
包阅导读总结
1. 关键词:Elasticsearch、分布式存储、分析检索、数据同步、关联查询
2. 总结:本文围绕 Elasticsearch 的核心特性,介绍了分布式存储特性(节点、集群、分片、副本等概念)和分析检索能力(倒排索引、分析器等),还阐述了查询类型、分页实现、关联查询方案以及数据同步方式。
3. 主要内容:
– Elasticsearch 核心特性:
– 分布式存储特性:
– 节点:单个 Elasticsearch 实例。
– 集群:节点的集合。
– 分片:索引的片段。
– 副本:分片的拷贝。
– 分析检索能力:
– 倒排索引:高效检索文档的关键数据结构。
– 分析器:文本预处理组件。
– 查询类型:
– 单词级别查询。
– 全文级别查询。
– Bool 查询。
– 分页实现:sort+Search After 分页,可手动构建 nextToken 分页条件。
– 关联查询方案:
– 父子文档,但存在限制。
– 服务端 JOIN。
– 宽表冗余存储。
– 数据同步:
– 手动写入。
– 数据同步工具,如阿里云 DTS、ES 套件 Logstash。
思维导图: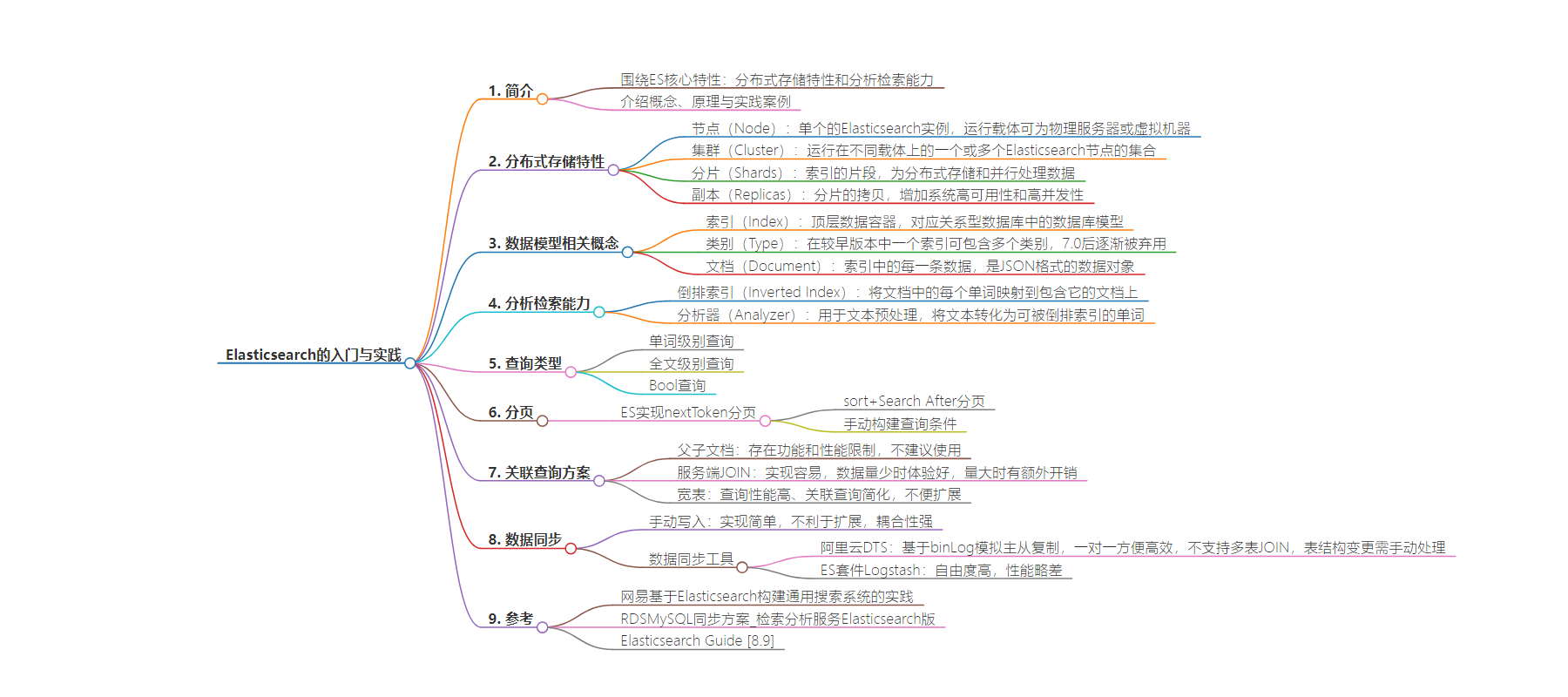
文章地址:https://mp.weixin.qq.com/s/wlh2AHpNLrz9dHxPw9UrkQ
文章来源:mp.weixin.qq.com
作者:剑洁、雲尧
发布时间:2024/8/12 10:16
语言:中文
总字数:5551字
预计阅读时间:23分钟
评分:89分
标签:Elasticsearch,分布式存储,分析检索,数据同步,倒排索引
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com

Elasticsearch(ES)是一种基于分布式存储的搜索和分析引擎,目前在许多场景得到了广泛使用,比如维基百科和github的检索,使用的就是ES。ES中不乏纷繁冗余的细节,而本文将关注其核心特性:分布式存储特性和分析检索能力。围绕这两大核心特性,本文将介绍其中的概念、原理与实践案例,希望让读者快速理解ES的核心特性与应用场景。
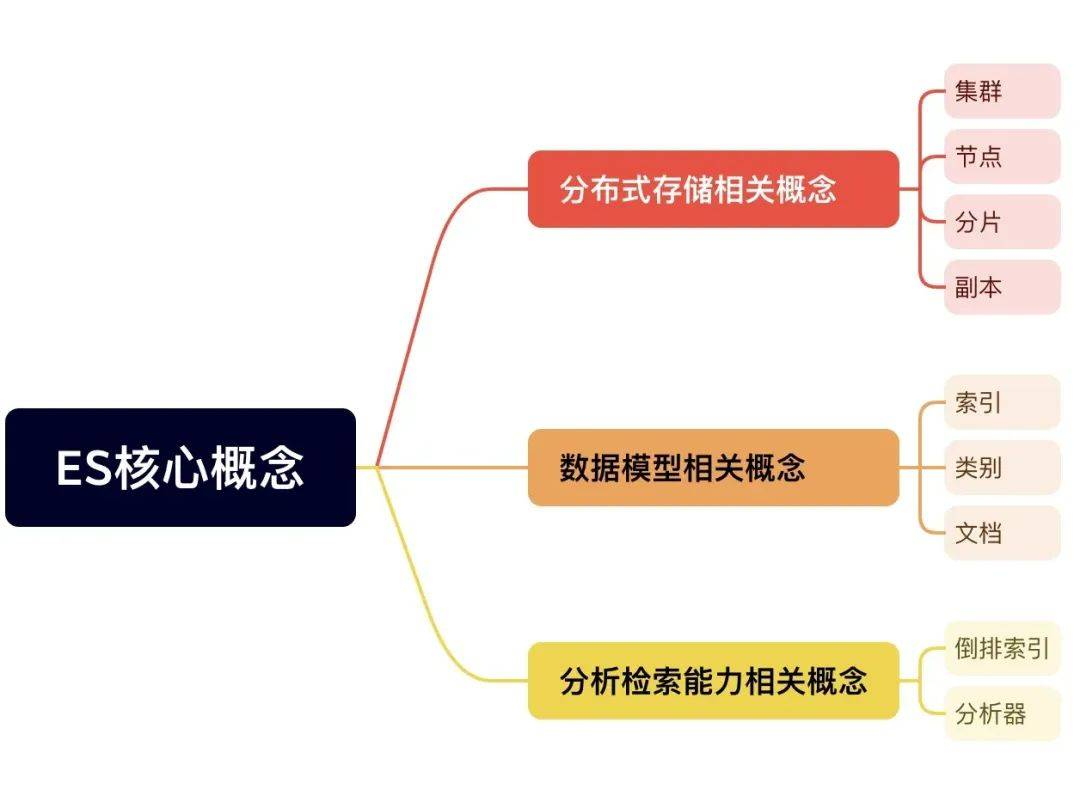
分布式存储特性相关概念:
节点(Node)
节点就是单个的Elasticsearch实例,该实例运行的载体可以是物理服务器或虚拟机器。
集群(Cluster)
集群是节点的集合。
集群是一组运行在不同载体(物理或虚拟机器)上的一个或多个Elasticsearch节点的集合。在集群内,节点间相互合作,对数据进行存储和管理。
分片(Shards)
分片是索引的片段。
受制于单个ES节点的性能上限(内存、磁盘IO速度),如果数据以整块形式进行存储与管理,则无法足够快速地响应客户端的请求,因此ES将索引拆分为更小块的分片,以便分布式存储和并行处理数据。
副本(Replicas)
副本是分片的拷贝。
每个分片可以有零个或者多个副本,副本与分片对外都可以提供数据查询服务。副本的存在可以增加整个ES系统的高可用性,高并发性,因为分片能做到的事情,副本也能做到。计算机世界里没有银弹,副本的开销主要体现在数据同步成本的增加(每次数据更新时,都需要把分片上的数据变更同步到其他副本中)。
数据模型相关概念
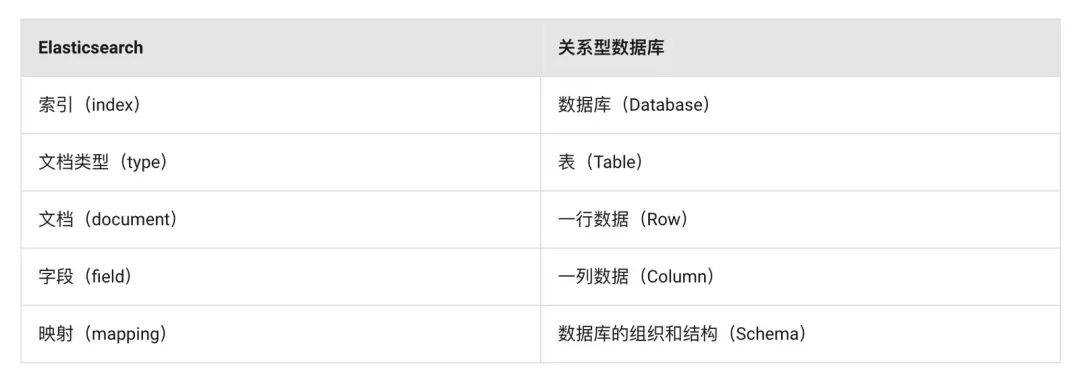
索引(Index)
索引由一个或多个分片组成。索引是Elasticsearch中的顶层数据容器,对应关系型数据库中的数据库模型。
类别(Type)
类别在较早的Elasticsearch版本中,一个索引可以包含多个类别,每个类别用于存储不同种类的文档。对应关系型数据库中的数据表。然而,在Elasticsearch 7.0以后,类别逐渐被弃用。原因是同一索引下,不同type的数据存储其他type的field,包含大量空值,造成资源浪费。
文档(Document)
索引中的每一条数据叫作一个文档,它是一个JSON格式的数据对象。对应关系型数据库中的数据行。这一点与非关系型数据库MongoDB很类似,MongoDB属于文档数据库,每条数据也是一个BSON文档(BinaryJSON)。非关系型数据库的文档相比关系型数据库的数据行,优势在于提供了更高的自由度,文档中可以方便地新增减字段,多个文档间也不要求字段完全一致。同时,文档也保留了一部分结构化存储的特性,对存储的数据进行了一定的结构化封装,而没有像K-V非关系型数据库那样完全抛弃数据的结构化。
分析检索能力相关概念
倒排索引(Inverted Index)
倒排索引是Elasticsearch中用于高效检索文档的关键数据结构。它是将文档中的每个单词映射到包含它的文档上。这种数据结构使得Elasticsearch能够高效地处理文本信息这类非结构化数据,相比传统关系型数据库的正排索引遍历整个数据表,它能够高效地进行文本检索与分析。
正排索引是从文档到关键字的映射(已知文档求关键字),倒排索引是从关键字到文档的映射(已知关键字求文档)。倒排索引由两个主要部分组成:词汇表(Vocabulary)和倒排列表(Inverted List)。词汇表存储了所有不同的单词,而倒排列表存储了每个单词文档中的分布情况。
分析器(Analyzer)
分析器是Elasticsearch用于进行文本预处理的组件。它的主要作用是将文本转化为可被倒排索引的单词(term)。分析通常由以下几个步骤组成:
在阿里云DTS数据同步工具中,可以选择一系列ES内置的分析器,但是Elasticsearch的内置分析器对于中文的支持较差,采取了暴力拆分每个中文单字的策略。如果希望对中文进行合适的分词,可以选择第三方分词器,比如jieba分词器。
基于以上的核心概念,Elasticsearch通过分布式存储结构和分析检索能力,支持并提供了多种不同类型的查询能力,用于满足各种检索需求。以下是ES中主要的查询类型:
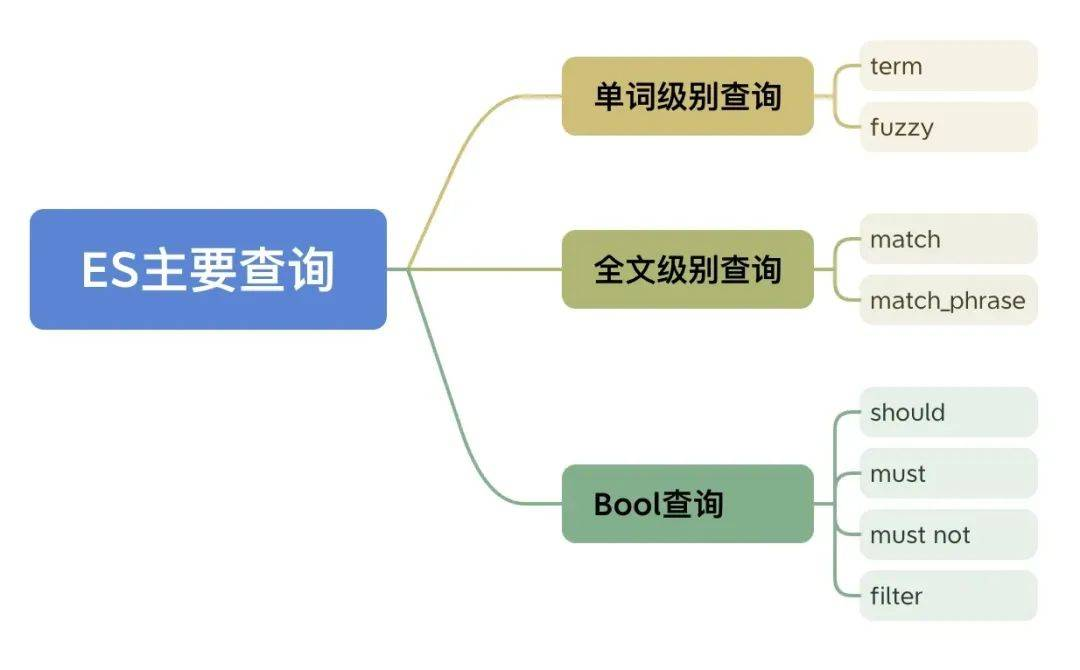
单词级别查询
万丈高楼平地起,优秀的全文索引能力是由基础的单词查询能力支撑的。
-
最基础的ES查询,把输入字符串全部看作一个完整的单词,然后去倒排索引表里面找。
全文级别查询
像使用match和match_phrase这样的高层查询都属于全文级别查询,全文级别查询是对多个/多种单词级别查询的封装。
i.检查字段类型,查看字段是analyzed还是not_analyzed;
ii.分析查询字符串,将输入字符串进行分词,对分出来的每个单词,根据是否设置了模糊度参数fuzziness,选择走term query或者fuzzy query;
Bool查询
用于实现复杂的组合查询逻辑,具体有四种:
逻辑完备性:足够数量的或且非,可以实现任何逻辑。
Term Query的文档相关度得分计算方式
利用倒排索引,对于输入的单词,考虑每个文档的以下指标:
综合这两个指标得出每个文档的相关度评分_score。
Elasticsearch实现nextToken分页
在服务端开发的实践中,由于数据量大,不可能一次请求一次查询就返回全部数据。因此,对数据进行分页查询是一种常见的工程实践。而由于ES方便处理非结构化字段的能力,常常被用作搜索框API中的主力分页查询。
在ES中,内置的分页机制为sort+Search After分页。它会对每次请求生成一个游标字段,这就相当于标记了上一页的结束位置,因此下次请求只要从上一次的游标字段开始,就能够方便地查找下一页。这实际上是ES官方提供的一种nextToken分页实现,它省略掉了构建游标这一过程,只需要使用者在查询条件中给定排序字段:
GET /service_version_index/service_version_type/_search{"size": 100,"sort": [{"gmt_modified": "desc"},{"score": "desc"},{"id": "desc"}],...}
sort+Search After就能在查询结果中方便地生成每一页在特定排序上的游标。
{"sort" : [1614561419000,"6FxZJXgBE6QbUWetnarH"]}
下次查询带上这个游标,就可以快速定位到上一页的结束位置,开始下一页的查询:
GET /service_version_index/service_version_type/_search{"size": 100,"sort": [{"gmt_modified": "desc"},{"score": "desc"},{"id": "desc"}],"query": {......},"search_after": [1614561419000,"6FxZJXgBE6QbUWetnarH"]}
我们也可以手动构建查询条件,手动实现nextToken分页条件。即使你不熟悉nextToken分页和ES查询的具体用法,你也应该能做出以下判断:你一定可以用ES的查询条件实现任意的nextToken分页逻辑。理由是ES的Bool查询具有逻辑完备性。
具体地,一个简单的if-else逻辑,可以用ES的基础查询来复现:
if A then B else C => (A must B) should (must not A must C)
类似地,任意复杂的查询条件,都可以实现了。
这样做的好处是,如果项目中涉及到多种数据库的分页,则后端代码的分页逻辑可以共用,只需要在不同的数据库中实现相同的nextToken条件:
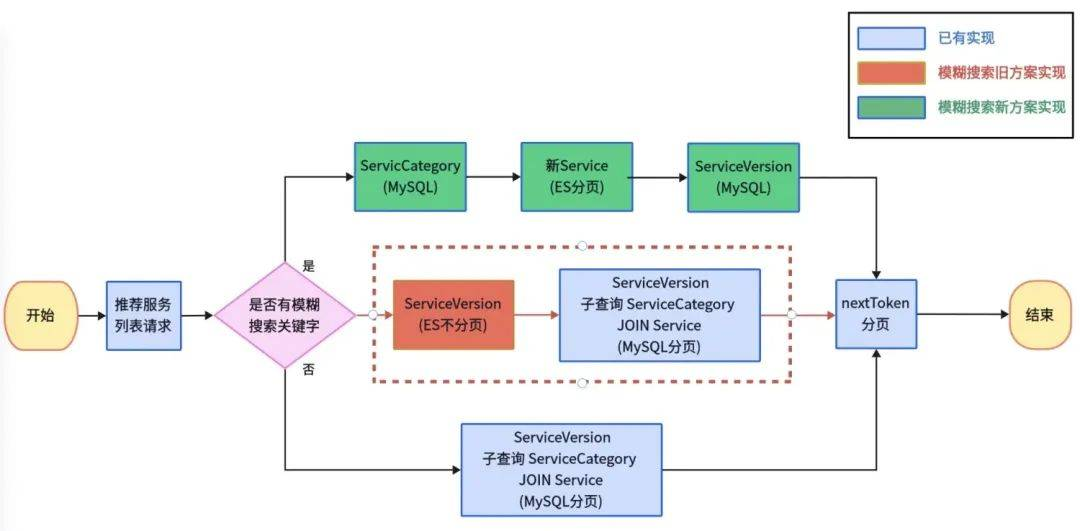
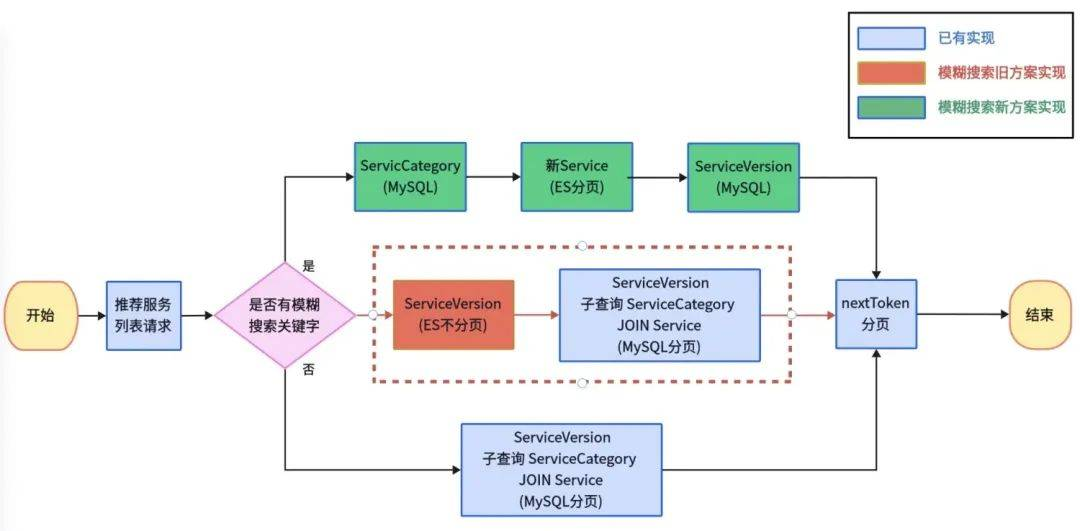
在上述项目中,一个API服务使用到了两条查询链路:一条纯MySQL的查询链路,另一条ES分页+MySQL补字段的查询链路。由于在ES分页中,我们已经手动复现了MySQL中的nextToken分页条件。因此,在查询结束后,封装nextToken分页请求的这部分后端逻辑就可以实现复用。如果MySQL基于自实现的nextToken分页而ES使用官方推荐的Sort分页,则复用性较差,需要两套分页逻辑。
关联查询方案:
ES与非关系型的文档数据库类似,基于文档存储数据,没有固定的表结构。关系型数据库以二维表结构的形式来组织数据,并擅长提供对数据表间关系的管理。而ES以文档为数据的组织形式,进行扁平化存储,它不擅长进行关系管理而擅长对扁平化的文档进行文本检索。
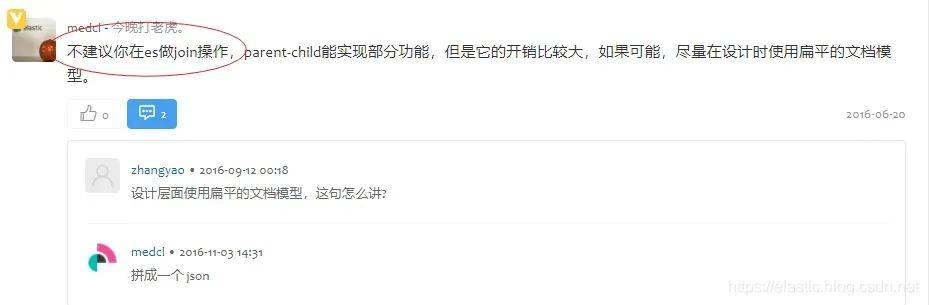
在ES中,由于其分布式存储特性和非关系性数据模型,类似关系型数据库中JOIN联表查询这样的操作将非常不便。ES内置了类似MySQL的JOIN的关联查询实现:父子文档,但它存在功能和性能上的限制:父子文档需要在在同一个分片中,额外实现关系管理需要的成本。ES官方通常不建议使用这种方式。
在ES中,如果要实现关联查询,最佳实践一般为构建宽表或采取服务端JOIN这种折中方案。
服务端JOIN
ES中分两个索引来存储数据,查询时在服务端的业务代码内进行两次查询,将第一次查询的结果作为第二次查询的条件。
好处:实现容易,数据量少时用户体验好。
坏处:数据量大时,两次查询会带来额外的开销,因为每次查询都需要建立连接、发送请求……
拓展:如果涉及不同数据库之间的关联查询,也可以采用此方案,比如用ES处理有限的文本字段,查得一个id列表,然后把这个id列表给MySQL的完整查询作为条件,补齐剩下的字段。
宽表冗余存储:
宽表:通俗地讲就是字段很多的数据库表。指的是把特定的查询业务需求所需要的全部字段都关联在一起的一张数据库表。由于关联了大量冗余字段,宽表已经不符合数据库设计的三范式,而因此获得的好处就是查询性能的提高与关联查询的简化(避开了查询时JOIN)。这是一种典型的空间换时间的优化思路。但宽表不便扩展,如果业务需求有变化,哪怕是需要新增一个字段,都需要变更宽表。
窄表:严格按照数据库设计三范式设计的数据表。这种表的设计形式减少了数据冗余,但是实现一个复杂查询要使用很多张表,涉及多表JOIN问题,可能会影响性能。其特点是方便扩展,多个窄表可以组合并适应多种业务场景,无论有多少不同的场景,都不用修改原本的表结构。但在查询逻辑和代码逻辑上需要进行封装。
如果对查询速度性能要求较高,建议选择宽表。
数据同步
由于ES擅长检索而不是存储,业务场景中很少会以ES作为主力做数据存储,而是使用关系型数据库进行存储,在需要ES时再构建需要的数据并进行同步。具体来说,有手动写入和数据同步工具等方案。
手动写入
在已有的业务逻辑中,同步或异步地增加对ES的增删改查。实现简单,但不利于扩展,耦合性较强。
数据同步工具
阿里云DTS:
是阿里云提供的一种云服务产品,基于binLog模拟主从复制实现数据同步。一对一数据同步方便高效,但对多表JOIN场景无法支持。如果表结构出现变更,则需要手动删除目标ES库,重建同步任务。
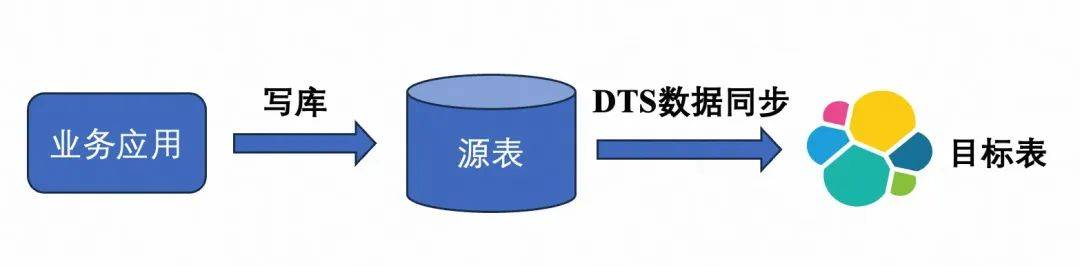
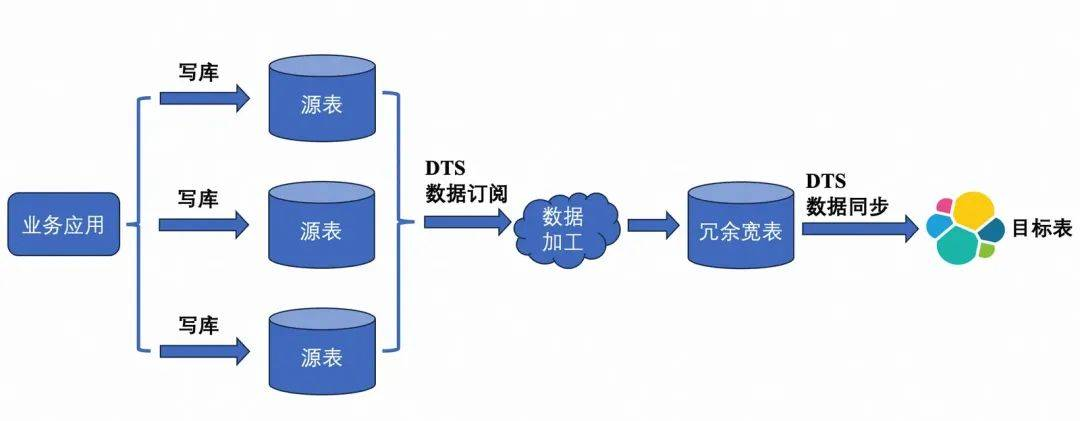
如果我们搭建一个中间层,将多表JOIN结果先写入一个冗余的MySQL宽表,再同步到ES,则数据同步可以使用简单高效的DTS。代价是整个同步链路环节增多,不稳定性增加了。
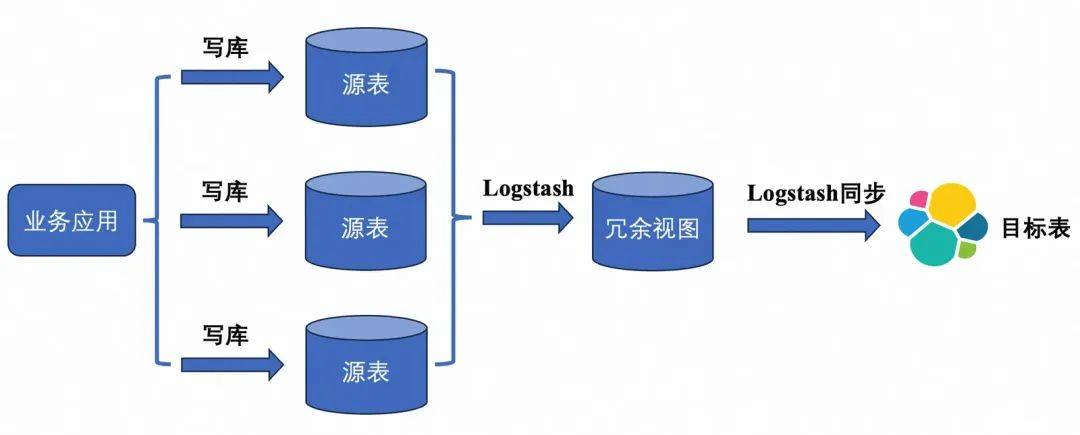
ES套件Logstash:
是ES官方套件系列中的数据同步工具。支持在config配置文件中写入需要的SQL逻辑并存储为视图,并通过视图来写入多表查询的结果到ES。这种方式自由度较高,能够方便地构建所需要的数据。但是数据同步的性能略差(秒级别)。
CREATE VIEW my_view ASSELECT sv.*, s.score, sc.categoryFROM service_version svJOIN service s ON sv.service_id = s.service_idJOIN service_category sc ON s.service_id = sc.service_id;
https://help.aliyun.com/zh/es/use-cases/select-a-synchronization-method
参考:
[1] 网易基于 Elasticsearch 构建通用搜索系统的实践 – 分享 – Elastic 中文社区:https://elasticsearch.cn/slides/243#page=20
[2] RDSMySQL同步方案_检索分析服务Elasticsearch版-阿里云帮助中心:https://help.aliyun.com/zh/es/use-cases/select-a-synchronization-method
[3] Elasticsearch Guide [8.9] | Elastic:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
本方案使用阿里云多端低代码开发平台魔笔低代码快速搭建适配于微信、支付宝等多平台的小程序,帮助您提升开发效率、降低维护成本。
点击阅读原文查看详情。