
包阅导读总结
1. 关键词:TED 演讲者、AI 生图、LoRA 技术、Imagen 3、FLUX.1
2. 总结:最近外网几位看似逼真的 TED 演讲者被爆并非真人,是用新技术生成的。文中还介绍了多种 AI 生图模型,如 Flux 真实版 LoRA、Midjourney、Imagen 3、FLUX.1 等的特点及效果,并提及当前 AI 视频存在诸多问题。
3. 主要内容:
– 爆火的 TED 演讲者非真人
– 由 Leo Kadieff 用 Flux 真实版 LoRA 制作,效果逼真,超越恐怖谷
– 其他模型尝试复刻
– Kyrannio 用 Midjourney 复刻,效果有差距
– 谷歌 Imagen 3 公开可用,网友尝试
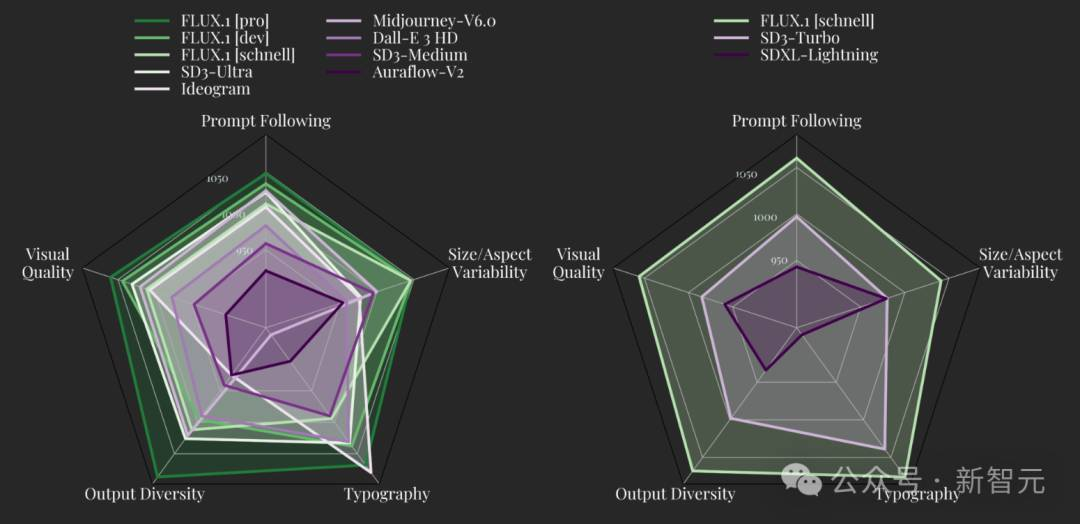
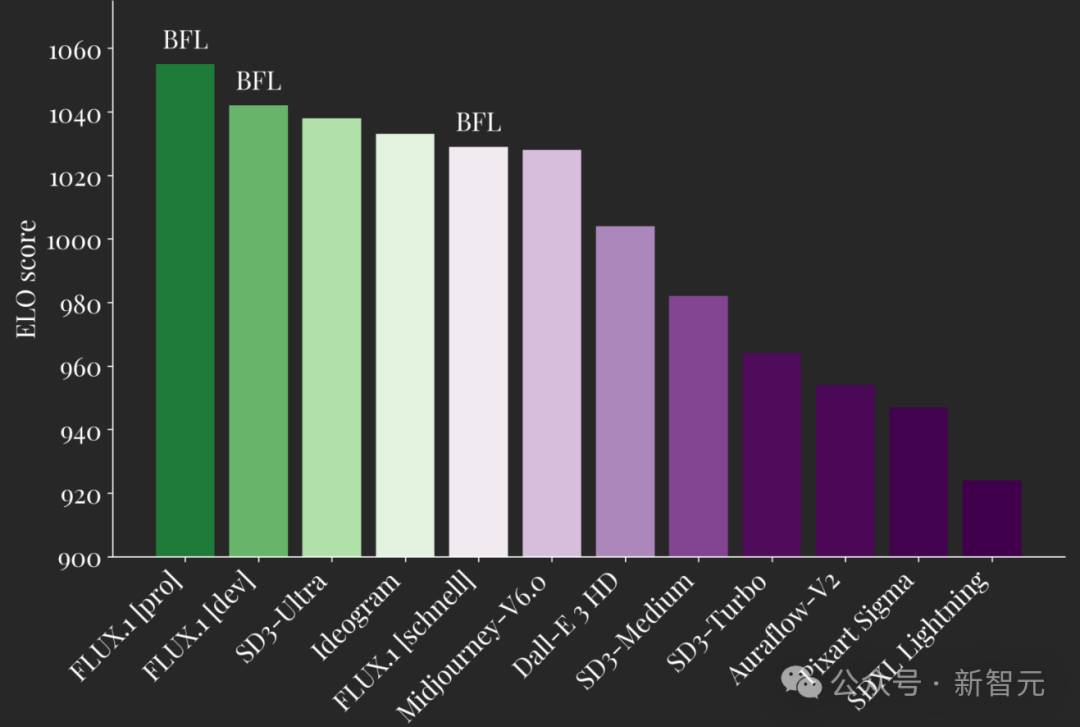
– 文生图模型对比
– Midjourney V6、Imagen 3、FLU.1[pro]的 PK
– FLUX.1 模型
– Robin Rombach 创业推出,效果佳
– 有三种变体,基于混合架构
– 团队成员及创新成果
思维导图:
文章地址:https://mp.weixin.qq.com/s/CQ2r065A06Ym7nMjMcM67w
文章来源:mp.weixin.qq.com
作者:创业邦
发布时间:2024/8/11 3:34
语言:中文
总字数:3131字
预计阅读时间:13分钟
评分:76分
标签:AI 图像生成,LoRA 技术,超真实谷,Stable Diffusion,谷歌 Imagen 3
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
【新智元导读】最近,这几位TED演讲者,在外网形成了病毒式传播,然而,他们竟然全都不是真人?!答案揭晓后,五百万网友简直惊掉下巴。这5张图里,你能发现几个bug?
最近,这些「TED演讲者」在外网火得一塌糊涂,堪称病毒式传播。
仔细看看,你能发现什么问题吗?





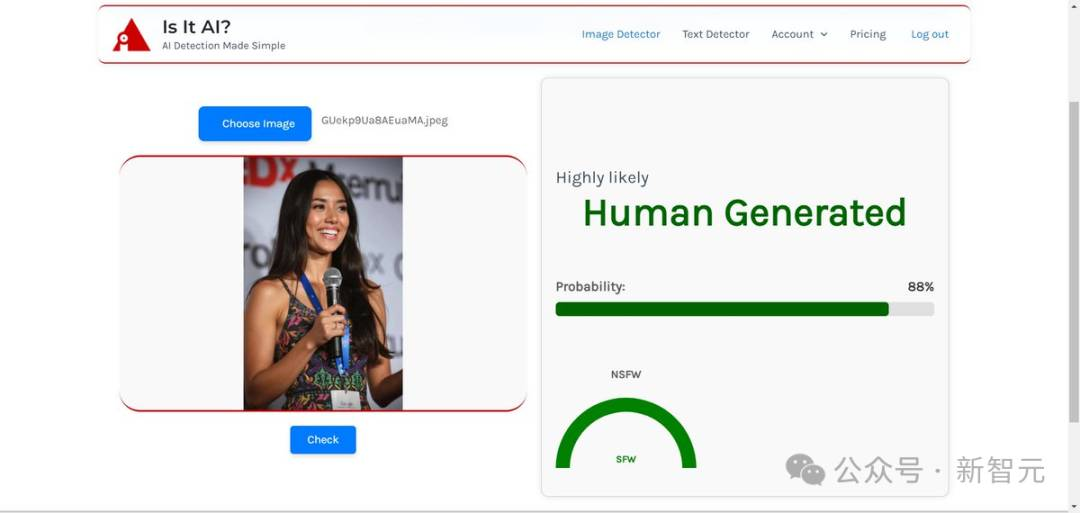
答案揭晓——这五个人中,没有一个是真人!
在线寻人的小哥要哭了
「没有一张是真人吗?简直令人毛骨悚然!」

网友锐评:这已经超越了恐怖谷,到达了「超真实谷」。

短短十几个小时,分享这张图片的帖子,在推上的观看人数已经破了500万。

随后,作者也被扒了出来——他就是Stable Diffusion团队的前成员Leo Kadieff。
他揭秘道:这些TEDx演讲者,都是用最新的Flux真实版LoRA制作的。
以往的AI生图,人眼多少都会看出违和感,而这次的图片如此逼真,正是靠LoRA技术改进了模型,才大大增加了真实感。
并且,作者介绍说,这个工作流还有一个好处,就是大大简化了复杂的提示词。
这个消息,简直让提示词苦手们狂喜。
这个小小的22MB文件,就可以让我们省去麻烦,不必再在每个提示词中写一堆与真实性相关的Token。
一句「一张RAW超现实主义照片,UHD,8k」,足矣。现实主义爱好者,绝对爱死了这个工具。
作者直言:我们还需要对现实模型进行微调吗?
– 这些图像是Flux+LoRA的原始输出,未经过任何放大或后期处理
– 你需要对应的「RealismLora」文件,以及ComfyUI工作流
ComfuUI:https://we.tl/t-zrC5tPFG17
真实版LoRA,效果拔群
从下面这两幅图中不难看出,用LoRA和不用LoRA的效果对比,果然十分明显。



与此同时,「TED演讲者」的分享者Kyrannio,也尝试用Midjourney复刻了一波。

最初的提示词如下:
一位女性在舞台上发言,来自谷歌,白色背景,企业标志被模糊处理,科技会议 –style raw –v 6.1
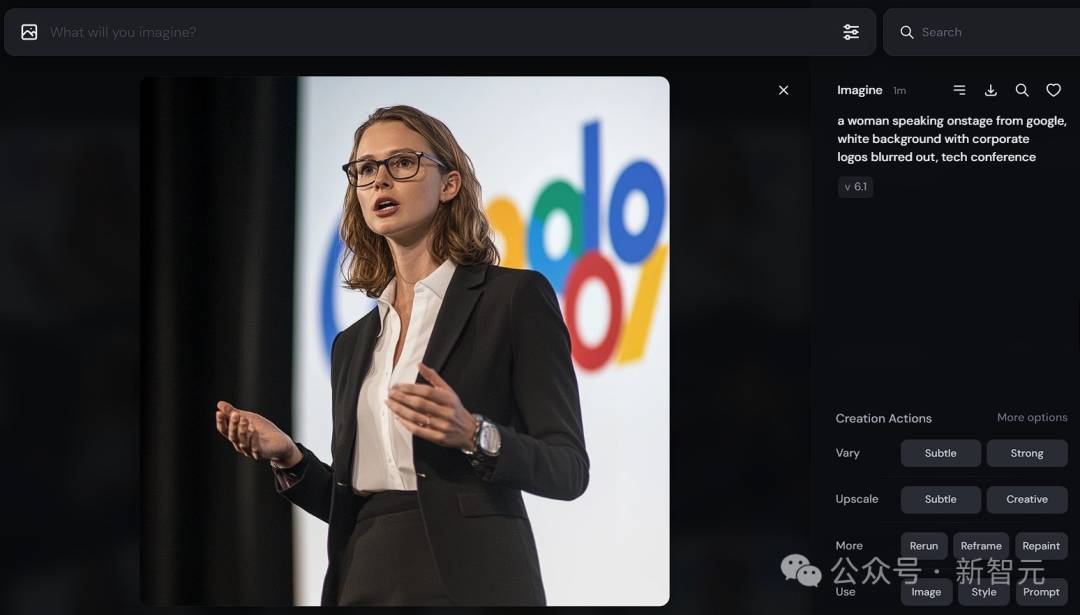
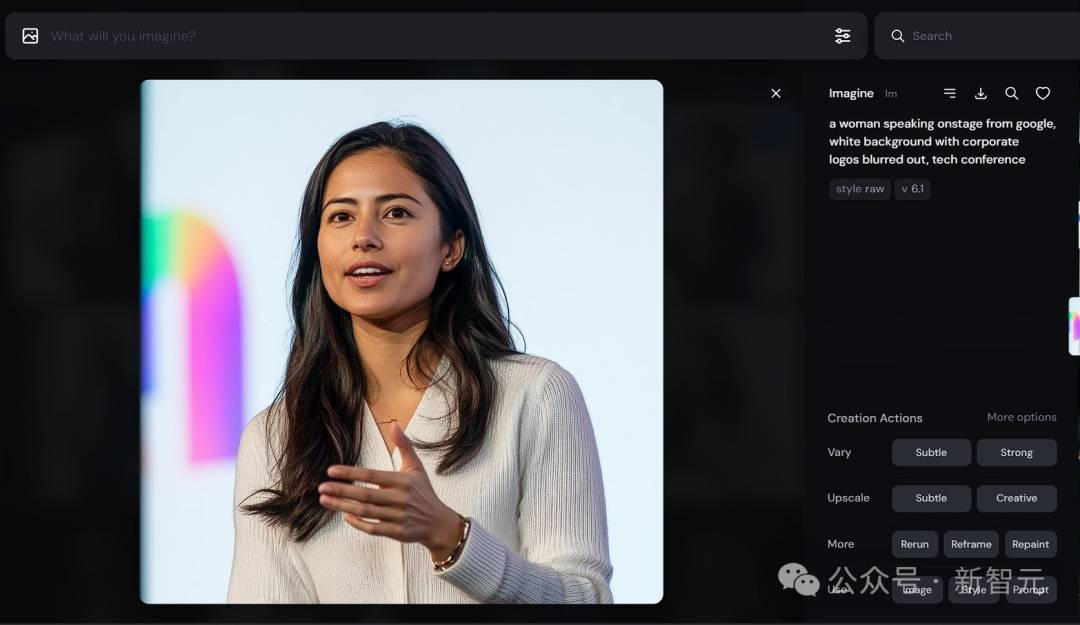
可以看出,生成效果还不错,但与Leo Kadieff生成的图片差距依然很大。
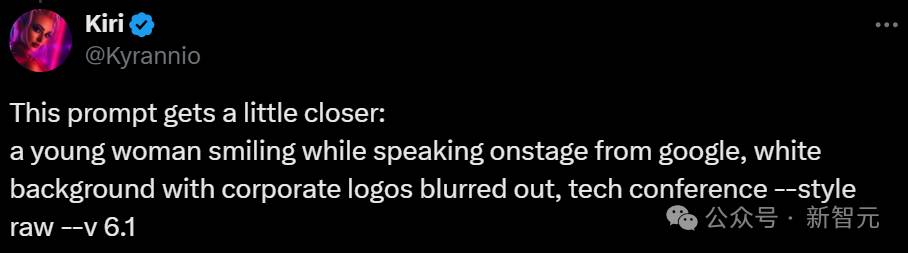
接着,博主又进行了一些改进:
一位年轻女性微笑着在舞台上发言,来自谷歌,白色背景,企业标志被模糊处理,科技会议 –style raw –v 6.1
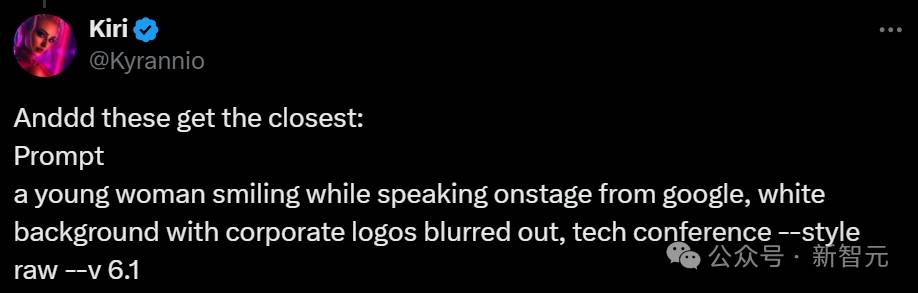
并在经过多次生成之后,试出了最为接近的结果:
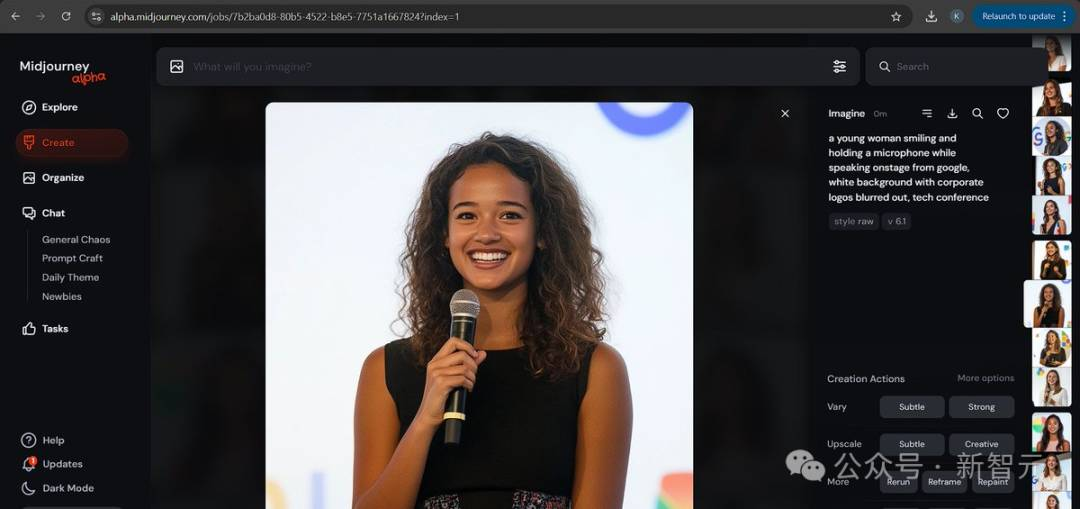
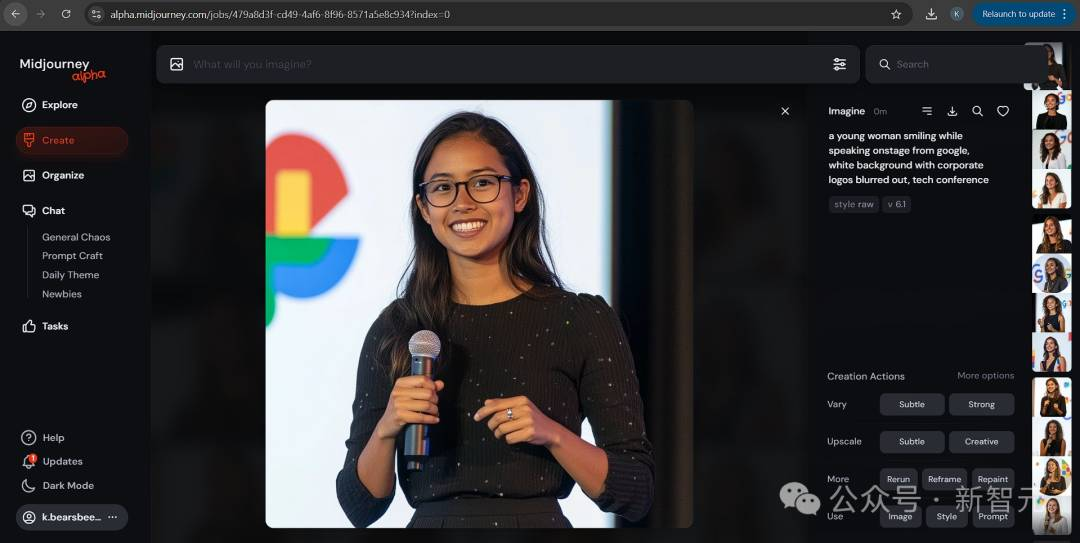

与此同时,随着谷歌Imagen 3公开可用,网友们也在第一时间拿着这套prompt进行了尝试。
一时间,全网都掀起AI生图的热潮。

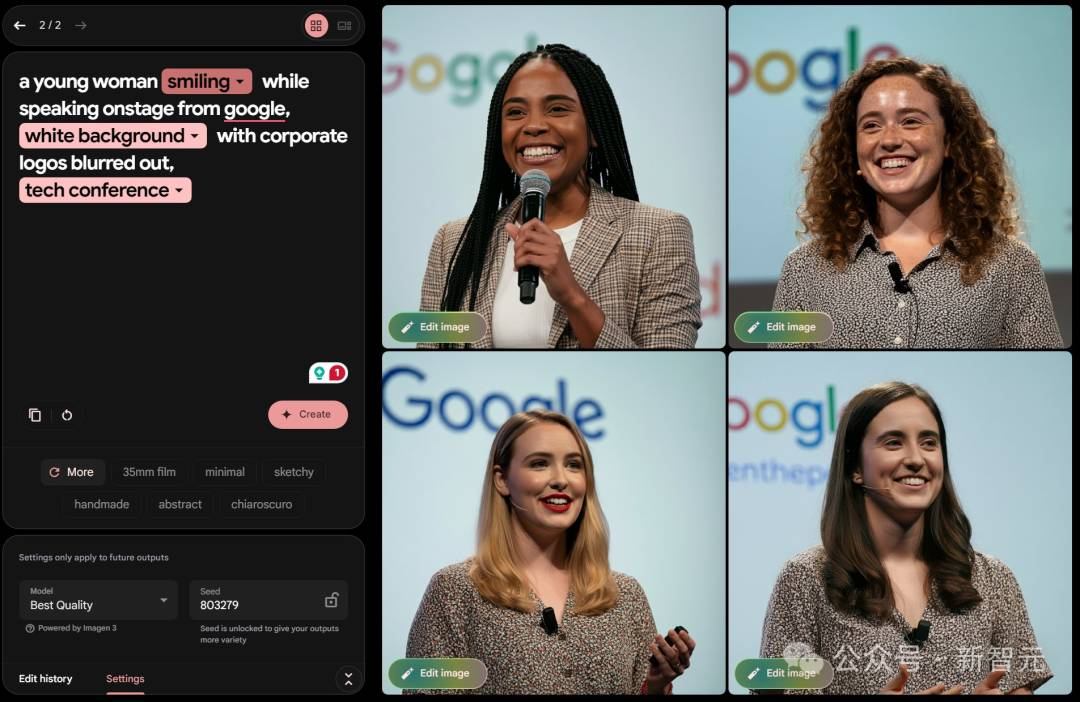
没错,正如刚刚提到的,谷歌最强文生图模型Imagen 3已经正式开放可用了。
prompt:Photo of a man holding a sign that says: “Imagen Is Now Almost As Good As Midjourney” in New York City.
来源:Risphere
网友chrypnotoad表示,自己还没见过哪个AI能把阿喀琉斯之盾做得这么好的!

能轻松hold住如此复杂的prompt,Imagen 3果然不能小觑。
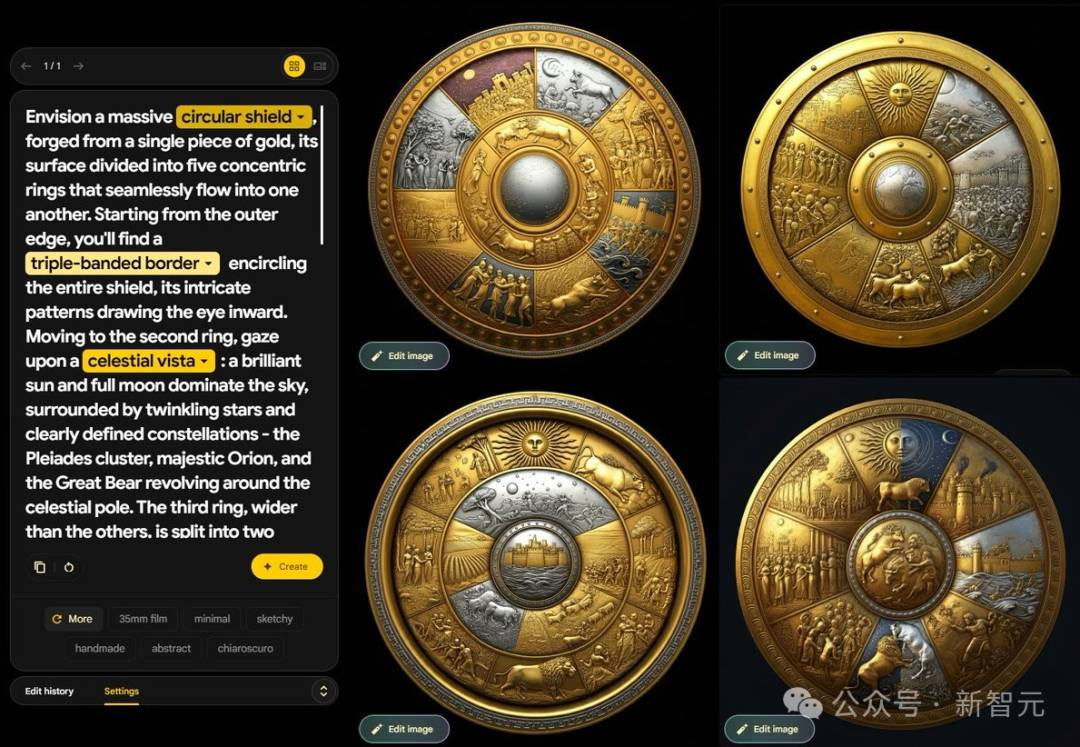
知名博主「歸藏」在体验之后表示:
生成的内容准确但图片美观度很差。只要涉及人物,你就得仔细斟酌提示词写法,不然大概率无法出图。
好在,他们在提示词的交互上做得很好:
LLM会分析提示词类型,并且给出相关词语你可以直接切换。
来源:歸藏
除了直接生成之外,Imagen 3还支持局部重绘功能,用画笔和提示词对图片进行编辑。
来源:歸藏
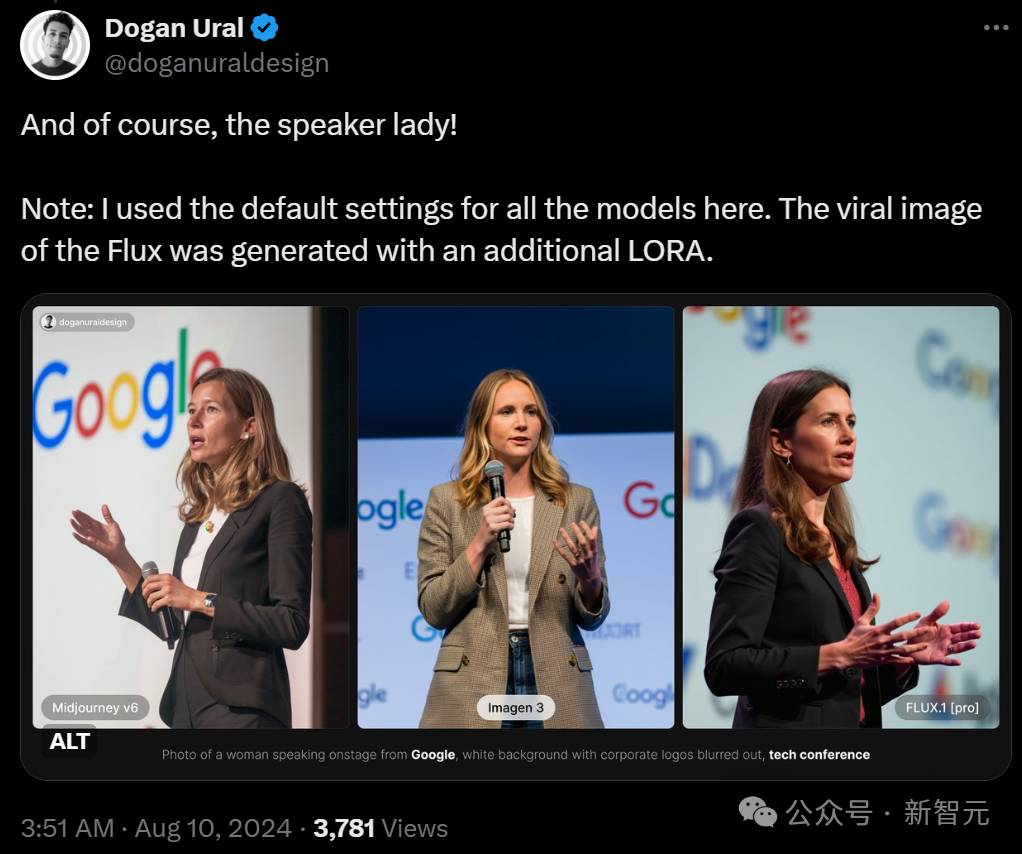
当然,几家顶流文生图AI的PK,肯定也少不了:Midjourney V6 vs Imagen 3 vs FLU.1[pro]。

异色瞳的亚洲女性。
团队成员



