
包阅导读总结
1. 大语言模型、工作原理、Token、训练、智能
2. 本文用简单术语解释大语言模型工作原理,包括Token、下一个Token预测、生成长文本序列、模型训练等,探讨其是否具有智能,指出虽有用但易产生幻觉,需人工验证。
3.
– Tokens
– Token是LLM理解的文本基本单位。
– LLM使用的所有Token统称词汇,通过BPE算法生成,有唯一标识符。
– 下一个Token预测
– 语言模型根据输入文本预测下一个Token。
– 训练中模型学习大量文本以计算概率。
– 生成长文本序列
– 多次循环运行模型生成新Token,直至生成足够文本。
– 可通过超参数控制标记选择过程。
– 模型训练
– 以简单方法展示训练,如构建概率表。
– 训练存在空洞问题,可能导致模型预测质量差。
– 从马尔可夫链到神经网络,后者擅长生成Token概率近似值。
– 神经网络通过参数调整训练,规模大,难以理解和调试。
– Transformer模型有注意力机制,能推导Token关系和模式。
– 大语言模型是否具有智能
– 作者认为大语言模型不具备推理和原创能力,但有用,易产生幻觉,需人工验证。
思维导图: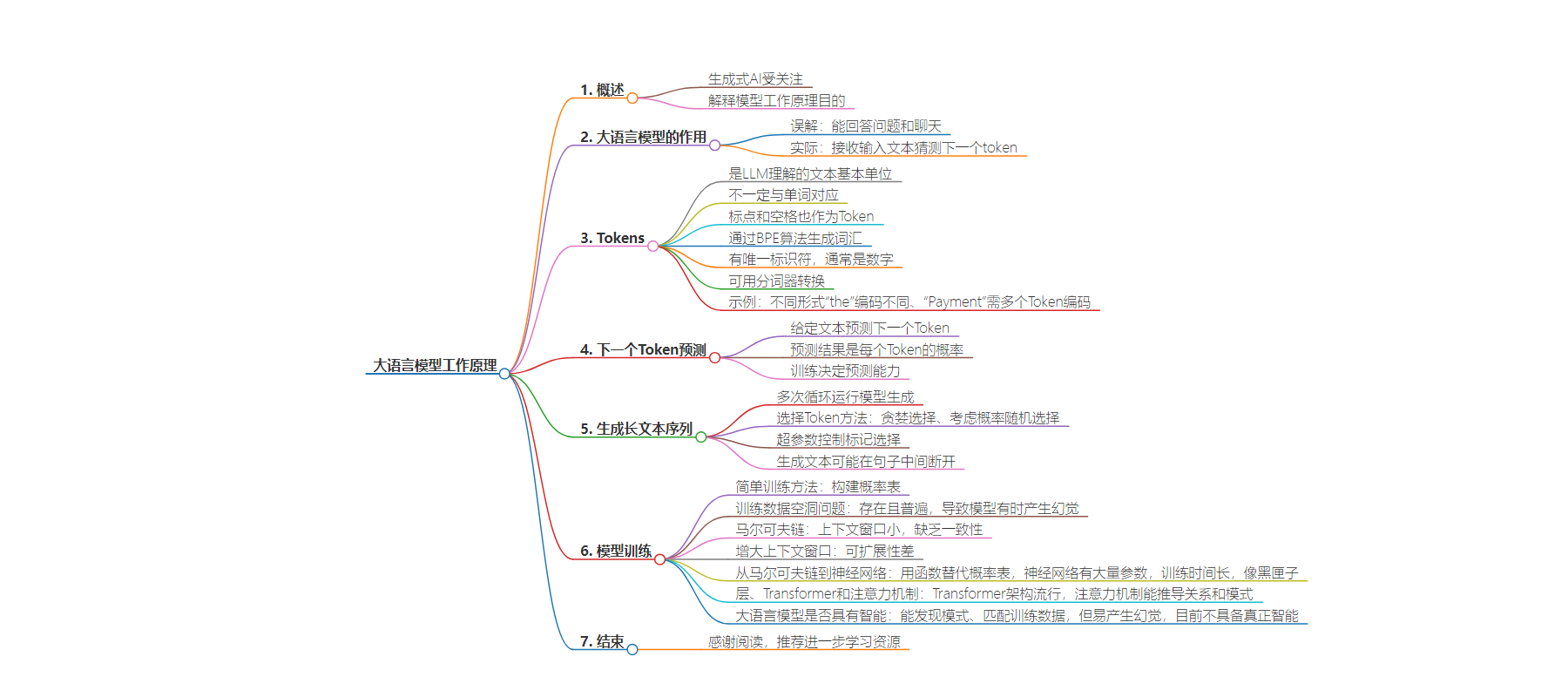
文章地址:https://baoyu.io/translations/llm/how-llms-work-explained-without-math
文章来源:baoyu.io
作者:宝玉
发布时间:2024/7/29 17:39
语言:中文
总字数:6274字
预计阅读时间:26分钟
评分:91分
标签:大语言模型,文本生成,神经网络,Transformer,注意力机制
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
我相信你会同意,现在忽视生成式 AI(GenAI)已经变得不可能,因为我们不断被关于大语言模型(LLMs)的主流新闻轰炸。很可能你已经尝试过ChatGPT,甚至可能一直将其作为助手打开。
我认为很多人对 GenAI 革命有一个基本疑问,那就是这些模型表面上展示的智能究竟来自哪里。在本文中,我将尝试用简单的术语解释生成式 AI 模型的工作原理,而不使用高级数学,帮助你将它们看作计算机算法,而不是魔法。
大语言模型的作用是什么?
首先,我要澄清人们对大语言模型如何工作的一大误解。大多数人认为这些模型可以回答问题或与你聊天,但实际上它们只能接收你提供的一些文本作为输入,并猜测下一个词(更准确地说,下一个_token_)是什么。
让我们从 tokens 开始解开大语言模型的谜团。
Tokens
Token 是 LLM 理解的文本基本单位。虽然将 Token 看作单词很方便,但对 LLM 来说,目标是尽可能高效地编码文本,所以在许多情况下,Token 代表的字符序列比整个单词短或长。标点符号和空格也作为 Token 表示,可能是单独或与其他字符组合。
LLM 使用的所有 Token 统称为其_词汇_,因为它可以用来表示任何可能的文本。字节对编码(BPE)算法通常用于 LLM 生成 Token 词汇。为了让你对规模有个大致的了解,GPT-2语言模型是开源的,可以详细研究,其词汇量为 50,257 个 Token。
LLM 词汇中的每个 Token 都有一个唯一的标识符,通常是一个数字。LLM 使用_分词器_在常规文本字符串和等效的 Token 数列表之间进行转换。如果你熟悉 Python 并想尝试 Token,可以从 OpenAI 安装tiktoken包:
$ pip install tiktoken
然后在 Python 提示符中尝试以下内容:
>>> import tiktoken
>>> encoding = tiktoken.encoding_for_model("gpt-2")
>>> encoding.encode("The quick brown fox jumps over the lazy dog.")
[464, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 13]
>>> encoding.decode([464, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 13])
'The quick brown fox jumps over the lazy dog.'
>>> encoding.decode([464])
'The'
>>> encoding.decode([2068])
' quick'
>>> encoding.decode([13])
'.'
在这个实验中,你可以看到对于 GPT-2 语言模型,Token 464 代表单词“The”,而 Token 2068 代表单词“quick”,包括一个前导空格。该模型使用 Token 13 表示句号。
由于 Token 是通过算法确定的,你可能会发现一些奇怪的现象,比如这三个变体的单词“the”,在 GPT-2 中都编码为不同的 Token:
>>> encoding.encode('The')
[464]
>>> encoding.encode('the')
[1169]
>>> encoding.encode(' the')
[262]
BPE 算法并不总是将整个单词映射到 Token。事实上,使用频率较低的单词不能成为独立的 Token,必须使用多个 Token 进行编码。以下是一个使用两个 Token 编码的单词示例:
>>> encoding.encode("Payment")
[19197, 434]
>>> encoding.decode([19197])
'Pay'
>>> encoding.decode([434])
'ment'
下一个 Token 预测
如上所述,给定一些文本,语言模型会预测下一个紧跟其后的 token。如果用 Python 伪代码展示可能会更清晰,下面是如何运行这些模型以获取下一个 token 的预测:
predictions = get_token_predictions(['The', ' quick', ' brown', ' fox'])
该函数接收一个由用户提供的提示词编码而来的输入 token 列表。在这个例子中,我假设每个单词都是一个独立的 token。为了简化,我使用了每个 token 的文本表示,但如前所述,实际上每个 token 将作为一个数字传递给模型。
该函数返回的值是一个数据结构,它为词汇表中的每个 token 分配一个紧随输入文本之后的概率。如果基于 GPT-2,这个函数的返回值将是一个包含 50,257 个浮点数的列表,每个数值预测相应 token 将成为下一个 token 的概率。
在上述例子中,你可以想象,一个训练良好的语言模型会给 token“jumps”一个较高的概率来紧跟提示词“The quick brown fox”后面。同样假设模型训练得当,你也可以想象,随机单词如“potato”继续这个短语的概率会非常低,接近于 0。
为了能够生成合理的预测,语言模型必须经过训练过程。在训练期间,它会被提供大量文本以进行学习。训练结束时,模型能够使用它在训练中见到的所有文本构建的数据结构来计算给定 token 序列的下一个 token 概率。
这与你的预期有何不同?我希望这现在看起来不再那么神奇了。
生成长文本序列
由于模型只能预测下一个标记 (token) 是什么,因此生成完整句子的唯一方法是多次循环运行模型。每次循环迭代都会生成一个新的标记,从返回的概率中选择该标记。然后将该标记添加到下一次循环迭代的输入中,直到生成足够的文本为止。
让我们看一个更完整的 Python 伪代码,展示这种方法的工作原理:
def generate_text(prompt, num_tokens, hyperparameters):
tokens = tokenize(prompt)
for i in range(num_tokens):
predictions = get_token_predictions(tokens)
next_token = select_next_token(predictions, hyperparameters)
tokens.append(next_token)
return ''.join(tokens)
generate_text()函数将用户提示作为参数。这可能是一个问题。
tokenize()辅助函数使用tiktoken或类似库将提示转换为等效的标记列表。在 for 循环中,get_token_predictions()函数是调用 AI 模型以获取下一个标记的概率,如前面的例子所示。
select_next_token()函数的作用是获取下一个标记的概率(或预测)并选择最佳标记以继续输入序列。函数可以只选择概率最高的标记,这在机器学习中称为“贪婪选择 (greedy selection)”。更好的是,它可以使用随机数生成器来选择一个符合模型返回概率的标记,从而为生成的文本添加一些变化。这也会使模型在多次给出相同提示时产生不同的响应。为了使标记选择过程更加灵活,LLM 返回的概率可以使用超参数进行修改,这些超参数作为参数传递给文本生成函数。超参数允许你控制标记选择过程的“贪婪性”。如果你使用过 LLM,你可能熟悉
temperature超参数。温度越高,标记概率越平坦,这增加了选择不太可能的标记的机会,最终使生成的文本看起来更有创造性或更不寻常。你可能还使用了另外两个超参数,称为top_p和top_k,它们控制被考虑选择的最高概率的标记数量。一旦选定了一个 token,循环就会迭代,模型会接收到一个包含新 token 在末尾的输入,并生成另一个紧随其后的 token。
num_tokens参数控制循环运行的迭代次数,换句话说,就是要生成多少文本。生成的文本可能(而且经常)在句子中间断开,因为大语言模型没有句子或段落的概念,它只处理一个 token。为了防止生成的文本在句子中间断开,我们可以将num_tokens参数视为最大值而不是确切的 token 数,在这种情况下,我们可以在生成句号 token 时停止循环。如果你已经理解了这些内容,那么恭喜你,你现在已经大致了解了大语言模型是如何工作的。你是否对更多细节感兴趣?在下一部分,我会更深入一些,但仍然尽量避免涉及支撑这一技术的数学原理,因为它相当复杂。
模型训练
在不使用数学表达式的情况下讨论如何训练模型实际上是很困难的。我将从一个非常简单的训练方法开始展示。
鉴于任务是预测其他词元后面的词元,一种简单的训练模型的方法是获取训练数据集中所有连续词元对,并用它们构建一个概率表。
让我们用一个简短的词汇表和数据集来做这个。假设模型的词汇表包含以下五个词元:
['I', 'you', 'like', 'apples', 'bananas']
为了使这个例子简短而简单,我不会将空格或标点符号视为词元。
我们使用一个由三句话组成的训练数据集:
我们可以构建一个 5×5 的表格,并在每个单元格中写下代表该单元格行的词元后面紧跟代表该单元格列的词元的次数。以下是从数据集中这三句话构建的表格:
希望这很清楚。数据集中有两次出现“我喜欢”,一次出现“你喜欢”,一次出现“喜欢苹果”和两次出现“喜欢香蕉”。
现在我们知道每对词元在训练数据集中出现的次数,我们可以计算每个词元相互跟随的概率。为此,我们将每行中的数字转换为概率。例如,表格中间一行的词元“喜欢”后面跟一次“苹果”和两次“香蕉”。这意味着“喜欢”后面 33.3% 的时间是“苹果”,剩下的 66.7% 的时间是“香蕉”。
以下是计算出所有概率后的完整表格。空单元格的概率为 0%。
– I you like apples bananas I 100% you 100% like 33.3% 66.7% apples 25% 25% 25% 25% bananas 25% 25% 25% 25% 对于“I”、“you”和“like”行来说,计算很简单,但“apples”和“bananas”行却出现了问题,因为它们没有任何数据。由于数据集中没有任何示例显示这些 Token 后面跟随其他 Token,这里我们的训练中存在一个“空洞”。为了确保模型在缺乏训练的情况下仍能生成预测,我决定将“apples”和“bananas”后续 Token 的概率平均分配到其他四个可能的 Token 上,这显然可能会产生奇怪的结果,但至少模型在遇到这两个 Token 时不会卡住。
训练数据中的空洞问题实际上非常重要。在真正的大语言模型中,训练数据集非常庞大,因此你不会发现像我上面这个小例子中那样明显的训练空洞。但由于训练数据覆盖率低而导致的小的、更难检测到的空洞确实存在并且相当普遍。在这些训练不足的区域中,大语言模型对 Token 的预测质量可能会很差,但通常是以难以察觉的方式。这是大语言模型有时会产生幻觉的原因之一,这种情况发生在生成的文本读起来很流畅但包含事实错误或不一致时。
使用上面的概率表,你现在可以想象
get_token_predictions()函数的实现方式。在 Python 伪代码中它可能是这样的:def get_token_predictions(input_tokens):
last_token = input_tokens[-1]
return probabilities_table[last_token]
比想象的更简单,对吧?这个函数接受一个由用户提示词生成的序列。它取序列中的最后一个 Token,并返回该 Token 在概率表中对应的那一行。
例如,如果你用
['you', 'like']作为输入 Token 调用这个函数,那么该函数会返回 “like” 的那一行,”like” 会给予 “apples” 33.3% 的概率来继续句子,而 “bananas” 则是另外的 66.7%。根据这些概率,上面展示的select_next_token()函数每三次应该会选择一次 “apples”。当 “apples” 被选为 “you like” 的延续时,句子 “you like apples” 就会形成。这是一个在训练数据集中不存在,但完全合理的原创句子。希望你开始了解这些模型如何通过重用模式和拼接它们在训练中学到的不同部分来生成看似原创的想法或概念。
上下文窗口
我在上一节中训练我的小型语言模型的方法称为马尔可夫链。
这种技术的一个问题是,只使用一个 Token(输入的最后一个)来进行预测。任何出现在最后一个 Token 之前的文本在选择如何继续时都没有影响,所以我们可以说这种解决方案的_上下文窗口_等于一个 Token,这个窗口非常小。由于上下文窗口如此小,模型会不断“忘记”思路,从一个词跳到另一个词,缺乏一致性。
可以通过构建一个更大的概率矩阵来改进模型的预测。为了使用两个 Token 的上下文窗口,需要增加额外的表行,这些行代表所有可能的两个 Token 序列。在示例中使用的五个 Token 中,每一对 Token 将在概率表中新增 25 行,加上已经存在的 5 个单 Token 行。模型将不得不再次训练,这次不仅看 Token 对,还要看 Token 组的三元组。在每次
get_token_predictions()函数的循环迭代中,当可用时,将使用输入的最后两个 Token 来查找较大概率表中的对应行。但是,2 个 Token 的上下文窗口仍然不够。为了生成一致且至少有基本意义的文本,需要更大的上下文窗口。没有足够大的上下文,新生成的 Token 不可能与之前 Token 中表达的概念或想法相关联。那么我们该怎么办呢?将上下文窗口增加到 3 个 Token 将为概率表增加 125 行,并且质量仍然很差。我们需要将上下文窗口扩大到多大?
OpenAI 开源的 GPT-2 模型使用了一个 1024 tokens 的上下文窗口。为了使用马尔可夫链实现这么大的上下文窗口,每行概率表都必须代表一个长度在 1 到 1024 tokens 之间的序列。使用上面示例中的 5 tokens 词汇表,有 5 的 1024 次方种可能的序列长度为 1024 tokens。需要多少表行来表示这些?我在 Python 会话中做了计算(向右滚动以查看完整数字):
>>> pow(5, 1024)
55626846462680034577255817933310101605480399511558295763833185422180110870347954896357078975312775514101683493275895275128810854038836502721400309634442970528269449838300058261990253686064590901798039126173562593355209381270166265416453973718012279499214790991212515897719252957621869994522193843748736289511290126272884996414561770466127838448395124802899527144151299810833802858809753719892490239782222290074816037776586657834841586939662825734294051183140794537141608771803070715941051121170285190347786926570042246331102750604036185540464179153763503857127117918822547579033069472418242684328083352174724579376695971173152319349449321466491373527284227385153411689217559966957882267024615430273115634918212890625
这行数太多了!而这只是表的一部分,因为我们还需要长度为 1023 的序列,1022 的序列,等等,一直到 1,因为我们想确保在输入中没有足够 tokens 时也能处理较短的序列。马尔可夫链是有趣的,但它们确实存在一个很大的可扩展性问题。
而且一个 1024 tokens 的上下文窗口已经不再那么好了。随着 GPT-3,上下文窗口增加到 2048 tokens,然后在 GPT-3.5 中增加到 4096。GPT-4 开始时为 8192 tokens,后来增加到 32K,然后又增加到 128K(没错,128,000 tokens!)。现在开始出现上下文窗口为 1M 或更大的模型,这允许在做 tokens 预测时有更好的一致性和回忆。
总之,马尔可夫链使我们以正确的方式思考文本生成问题,但它们有很大的问题,阻止我们考虑其作为可行的解决方案。
从马尔可夫链到神经网络
显然,我们不能再考虑使用概率表的方案,因为合理上下文窗口的概率表会需要庞大的 RAM。我们可以做的是用一个函数来替代概率表,该函数返回 Token 概率的近似值,这些概率是通过算法生成的,而不是存储在一个庞大的表格中。事实上,这正是_神经网络_擅长的任务。
神经网络是一种特殊的函数,它接受一些输入,对这些输入进行计算,然后返回一个输出。对于语言模型来说,输入是表示提示词的 Token,输出是下一个 Token 的预测概率列表。
神经网络之所以被称为“特殊”的函数,是因为它们除了函数逻辑外,还受一组外部定义的_参数_控制。最初,网络的参数是未知的,因此函数产生的输出完全没有用。神经网络的训练过程在于找到能使函数在训练数据集上表现最佳的参数,假设如果函数在训练数据上表现良好,那么在其他数据上也会表现良好。
在训练过程中,参数会使用一种称为反向传播的算法进行小幅度的迭代调整,这个算法涉及大量数学运算,所以本文不会详细讨论。每次调整后,神经网络的预测结果会略有改善。参数更新后,网络会再次根据训练数据集进行评估,评估结果用于指导下一轮调整。这个过程会持续进行,直到函数在训练数据集上表现出良好的下一个 Token 预测为止。
为了让你了解神经网络工作的规模,可以考虑 GPT-2 模型有大约 15 亿个参数,而 GPT-3 将参数数量增加到 1750 亿。据说 GPT-4 有大约 1.76 万亿个参数。以现有硬件条件训练这种规模的神经网络需要很长时间,通常是数周或数月。
有意思的是,由于参数众多,都是在没有人为干预的情况下通过漫长的迭代过程计算出来的,因此很难理解模型的工作原理。一个训练有素的大语言模型就像一个黑匣子,非常难以调试,因为模型的大部分“思考”都隐藏在参数中。即使是训练该模型的人也难以解释其内部工作原理。
层、Transformer 和注意力机制
你可能会好奇,在神经网络函数内部发生了哪些神秘的计算,在参数调优的帮助下,可以将一列输入 token 转换为合理的下一个 token 的概率。
一个神经网络被配置为执行一系列操作,每个操作称为一个“层”。第一层接收输入,并进行某种转换。转换后的输入进入下一层,再次被转换。如此反复,直到数据到达最后一层,并进行最后一次转换,生成输出或预测结果。
机器学习专家设计出不同类型的层,对输入数据进行数学转换,并找出如何组织和组合层以达到预期的结果。有些层是通用的,而有些层则专门设计用于处理特定类型的输入数据,如图像或在大语言模型中的 token 化文本。
如今在大语言模型中用于文本生成最流行的神经网络架构称为 Transformer。使用这种设计的大语言模型被称为 GPTs,即生成式预训练 Transformer。
Transformer 模型的显著特点是其执行的一种称为注意力机制的层计算,这使得它们能够在上下文窗口中的 token 之间推导出关系和模式,并将这些关系和模式反映在下一个 token 的概率中。
注意力机制最初用于语言翻译器,作为一种找到输入序列中最重要的 token 以提取其含义的方法。这种机制使得现代翻译器能够在基本层面上“理解”一个句子,通过关注(或将“注意力”引向)重要的词或 token。
大语言模型是否具有智能?
到现在,你可能已经开始对大语言模型在生成文本的方式上是否表现出某种形式的智能形成一种看法。
我个人并不认为大语言模型具备推理能力或提出原创思想的能力,但这并不意味着它们毫无用处。由于它们在上下文窗口中的 token 上进行的巧妙计算,大语言模型能够发现用户提示中存在的模式,并将这些模式与训练期间学到的类似模式相匹配。它们生成的文本主要由训练数据的片段组成,但它们将词(实际上是 token)拼接在一起的方式非常复杂,在许多情况下,产生的结果感觉是原创且有用的。
鉴于大语言模型容易产生幻觉现象,我不会信任任何大语言模型直接将输出交给终端用户的工作流程,而不经过人工验证。
未来几个月或几年内出现的更大规模的大语言模型会实现类似于真正智能的东西吗?我觉得这在 GPT 架构下不会发生,因为它有很多限制,但谁知道呢,也许通过未来的一些创新,我们会实现这一目标。
结束
感谢你坚持读到最后!我希望我已经引起了你的兴趣,让你决定继续学习,并最终面对那些你无法避免的可怕数学,如果你想理解每一个细节。在这种情况下,我强烈推荐 Andrej Karpathy 的 Neural Networks: Zero to Hero 视频系列。