
包阅导读总结
1. 关键词:AI 模型崩溃、训练数据、牛津剑桥、Nature、解决方案
2. 总结:牛津剑桥研究者在《Nature》发文指出,用 AI 生成的数据训练 AI 会导致模型崩溃,文章分析了原因并提出了使用真实数据等一系列解决方案。
3. 主要内容:
– 背景:AI 大模型通常依赖现成数据训练,当考虑用 AI 生成数据训练时引发担忧。
– 模型崩溃概念:是指训练递归生成数据时的退化过程,模型会忘记部分事件,偏离预期,如大语言模型等都可能发生。
– 实验与现象:语言模型生成数据含大量重复短语,实验施加重复惩罚反而更差,模型会逐渐偷懒丢失多样性并引入错误。
– 崩溃原因:包括统计近似误差、函数表达误差和统计误差的复合效应。
– 解决方案:使用真实数据、加强数据标注和验证、改进模型架构和训练算法、动态调整训练目标、建立监控机制等。
思维导图: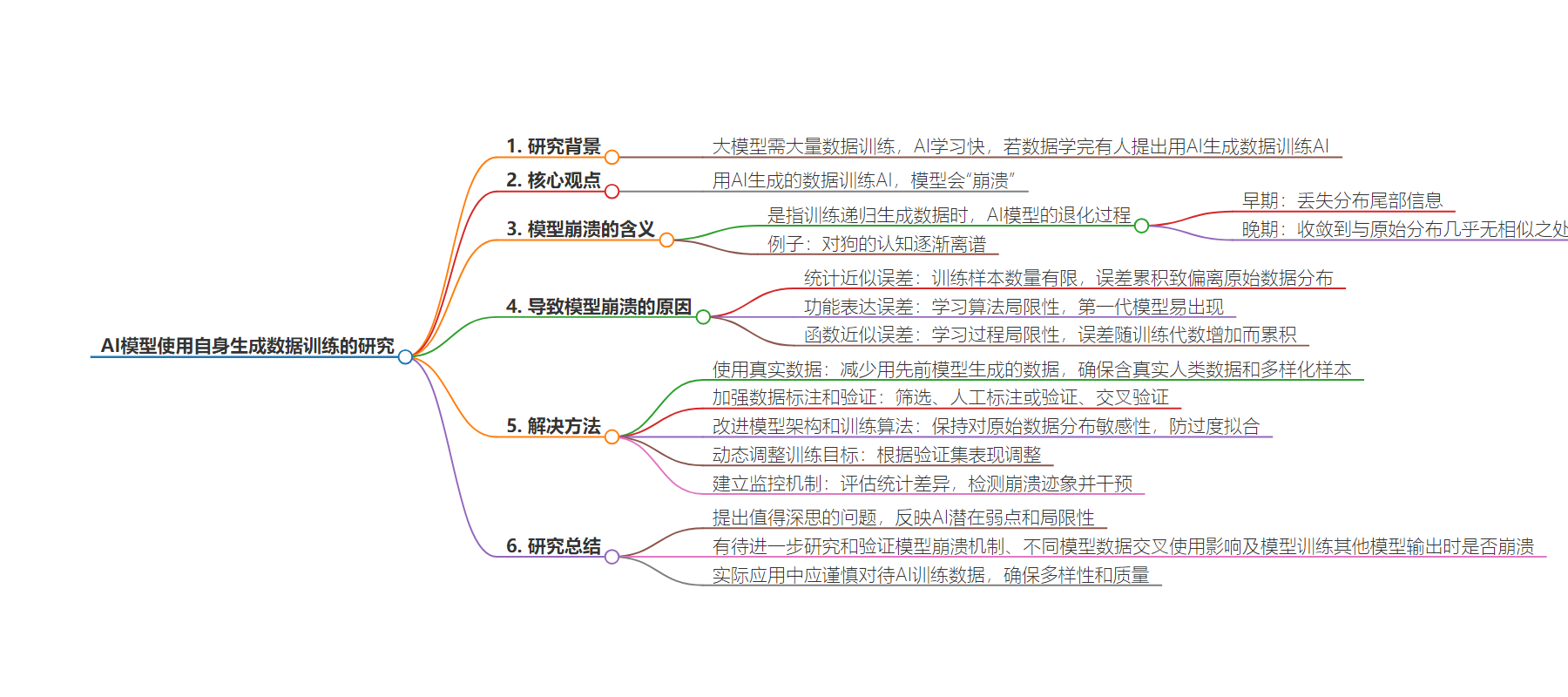
文章地址:https://mp.weixin.qq.com/s/DzuySbEXPe3Pk0uARyYA7Q
文章来源:mp.weixin.qq.com
作者:谷雨龙泽
发布时间:2024/7/29 12:59
语言:中文
总字数:2765字
预计阅读时间:12分钟
评分:82分
标签:AI模型训练,模型崩溃,数据质量,牛津剑桥研究,AI生成数据
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
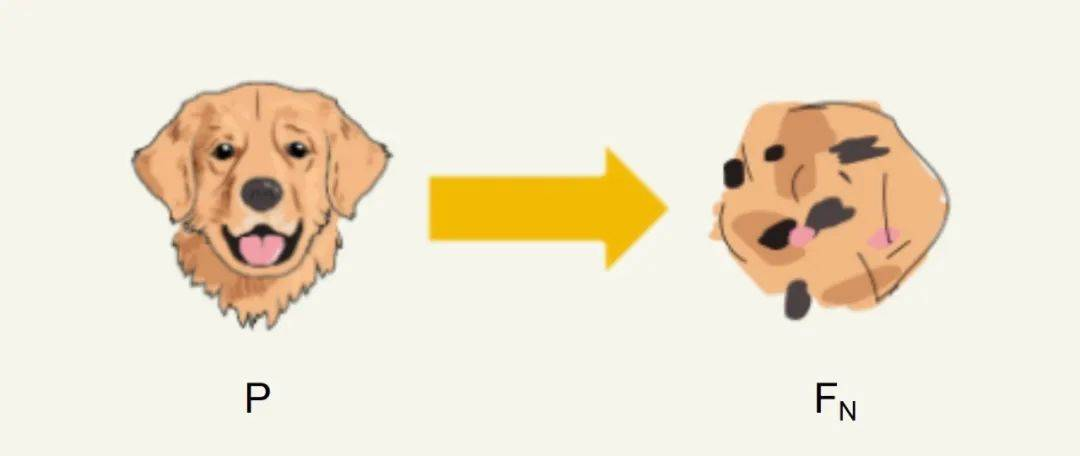 夕小瑶科技说 原创
夕小瑶科技说 原创
作者 | 谷雨龙泽
我们都知道,AI大模型是需要现成的数据来训练,只有喂给AI大量的数据,AI才能“学富五车”。为此,不少AI模型在研发的时候,特别注重数据的数量以及质量——就好比上学的时候老师告诉你们,读书要读名著,不能读乱七八糟的东西是一个道理。
但是学着学着,人们发现了——AI的学习速度太快了,如果有一天,AI把所有现成的数据都学完了怎么办?
于是有人提出来了一个“好点子”——用AI自己生成的数据来喂给AI(事实上,现在AI生成的数据已经无孔不入,AI如果自己上网查资料学习,说不定吸收的就是AIGC)。
是不是感到兴奋了?是不是一下子放轻松了?
先别着急开香槟。近日,一群来自牛津、剑桥等的研究者在《Nature》上发表了一篇文章,提出了一个值得警惕的观点:
如果用AI生成的数据来训练AI,AI模型会“崩溃”掉!
论文标题:
《AI models collapse when trained on recursively generated data》
论文链接:
https://www.nature.com/articles/s41586-024-07566-y

“模型崩溃”是什么?
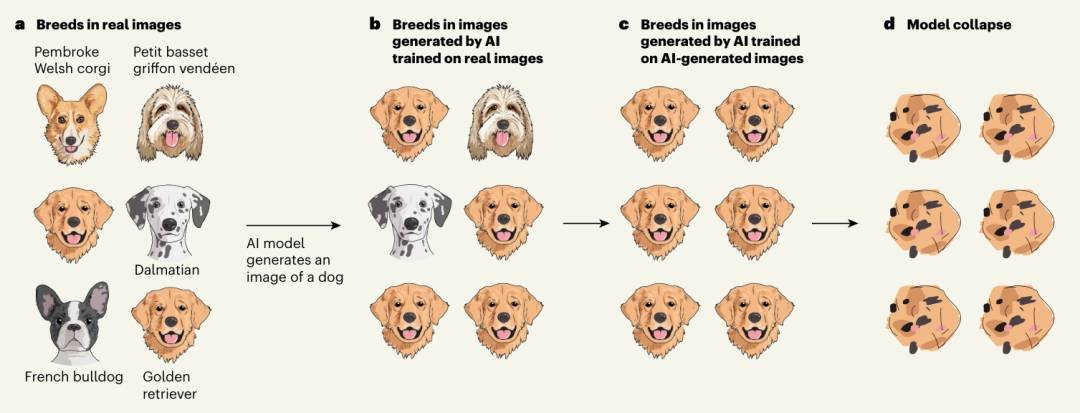
“模型崩溃”(Model Collapse)是指在训练递归生成的数据时,AI模型经历的一个退化过程。 在这个过程中,模型逐渐忘记一些事件,因为它们被自己的输出数据所“毒害”。
当模型的训练数据主要来源于先前版本的模型生成,而不是原始的真实数据时,模型会失去对原始数据分布的理解,导致模型的表现或输出逐渐偏离预期,甚至完全无法反映数据的真实分布或特征。
研究团队将这一过程分为了早期模型崩溃和晚期模型崩溃。在早期模型崩溃中,模型开始丢失有关分布尾部的信息,即 “吃掉自己的尾巴” ;在模型坍缩后期,模型收敛到与原始分布几乎没有相似之处的分布,已经 “改头换面” 了,亲妈都不认识的那种。
这一现象在大语言模型(LLM)、变分自编码器(VAEs)和高斯混合模型(GMMs)中都可能发生。
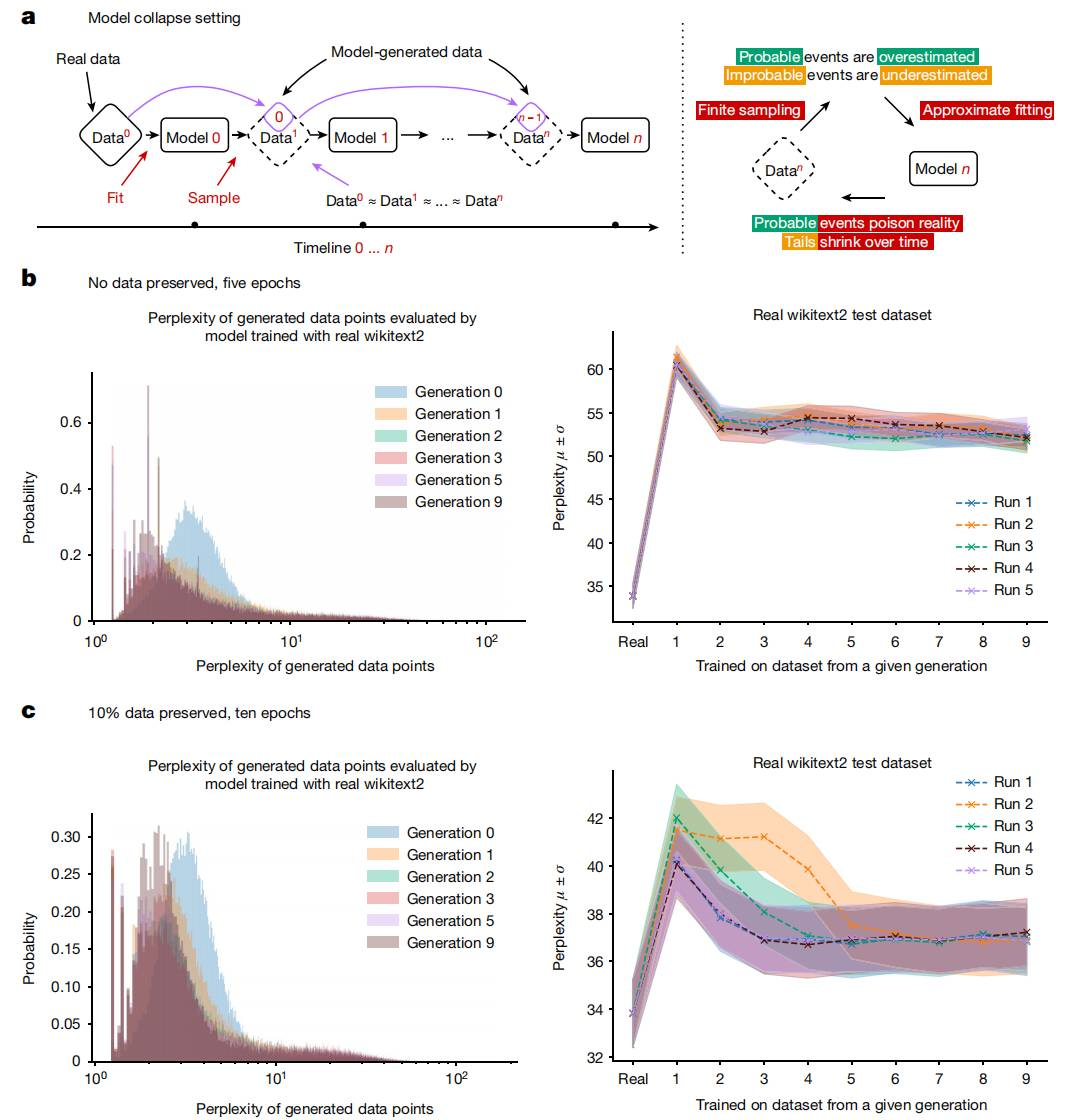
研究者通过实验发现,由语言模型生成的数据往往包含大量重复的短语。为了排除重复性是导致模型崩溃的原因,他们进行了数值实验,通过施加一个重复惩罚(repeating penalty)来鼓励模型生成非重复序列。然而,这样做反而使模型的表现变得更差,模型的困惑度(perplexity)相对于使用原始真实数据分布训练的模型翻倍。
此外,随着生成轮数的增加,模型的密度开始集中在低困惑度样本上,这预示着模型可能会逐渐崩溃到一个delta函数,即数据分布极度集中。
这是什么意思呢?就是模型会逐渐偷懒,生成它常见的内容,忘记不常见的小概率事件,一步步丢失多样性,并逐渐引入未知的错误,即逐渐“离谱化”。
这些观察结果表明,即使是微调过的语言模型也无法避免模型崩溃的影响。
这张图片展示了一个关于OPT-125m模型的示例,模型在多代训练后出现退化的现象。具体来说,每一代模型都是基于前一代模型生成的数据进行训练的,随着代数的增加,模型的输出质量逐渐下降。
输入示例:给出了一个关于1360年前建筑工程的历史描述作为输入。
输出示例:展示了从Gen 0到Gen 9不同代际模型的输出结果。

退化过程:
-
Gen 0的输出还比较相关,提到了建筑风格和具体例子。 -
Gen 5的输出完全偏离了主题,讨论起了语言翻译。
每一代的错误和偏差都被传递并放大到下一代,导致输出质量急剧下降。
为什么会发生这种现象?
“模型崩溃”(Model Collapse)主要是统计近似误差、函数表达误差和统计误差的复合效应导致的。
-
统计近似误差(Statistical Approximation Error):这是最主要的误差类型,由于训练样本的数量有限而产生。当样本数量趋于无穷大时,这种误差会消失。但在实际中,由于数据集的有限性,模型无法完全捕捉到原始数据分布的所有细节,导致在训练过程中产生偏差。随着模型不断在由其他模型生成的数据上进行训练,这种误差会逐步累积,导致模型逐渐偏离原始数据分布。 -
功能表达误差(Functional expressivity error):由于学习算法的局限性,即使在无限数据和完美表达性的条件下,模型也无法完全捕捉到数据分布的所有复杂性。例如,随机梯度下降的结构偏差或目标选择的问题会导致这种误差。这种误差通常只在第一代模型中出现,随着模型的迭代和复杂性的增加,其他类型的误差如统计误差和表达率误差会更加显著。 -
函数近似误差(Functional approximation error):主要由学习过程的局限性引起,如随机梯度下降的结构偏差或者目标函数的选择。例如,尝试用单个高斯分布去拟合两个高斯分布的混合体,即使我们对数据分布有完美信息(即无限样本),模型错误也是不可避免的。这种误差可以看作是在每一代的无限数据和完美表现力的极限下产生的误差。随着模型训练代数的增加,这种误差会不断累积。
不能看着AI就这样烂下去!
这个问题如果放任不管,AI的水平会越来越垃圾。为此,可以有这些方法来处理这一问题。
-
使用真实数据:在训练新一代模型时,应尽量减少或避免使用完全由先前模型生成的数据。确保训练数据中包含足够比例的真实人类生成的数据;确保训练数据集包含多样化的样本,覆盖广泛的分布,特别是那些在人类数据中常见但在模型生成数据中可能缺失的“尾部”样本。 -
加强数据标注和验证:如果必须使用AI生成的数据,需要对其进行筛选;确保训练数据中的每个样本都经过严格的人工标注或验证,以减少错误和噪声;使用不同的数据集和模型架构进行交叉验证。 -
改进模型架构和训练算法:鼓励模型保持对原始数据分布的敏感性,防止过度拟合到模型生成的数据。 -
动态调整训练目标:根据模型在验证集上的表现动态调整训练目标,以确保模型不仅优化生成数据的准确性,还保持对真实数据分布的忠诚度。 -
建立监控机制:定期评估模型生成的样本与真实数据之间的统计差异,特别是关注那些可能表明模型崩溃的指标,如样本多样性减少、特定模式的重复出现等。一旦检测到模型崩溃的迹象,应立即采取措施进行干预,如重新训练模型、调整训练数据集的构成或修改模型架构。
这就像我们在上学的时候,老师及时纠正我们出现的问题一样。“小洞不补、大洞吃苦”,“防微杜渐、未雨绸缪”总是适用的。
使用AI训练数据需谨慎
这个研究确实提出了一个值得深思的问题。
AI模型在自身生成的数据上训练可能导致”崩溃”。
这反映了AI系统的一个潜在弱点和局限性。然而,这个问题还有待进一步研究和验证。还需要更深入地研究AI模型崩溃的机制,以及不同模型之间数据交叉使用的影响。此外一个模型在训练其他模型的输出时是否会崩溃也有待观察。
无论怎样,AI训练数据质量对模型稳定性和性能都有关键影响,在实际应用中,我们应该采取谨慎的态度,确保AI训练数据的多样性和质量。



参考资料
[1]https://techcrunch.com/2024/07/24/model-collapse-scientists-warn-against-letting-ai-eat-its-own-tail/
[2]https://www.nature.com/articles/s41586-024-07566-y