic human-like problem-solving, by breaking down tasks into smaller, manageable components and executing them sequentially, or in parallel. This often necessitates the use of multiple specialized language models, each tailored to handle specific aspects of the workflow. For instance, one model might excel at natural language understanding, another at generating detailed responses, and yet another at handling domain-specific knowledge.
Additionally, agents may rely on SLMs at the edge for real-time, low-latency processing, and more capable LLMs in the cloud for handling complex, resource-intensive tasks. By leveraging the unique strengths of various models, agentic workflows can ensure higher accuracy, efficiency, and contextual relevance in their operations. The need to communicate with multiple models allows the workflow to integrate diverse capabilities, ensuring that complex tasks are addressed holistically and effectively, rather than relying on a single model’s limited scope. This multimodel approach is crucial for achieving the nuanced and sophisticated outcomes expected from agentic workflows in real-world applications.
Implementing Federated Language Models
Step 1: The user sends a prompt that needs access to the local databases exposed as APIs to the agent.
Step 2: Since the SLM running at the edge cannot map the prompt to functions and arguments, the agent — which acts as the orchestrator and the glue — sends the prompt, along with the available tools, to the LLM running in the cloud.
Step 3: The capable LLM responds with a set of tools — functions and arguments — to the orchestrator. The only job of this model running in the public domain is to break down the prompt into a list of functions.
Step 4:The agent enumerates the tools identified by the LLM and executes them in parallel. This essentially involves invoking the API that interfaces with the local databases and data sources, which are sensitive and confidential. The agent aggregates the response from the invoked functions and constructs the context.
Step 5:The agent then sends the original query submitted by the user, along with the aggregated context collected from the tools, to the SLM running at the edge.
Step 6:The SLM responds with factual information derived from the context sent by the orchestrator/agent. This is obviously limited to the context length of the SLM.
Step 7:The agent sends the final response to the original query sent by the user.
FLM Challenges
While this approach is promising, it may face implementation challenges:
- Coordination between the edge SLM and cloud LLM would need to be carefully managed.
- The performance of the SLM for generation tasks might not match that of LLMs, potentially limiting the overall system capability.
- The approach might introduce latency due to the back-and-forth communication between edge and cloud.
The objective of this article was to introduce Federated Language Models, an innovative approach combining edge-based Small Language Models (SLMs) with cloud-based LLMs. This approach leverages LLMs for complex task planning and SLMs for local data generation, addressing privacy concerns in enterprise AI applications. While promising, the system faces challenges in coordination between models, potential performance limitations of SLMs, and latency issues. Despite these hurdles, it offers a novel solution balancing advanced AI capabilities with data security, though careful implementation is crucial for success.
I implemented a proof of concept of this approach based on Microsoft Phi-3 running on Jetson Orin locally, a MongoDB database exposed as an API, and GPT-4o available from OpenAI. In the next part of this series, I will walk you through the code and the step-by-step guide to run this in your own environment.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.