
包阅导读总结
1. 关键词:LinkedIn、生成式 AI、技术架构、挑战、质量评估
2. 总结:本文介绍了 LinkedIn 构建生成式 AI 产品的经验,包括基于信息流和职位的功能、多智能体技术架构、团队协作与数据检索的挑战、稳定生成结构化数据的方法、减少幻觉等措施及生成结果质量评估的做法。
3. 主要内容:
– 技术架构
– 路由:确定查询转发的智能体。
– 检索:决定调用服务及方式。
– 生成:LLM 生成答案。
– 团队协作挑战
– 按智能体分组初有优缺点。
– 调整为公共和底层框架组与多个垂直智能体组。
– 数据检索挑战
– 自然语言检索,需 LLM 转化。
– API 需针对 LLM 优化。
– 稳定生成结构化数据
– 用 YAML 格式,优化解析器。
– 无法解析时让 LLM 修复,优化提示词。
– 减少幻觉、降低延迟和提升吞吐量
– CoT 提升质量但增延迟。
– 流式输出提升体验但复杂流程有挑战。
– 异步非阻塞管道优化吞吐量。
– 评估生成结果质量
– 制定标准难、标注规模化难、自动化难。
– 工程师粗略评估、标注员细致反馈、团队成员全面评估。
思维导图: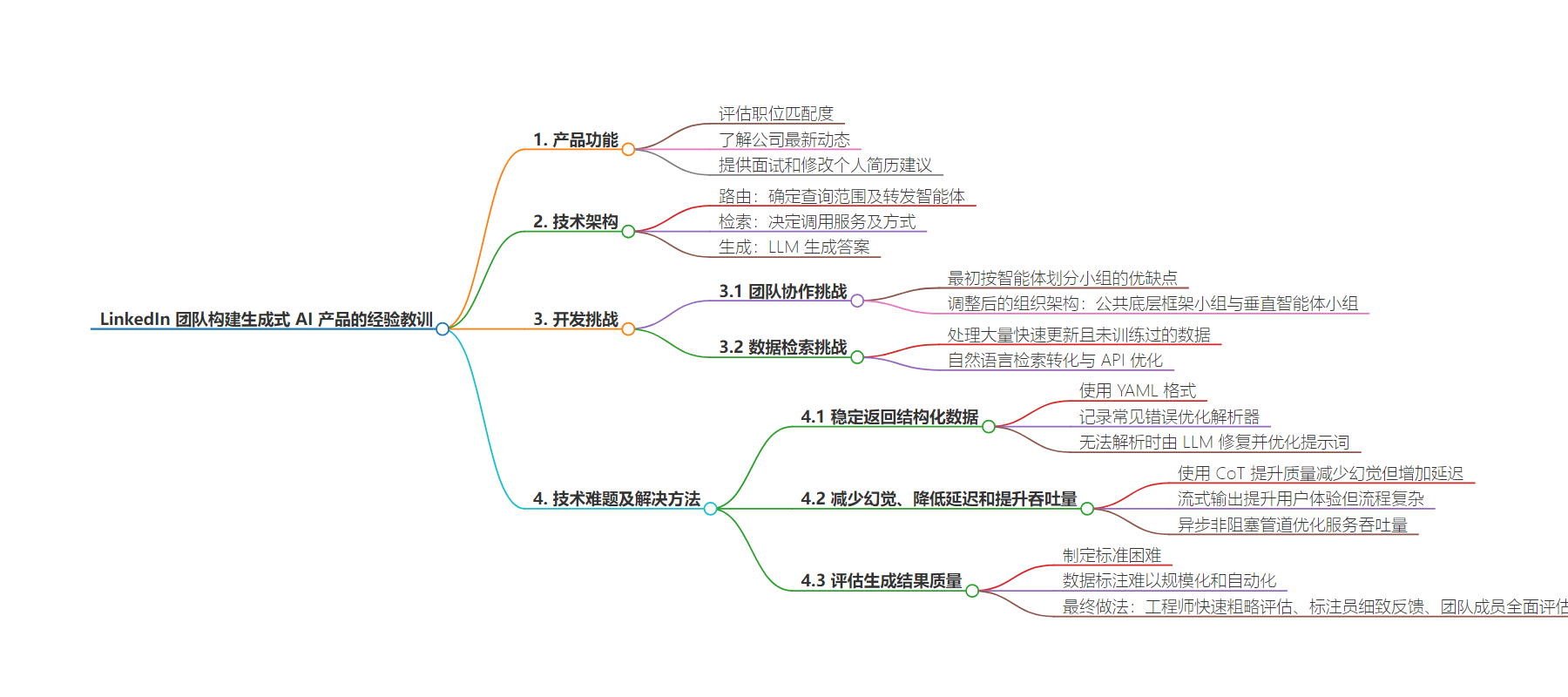
文章地址:https://baoyu.io/blog/ai/linkedin-team-building-generative-ai-lessons
文章来源:baoyu.io
作者:宝玉
发布时间:2024/7/28 16:00
语言:中文
总字数:1767字
预计阅读时间:8分钟
评分:91分
标签:生成式AI,AI产品开发,技术架构,团队协作,数据检索
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
LinkedIn 的这个分享很有价值,他们分享了在构建生成式 AI 产品时的一些宝贵经验教训
他们做的产品时基于 LinkedIn 上的信息流和职位,借助 AI 帮助用户评估是不是和职位匹配、了解某个公司的最新动态、面试和修改个人简历方面的建议,以及其他一些功能。
从技术架构上来说,是一个多智能体的技术架构,主要分成三步:
- 路由:确定查询是否在范围内,并决定将其转发给哪个 AI 智能体。智能体的例子有:职位评估、公司理解、帖子总结等。
- 检索:AI 智能体决定调用哪些服务以及如何调用(例如 LinkedIn 用户搜索,Bing 搜索 等)。
- 生成:LLM 根据获取到的信息、原始问题和上下文去生成答案。
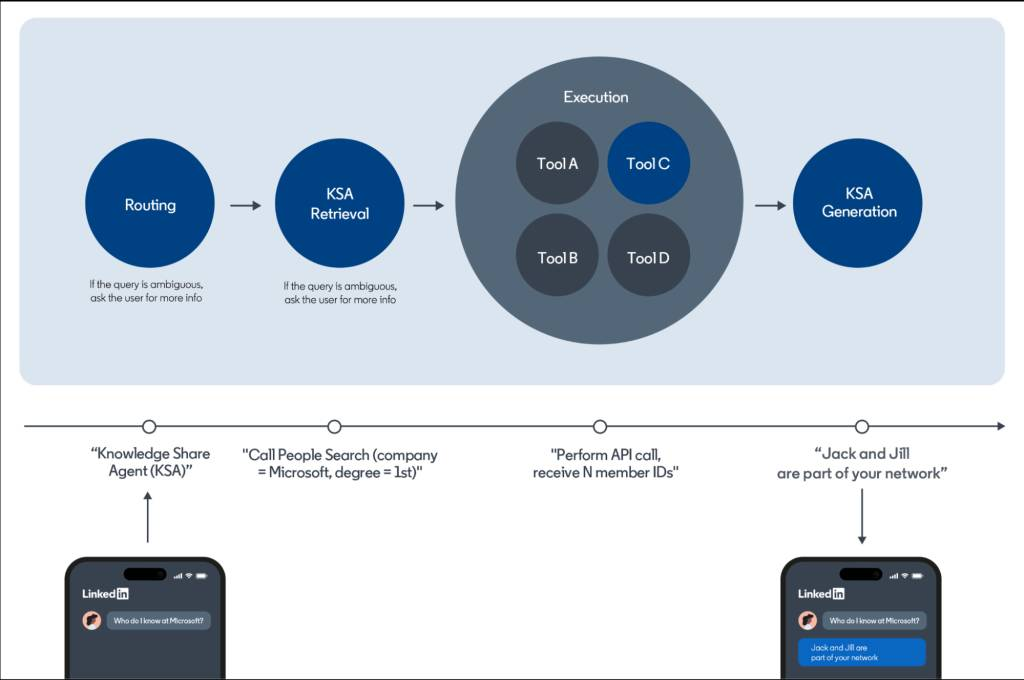
这其中路由、检索可以使用小模型,但生成内容需要使用大模型,这样才能有比较好的生成效果。
在整个项目的开发过程中,挑战是多方面的,有来自团队协作的,有来自大语言模型本身的
- 团队协作的挑战
首先在团队协作方面,最开始他们是按照智能体划分小组,各自负责,这样优点是开发速度快,但缺点是各自的提示词、对话历史、越狱防护等这些需要重复建设,用户体验不一致。
所以他们后来将组织架构进行了调整:
- 一个小组负责公共和底层框架,并且保证提供一致的体验,这样可以共享提示词模板、集中解决安全防护、统一用户体验等
- 多个小组负责垂直方向的智能体,基于公共组提供的框架优化提示词、连接后端 API 等
- 数据检索的挑战
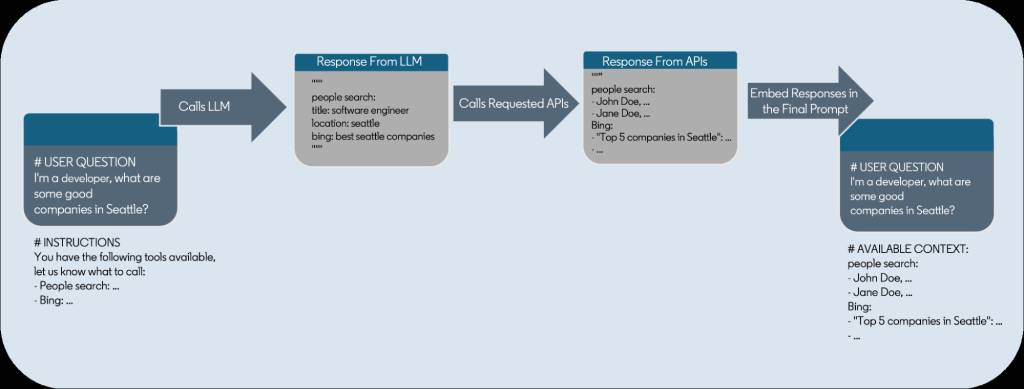
LinkedIn 有大量的用户资料、公司信息、还有一些其他的信息,这些数据更新很快,并且没有被大语言模型训练过,所以当用户请求时,需要能检索到用户想要的数据,而基于生成式 AI 产品的交互,不再是传统的关键字 + 选项的检索,而是完全自然语言的检索,这就需要先调用一次 LLM 帮助将自然语言转化为 API 调用。另外传统的 API 是给传统的 App 使用的,返回的数据冗余很多,并不适合 LLM 使用,所以需要针对 API 做一些针对 LLM 的优化。
举例来说,用户可能会询问:“请给我推荐西雅图的待遇好的公司”,那么针对这样的查询,首先需要去根据用户的身份找出来用户自己的职业(比如 Java 后端开发工程师),然后将用户资料 + 咨询的问题 + 可用的检索 API,一起交给 LLM,LLM 将请求分解成适合 API 查询的参数:
- 职位搜索 API
- 职位:Java 后端开发工程师
- 地点:西雅图
- 排序:工资由高到低
然后去调用 API,API 返回结果后,将返回结果、用户原始问题、历史对话一起交给 LLM,最终生成答案。
- 怎么稳定的让 LLM 返回结构化的数据?
真正做过 LLM 开发的都知道,虽然理论上 LLM 可以生成结构化的数据,但是真正生成的时候经常出错。LinkedIn 的做法是:1). 使用 YAML 格式而不是 JSON,相对来说容错率更高2). 用日志记录常见的 YAML 错误,优化自己的 YAML 解析器,可以解析 LLM 返回的不规范的 YAML3). 如果还是无法解析则将错误信息交给 LLM 修复,并且不断优化提示词,提升 LLM 修复的成功率
最终结构化数据的错误率从 10% 下降到 0.01%
- 如何减少幻觉、降低延迟和提升吞吐量
- 使用 CoT(思维链)可以有效提升质量和减少幻觉,但由于一些中间步骤不能显示给用户,要等前面的中间步骤输出完成才能给用户显示结果,这也会增加延迟
- 使用流式(streaming)输出可以提升用户体验,让用户尽早看到输出,但这在复杂的流程上有很多挑战
- 由于 LLM 调用可能需要很长时间处理,使用异步非阻塞管道可以优化服务吞吐量,从而避免因 I/O 阻塞线程而浪费资源。
- 如何评估生成结果的质量
只有对生成的结果有科学的评估,才能不断优化生成结果,但如何评估生成质量是很困难的,主要表现在:
- 难以制定标准。以职位评估为例:点击“评估我与该职位的匹配度”然后得到“你很不适合”并没有多大价值。好的结果既要真实准确又富有同情心。
- 对数据标注很难规模化,主要得依赖团队成员和外部标注员
- 难以自动化,还是需要人工去标注,并且需要收集一定的数据后才能评估
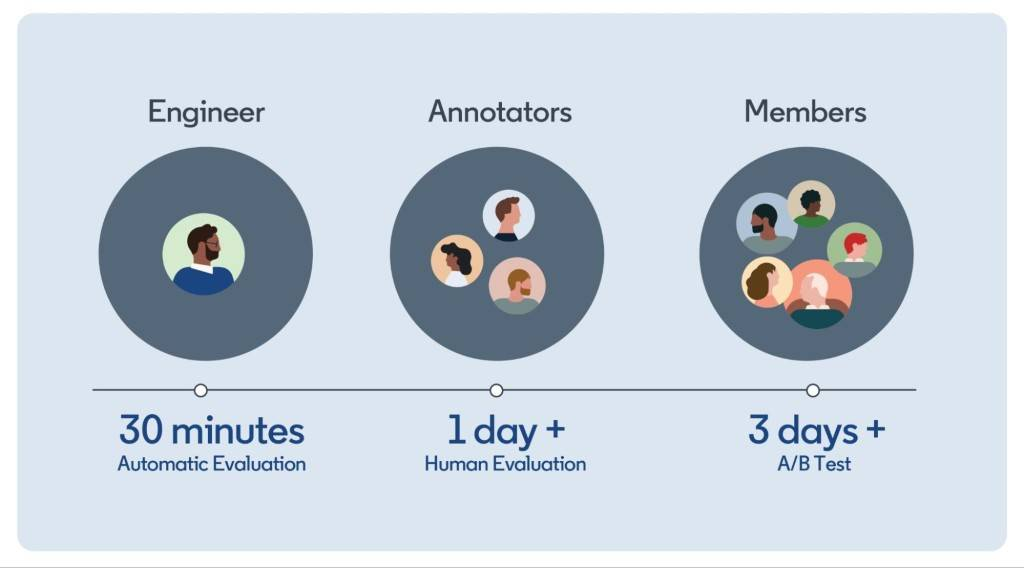
最终 LinkedIn 的做法:1). 工程师们先快速粗略评估,得到个大致的指标。2). 标注员提供更细致的反馈,但需要大约 1 天的时间。3). 最终由团队成员进行全面评估,但可能需要超过 3 天的时间。
具体内容建议阅读原文。