
包阅导读总结
1. 端到端自动驾驶、知识蒸馏、性能提升、北京理工大学、PlanKD
2. 北京理工大学计算机学院团队在 CVPR 2024 入选论文中提出新的知识蒸馏框架 PlanKD,使端到端自动驾驶系统性能提升一倍左右,且不牺牲可靠性和增加成本,为车端大模型部署提供解决方案。
3.
– 问题提出
– 自动驾驶技术体系流行端到端,但 Transformer 架构的大模型参数量大,车端部署存在性能和成本的矛盾。
– 解决方案
– 北理工团队提出知识蒸馏框架 PlanKD。
– 设计基于信息瓶颈策略的规划相关信息蒸馏器,提取规划相关信息。
– 给出以安全为考虑的路径点知识蒸馏方法,引入熵损失确保注意力权重分布平滑。
– 实验结果
– 相同参数量模型使用 PlanKD 后性能大幅提升,碰撞和违章率下降,推理时间减少。
– 论文具有重要意义,提供了车端大模型部署方案等。
– 论文地址:https://arxiv.org/abs/2403.01238
思维导图: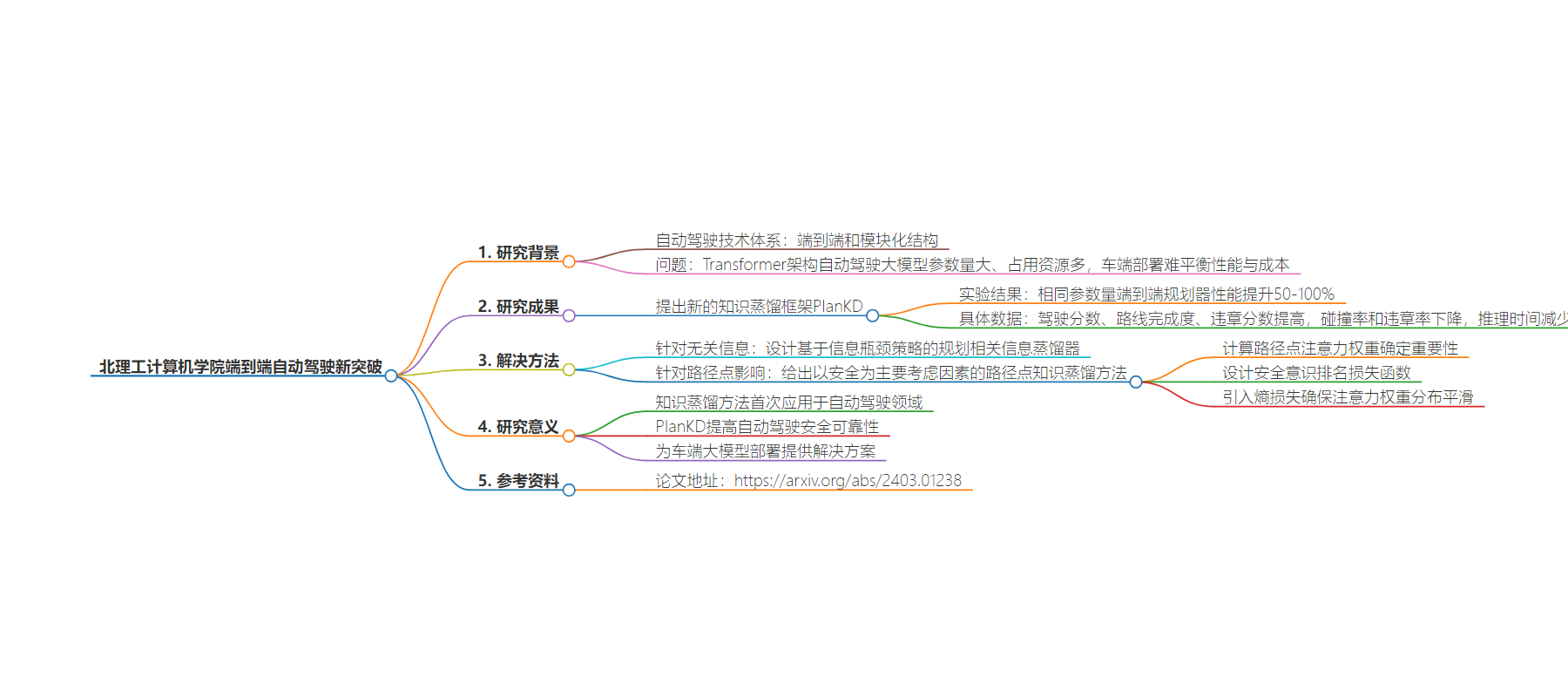
文章地址:https://www.qbitai.com/2024/07/169918.html
文章来源:qbitai.com
作者:贾浩楠
发布时间:2024/7/23 4:43
语言:中文
总字数:2062字
预计阅读时间:9分钟
评分:78分
标签:自动驾驶,知识蒸馏,端到端系统,PlanKD,性能优化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
端到端新突破:「蒸馏」一下性能提升100%!北理工计算机学院出品
 贾浩楠2024-07-2312:43:04 来源:量子位
贾浩楠2024-07-2312:43:04 来源:量子位 贾浩楠 发自 副驾寺智能车参考 | 公众号 AI4Auto
既省资源,又提升效率的不可能任务,真能在端到端自动驾驶上实现!
今年计算机顶会CVPR 2024入选论文中,来自北京理工大学计算机学院团队,拿出了一项“全球首次”的成果:
“蒸馏”一下,端到端自动驾驶系统性能,直接提升一倍左右。
而且这样的提升,完全不以牺牲系统可靠性或增加成本为代价。
就是既要又要。
解决了什么问题
自动驾驶技术体系,现在流行端到端,以前则是模块化的结构。但无论是哪种,其实之前一直有这么一个问题没解决:
Transformer架构为基础的自动驾驶大模型,参数量大,占用计算资源多,部署在资源有限的车端,其实并不是最佳方案。
如果要保证性能,车端计算成本就要增加,而且输出结果的时间也会变长;如果要保证成本和敏捷性,又不得不削减模型规模,导致性能下降。
北京理工大学计算机学院团队提出了一种新的知识蒸馏框架——PlanKD,业内首次实现了端到端规划器在保持较小体量的同时,性能不打折扣:
实验结果中可以看出,相同参数量的端到端规划器,使用PlanKD后性能(驾驶分数)有50-100%的提升。
更详细的实验结果如下:
采用一个52.9Million参数的大模型最为“老师”,带着几个不同规模的“学生”模型,并采用这3个主要的数据作为标准:驾驶分数,路线完成度、违章分数。
实验的基础条件,首先是著名的自动驾驶开源仿真平台CARLA,由英特尔和丰田联合开发,提供基于真实城镇构建的仿真环境和各种不同类型的气候条件,NOA开发必备的工具,也是目前端到端唯一测试平台。
端到端自动驾驶基础模型,使用的是2023年由商汤科技一作提出的InterFuser,一个以Transformer为主要架构的多模态模型。当时InterFuser在CARLA公开排行榜是No.1的水平。
关于商汤多模态大模型和端到端自动驾驶的新进展,智能车参考详细介绍过。
实验的硬件条件,是一块英伟达RTX 3090 GPU。
研发团队在8个不同模拟城镇中分别采用21种不同的天气条件模拟(7个用来训练算法,1个用来测试)。
结果显示,同样参数的InterFuser模型,在有PlanKD的情况下,驾驶分数分平均提高60-100%;路线完成度提升20%左右;违章分数提升25%左右。
同时,碰撞率和违章率都下降了10-60%不等。
以及和规模巨大的“老师”模型比起来,有PlanKD加持的小规模模型,推理时间大大减少。
什么样的方法解决问题
自动驾驶发展这么多年,各种思路、技术、路线层出不穷,但业内专家都会告诉你,自动驾驶干的其实就是一条线:
车辆轨迹的规划路线,各位老司机在使用智驾的过程中肯定深有体会:只要屏幕上的这条线能“甩”过去,那么极大概率就能顺利通过场景,反之就需要人为接管了。
规划的过程,包括了感知、识别、预测等等环节在里面。
北理计算机学院团队的PlanKD,本质是一个“蒸馏器”,把大模型的能力、知识转移给小模型,提高相应性能。
知识蒸馏本身其实是深度学习领域内被广泛应用的方法,但之前从来没应用在端到端自动驾驶上,因为驾驶任务本身具有特殊性。
首先是传感器采集的场景信息中,有大量和驾驶行为本身无关的信息,如果把这些信息也转移给小模型,反而会降低性能。
其次, 输出规划轨迹中的不同路径点,可能对运动规划具有不同程度的重要性,而在某些关键路径点上的轻微偏差可能会导致严重后果。
知识蒸馏改善端到端性能、成本,本身具有很大的潜力,但真的“上车”,主要就得解决上面两个问题。
针对场景中的无关信息,团队设计了一种基于信息瓶颈策略的规划相关信息蒸馏器,只提取与规划相关的信息,而不是不加区别地传输所有信息:
所谓信息瓶颈本质是一种学习方式,在学习一种场景特征时,既能最大限度地降低这个特征与输入之间的相关性,同时最大化它与特定类别之间的相关性。
具体到端到端规划任务上,团队采取的是最小化某一关键特征征与其他中间特征之间的相关性,同时最大化该特征与规划所需的基本事实之间相关性,来推导出重要且必要的规划信息:
其中β是拉格朗日乘数,I(x,x)是相关性,M则是为规划状态数量。Z是学习到的与规划相关的关键特征。
H 和 Yi 分别是第 i 个规划状态的中间特征图和真值的随机变量
对于不同路径点对规划的影响,团队给出了一种以安全为主要考虑因素的路径点知识蒸馏方法:
首先考虑到每个路径点的重要性与驾驶场景的上下文有关,所以需要计算 BEV 场景图像与轨迹中每个路径点之间的注意力权重来确定其重要性。
其次为了提高注意力权重对安全关键情况的意识,还设计了一种安全意识排名损失函数。
获得注意力权重后,将其纳入路径点安全意识损失函数中,用于蒸馏,具体如下:
此外,为了避免学生模型过分专注于重要的路径点而忽略其他路径点,还引入熵损失,以确保更平滑的注意力权重分布。
具体思路就是这样。
这篇CVPR 2024顶会论文的意义其实可以这么理解:
知识蒸馏方法首次“上车”,应用在自动驾驶领域;
PlanKD本身能提高自动驾驶安全可靠性;
为资源有限的车端大模型部署提供了一个解决方案。
论文地址:https://arxiv.org/abs/2403.01238
版权所有,未经授权不得以任何形式转载及使用,违者必究。