
包阅导读总结
1. 关键词:RAG、Retrieval、Data Quality、Workflow、LLM
2. 总结:文本强调了 RAG 中检索的重要性,指出若无有效机制,会导致系统响应混乱,不同工作流对 RAG 有独特需求,数据质量和检索模型决定效果,良好设计的 AI 代理方法可降低 RAG 部署风险。
3.
– 缺乏有效检索机制的系统会给金融和风险分析师带来困扰
– 回应包含大量无关数据,如 CEO 新闻和名人购买等
– 产生模糊、不完整或错误的响应,用户需手动筛选和验证
– RAG 系统需满足多种工作流需求
– 不同工作流如金融和风险分析有特定要求
– 输出要依特定词汇和格式精细调整,取决于数据质量和检索模型
– 设计良好的 AI 代理方法有助于降低 RAG 部署风险
– 将复杂知识工作流分解为离散任务
– 便于确保各阶段的相关性、上下文和有效微调
思维导图: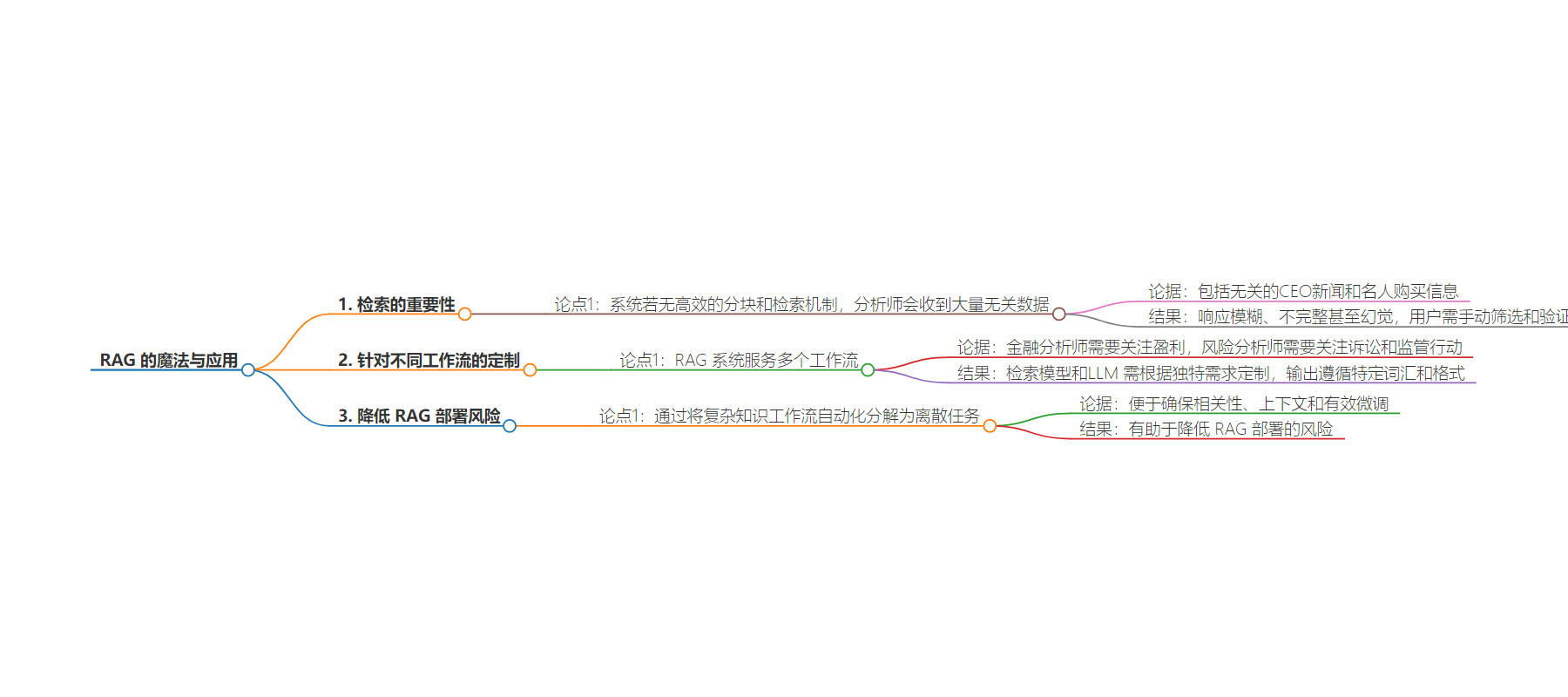
文章地址:https://www.infoworld.com/article/3484132/the-magic-of-rag-is-in-the-retrieval.html
文章来源:infoworld.com
作者:InfoWorld
发布时间:2024/8/14 8:30
语言:英文
总字数:1179字
预计阅读时间:5分钟
评分:90分
标签:RAG,检索增强型生成,AI 智能体,数据质量,检索模型优化
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Consider a system with embedded Tesla data spanning the company’s history. Without efficient chunking and retrieval mechanisms, a financial analyst inquiring about earnings or a risk analyst searching for lawsuit information would receive a response generated from an overwhelming mix of irrelevant data. This data might include unrelated CEO news and celebrity purchases. The system would produce vague, incomplete, or even hallucinated responses, forcing users to waste valuable time manually sorting through the results to find the information they actually need and then validating its accuracy.
RAG agent-based systems typically serve multiple workflows, and retrieval models and LLMs need to be tailored to their unique requirements. For instance, financial analysts need earnings-focused output, while risk analysts require information on lawsuits and regulatory actions. Each workflow demands fine-tuned output adhering to specific lexicons and formats. While some LLM fine-tuning is necessary, success here primarily depends on data quality and the effectiveness of the retrieval model to filter workflow-specific data points from the source data and feed it to the LLM.
Finally, a well-designed AI agents approach to the automation of complex knowledge workflows can help mitigate risks with RAG deployments by breaking down large use cases into discrete “jobs to be done,” making it easier to ensure relevance, context, and effective fine-tuning at each stage of the system.