
包阅导读总结
1.
“`
Qwen2-Math、数学模型、合成数据、准确率、指令微调
“`
2.
通义千问的 Qwen2-Math 开源,在 MATH 基准测评中准确率超其他模型。它用 Qwen2 大语言模型初始化,在专用语料库预训练,支持英文,即将有中英双语版。该模型可用于多种场景,能生成合成数据,解决数据相关问题,介绍了模型下载、推理及生成 json 文件的方法。
3.
– Qwen2-Math 开源及成绩
– 在 MATH 基准测评中准确率达 84%,超过多种开闭源模型
– Qwen2-Math 模型特点
– 基础模型用 Qwen2 初始化,在数学专用语料库预训练,数据去污染处理
– 训练了指令微调版本,包括奖励模型、结合信号构建监督微调数据、使用 GRPO 方法优化
– 模型语言支持及未来计划
– 目前主要支持英文,很快推出中英双语版,多语言版在开发
– 适用场景
– 如教育行业的 AI 教师、解题辅助、智能阅卷等,关注 AI teacher for LLM 场景
– 合成数据优势
– 解决真实数据获取难、结构化等问题,可用作数据增强、丰富数据集
– 模型下载和推理
– 介绍了模型下载、安装依赖和运行模型的方法
– 展示了生成带有结构提示的 json 文件的示例
思维导图:
文章地址:https://mp.weixin.qq.com/s/ZK3BqsyIq5B1U__kLs52Hg
文章来源:mp.weixin.qq.com
作者:魔搭开发者
发布时间:2024/8/9 8:04
语言:中文
总字数:2014字
预计阅读时间:9分钟
评分:92分
标签:数学模型,开源,合成数据生成,人工智能,AI模型
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
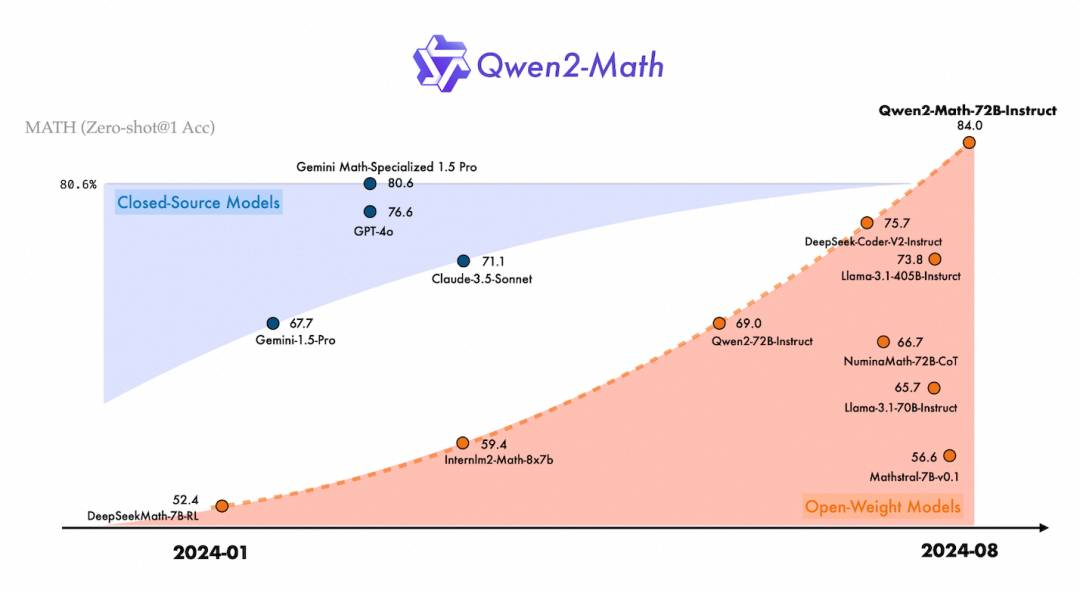
注:在MATH基准测评中,通义千问数学模型的旗舰款Qwen2-Math-72B-Instruct取得了84%的准确率,超过GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro 和 Llama-3.1-405B等开闭源模型。
Qwen2-Math 基础模型使用 Qwen2大语言模型进行初始化,并在精心设计的数学专用语料库上进行预训练,训练数据包含大规模高质量的数学网络文本、书籍、代码、考试题目,以及由 Qwen2 模型合成的数学预训练数据。所有预训练和微调数据集都进行了去污染处理。
随后,研发团队训练了指令微调版本模型:首先,基于Qwen2-Math-72B 训练一个数学专用的奖励模型;接着,将密集的奖励信号与指示模型是否正确回答问题的二元信号结合,用作学习标签,再通过拒绝采样构建监督微调(SFT)数据;最后在SFT模型基础上使用 GRPO 方法优化模型。
Qwen2-Math系列模型目前主要支持英文,通义团队很快就将推出中英双语版本,多语言版本也在开发中。
Qwen2-Math-72B-Instruct表现优异,在十大测评中都获得了远超其他开源数学模型的成绩。
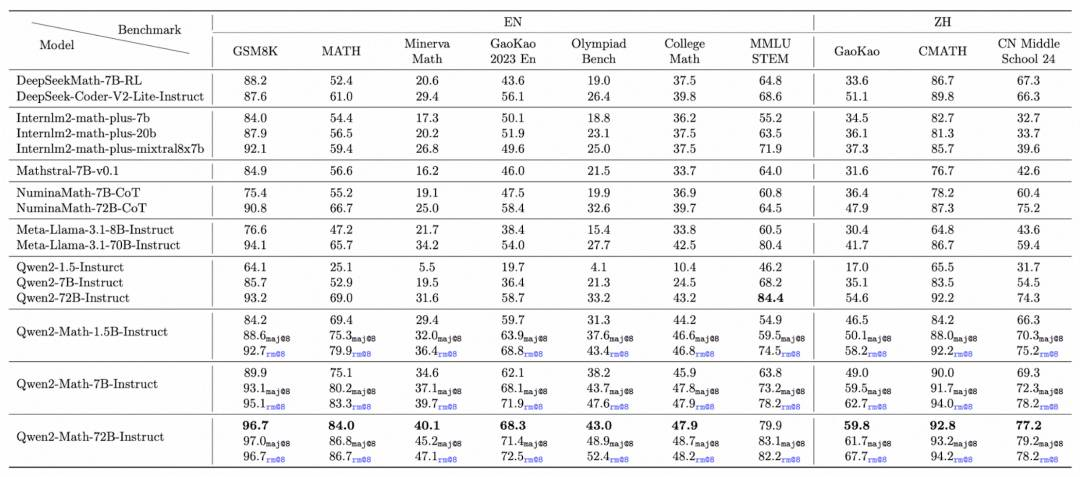
注:研发团队在greedy和RM@8 的条件下对模型作了测评,表中为每款Qwen2-Math-72B-Instruct模型列出了三个得分结果,分别是第1次回答得分(无下标数字)、8次回答中出现最多次数的答案的得分,8次回答中reward model所选答案的得分。
适用场景
数学模型可用在多种场景,比如教育行业的AI教师,解题辅助,智能阅卷等场景,本文更加关注在AI teacher for LLM场景,比如蒸馏,能否使用更强的专业模型为小模型生成高质量的数据,更便宜,更快速微调小模型,以提高性能和降低成本。
用例参考链接:https://cookbook.openai.com/examples/sdg1
合成数据优势
使用专业大语言模型生成合成数据可以为模型训练提供高质量、专业性高且符合隐私要求的数据。可以用在多种场景,比如生成专业数据,并SFT数据中混合,使大语言模型微调取得更好的结果、生成针对模型的数学能力的测试数据等。
合成数据可以解决如下问题:
1 真实数据可能因为隐私限制等,更加难以获取。
2 合成数据比真实数据结构化性更高,降低数据清洗成本。
3 在专业数据比较稀疏的情况下(如数学),合成数据可用作数据增强。
4 当训练数据中,配比不平衡,以及数据多样性不够是,通过合成数据来丰富数据集。
与传统的数据增强或手动数据创建方法不同,使用 LLM 可以生成丰富、细致入微且与上下文相关的数据集,从而显著增强其对企业和开发人员的实用性。
模型下载和推理
模型下载
modelscopedownload--model=qwen/Qwen2-Math-7B-Instruct--local_dir./Qwen2-Math-7B-Instruct
使用vLLM模型推理
python-mvllm.entrypoints.openai.api_server--served-model-nameQwen2-Math-7B-Instruct--model./Qwen2-Math-7B-Instruct/
安装依赖和运行模型
%pip install openai%pip install pandas%pip install scikit-learn%pip install matplotlib
from openai import OpenAIimport osimport jsonopenai_api_key = "EMPTY"openai_api_base = "http://localhost:8000/v1"client = OpenAI(api_key=openai_api_key,base_url=openai_api_base,)
生成带有结构提示的json文件
我们以最简单的方式创建数据。本文通过解决 3 个关键点来快速生成数据:告诉它数据的格式 (json)、架构以及有关列如何关联的有用信息(LLM 将能够从列名称中推断出这一点,但帮助会提高性能)。
datagen_model = "Qwen2-Math-7B-Instruct"question = """Create a json file with 3 rows of math data.Each row should include the following fields:- id (incrementing integer starting at 1)- elementary school Olympiad math problem- detailed solutions for the problemMake sure that the problem make sense (i.e. suit elementary school students, solution is step by step). Also only respond with the json."""response = client.chat.completions.create(model=datagen_model,messages=[{"role": "system", "content": "You are a helpful assistant designed to generate synthetic data."},{"role": "user", "content": question}])res = response.choices[0].message.contentprint(res)
```json[{"id": 1,"problem": "Find the sum of the first 100 even numbers.","solutions": ["To find the sum of the first 100 even numbers, we can use the formula for the sum of an arithmetic series. The first 100 even numbers form an arithmetic series where the first term \(a = 2\) and the common difference \(d = 2\). The sum \(S_n\) of the first \(n\) terms of an arithmetic series is given by \(S_n = \frac{n}{2} (2a + (n-1)d)\). Here, \(n = 100\), \(a = 2\), and \(d = 2\). Substituting these values in, we get","S_100 = \frac{100}{2} (2 \cdot 2 + (100-1) \cdot 2) = 50 (4 + 198) = 50 \cdot 202 = 10100."]},{"id": 2,"problem": "What is the smallest positive integer that is both a multiple of 7 and a multiple of 11?","solutions": ["To find the smallest positive integer that is both a multiple of 7 and a multiple of 11, we need to find the least common multiple (LCM) of 7 and 11. Since 7 and 11 are both prime numbers, their LCM is simply their product. Therefore, the LCM of 7 and 11 is \(7 \times 11 = 77\). So, the smallest positive integer that is both a multiple of 7 and a multiple of 11 is 77."]},{"id": 3,"problem": "If a square has a side length of 5 units, what is the area of the square?","solutions": ["The area \(A\) of a square with side length \(s\) is given by the formula \(A = s^2\). Here, the side length \(s = 5\) units. Substituting this value into the formula, we get","A = 5^2 = 25."]}]```
“大模型能不能做数学题”,不仅是社交平台的热门话题,也是业界非常关注的研究课题。处理高级数学问题,需要模型具备复杂多步逻辑推理能力。通义团队在技术博客中表示,希望通过开源“为科学界解决高级数学问题做出贡献”,未来将持续增强模型数学能力。
点击阅读原文,即可跳转模型链接~