
包阅导读总结
1.
关键词:OpenAI、CriticGPT、ChatGPT、代码评估、可扩展监督
2.
总结:OpenAI 发布关于 CriticGPT 的论文,这是微调后的 GPT-4,用于评估 ChatGPT 生成的代码。与人类评估者相比,它能捕捉更多错误。OpenAI 旨在用其改善模型,解决人类难以评估 AI 输出的问题,其也是用 RLHF 微调的,评估显示其效果较好。
3.
主要内容:
– OpenAI 发布 CriticGPT 相关论文
– CriticGPT 是微调后的 GPT-4,用于评估 ChatGPT 生成的代码
– 与人类评估者相比,能捕捉更多错误,生成更好的评估
– 开发背景
– 开发 ChatGPT 时用人类“AI 训练员”评估模型输出
– 随着 AI 模型进步,人类评估困难,CriticGPT 用于解决此问题
– 训练方式
– 用 RLHF 微调,训练数据包括有缺陷的代码及人类生成的评估
– 人类评估显示其输出优于 ChatGPT 和人类评论家
– Human+CriticGPT 团队输出更全面但“吹毛求疵”更多
– 相关讨论
– 被认为是 Paul Christiano 多年前提出的想法的实现
– 其他公司也在进行可扩展监督的研究
思维导图: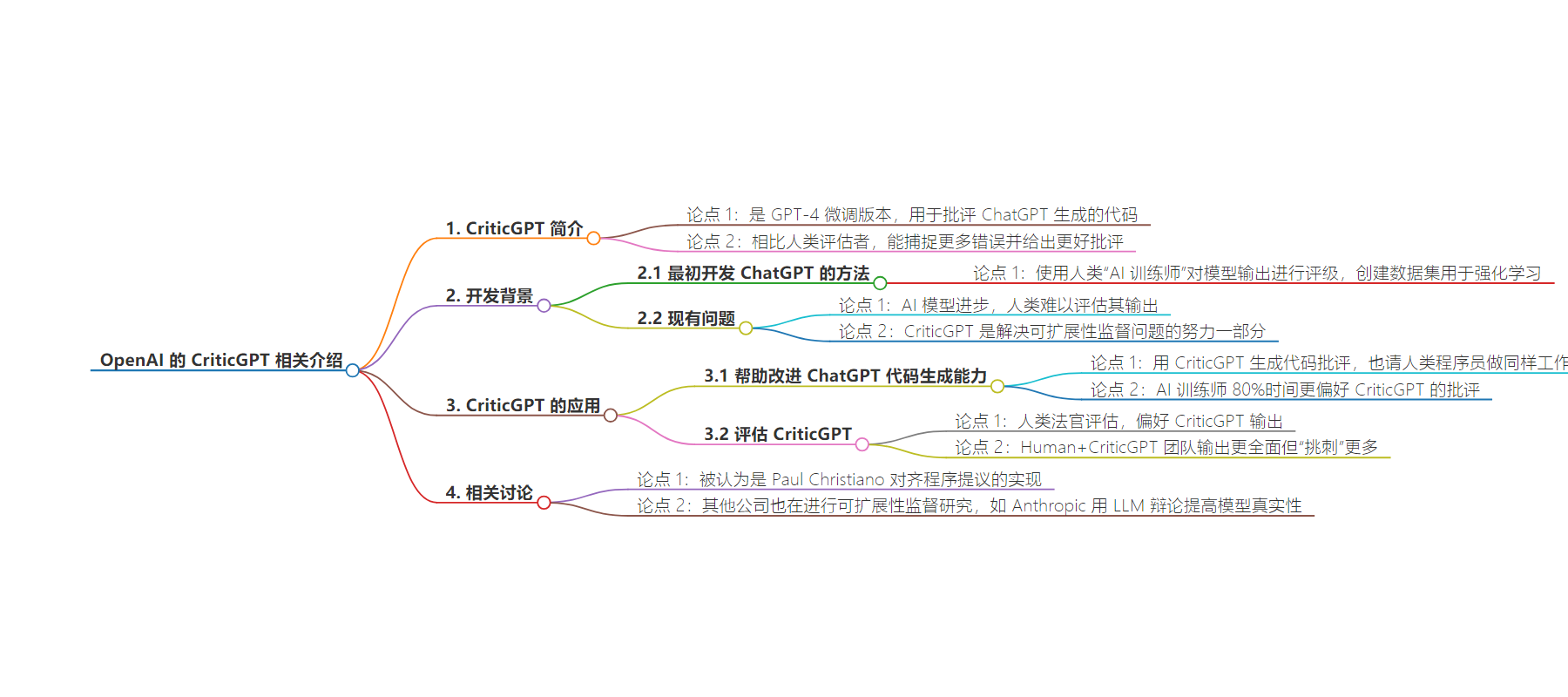
文章来源:infoq.com
作者:Anthony Alford
发布时间:2024/7/9 0:00
语言:英文
总字数:550字
预计阅读时间:3分钟
评分:87分
标签:OpenAI,CriticGPT,代码评审器,GPT-4,ChatGPT
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
OpenAI recently published a paper about CriticGPT, a version of GPT-4 fine-tuned to critique code generated by ChatGPT. When compared with human evaluators, CriticGPT catches more bugs and produces better critiques. OpenAI plans to use CriticGPT to improve future versions of their models.
When originally developing ChatGPT, OpenAI used human “AI trainers” to rate the outputs of the model, creating a dataset that was used to fine-tune it using reinforcement learning from human feedback (RLHF). However, as AI models improve, and can now perform some tasks at the same level as human experts, it can be difficult for human judges to evaluate their output. CriticGPT is part of OpenAI’s effort on scalable oversight,which is intended to help solve this problem. OpenAI decided first to focus on helping ChatGPT improve its code-generating abilities. The researchers used CriticGPT to generate critiques of code; they also paid qualifiedhuman coders to do the same. In evaluations, AI trainers preferred CriticGPT’s critiques 80% of the time, showing that CriticGPT could be a good source for RLHF training data. According to OpenAI:
The need for scalable oversight, broadly construed as methods that can help humans to correctly evaluate model output, is stronger than ever. Whether or not RLHF maintains its dominant status as the primary means by which LLMs are post-trained into useful assistants, we will still need to answer the question of whether particular model outputs are trustworthy. Here we take a very direct approach: training models that help humans to evaluate models….It is…essential to find scalable methods that ensure that we reward the right behaviors in our AI systems even as they become much smarter than us. We find LLM critics to be a promising start.
Interestly, CriticGPT is also a version of GPT-4 that is fine-tuned with RLHF. In this case, the RLHF training data consisted of buggy code as the input, and a human-generated critique or explanation of the bug as the desired output. The buggy code was produced by having ChatGPT write code, then having a human contractor insert a bug and write the critique.
To evaluate CriticGPT, OpenAI used human judges to rank several critiques side-by-side; judges were shown outputs from CriticGPT and from baseline ChatGPT, as well as critiques generated by humans alone or by humans with CriticGPT assistance (“Human+CriticGPT”). The judges preferred CriticGPT’s output over that of ChatGPT and human critics. OpenAI also found that the Human+CriticGPT teams’ output was “substantially more comprehensive” than that of humans alone. However, it tended to have more “nitpicks.”
In a discussion about the work on Hacker News, one user wrote:
For those new to the field of AGI safety: this is an implementation of Paul Christiano’s alignment procedure proposal called Iterated Amplification from 6 years ago…It’s wonderful to see his idea coming to fruition! I’m honestly a bit skeptical of the idea myself (it’s like proposing to stabilize the stack of “turtles all the way down” by adding more turtles)…but every innovative idea is worth a try, in a field as time-critical and urgent as AGI safety.
Christiano formerly ran OpenAI’s language model alignment team. Other companies besides OpenAI are also working on scalable oversight. In particular, Anthropic has published research papers on the problem, such as their work on using a debate between LLMs to improve model truthfulness.