
包阅导读总结
1. 朴朴 APM、头部采样、降本增效、链路完整性、云原生可观测性
2. 朴朴业务增长致 APM 成本高,通过存储替换、T+1 尾采样仍成本高,自研头部采样方案,基于业务规律和用户需求设置采样规则和策略,保证链路完整性,上线后成本减半,未来计划进一步降低成本。
3.
– 背景
– 朴朴业务增长,拥抱微服务等技术,APM 数据量剧增,成本高、性能降。
– 优化措施
– 存储替换:从 Elasticsearch 换为 ClickHouse,降低存储成本。
– T+1 尾采样:降低存储成本和提升查询速度。
– 头部采样:自研方案,设定目标。
– 方案设计
– 分析规律:二八原则、consumer 服务占大头等。
– 考虑需求:异常等链路全保留等。
– 采样规则设置:用户可针对服务设置。
– 采样策略:包括默认、span 全采样等 4 种。
– 保证链路完整性:服务分层、染色等。
– 成果与规划
– 成果:上报数据量减少,机器数量减少,成本减半。
– 规划:进一步提高采样丢弃比例降成本。
思维导图: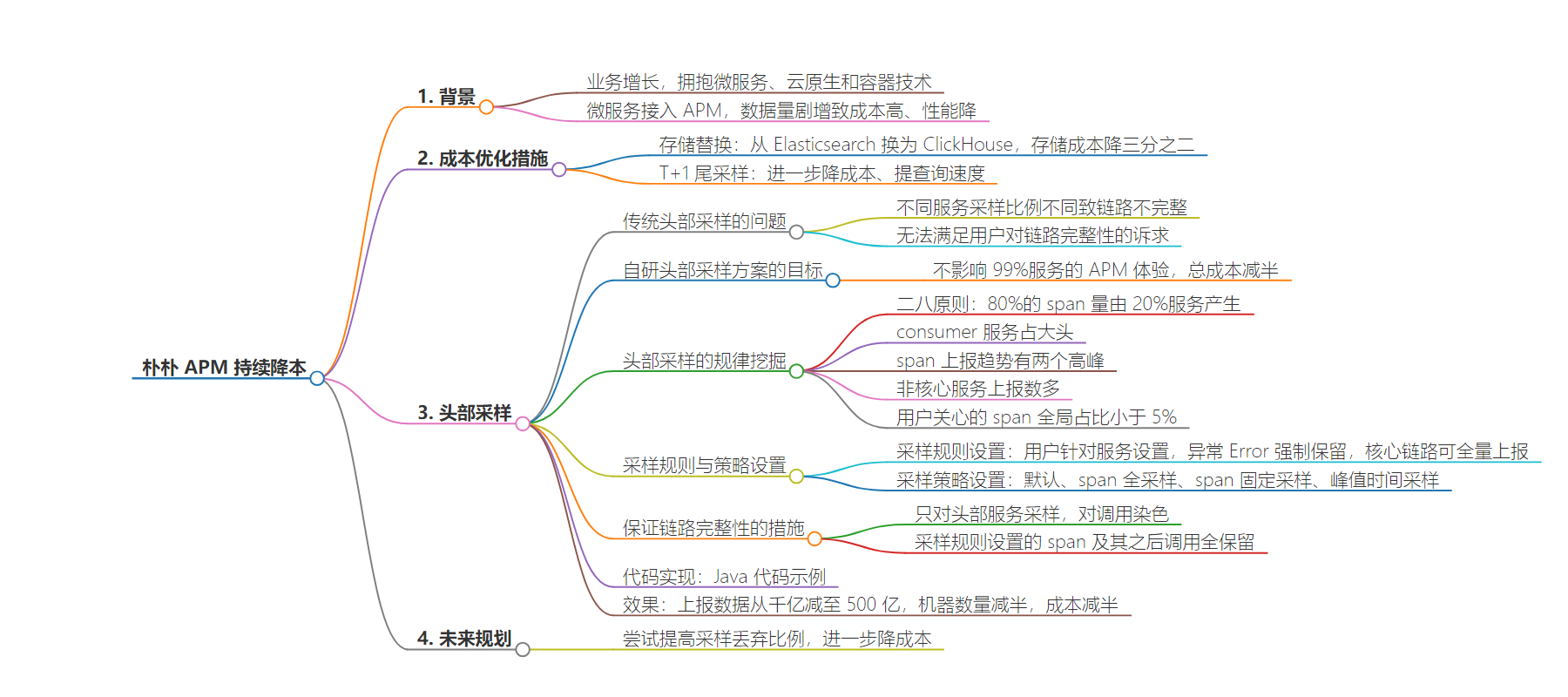
文章地址:https://mp.weixin.qq.com/s/PtN99r5RcbYKpo9u-JmM1A
文章来源:mp.weixin.qq.com
作者:朴朴科技平台组
发布时间:2024/8/13 10:07
语言:中文
总字数:4115字
预计阅读时间:17分钟
评分:91分
标签:APM优化,成本降低,头部采样,朴朴科技,微服务
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
随着朴朴业务的迅猛增长,朴朴全面拥抱微服务、云原生和容器技术。在云原生可观测性方面,朴朴几乎所有的微服务都接入了朴朴 APM,以帮助开发者快速定位、分析和诊断问题。然而,随着业务复杂度和服务数量的不断增加,上报给朴朴 APM 的数据量也急剧增加,导致 IT 成本越来越高,同时用户查询 APM 的性能也急剧下降。
为了响应公司的降本增效的理念,我们将朴朴 APM 的存储从 Elasticsearch 替换为 ClickHouse,使得同样性能下,将存储成本降低三分之二,可参考文献《存储成本降低 80%,查询效率提升 5 倍,朴朴 APM 链路采样实战》;考虑到历史数据的存储能否只存储对用户有意义的数据,我们进行了 T+1 尾采样,使得存储成本进一步降低且查询速度更快,可参考文献《存储成本降低 80%,查询效率提升 5 倍,朴朴 APM 链路采样实战》。
尽管我们做了上述两个重大优化成本的措施,但是朴朴 APM 的成本仍然较高,于是我们考虑能否直接进行头部采样,在源头抛弃掉无意义的 Span,从而使得消息队列、OAP 以及 CK 的成本直接降低,同时更高的信噪比也能够提升查询性能。
传统的头部采样方案是基于服务维度对整段链路唯一标识 TraceId 的 Hash 值取模,然后设置采样比例,对模小于固定值的链路进行入库,这种头部采样实现逻辑较较简单,但是没办法保证链路的完整性。在图 1 中,我们给出一个传统头部采样 – 服务采样比例不同时的可能效果图,其中,服务 A、服务 B、服务 C 的头部采样比例分别是 50%、25% 以及 100%,且服务的调用关系是服务 A ->服务 B ->服务 C,其中蓝色的是采样保留的链路数据,红色是被丢弃的链路数据,可以看到 4 条链路中,仅有 1 条链路是完整的。
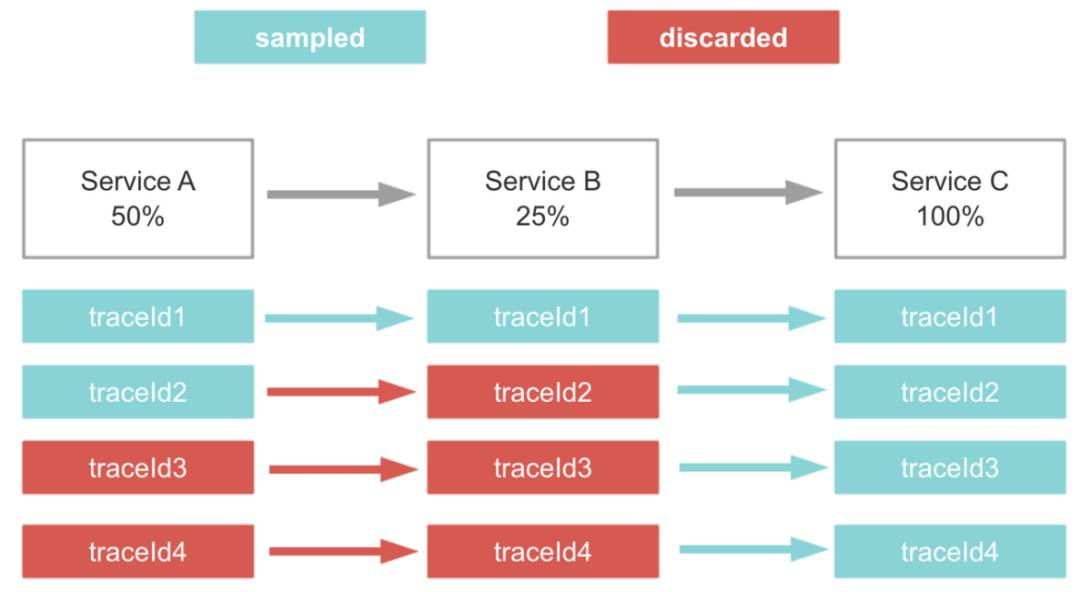
图 1 传统头部采样 – 服务采样比例不同时的可能效果图
除了上述由于不同服务头部采样比例不同导致链路不完整外,我们还发现用户对异常、慢查询以及用户核心链路的完整性有强烈的诉求,比如用户提出头部采样应该至少满足以下:
-
异常或错误链路要全保留:当链路中有一个 span 错误时,需要将全链路的数据进行全保留。
-
慢数据库、慢接口全保留:当链路中出现慢数据库或者慢接口时,需要将该 span 保留下来。
-
核心链路数据要全保留:像一些订单支付等链路的数据,希望能够全链路进行保留。
-
非核心的链路数据支持忽略上报:对于不重要的接口或链路的数据能够支持不上报到朴朴 APM。
显然,传统的头部采样没办法完成上述的需求,因此,我们决定自研一套即能够有效进行头部采样又能够不影响用户对链路完整性的需求的技术方案。我们给整个头部采样制定了如下目标:在不影响 99% 的服务的使用 APM 体验,通过头部采样,达到总成本降低一半,即上报的数据量减少一半。
技术架构或方案的设计必须依赖于对业务的深入了解,因此,我们通过对海量的 span 数据进行分析,发现了如下规律:
-
二八原则:我们 80% 的 span 量是由 20% 的服务产生的。
-
consumer 服务占大头:consumer 服务异步消费 binlog 的 span 数占全部 span 的一半左右。
-
span 上报趋势存在两个高峰:分别是早上 11 点左右和下午 5 点左右,正好是朴朴的 C 端用户高峰期。
-
一些非核心服务上报数太多:我们对服务分级后发现,非核心的服务,比如:大数据的一些服务由于海量数据调用,导致上报的 span 数过多。
-
用户关心的 span 全局占比小于 5%:即在朴朴 APM 中用户每天上报了千亿的数据,实际需要查看的数据比例不到 5%。
有了这些规律之后,我们对每个规律进行挖掘,根据 span 上报量归属服务的二八原则,我们只需要重点让前 20% 的服务进行头部采样即可让全局数据量减少;同时,consumer 服务占大部分上报 span 数,则可以专门对这些服务进行采样,并且观测 consumer 服务上报 span 的特点进行优化;在不考虑弹性扩缩容的前提下,IT 成本取决于能支撑峰值的容量,因此,我们如果能够让 span 上报的两个高峰进行削峰,则相应的 IT 成本也会下降;为了保证投入产出比的最大化,合理的服务、接口分级后,我们可以将非核心的服务或接口进行较高比例的采样;最后,用户关心的 span 占比全局的比例不到 5%,因此我们只需做好剔除用户不关心的 span,尽量保留用户关心的 span。
在进行头部采样前,我们需要尽可能的保证头部采样应该保证用户关心的 span 的数据都上报上去。根据日常线上排查经验,我们发现业务研发主要关心以下优先级高场景:
上述的功能可以在图 2 中用户针对具体的服务进行设置(默认在调用链上出现异常 Error 会强制保留),用户可根据不同服务对关心的 span 的阈值不同进行设置。针对业务场景核心链路要全保留,可以通过接口设置下的全量上报 / 存储来指定添加。
这里需要特别说明的是,采样规则设置中的数据是会被强制保留的,优先级高于下一节中的采样策略设置。
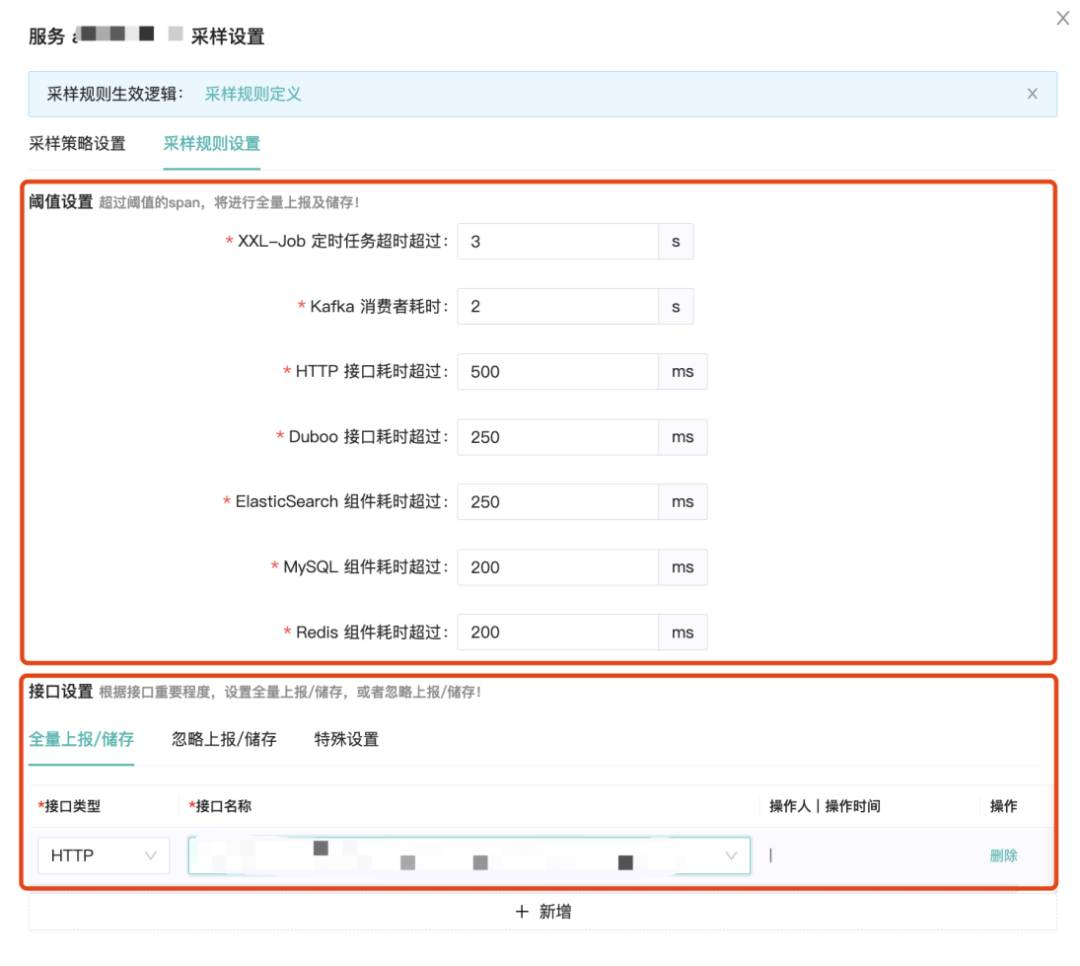
图 2 某个服务服务采样规则设置和接口设置
设置好采样规则后,需要设置对应的采样策略,图 3 为某个服务的采样策略设置,可以看到支持 4 种采样策略,分别为:
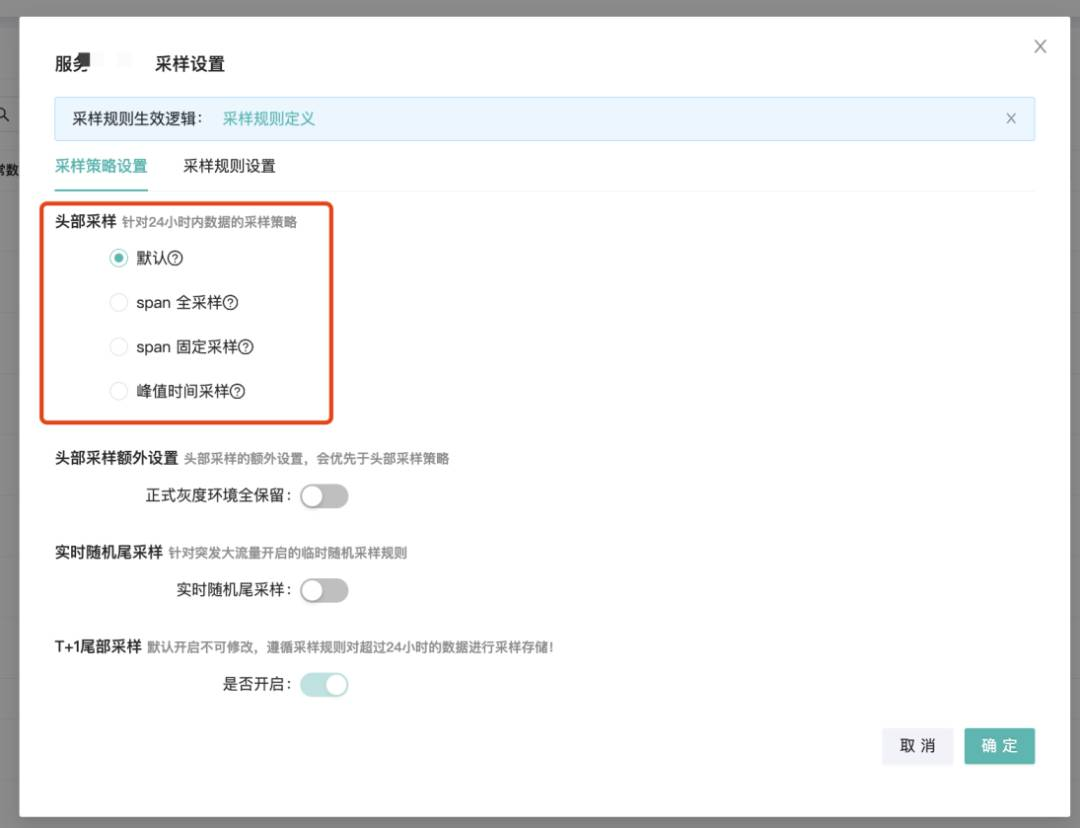
图 3 某个服务的采样策略设置
1. 默认:依赖上游传递是否采样保留标志,如果链路中上游服务是采样保留则该服务的链路数据也会被保留,如果链路中上游服务是丢弃则对应调用该服务的调用数据被丢弃。如果没有传递采样保留标记,则会进行是否全量上报接口以及忽略上报接口的判断,全量上报的接口会可以保证核心链路数据全保留,忽略上报的接口能够让非核心的流量不上报到 APM,除此之外,对于异常等数据会进行保留。
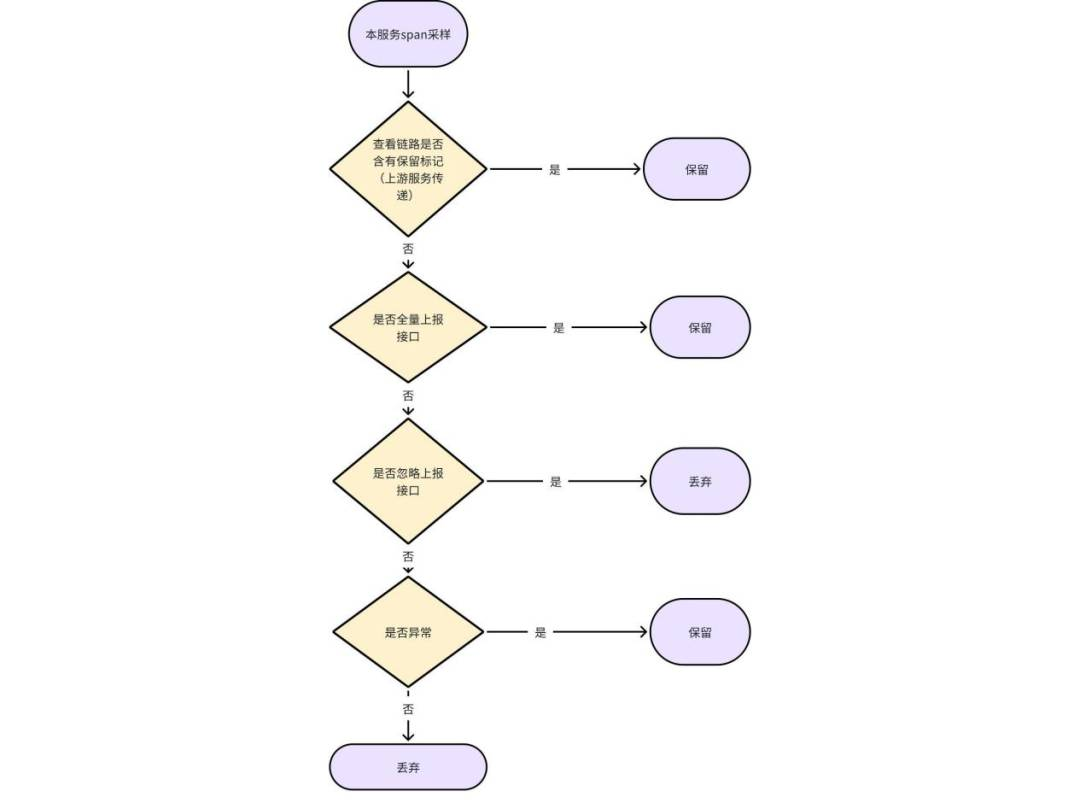
图 4 默认采样策略流程图
2. span 全采样:该条规则比较简单,即保留该服务所有链路数据,如图 5 所示。
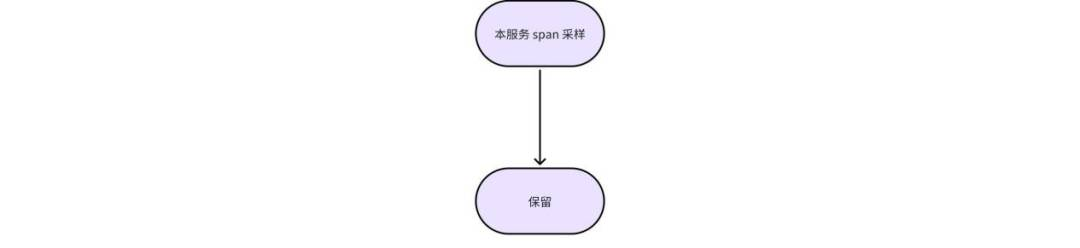
图 5 span 全采样策略流程图
3. span 固定采样:每天按照固定比例采集该服务 span(比如设置比例为 80%,则采集该服务 80% 的 span 数据),其流程如图 6 所示,适用于服务并不是核心服务,但需要对用户关心的 span 进行问题排查。
4. 峰值时间采样:在峰值时间段,即 10:00~12:00 点,16:30~18:30 这两个时间段内开启固定比例的采样。适用于服务为核心服务,不仅需要对「有意义的 Span」进行问题排查,还需要对日常链路进行业务分析,所以只需要对峰值削峰即可,实际的代码执行流程如图 6 所示。
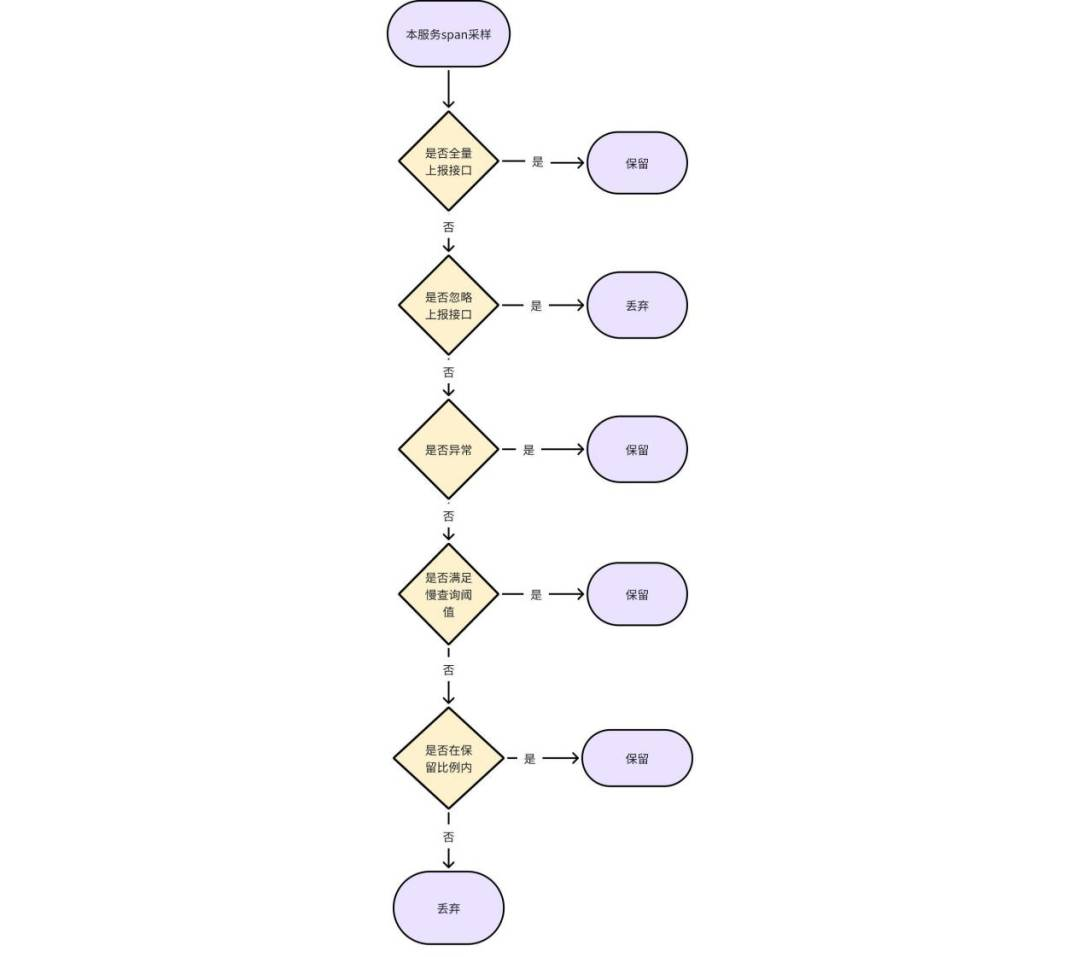
图 6 span 固定采样 / 峰值时间采样流程图
在头部采样挑战这部分内容中我们提到了头部采样对带来链路的不完整性,为此我们对服务进行分层,只对头部服务进行采样,随后对这部分服务的调用进行染色,有被采样的链路之下的所有服务的链路都将被采样,从而保证链路的完整性,我们考虑从业务的特点上进行出发,设计并保证了如下:
-
采样只发生在头部请求的服务:我们对服务进行分层,只对头部服务进行采样,随后对这部分服务的调用进行染色,有被采样的链路之下的所有服务的链路都将被采样,从而保证链路的完整性。
-
采样规则设置的 span 及其之后的调用全保留:用户在采样规则中的设置感兴趣的 span 需要全保留,当系统监测到这部分 span 会自动向下传递保留标记,因此可以做到在不能满足全链路的完整性下,也能让用户关心的 span 以及之后调用的 span 的数据得以保留。举个例子,如果服务 A ->服务 B ->服务 C 的调用链路,如果服务 B span 报错,标识只会往下传递,则服务 C span 肯定会入库。如果 B 服务报错的异常向上游抛出的话,A 服务有感知到,则服务 A span 也会入库。
图 7 给出了链路染色采样的效果示意图,有 3 个服务分别是服务 A、服务 B 以及服务 C,图中蓝色表示采样保留,红色表示采样丢弃,在图中可以看到三种策略:
-
策略命中:即用户设置说要强制保留该服务的某些 span 数据。
-
策略未命中:即用户设置强制忽略上报该服务的某些 span 数据。
-
无策略:即默认情况。
在链路 1 中,由于在服务 A 设置了强制保留该链路的数据,而之后的两个服务的对应为无策略,因此之后的调用链数据都将被保留;链路 2 中 ,服务 A 被设置为策略未命中,即忽略上报这部分的数据,此时服务 B 和服务 C 由于都是默认情况,因此也无需上报数据;链路 3 中,服务 A 被设置为策略未命中,但是服务 B 设置策略命中,服务 C 设置为无策略,按照就近原则,服务 B 和服务 C 的链路数据都将被保留,从而保证了局部链路的完整性;最后一条链路是链路 4,三个服务都进行策略的配置,其中服务 A 和服务 C 设置了策略命中,服务 B 设置为策略未命中,则以各自设置的策略为主进行生效。
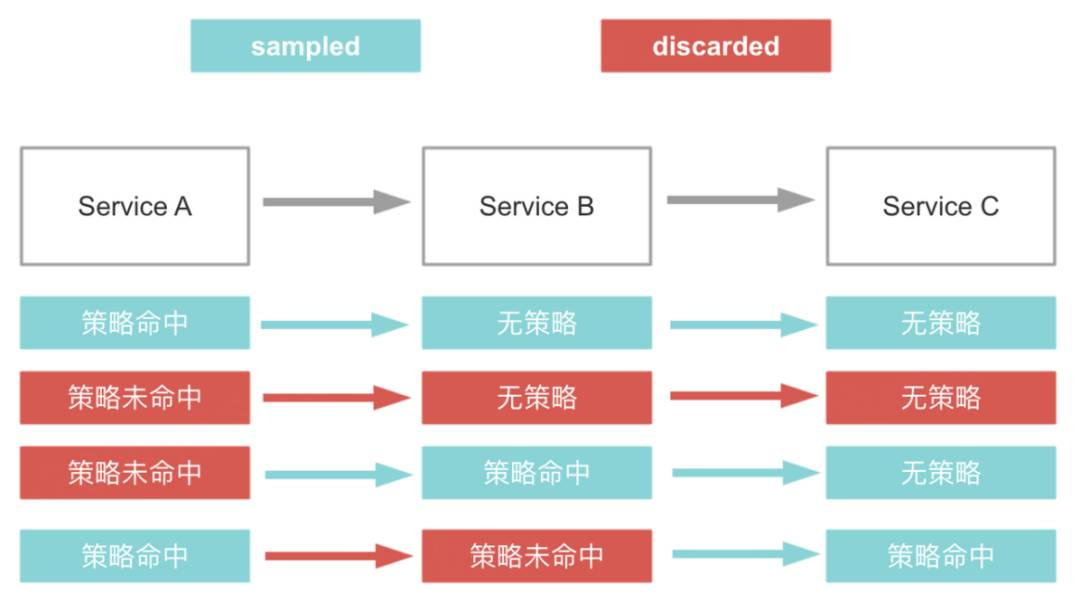
图 7 链路染色采样示意图
具体相关 Java 代码实现如下,这里就不详细展开。
Javapublic class OwlSamplingCarrierItem extends CarrierItem {public static final String HEADER_NAME = "Owl-sampling";private ContextCarrier carrier;public OwlSamplingCarrierItem(ContextCarrier carrier, CarrierItem next) {super(HEADER_NAME, carrier.getSampling() + "", next);this.carrier = carrier;}@Overridepublic void setHeadValue(String headValue) {if (OwlHeadSampleConfigProperties.trySamplingSwitchIsNull()) {carrier.setSampling(Integer.valueOf(headValue == null ? "1" : headValue));}if ("999".equals(headValue)) {carrier.setSampling(999);}}}
朴朴 APM 通过上线头部采样系统后,能够做到不影响大部分服务使用 APM 体验,将原本每日上报千亿条 span,减少到每日上报 500 亿条 span,在表 1 中给出了朴朴 APM 头部采样前后机器数量的变化,通过头部采样,我们将 ClickHouse、Kafka、分析集群的机器数量都减少一半,从而实现用户功能基本不影响,但总成本减半。
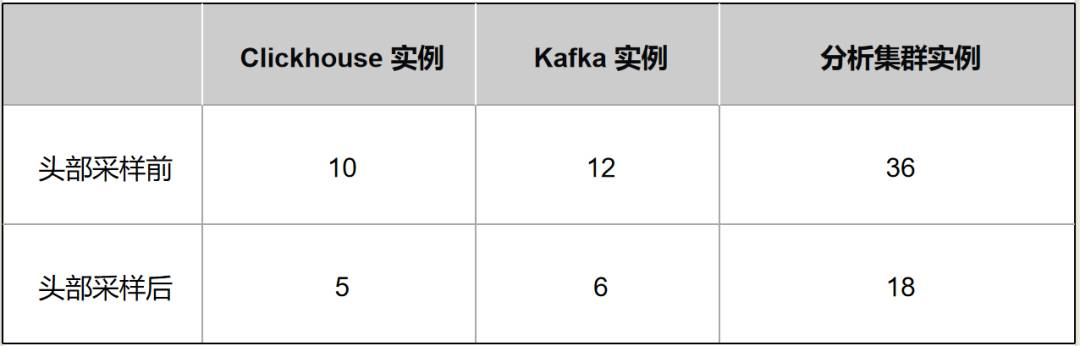
表 1 朴朴 APM 头部采样前后机器数量变化
在落地实践头部采样方案的过程中,我们深刻了解到了好的头部采样不仅能够极大减少机器成本,还能够提高查询性能,截止目前我们的头部采样仅丢弃了总上报数据量的一半,根据我们自己内部统计用户关心的 span 占全局比例不到 5%,因此,在未来的技术规划中,我们会尝试在不影响用户排查问题的情况下,能够进一步将系统的采样丢弃比例提高上去,从而进一步降低 APM 成本。