
包阅导读总结
1. 关键词:Golang、零拷贝、超边缘缓存服务器、IO 性能、优化
2. 总结:
本文探讨使用 Golang 零拷贝解决超边缘缓存服务器开发中的关键问题,介绍了传统 IO 流程及存在的问题,详细阐述了零拷贝的优化方式及在 Golang 中的实现,展示了业务实践效果,并对未来的技术沉淀和 KTLS 支持进行了展望。
3. 主要内容:
– 背景
– 超边缘服务器硬件性能低,需软件优化,超边缘缓存服务器优化 IO 性能关键在于磁盘和网络 IO。
– 传统 IO 流程
– 输入过程:应用程序发起 read 系统调用,经多次拷贝和中断,数据从磁盘到用户缓冲区。
– 输出过程:应用程序处理数据后发起 write 系统调用,数据经多次拷贝发送出去。
– 存在问题:CPU 负载高、数据多次拷贝占用内存、上下文切换耗时多。
– 对传统 IO 流程的优化
– DMA:直接内存访问技术,代替 CPU 进行数据拷贝,释放 CPU 做其他事。
– 零拷贝
– mmap + write:减少 1 次数据拷贝,但仍有 CPU 拷贝和 4 次上下文切换。
– sendfile:减少 1 次系统调用和 2 次上下文切换,仍非彻底零拷贝。
– sendfile + SG-DMA:真正零拷贝,降低内核空间和用户空间切换次数及数据拷贝次数。
– Golang – 零拷贝实现
– 因超边缘服务器异构性选择 Golang,通过一系列函数调用实现零拷贝。
– 业务实践
– 零拷贝功能上线后,在内存、CPU、服务端发送速度方面有很大优化。
– 未来展望
– 技术沉淀:整理相关函数使用,支持不同情况下零拷贝,减少业务使用负担。
– KTLS:Golang 目前不支持,期待未来进展。
思维导图:
文章地址:https://juejin.cn/post/7380222254195834892
文章来源:juejin.cn
作者:字节跳动技术团队
发布时间:2024/6/14 10:28
语言:中文
总字数:4738字
预计阅读时间:19分钟
评分:93分
标签:性能优化,Go
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
作者:李伟伟
-
本文通过 Golang-零拷贝来解决现代超边缘缓存服务器开发中的两个关键问题:
- 第一:如何使用 Golang 这一在各大互联网公司中越来越流行的、高效的工程语言来实现超边缘缓存服务器,以实现研发效率和软件性能的平衡。
- 第二:如何在硬件资源条件较低的超边缘服务器上,通过低成本的优化手段,实现高性能 IO。
-
阅读完本文后,你可以了解到对传统 IO 进行优化的4种方法,尤其会对零拷贝有一个更深、更详细的理解,理论上它可以让 CPU 拷贝数据的次数降低 50%、用户空间和内核空间切换的次数降低 50%、内存占用降低 66%。并且你能看到它在字节几千台超边缘缓存服务器上部署后,为点播、下载业务提供 Tb 级别带宽时的实际优化效果。
-
同时,本文作者准备逐步开放 Golang 点直播零拷贝程序包。鼓励共建,把这块儿能力推出去,让其他业务能够快速复用。为超边缘计算中的 IO 密集型服务,提供开箱即用的优化手段。
1. 背景
超边缘服务器通常位于网络架构的边缘,远离中心机房,其网络带宽较低、CPU 和磁盘等硬件性能较低,这就需要通过软件层面的优化来提升服务器性能。
超边缘缓存服务器作为传输静态文件的网络服务器,其主要功能是通过网络将磁盘上的文件发送到客户端。在这一过程中,主要涉及磁盘 IO 和网络 IO。因此,优化 IO 性能是提升超边缘缓存服务器性能的关键。简言之,通过改进磁盘和网络 IO 的效率,能够显著提升服务器的响应速度和性能表现。
优化 IO 的常见方法有缓存、合并 IO 和多线程处理,但这些方法往往需要对业务架构进行较大幅度的调整,零拷贝(zero-copy)技术在业务上改造少(尤其是使用 Golang 的业务,只需要将read、write调用换成io.CopyN即可,见后文详细分析),且能大幅度优化 IO 性能:减少 50% 的内核空间和用户空间的切换次数、减少 50% 的数据拷贝次数、减少 66% 的内存占用。
2. 传统IO流程
在传统 IO 流程中,从磁盘发送文件到网络的 IO 过程如下:
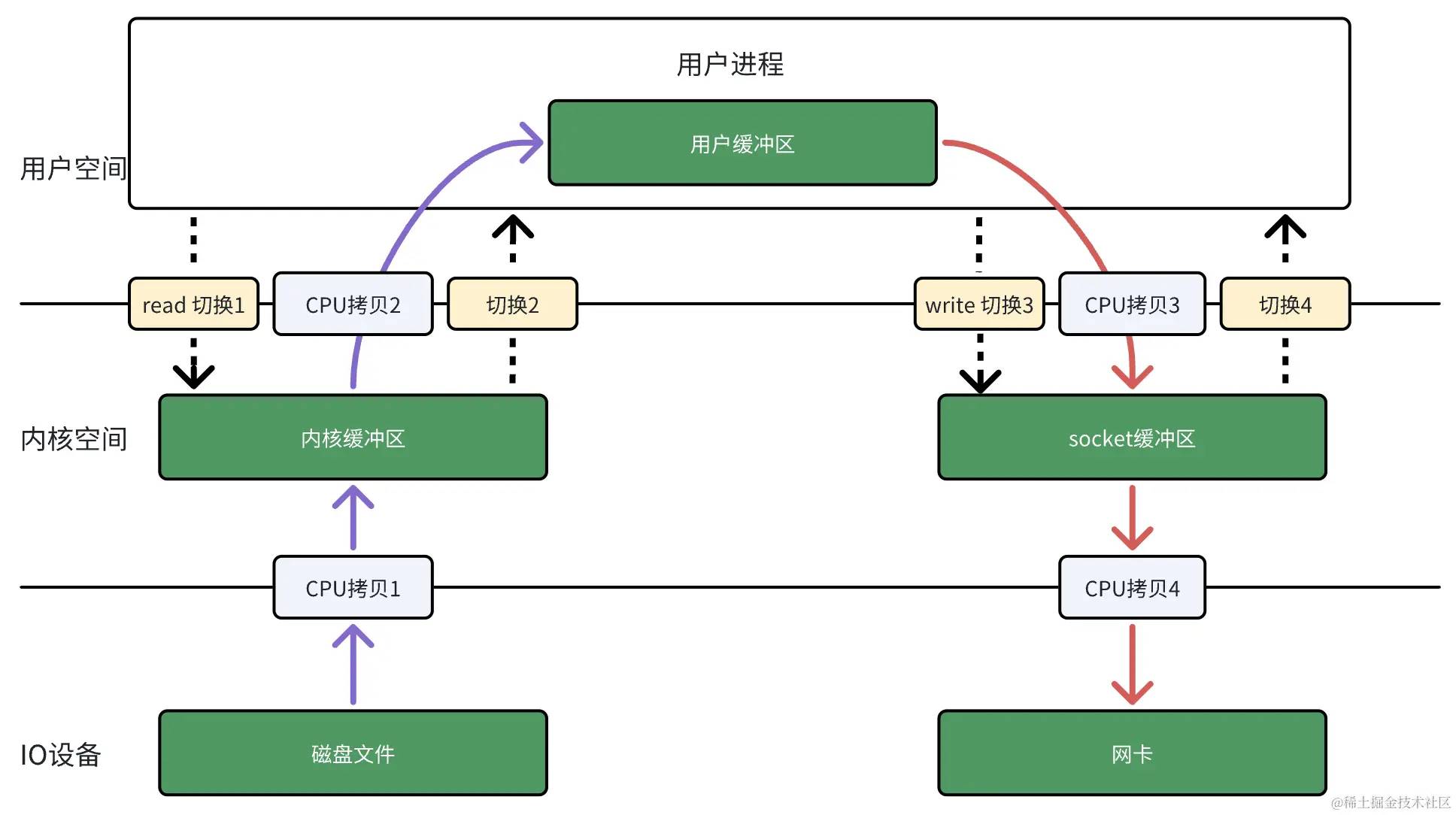
图1 传统 IO 流程
传统 IO 流程具体步骤:
Input 过程:
- 应用程序发起
read系统调用,操作系统接收到系统调用请求后,切换到内核空间 - CPU 将
read系统调用转化为 IO 请求发送给磁盘控制器 - 磁盘控制器将数据从磁盘加载到磁盘控制器的缓冲区,数据拷贝完后,磁盘控制器给 CPU 发送 IO 中断信号
- CPU 收到磁盘控制器的 IO 中断信号后,将数据从磁盘控制器缓冲区拷贝到内核缓冲区(page cache)
- CPU 将数据从内核缓冲区再拷贝到用户缓冲区,
read系统调用结束,切换回到用户空间
Output 过程:
- 应用程序对数据处理后,发起
write系统调用,操作系统接收到系统调用后,再次切换到内核空间 - CPU 将数据从用户缓冲区拷贝到socket缓冲区
- CPU 将数据从 socket 缓冲区拷贝到网卡缓冲区,系统调用返回,再次切回到用户空间
- 网卡将数据发送出去
在传统 IO 流程中,主要存在 3 个问题:
- CPU 忙于拷贝数据,在高 QPS 场景下会导致 CPU 的负载过高
- 数据被多次拷贝,同一份数据占用多份内存
- 多次在用户空间和内核空之间切换上下文,CPU 处理耗时较多
优化 IO 流程主要是解决上面 3 个问题。
3. 对传统IO流程的优化
3.1 DMA
在传统 IO 流程中,数据读取、发送过程中,每次数据拷贝都需要 CPU 来完成,如果read/write请求不多,CPU还能在两次read/write之间去做其他事情,但是当read/write请求比较多时,CPU 会花费很多时间在数据拷贝上,如果有一个模块能够代替 CPU 做这些数据拷贝的工作,那么 CPU 就可以释放出来,做更多其他事情了, 这时,DMA 应运而生。
DMA(Direct Memory Access),又称直接内存访问技术,当 CPU 要从磁盘读取文件内容时,CPU 会告诉 DMA 读取哪些数据、读取到内存的哪个位置,DMA 就会从磁盘读取数据,并将数据写入到内存中对应位置,而此过程中 CPU就可以去做其他事情了,根本不需要参与到具体每个字节数据的搬运过程中了。另外,DMA 可以比 CPU 更快地进行数据传输,因为 CPU 架构决定了它专精于计算,而 DMA 是专门被设计用作传输数据的,它更擅长传输数据。
有 DMA 后,从磁盘发送文件到网络的 IO 流程如下:
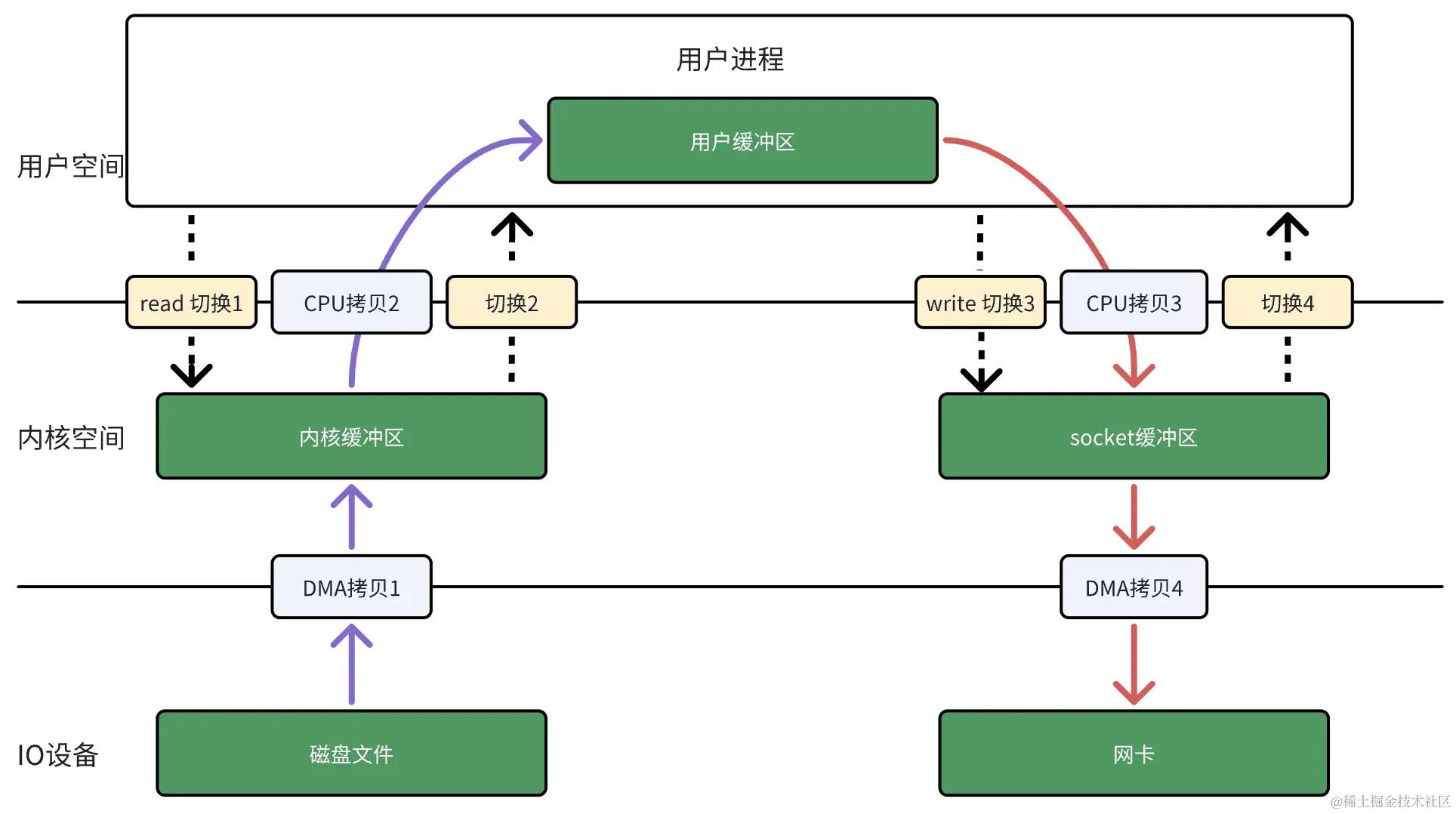
图2 有 DMA 参与的 IO 流程
3.2 零拷贝
虽然 DMA 减少了 CPU 参与数据拷贝的次数,但是仍然需要 4 次数据拷贝、4 次用户空间和内核空间的切换,这两点既占用内存,又耗时。零拷贝技术能够减少数据拷贝次数、减少用户空间和内核空间相互切换的次数。
零拷贝技术实现的方式通常有 3 种:
mmap+writesendfilesendfile+SG-DMA
3.2.1 mmap + write
read 系统调用的过程中会把内核缓冲区的数据拷贝到用户缓冲区里,为了减少这一步的开销,可以用mmap 替换 read 系统调用函数。
mmap 系统调用会直接把内核缓冲区里的数据映射到用户空间,这样,内核空间与用户空间就不需要再进行任何的数据拷贝操作。
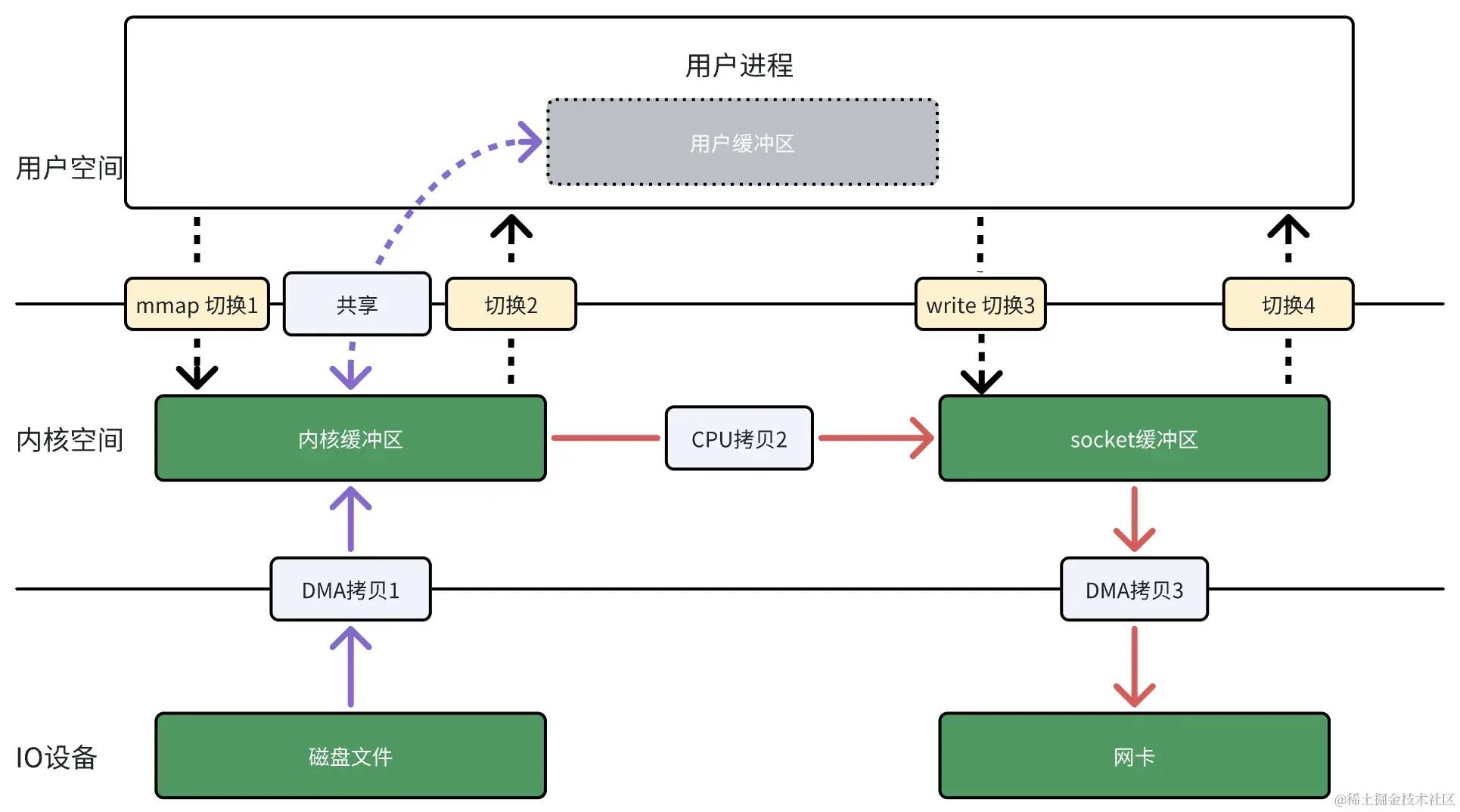
图3 mmap + write
具体过程如下:
- 应用进程调用
mmap后,DMA 会把磁盘的数据拷贝到内核缓冲区里。接着,应用进程和内核共享这个缓冲区。 - 应用进程再调用
write,操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核空间,由 CPU 来搬运数据。 - 最后,通过 DMA 把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里。
因此,通过用 mmap来代替 read, 可以减少 1 次数据拷贝的过程。
但这还不是最理想的,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且系统调用还是 2 次,仍然需要 4 次上下文切换。
3.2.2 sendfile
Linux 提供了一个专门发送文件到网络的系统调用函数 sendfile,函数形式如下:
#include <sys/socket.h>ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);首先,它可以替代前面的 read 和 write 这两个系统调用,这样就可以减少 1 次系统调用,也就减少了 2 次内核空间和用户空间切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次内核空间和用户空间切换、3 次数据拷贝。
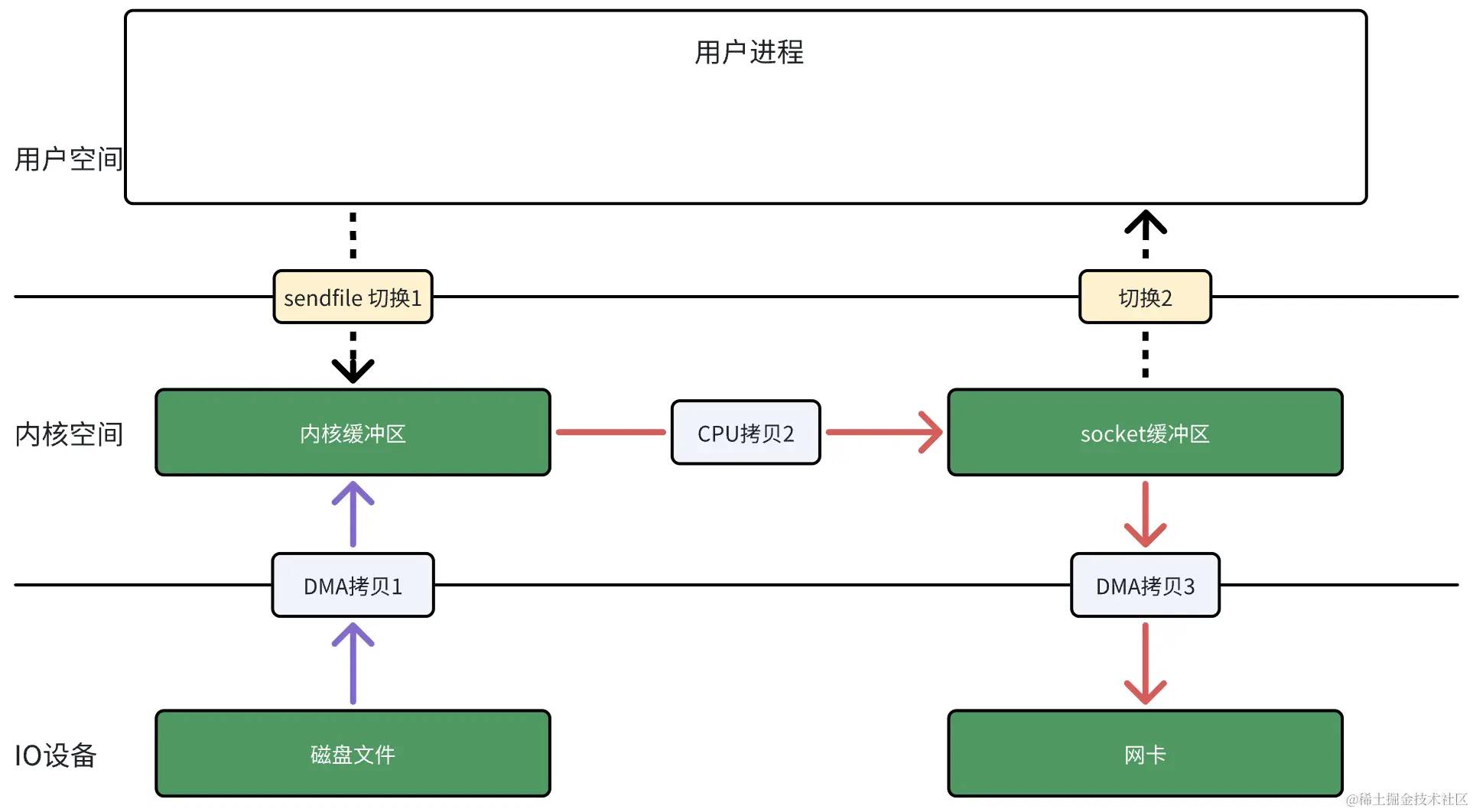
图4 sendfile
图4这个过程已经是一般语境下大家常说的“零拷贝”:在内存层面没有在用户空间到内核空间的拷贝,但是由于仍然有内存拷贝,所以这还不是彻底的零拷贝。
3.2.3 sendfile + SG-DMA
如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access),可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
$ ethtool -k eth0 | grep scatter-gatherscatter-gather: on于是,从 Linux 内核 2.4 版本开始起,对于网卡支持 SG-DMA 的情况( SG-DMA 需要硬件和操作系统同时支持), sendfile 系统调用的过程得到了进一步改善,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓冲区中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从内核缓冲区拷贝到 socket 缓冲区,又减少了 1 次数据拷贝。
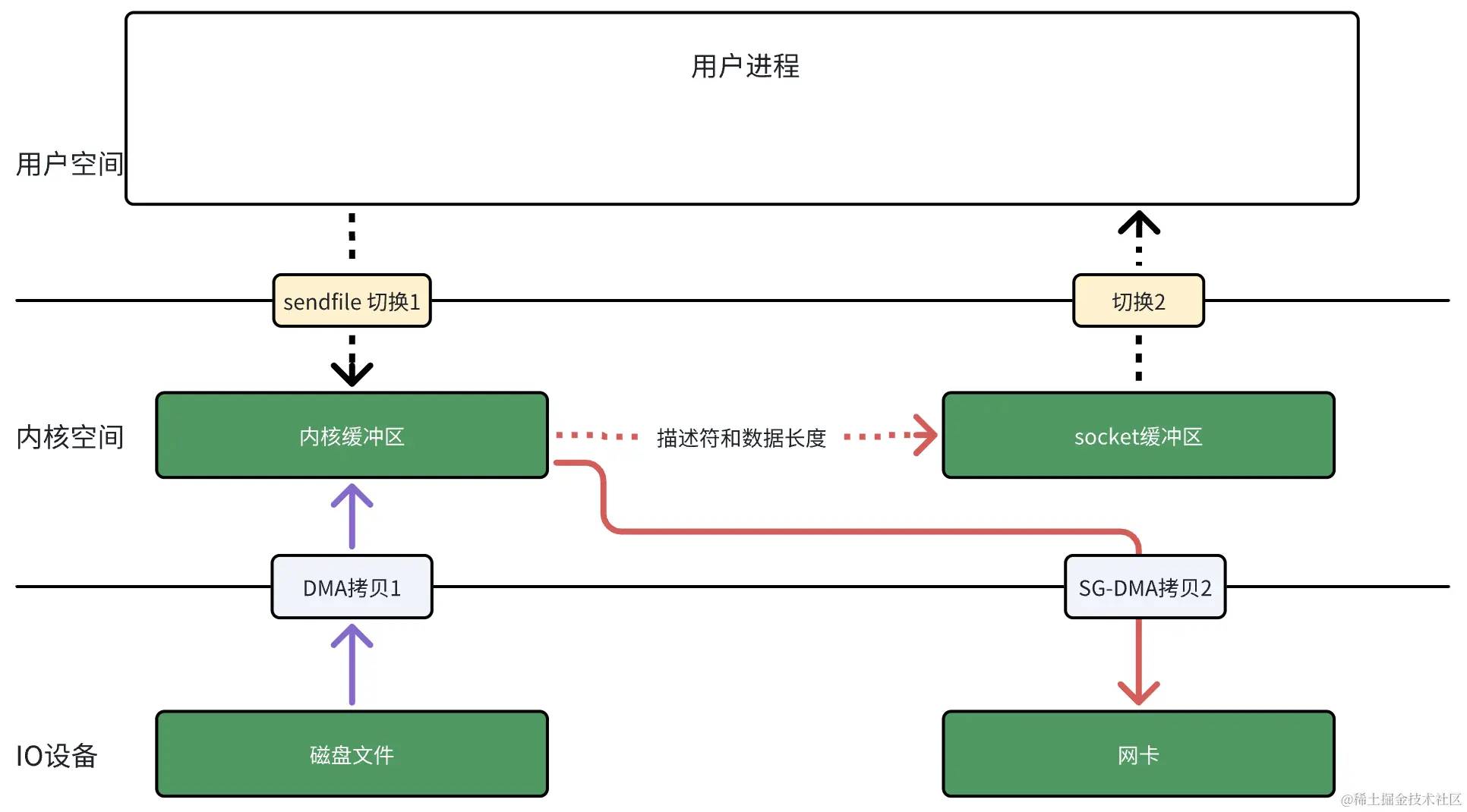
图5 支持 SG-DMA 情况下的sendfile
图5是真正的零拷贝,不仅全程没有通过 CPU 来拷贝数据,而且没有在内存间相互拷贝数据 。
图5相对于图1,对比如下:
优势
- 内核空间和用户空间切换次数降低 50%,4 次 -> 2 次。
- 数据拷贝次数降低 50%,4 次 -> 2 次,而且 2 次数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运,降低了 CPU 负载。
劣势
- 在每次的响应过程中,无法在用户空间对从磁盘文件读取的数据进行处理。
以上优势比较明显,且劣势可以通过其他方式解决,比如:校验–新开协程专门进行异步的 CRC 校验,不必每次发送前进行文件数据的校验。
总结上面几种情况下的 IO 流程,其对比如下:
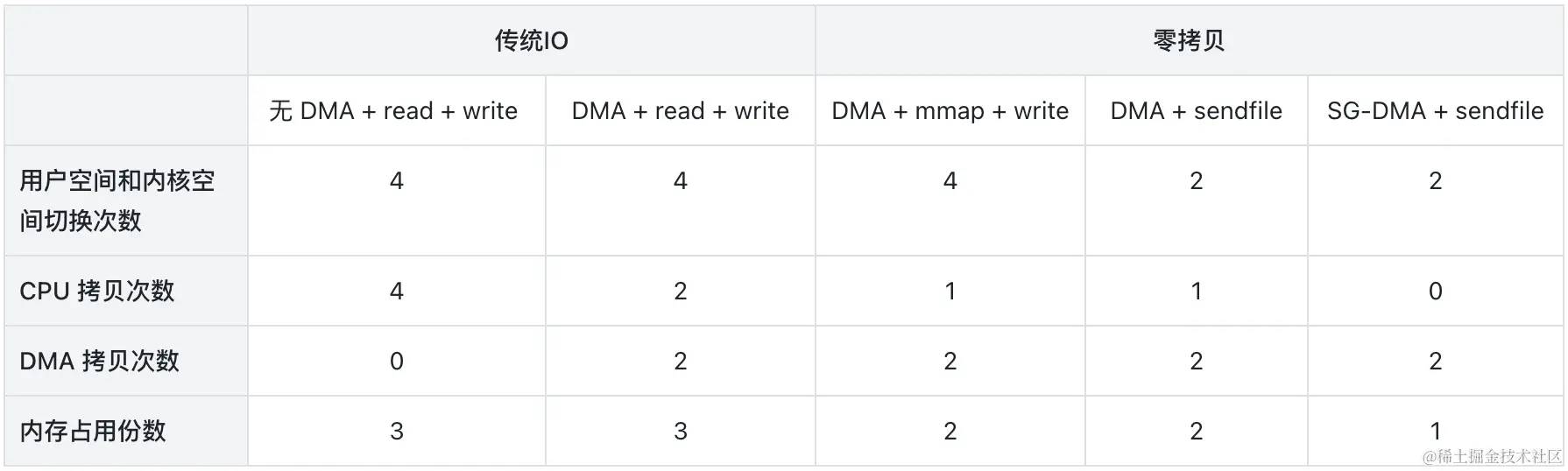
4. Golang-零拷贝实现
超边缘缓存服务器的 ARCH、OS 通常不是统一的,存在较大的异构性,在选择编程语言时需要兼顾使用的流行程度、高性能、易编程、支持跨平台,综合考虑后选择 Golang。
调用sendfile需要获取到发送文件的fd和socket fd,但是在使用Golang封装好的http.Server中获取底层的 socket fd 很麻烦,不过,在http.Handler中调用func CopyN(dst Writer, src Reader, n int64) (written int64, err error) ,能够默认调用系统调用sendfile或者splice。函数调用流程如下代码所示:
以下代码只展示与零拷贝调用流程相关的关键部分,其它用 … 代表省略。以 Go1.21.8 版本为准。
io.CopyN(http.ResponseWriter, *os.File, n)func CopyN(dst Writer, src Reader, n int64) (written int64, err error) { written, err = Copy(dst, LimitReader(src, n)) if written == n { return n, nil } ...}func Copy(dst Writer, src Reader) (written int64, err error) { return copyBuffer(dst, src, nil)}func CopyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) { if buf != nil && len(buf) == 0 { panic("empty buffer in CopyBuffer") } return copyBuffer(dst, src, buf)}func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) { if wt, ok := src.(WriterTo); ok { return wt.WriteTo(dst) } if rt, ok := dst.(ReaderFrom); ok { return rt.ReadFrom(src) } ...}type response struct { conn *conn ...}func (w *response) ReadFrom(src io.Reader) (n int64, err error) { ... rf, ok := w.conn.rwc.(io.ReaderFrom) if !ok { return io.CopyBuffer(writerOnly{w}, src, buf) } ... return n, err}type conn struct { ... rwc net.Conn ...}type TCPConn struct { conn }func (c *TCPConn) ReadFrom(r io.Reader) (int64, error) { ... n, err := c.readFrom(r) ... return n, err}func (c *TCPConn) readFrom(r io.Reader) (int64, error) { if n, err, handled := splice(c.fd, r); handled { return n, err } if n, err, handled := sendFile(c.fd, r); handled { return n, err } return genericReadFrom(c, r)}func splice(c *netFD, r io.Reader) (written int64, err error, handled bool) { ... var s *netFD if tc, ok := r.(*TCPConn); ok { s = tc.fd } else if uc, ok := r.(*UnixConn); ok { if uc.fd.net != "unix" { return 0, nil, false } s = uc.fd } else { return 0, nil, false } written, handled, sc, err := poll.Splice(&c.pfd, &s.pfd, remain) if lr != nil { lr.N -= written } return written, wrapSyscallError(sc, err), handled}func sendFile(c *netFD, r io.Reader) (written int64, err error, handled bool) { var remain int64 = 1<<63 - 1 lr, ok := r.(*io.LimitedReader) if ok { remain, r = lr.N, lr.R if remain <= 0 { return 0, nil, true } } f, ok := r.(*os.File) if !ok { return 0, nil, false } sc, err := f.SyscallConn() if err != nil { return 0, nil, false } var werr error err = sc.Read(func(fd uintptr) bool { written, werr, handled = poll.SendFile(&c.pfd, int(fd), remain) return true }) ... return written, wrapSyscallError("sendfile", err), handled}func SendFile(dstFD *FD, src int, remain int64) (int64, error, bool) { ... dst := dstFD.Sysfd var ( written int64 err error handled = true ) for remain > 0 { n := maxSendfileSize if int64(n) > remain { n = int(remain) } n, err1 := syscall.Sendfile(dst, src, nil, n) ... } return written, err, handled}5. 业务实践
零拷贝功能在字节几千台超边缘缓存服务器上线后,为点播、下载业务提供了 Tb 级别带宽的传输服务,内存、CPU、服务端发送速度均有很大的优化。
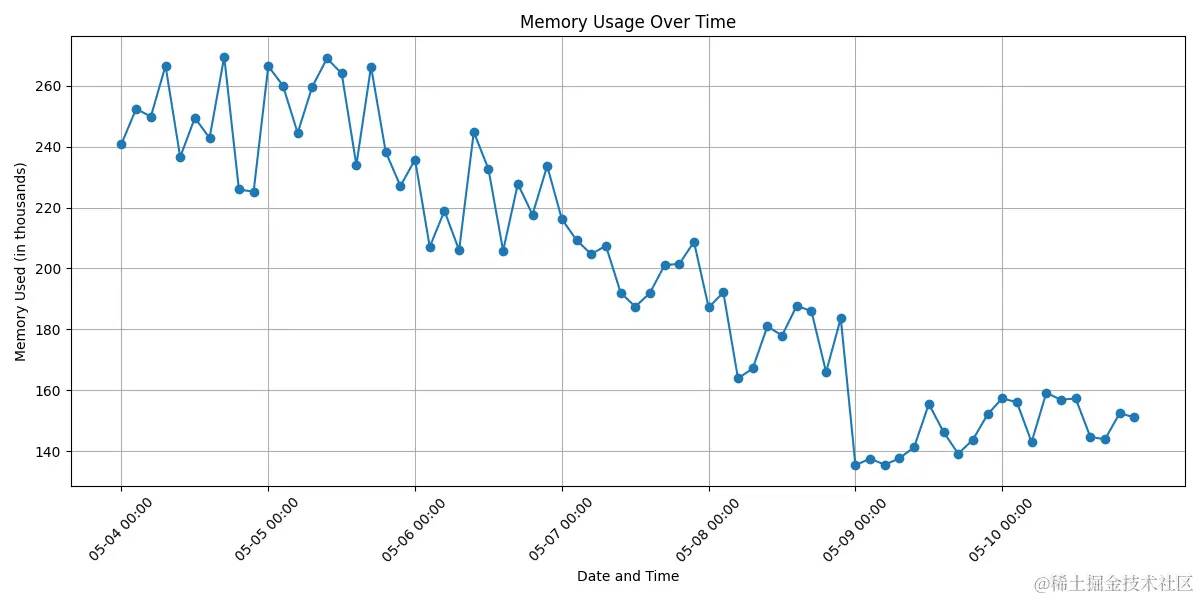
图6 已用内存的优化效果
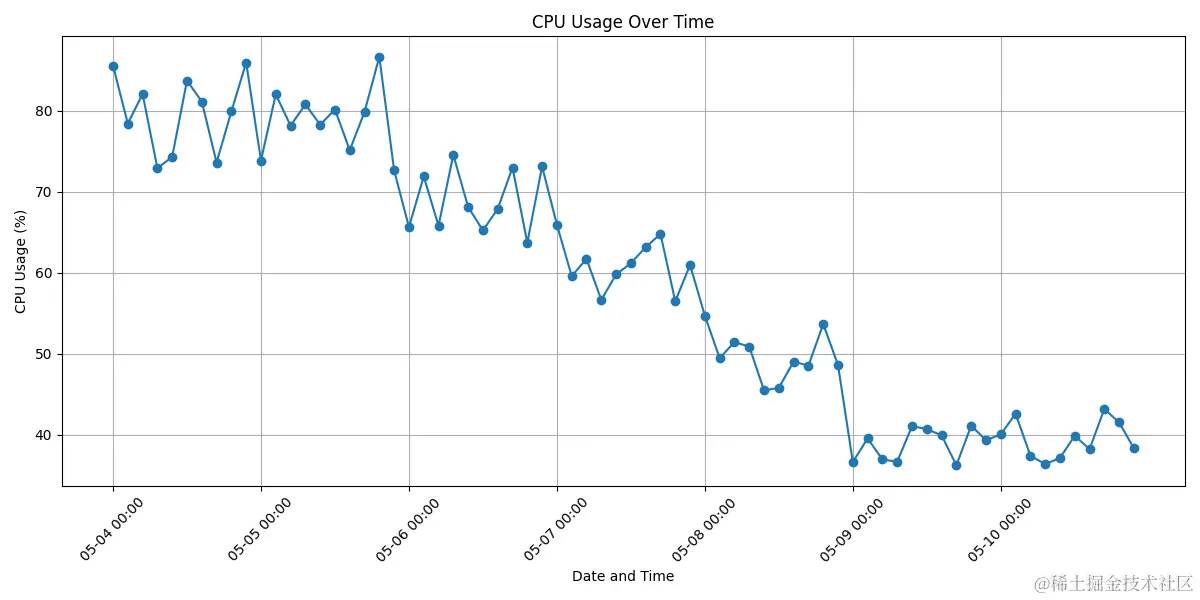
图7 CPU 使用率的优化效果
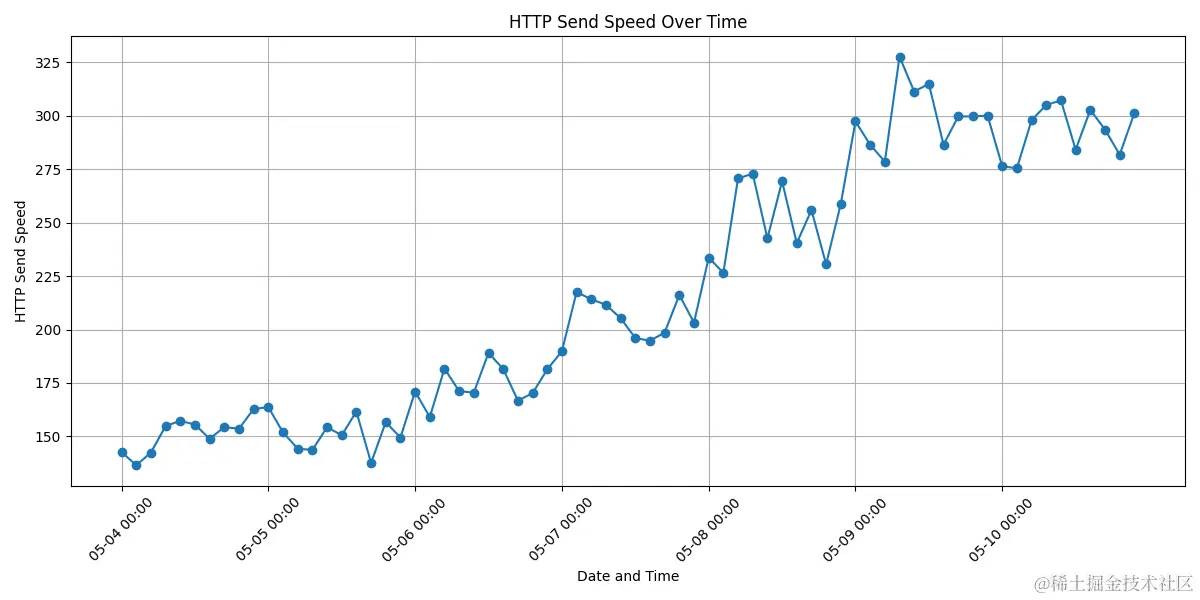
图8 服务发送速度的优化效果
6. 未来展望
6.1 技术沉淀
未来会整理 Golang 零拷贝技术相关的函数使用,支持磁盘文件fd到socket-fd,也支持socket-fd到socket-fd两种情况下的零拷贝,减少业务在使用上的负担,比如使用 Golang 原生http.Server作为网络服务器时,难以获取到底层请求的socket-fd,以及ResponseWriter中实际的socket-fd,这个库将帮助大家解决这些繁琐而重要的问题。
6.2 KTLS
目前 Golang io.CopyN无法对数据进行 TLS 加密,如果要使用 TLS (比如 HTTPS),必须将数据拷贝到应用层进行TLS 加密,然后再发送出去。不过,Linux 已经支持 kernel TLS,不需要将数据拷贝到应用层也可进行TLS加解密,由内核完成加解密后直接交给TCP stack发送出去。Golang crypto/tls 目前不支持 kernel TLS,可以在同机上部署NGINX,NGINX 已经支持ssl_sendfile调用 kernel TLS,可以实现 HTTPS 的零拷贝转发。
Golang 团队大约每一两周会讨论社区提出的建议,并给出是否接纳建议的结论,其中 Golang 支持 KTLS 的建议已经被提出好几年了,一直没有什么实际进展,不过2024年05月又开始被 Golang 团队关注到,被加入到了每周的讨论列表中,敬请期待!
7. 附录
Golang-KTLS 提议:github.com/golang/go/i…
Golang 每周讨论提议的会议记录:github.com/golang/go/i…
Linux kernel TLS offload:docs.kernel.org/networking/…