
包阅导读总结
1. 关键词:大模型、小哥作业、智能操作、智能问答、物流
2. 总结:
本文探讨了利用大模型服务一线小哥的实践,包括模板加载与渲染、提升小哥作业效率的动作分析与场景选取,以及在智能操作和智能问答方面的应用,同时注重用户隐私和信息安全保护,还介绍了相关技术的优化,以提高服务质量和效率。
3. 主要内容:
– 大模型与小哥作业
– 介绍大模型服务小哥作业的流程,如模板加载和渲染。
– 分析小哥作业动作,选取部分场景结合大模型等技术提供作业工具。
– 重视用户隐私和信息安全建设。
– 智能操作
– 常规算法的pipline存在问题,大模型可直接使用,提升研发效率。
– 接收小哥语音输入后实现作业功能的方式,如发短信、填写揽收信息和查询信息。
– 智能问答
– 业务发展对小哥作业要求高,大模型能更好理解小哥问题,提高回答准确率。
– 通过Prompt+检索增强生成实现智能问答,优化文档内容提取和切分方式。
思维导图: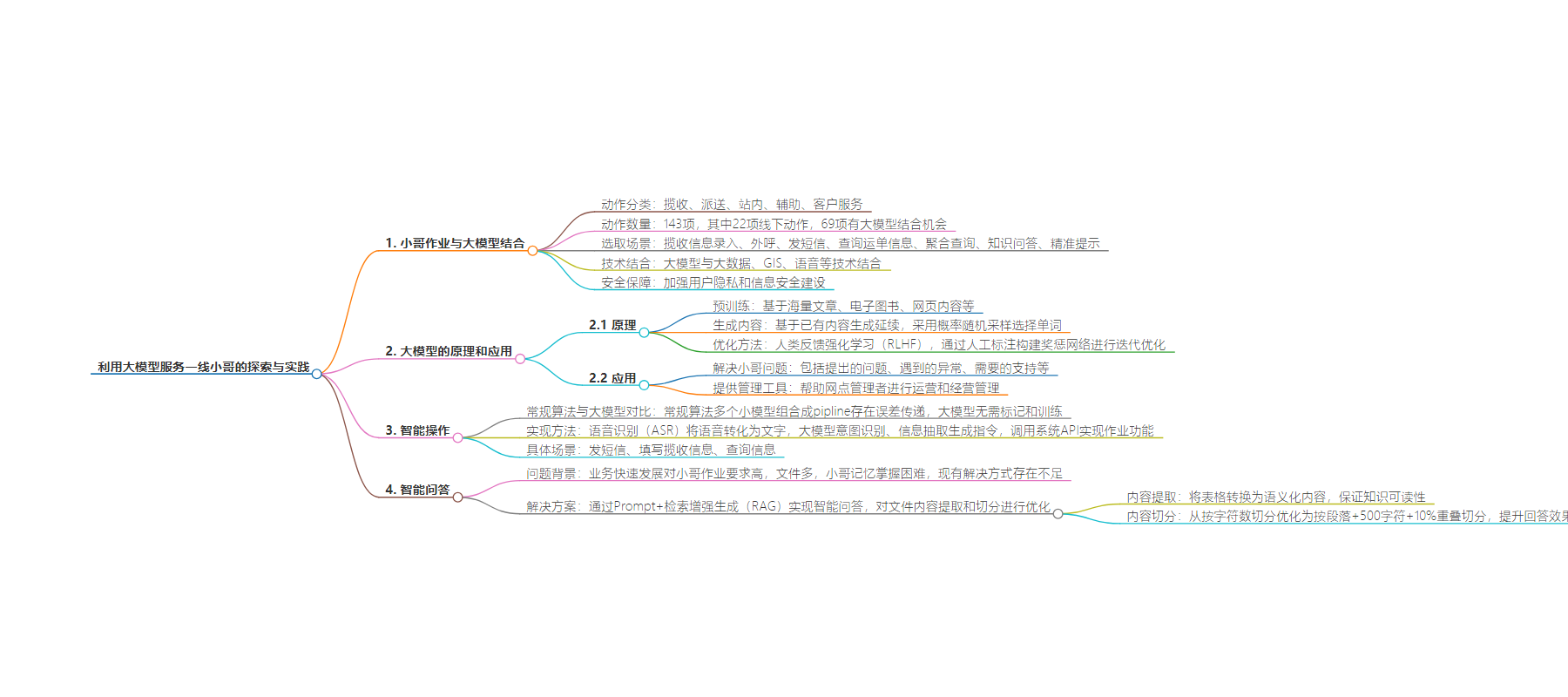
文章地址:https://mp.weixin.qq.com/s/qFcNY4fyl92nCqFtbTHX2g
文章来源:mp.weixin.qq.com
作者:京东物流??马酩
发布时间:2024/7/4 3:47
语言:中文
总字数:5759字
预计阅读时间:24分钟
评分:92分
标签:大模型,AI应用,快递物流,智能助手,语音识别
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

小哥作业+大模型
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
2022年OpenAI基于GPT推出了聊天机器人ChatGPT,带来了非常惊艳的语言理解、内容生成、知识推理等能力,能够准确理解人的语言、意图,并能够回答出清晰、完整的内容,让人很难分辨出沟通交流的是人类还是机器人。
大模型会尝试基于已有的内容,生成内容的延续。基于预训练阶段加入的海量文章、电子图书、网页内容等等,大模型给出最接近我们期望的内容。比如我们提供的内容是“北京是…”,大模型扫描海量内容进行排名,为了让内容更有创造力,大模型使用了巫术,一般采用基于可配置参数(top K, top P, Temperature) 的概率随机采样来选择单词,而不是总采用排名最高的单词。通过延续生成了“北京是一座充满活力的城市”。人类反馈强化学习(RLHF)即基于人类反馈对大语言模型进行强化学习,通过人工标注来构建奖惩网络,强化学习基于奖惩网络对模型进行迭代优化,改善生成内容的质量。
快递快运终端系统是快递小哥、快运司机、网点管理者日常使用的系统,是物流作业人员最多、作业流程最末端、服务形态最多元的系统。大模型带来了新的方法来解决小哥提出的问题、遇到的异常、需要的支持,并提供帮助网点管理者进行运营和经营管理的工具。
提升小哥作业效率,就需要了解小哥日常工作中有哪些作业动作,然后根据作业动作的特点,来分析大模型有什么样的机会来实现效率提升。通过调研和分析,小哥有143项作业动作,可分类为:揽收、派送、站内、辅助、客户服务五大类,其中22项动作是系统外的线下动作,其他动作中有69项被认为有大模型结合的机会。在69项中我们选取了小哥揽收信息录入、外呼、发短信、查询运单信息、聚合查询、知识问答、精准提示等场景,通过大模型与大数据、GIS、语音等技术的结合,为小哥提供高效、易用的作业工具。
在一线小哥高效履约的同时,系统也加强了对用户隐私、信息安全方面的建设。面单中用户姓名、地址、电话采用微笑面单保护, 系统中电话采用隐私号技术,在信息流中也同样隐私保护敏感信息。京东物流非常重视全链路信息安全,建立了全面的安全防护体系。小哥日常作业中,会频繁给客户打电话、发短信。出于客户个人隐私安全的考虑,面单中隐藏了电话,所以外呼前需要小哥一次次在系统中查找电话,经常是扫单号、在详情页点击外呼按钮、拨打电话等一系列动作。通过小哥语音,大模型可以帮助我们分析小哥的意图,识别出拨打电话,就可以通过语音中提到的运单尾号、地址等特征完成外呼。
智能操作
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
小哥作业+大模型
2022年OpenAI基于GPT推出了聊天机器人ChatGPT,带来了非常惊艳的语言理解、内容生成、知识推理等能力,能够准确理解人的语言、意图,并能够回答出清晰、完整的内容,让人很难分辨出沟通交流的是人类还是机器人。
大模型会尝试基于已有的内容,生成内容的延续。基于预训练阶段加入的海量文章、电子图书、网页内容等等,大模型给出最接近我们期望的内容。比如我们提供的内容是“北京是…”,大模型扫描海量内容进行排名,为了让内容更有创造力,大模型使用了巫术,一般采用基于可配置参数(top K, top P, Temperature) 的概率随机采样来选择单词,而不是总采用排名最高的单词。通过延续生成了“北京是一座充满活力的城市”。人类反馈强化学习(RLHF)即基于人类反馈对大语言模型进行强化学习,通过人工标注来构建奖惩网络,强化学习基于奖惩网络对模型进行迭代优化,改善生成内容的质量。
智能操作
小哥智能助手中智能操作的实现方法如下:
小哥查询信息,也可以通过语音输入,大模型识别意图,进行结果的反馈。如下是通过大模型实现的意图识别示例:
智能问答
通过Prompt+检索增强生成(RAG)实现了第一阶段的智能问答。之所以需要检索增强生成是因为大模型目前存在幻觉、知识过时等问题,RAG实现从外部知识库中检索相关信息进行回答,提高答案的准确性。
第一版采用了DocumentLoaderUtil直接提取文本,将文本信息存入txt文件,具体实现方式如下:
from src.document_loader.document_loader import DocumentLoaderUtilprocessor = DocumentLoaderUtil(file_path=path_ori, pic_save_dir=dir_save_picture)texts = processor.load()texts = json.dumps(texts, ensure_ascii=False, indent=4)with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt"), "w") as f:f.write(texts)
优化后处理DOCX文件:
1.读取文档信息时,遇到表格,将表格单独存储到excel中,并在文本中使用特殊占位符标注表格位置;
2.结合大模型对表格进行语义化处理,使表格信息转化成语义化文本;
def extract_tables_to_excel(docx_path, excel_result_path):doc = Document(docx_path)docx_name = os.path.splitext(os.path.basename(docx_path))[0]folder_path = os.path.join(excel_result_path, docx_name)if not os.path.exists(folder_path):os.makedirs(folder_path)table_count = 0for table in doc.tables:table_count += 1data = [[cell.text for cell in row.cells] for row in table.rows]df = pd.DataFrame(data)excel_path = os.path.join(folder_path, f"【表格{table_count}】.xlsx")df.to_excel(excel_path, index=False, header=False)return folder_pathdef replace_marker_in_txt(file_path, marker, replacement_text):with open(file_path, 'r+', encoding='utf-8') as file:content = file.read()if replacement_text is None:replacement_text = ''content = content.replace(marker, replacement_text)file.seek(0)file.write(content)file.truncate()def insertTable(folder_path, txt_path):for filename in os.listdir(folder_path):filepath = os.path.join(folder_path, filename)filename_without_extension, _ = os.path.splitext(filename)result = excel_to_txt_single(filepath)replace_marker_in_txt(txt_path,filename_without_extension,result)
优化后处理PDF文件:
def process_pdf(file_path, file_name, output_directory, save_directory, txt_file):individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)content = DocumentLoaderUtil(file_path, save_directory).load()content = [doc['page_content'] for doc in content]with open(txt_file, 'w', encoding='utf-8') as f:for line in content:f.write(line + '\n')replace_similar_module_in_txt(individual_file_names, txt_file, file_path)def handle_exception(extension, file_path, file_name, output_directory, save_directory):try:if extension == '.pdf':individual_file_names = save_pdf_tables_to_excel(file_path, file_name, output_directory)text, txt_file = convert_pdf_to_txt(file_path, os.path.join(save_directory, 'txt'))else:returnwith open(txt_file, 'w', encoding='utf-8') as output_file:output_file.write(text)replace_similar_module_in_txt(individual_file_names, txt_file, file_path)except FileNotFoundError as e:with open('error.md', 'a') as file:file.write(f"文件未找到错误:{file_path}\n")except Exception as e:with open('error.md', 'a') as file:file.write(f"handle_exception处理异常时发生错误:{file_path}\n")def replace_similar_module_in_txt(individual_file_names, txt_file, file_path):with open(txt_file, 'r', encoding='utf-8') as file:txt_content = file.read()for excel_path in individual_file_names:excel_content = read_excel_content(excel_path)most_similar_part = find_most_similar_part(txt_content, excel_content, threshold=0.02)if most_similar_part:replacement_text = excel_to_txt_single(excel_path)txt_content = safe_replace(txt_content, most_similar_part, replacement_text)else:replacement_text = excel_to_txt_single(excel_path)txt_content += replacement_textwith open(txt_file, 'w', encoding='utf-8') as file:file.write(txt_content)
from src.text_splitter.text_splitter import TextSplitterUtilsplitter_name = "RecursiveCharacterTextSplitter"splitter_args = {"chunk_size": 300,"chunk_overlap": round(300 * 0.15),"length_function": len,}splitter = TextSplitterUtil(splitter_name, splitter_args)with open(os.path.join(dir_save_text, f"{os.path.basename(path_ori)}.txt")) as f:texts = json.load(f)texts_splitted = splitter.create_documents(texts=[t["page_content"] for t in texts],metadatas=[{"source": f"{path_ori}_{ti}"} for ti, t in enumerate(texts)],)print(texts_splitted)
import osimport jsonimport reimport csvdef find_all_matches(doc, patterns):last_end = 0matches = []for pattern in patterns:for match in pattern.finditer(doc):start, end = match.span()if start > last_end:matches.append(doc[last_end:start])matches.append(match.group())last_end = endif last_end < len(doc):matches.append(doc[last_end:])return matchesdef trim_regex_title(path_ori):with open(path_ori, 'r', encoding='utf-8') as file:document = file.read()patterns = [re.compile(r'((?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|\d+\.)[^\n]+)([\s\S]*?)(?=\n(?:一、|二、|三、|四、|五、|六、|七、|八、|九、|十、|\d+\.)[^\n]+|$)'),re.compile(r'(\n.+?)(?=\n.+|$)'),re.compile(r'(?s)(\n\d+\.\d+\s+.*?)(?=\n\d+\.\d+\s+|$)')]matches = find_all_matches(document, patterns)page_contents = []for match in matches:section_content = match.strip()page_contents.append({'page_content': section_content,'metadata': {'source': path_ori,},})page_checks = []accumulated_content = ""for page in page_contents:page_content = page['page_content']if len(accumulated_content) + len(page_content) > 500:if accumulated_content:page_check_dict = {"page_content": accumulated_content,"metadata": {"source": path_ori}}page_checks.append(page_check_dict)accumulated_content = ""start_index = 0while start_index < len(page_content):end_index = min(start_index + 500, len(page_content))page_check_dict = {"page_content": page_content[start_index:end_index],"metadata": {"source": path_ori}}page_checks.append(page_check_dict)start_index += 450else:if len(accumulated_content) + len(page_content) < 500:accumulated_content += page_contentelse:page_check_dict = {"page_content": accumulated_content,"metadata": {"source": path_ori}}page_checks.append(page_check_dict)accumulated_content = page_contentif accumulated_content:page_check_dict = {"page_content": accumulated_content,"metadata": {"source": path_ori}}page_checks.append(page_check_dict)return page_checks
from src.embedding.get_embedding import get_openai_embeddingmodel_key = "xxxx"model_name = "text-embedding-ada-002-2"texts_embedding = [get_openai_embedding(text=t.page_content, model_name=model_name, model_key=model_key)for t in texts_splitted]
d. 内容管理
我们为向量创建索引,以便于检索和更新,同时将各阶段产物包括源文件、切分脚本、切分文本块、向量嵌入脚本、向量存储通过oss进行管理,并建立映射表。当业务知识进行更新时,可以对向量库中的内容进行更新替换。

智能提示

智能体
▪功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活