
包阅导读总结
思维导图:
文章地址:https://mp.weixin.qq.com/s/uyiVl4PrZ6nWvD7rTddCSQ
文章来源:mp.weixin.qq.com
作者:LLM??SPACE
发布时间:2024/7/30 13:39
语言:中文
总字数:2833字
预计阅读时间:12分钟
评分:86分
标签:大模型,AI研究,时间序列预测,可解释AI,图神经网络
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
我们希望能够搭建一个AI学习社群,让大家能够学习到最前沿的知识,大家共建一个更好的社区生态。
https://www.feishu.cn/community/article/wiki?id=7355065047338450972
点击「订阅社区精选」,即可在飞书每日收到《大模型日报》每日最新推送
如果想和我们空间站日报读者和创作团队有更多交流,欢迎扫码。
欢迎大家一起交流!

论文
Survey and Taxonomy:数据中心智能在基于Transformer的时间序列预测中的作用
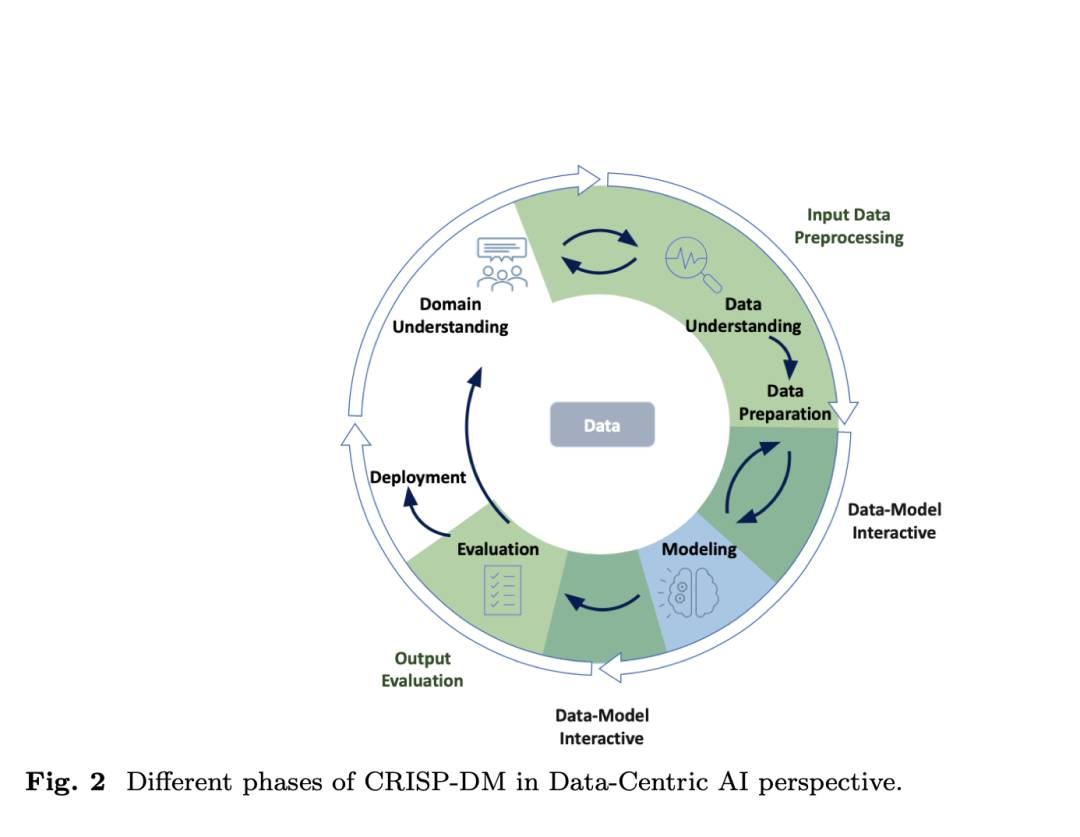 http://arxiv.org/abs/2407.19784v1
http://arxiv.org/abs/2407.19784v1BEExAI:评估Explainable AI的基准
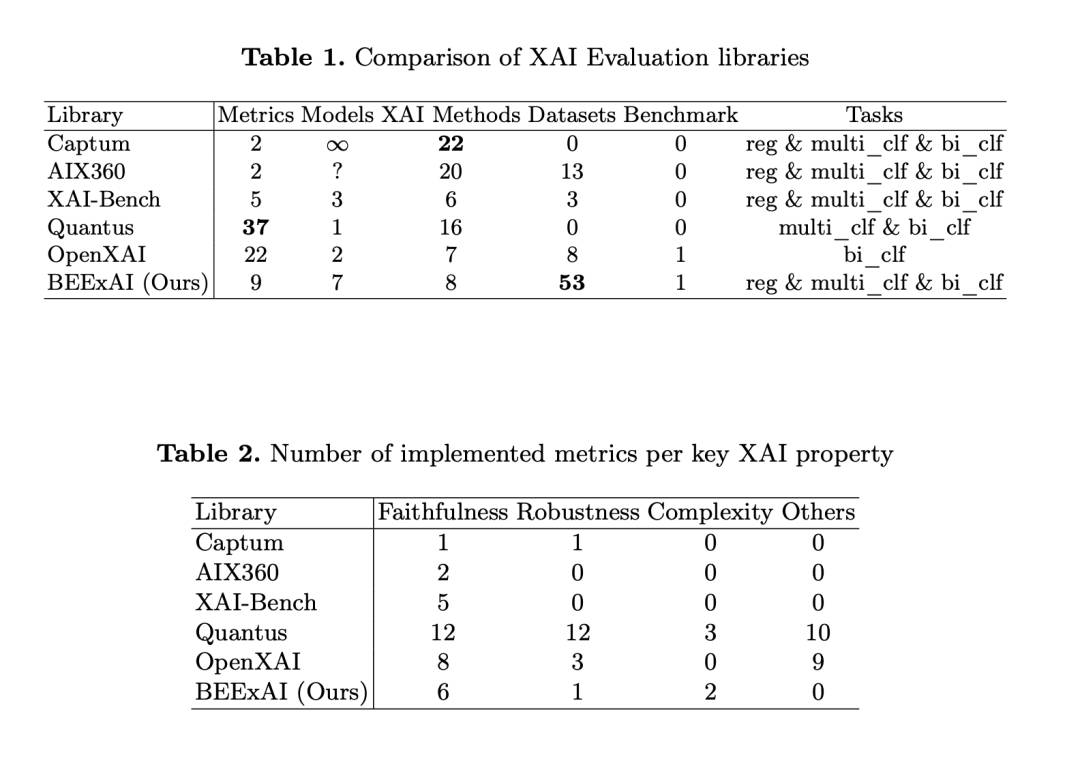 http://arxiv.org/abs/2407.19897v1
http://arxiv.org/abs/2407.19897v1xAI-Drop: 不使用无法解释的内容
 http://arxiv.org/abs/2407.20067v1
http://arxiv.org/abs/2407.20067v1Unknown Cluster Number的非结构化数据中的自适应自监督鲁棒聚类
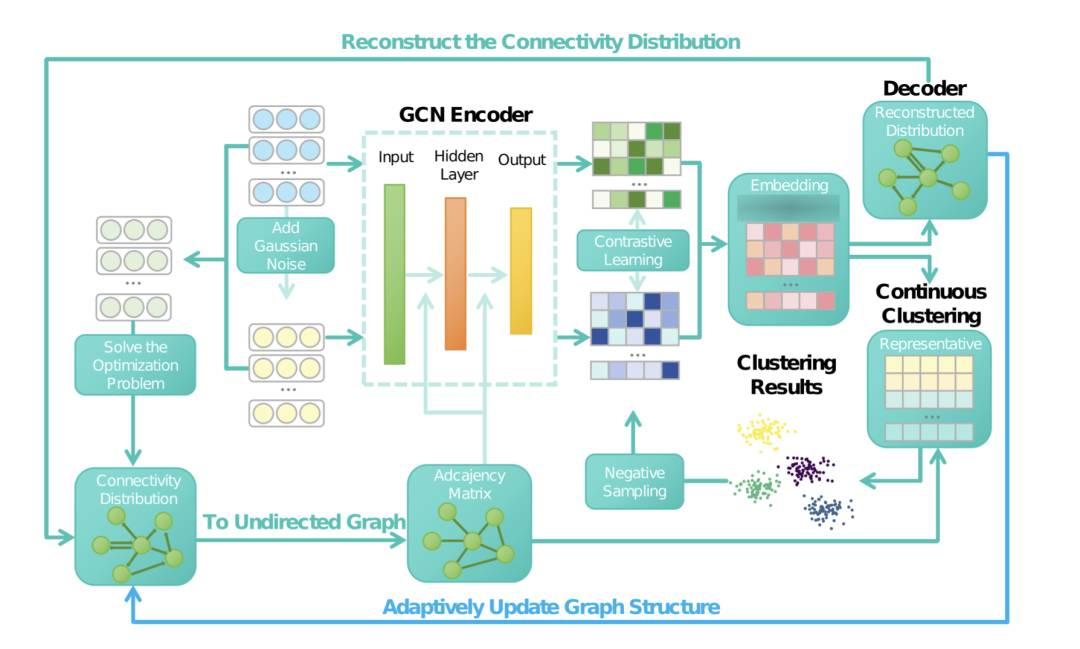 http://arxiv.org/abs/2407.20119v1
http://arxiv.org/abs/2407.20119v1使用LLMs生成易读内容的探索
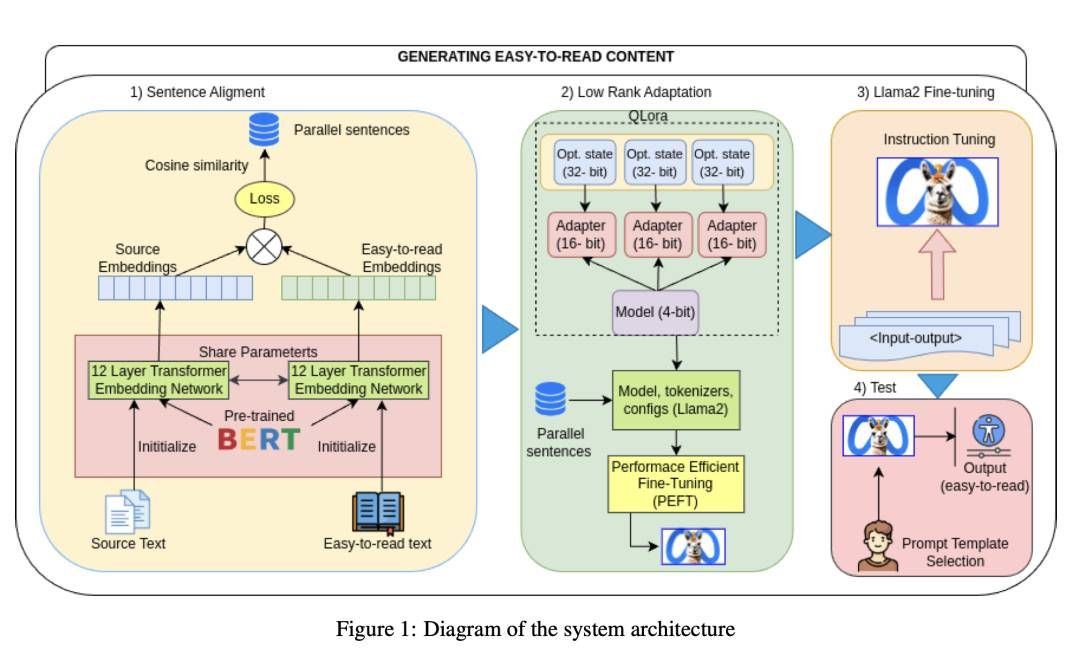 http://arxiv.org/abs/2407.20046v1
http://arxiv.org/abs/2407.20046v1利用“stairs”辅助greedy 生成加速大语言模型推理
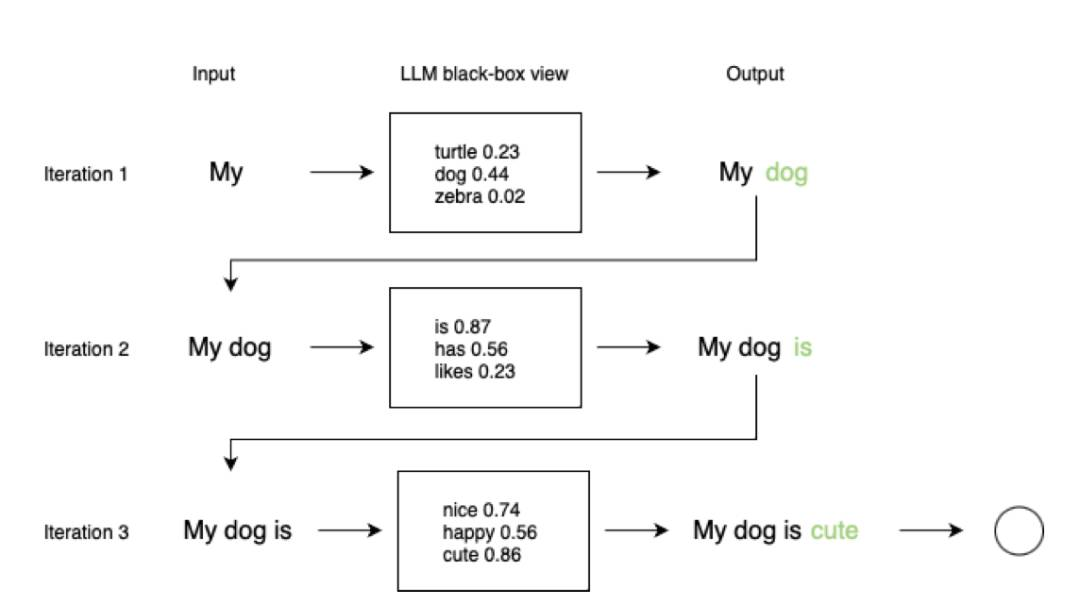 http://arxiv.org/abs/2407.19947v1
http://arxiv.org/abs/2407.19947v1Meta-Rewarding Language Models::LLM-as-a-Meta-Judge的自我改进对齐
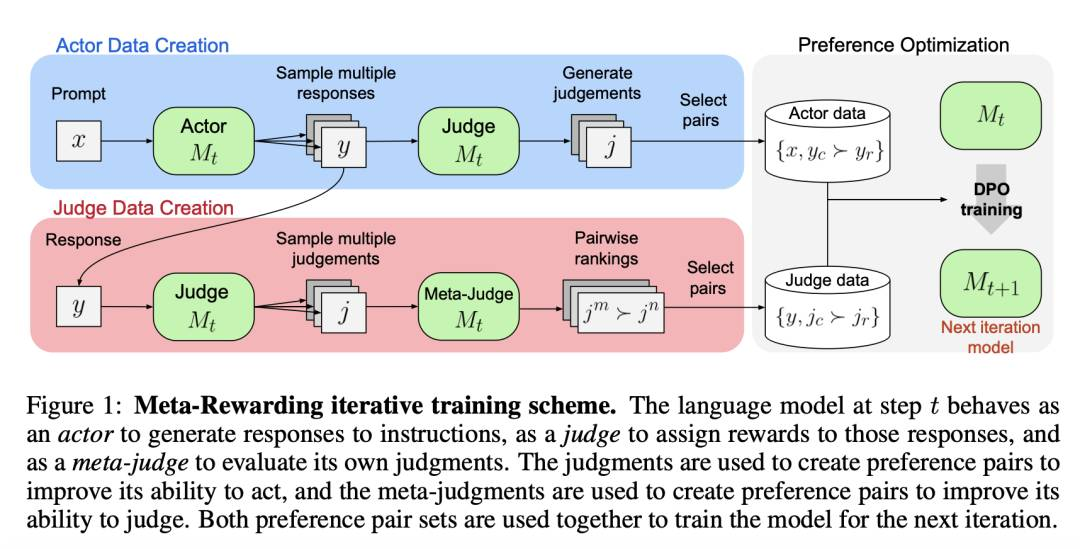 http://arxiv.org/abs/2407.19594v1
http://arxiv.org/abs/2407.19594v1Wren Engine
 https://github.com/Canner/wren-engine
https://github.com/Canner/wren-engineTable LLM
-
— END —