
包阅导读总结
1. `Llama3.1`、`OpenBuddy`、`跨语言模型`、`中文能力`、`模型训练`
2. 本文主要介绍了 OpenBuddy 发布的基于 Llama3.1 的新一代跨语言模型,包括 Llama3.1 的开源新进展及优势,Llama3.1-8B-Instruct 的训练与提升,以及 OpenBuddy 在此基础上增强中文能力的尝试,同时指出当前模型存在的局限和未来的训练计划。
3.
– Llama3.1 模型
– 7 月 23 日 Meta 发布,405B 参数版本性能刷新上限,许可协议修改。
– 8B、70B 模型 3.1 增强版本在数据集、训练方法等方向增强。
– Llama3.1-8B-Instruct 模型
– 基于 8 种语言训练,支持多种语言,借助长文扩容技术,知识截止到 2023 年 12 月。
– 用 405B 模型合成数据提升小模型能力,在认知、推理能力测试中成绩佳。
– OpenBuddy-Llama3.1-8B-v22.1 模型
– 半天训练增强中文能力,能中文问答和跨语言翻译。
– 仍存在中文知识幻觉,未来计划大规模训练和探索微调 405B 模型。
思维导图: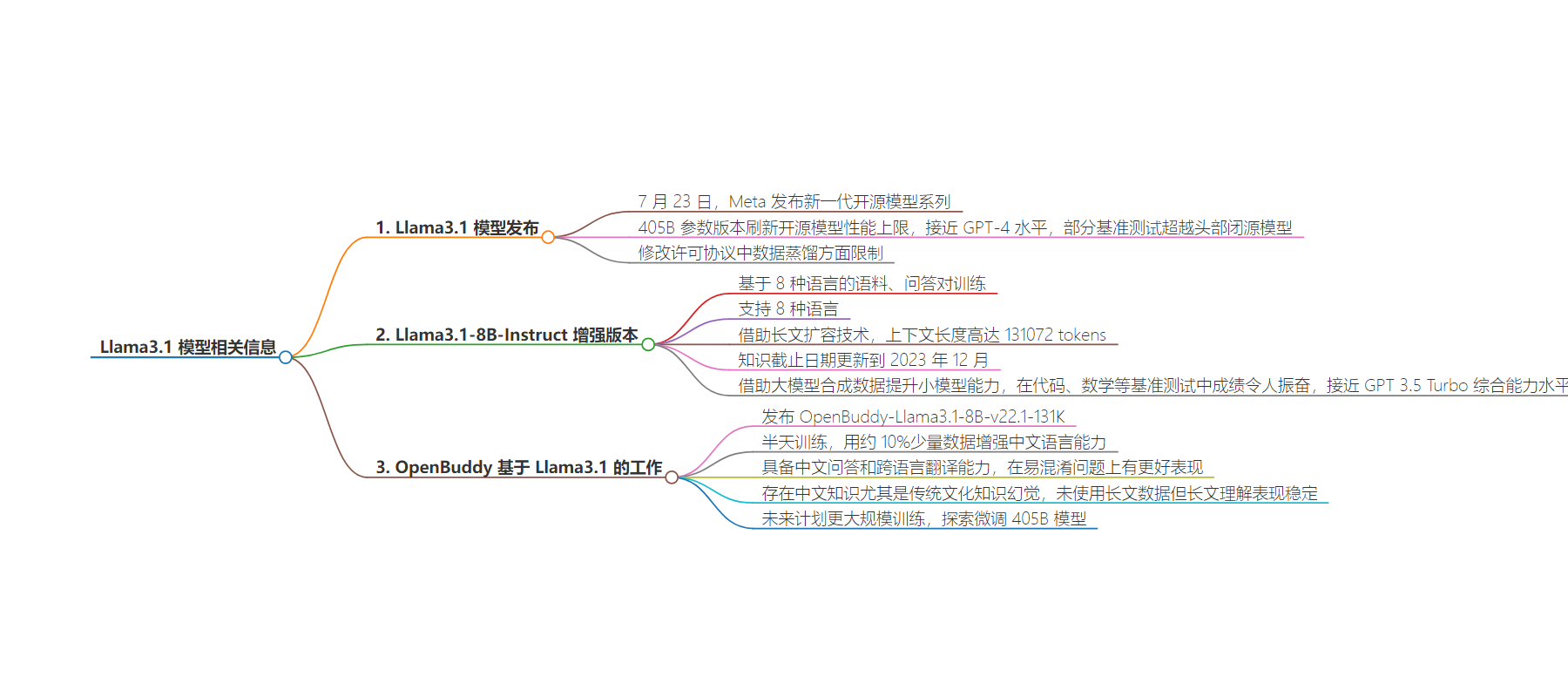
文章地址:https://mp.weixin.qq.com/s/WYFRzfmLsZwfI9bYbCzrkg
文章来源:mp.weixin.qq.com
作者:44670
发布时间:2024/7/24 13:12
语言:中文
总字数:1681字
预计阅读时间:7分钟
评分:90分
标签:Llama3.1,OpenBuddy,跨语言模型,中文增强,认知推理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
本次发布我们在Llama3.1上首个工作:OpenBuddy-Llama3.1-8B-v22.1-131K。
Llama3.1:开源模型的新里程碑
7月23日,Meta发布了新一代开源模型系列:Llama3.1。其中405B参数的版本刷新了开源模型性能的上限,在多种指标上的测试成绩接近GPT-4等闭源模型的水平,甚至在部分基准测试中展现出来了超越头部闭源模型的潜力。
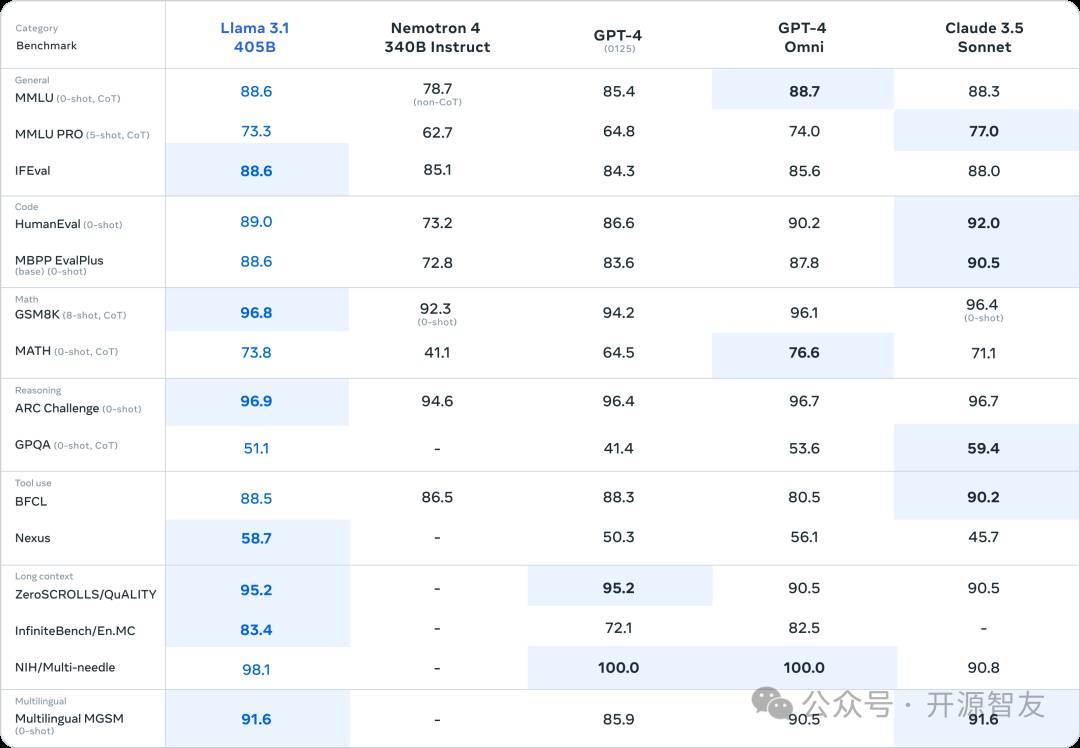
同时,Meta在本次发布时修改了许可协议中对数据蒸馏方面的限制,允许开发者使用Llama3.1-405B模型的输出训练其它模型。
Llama3.1-8B-Instruct:利用合成数据增强小模型
除了模型尺寸的提升之外,Meta还尝试了在数据集构成、训练方法、 位置编码缩放等方向上增强模型的综合能力,并于同日发布了8B、70B模型的3.1增强版本。
Llama3.1-8B-Instruct基于8种语言的语料、问答对进行训练,支持英语、德语、法语、意大利语、葡萄牙语、西班牙语、印地语和泰语。借助特有的长文扩容技术,其上下文长度高达131072tokens。模型训练集中的知识截止日期更新到了2023年12月,和上个版本相比具备更新的知识储备。
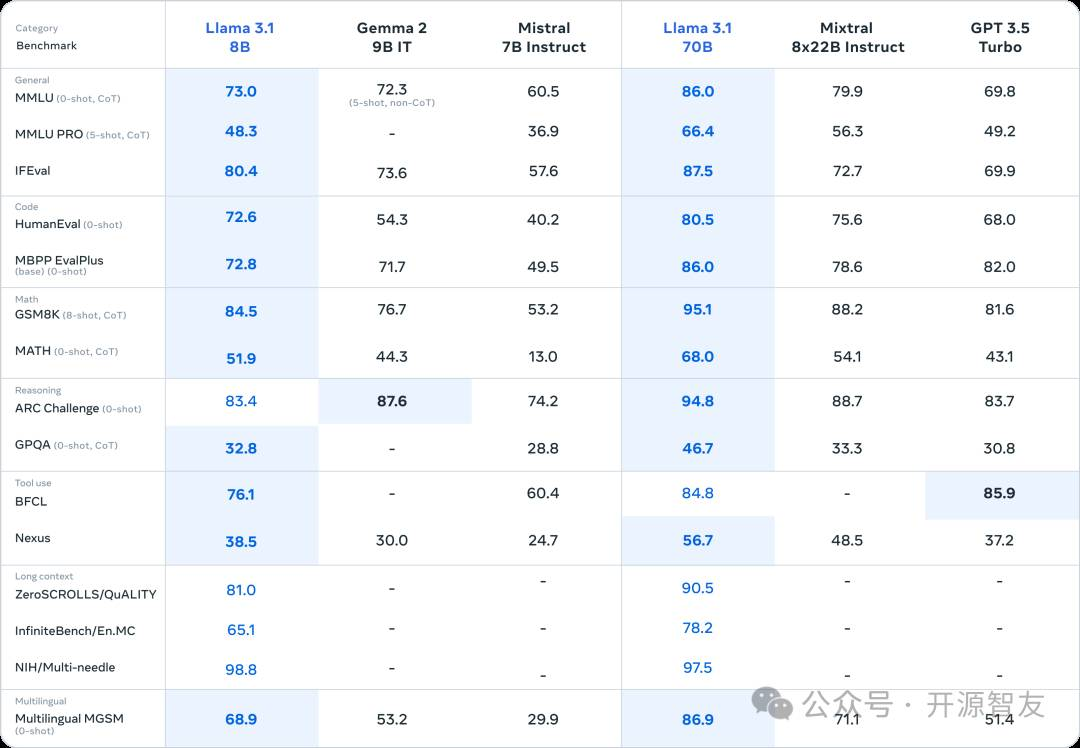
除了语言、长文、时效性方面的提升外,Meta尝试了借助405B模型等大模型合成数据,并用合成数据提升小模型的能力的路线。在后期训练中,Meta使用了超过2500万条合成数据,使8B小模型的能力得到进一步提升。
在代码、数学等测试模型的认知、推理能力的基准中,Llama3.1-8B-Instruct取得了令人振奋的成绩,具备和GPT 3.5 Turbo相接近的综合能力水平:
OpenBuddy-Llama3.1-8B-v22.1:新一代开源跨语言模型
尽管Llama3.1仍然不具备中文能力,但模型已经在8种语言上得到了充分的训练,具备一定的跨语言潜力。本次时长约为半天的训练过程中,我们尝试使用了约10%的少量数据,在Llama3.1-8B-Instruct的基础上进行以增强中文语言能力为主要目标的训练过程。
经过少量数据训练后,模型具备了中文问答和跨语言翻译能力。和上一代8B模型相比,本次发布的模型在一些容易产生概念混淆的问题上,能够输出通常只有更大模型才能生成的答案,具备更强的认知潜力。
Q: 为什么手机只有100/100的电啊,根本就不够用,建议以后手机都有200/200的电
A:手机电量显示为 100/100 的设计主要是为了向用户提供一个直观的电量剩余指示。这种设计简化了电量显示,使得用户可以快速了解当前的电量状况。然而,实际上,手机的电池容量并不是 100 单位,而是以毫瓦时(mAh)或瓦时(Wh)等单位来衡量,这意味着它们能够存储和释放电能的量。
欢迎点击“阅读原文”,访问我们在ModelScope中的项目页面,下载、体验我们的模型。
受训练数据集和训练时间的限制,本次发布的模型在中文知识,尤其是传统文化知识上仍存在幻觉。尽管本次训练过程中未使用长文数据,但得益于模型原本的长文能力,模型在长文理解等任务上具备相对稳定的表现。
未来,我们计划对8B和70B模型进行更大规模的训练,从而进一步增强模型的中文知识储备、长文能力和认知能力。同时,我们也正在探索微调405B模型的可能性,敬请期待。