
包阅导读总结
1. 关键词:LLMs、Configuration、Happy Path、Expert Attention、Creativity
2. 总结:本文探讨了在复杂系统中如何借助 LLMs 找到快乐路径,如解决配置问题和编码难题。还提到 LLMs 能重组专家注意力,加速解决问题,虽有质疑其创造性,但作者认为它是人类创造力的放大器。
3. 主要内容:
– 作者个人学习风格常走弯路,但在复杂系统中更希望走快乐路径。
– 配置是复杂系统中的难题,以处理 Google Docs 相关问题为例,涉及 API 学习和认证等困难。
– 他人走过相同路径,LLMs 能提供间接帮助,可充当同事代理,减少专家干扰。
– 展示而非讲述能改变局面,如截图辅助解决问题。
– 让 LLMs 写详细注释的正则表达式,能快速解决编码问题。
– 虽有人质疑 LLMs 创造性,但它能重组知识,是人类创造力的放大器。
思维导图:
文章地址:https://thenewstack.io/how-llms-guide-us-to-a-happy-path-for-configuration-and-coding/
文章来源:thenewstack.io
作者:Jon Udell
发布时间:2024/8/9 13:39
语言:英文
总字数:1586字
预计阅读时间:7分钟
评分:90分
标签:大型语言模型,配置,编码,Google Docs API,专家知识
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
We all have different learning styles. Mine, sadly, involves trying all the wrong ways to do a thing before I finally arrive at the right thing. This is not always bad. You can learn a lot about a complex system by exploring all of the unhappy paths, and that learning can be valuable. But often you just want to walk the happy path and proceed as quickly as possible to a destination.
As our systems grow ever more complex, layered and interdependent, unhappy paths multiply.
There is no technical realm more crisscrossed with unhappy paths than configuration. As our systems grow ever more complex, layered and interdependent, those unhappy paths multiply. We all know about the traditional hard problems: cache invalidation, naming, off-by-one errors. I think configuration is the new — and even more vexing — hard problem.
This week I needed to expand on the solution described in Human Insight + LLM Grunt Work = Creative Publishing Solution. Using Google Docs to write and collaboratively review documentation, which then converts to the Markdown that powers our sites, has solved a big problem. It has also, inevitably, surfaced a new problem. As we reviewed batches of docs created this way, we realized that our conventions for filenames and titles needed to change. That was going to be a painful exercise if done manually in Google Docs, and none of the add-ons I found could handle multi-document regex-based search and replace. So now, in addition to the converter that reads and translates the GDocs, I needed an updater to automate in-situ transformation.
What’s the fast path to learning as little as necessary about the Google Docs API to get the job done?
If the documents in question were just text files on a local system, that would be trivial thanks to the regex prowess of LLMs. But they’re Google docs, and that’s a whole different ball game. Figuring out how to authenticate to Google has always been a huge headache for me. If it were something I had to do on a regular basis, I’d have built up enough scar tissue to power through without too much drama. But like a lot of such chores, this isn’t one I do regularly. There can be months or years between encounters, so each one entails scrambling up a painful learning curve. What kind of OAuth app do I need to create? Remind me again about that consent screen. And, oh yeah, I have to figure out which APIs to enable, and then explicitly enable them, right? And then work out which scopes to make available to my app? And how to persist the auth token? And then, please remind me, when I change the scopes, do I need to delete the token and reauthenticate? Oh, and can my converter and updater share common credentials? Finally, what’s the fast path to learning as little as necessary about the Google Docs API to get the job done?
You know that other people have walked the same path before you.
I’ve always hated relearning all this crap necessary but annoying ceremony the hard way. You know that other people have walked the same path before you. If you could tap one of them on the shoulder and have a five-minute conversation, you could avoid the pitfalls. Historically, our best way to access that knowledge has been to do web searches and read documentation. And that was amazing compared to what existed before: reading books, taking classes. But still not great. web search, documentation, books and classes don’t respond well, if at all, to the specific context in which you are trying to learn. LLMs expand our access to knowledgeable people. This is indirect access, it’s impersonal and it wouldn’t be my first choice if I could get five minutes with the right person at the right time. But that’s rarely possible, and conversing with LLMs is a great alternative.
Restructuring Expert Attention
We should linger on this point for a moment. In Reinventing Discovery: The New Era of Networked Science, Michael Nielsen writes:
“The attention of the right expert at the right time is often the single most valuable resource one can have in creative problem-solving. Expert attention is to creative problem solving what water is to life in the desert: it’s the fundamental scarce resource.”
One of the touchstone stories in the book tells how an organization called InnoCentive, now merged into the crowd-source problem-solving platform Wazoku Crowd, helped a nonprofit — in need of solar-powered wireless routers that would work reliably in rural India — connect with Zacary Brown, a software engineer and radio enthusiast who had the necessary skills. Nielsen adds:
“InnoCentive creates value by restructuring expert attention, so that people such as Zacary Brown can use their expertise in high-leverage ways.”
We should absolutely expect our collaboration tools (looking at you, Slack!) to help us make effective use of expert attention. How can we help people connect with experts in an organization without flooding those experts with unwanted flow-killing interruptions? It’s an important open problem. As I mentioned last time, LLM-backed tools like Cody and Unblocked can serve as proxies for coworkers, and thus shields that protect them from interruption. But let’s not lose sight of the need to connect people to one another in the most efficient and least disruptive ways. On that front there’s plenty of headroom to improve — or compete with — Slack.
Look at My Screen
The ability to show rather than tell is a game-changer.
If I could have prevailed on an expert to guide me through Google’s authentication maze, we’d have jumped onto a call with screen-sharing so I could show my various failed efforts. Delightfully, that is now possible with LLMs. As I’ve mentioned a few times before, pasting screenshots into ChatGPT (and now Claude too) is a wildly effective method. Here’s one of the pictures I see in the transcripts that got me through the maze.
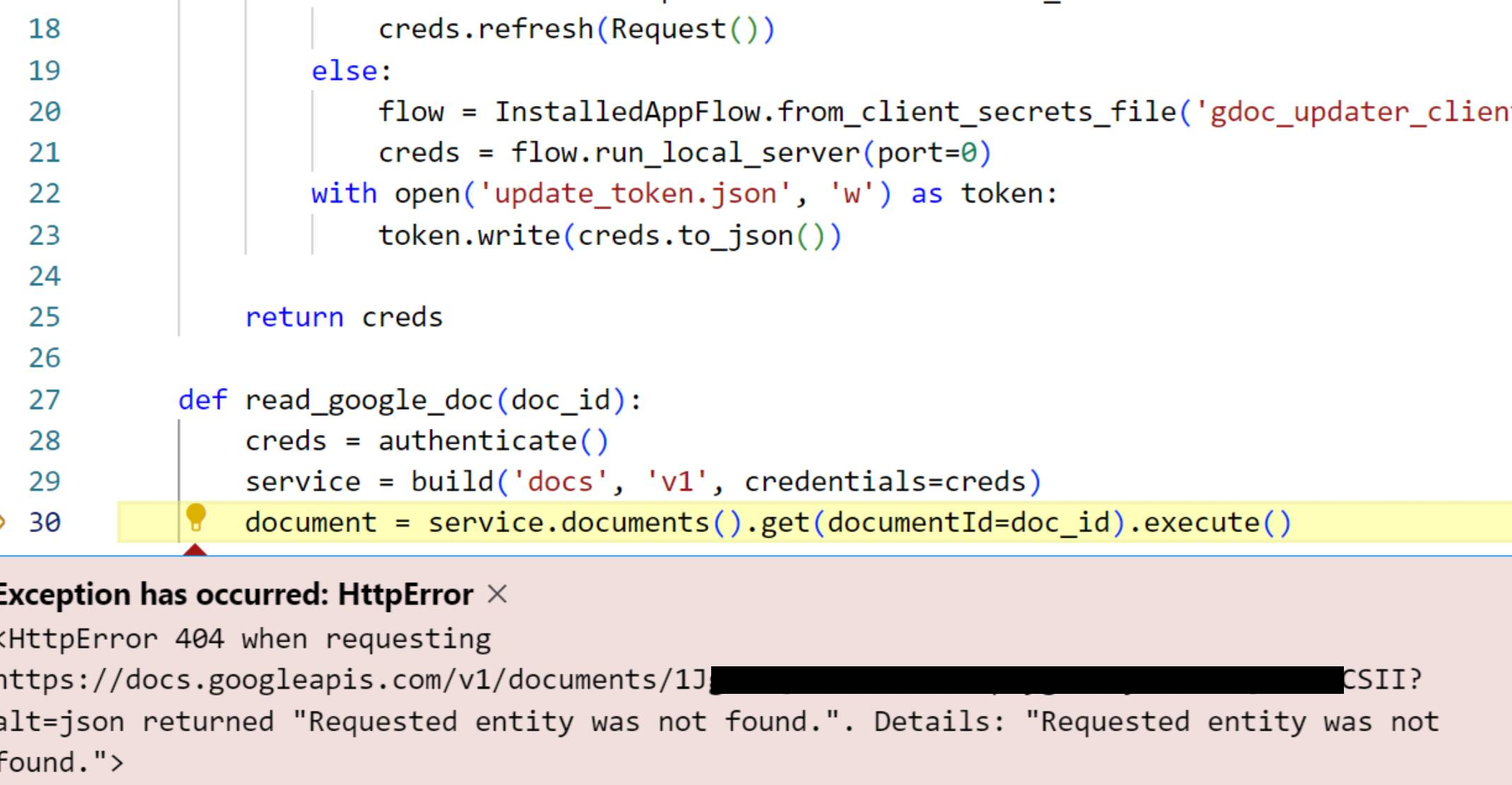
That picture is worth quite a few words. It says that we’re operating in the context of Python’s Google API client and that we’ve authenticated to the service with some kind of valid credential, but the document ID is wrong or a necessary scope wasn’t granted (or requested by the app), or perhaps there’s a different problem. Using words to transmit that context to another person would be tedious — that’s why we screenshare. Using the same words to prompt a language model would be just as tedious. The ability to show rather than tell is a game-changer.
Other screenshots in that transcript showed:
- The Google Doc itself, which proved that I had the right document ID.
- The Google Doc’s share dialog, which proved that as a logged-in user I could view and edit the document with that ID.
- The dev console’s consent screen, which proved that I had granted the necessary scopes.
Grabbing bits from my screen and pasting them into ChatGPT made quick work of all this basic troubleshooting.
In this case, the problems lay elsewhere. First, after adding a necessary scope, I needed to delete the saved token and re-authenticate. Second, my script needed to include that added scope in its API request. These are mistakes that have been made over and over again and that I would have eventually corrected on my own. By tapping into the experience of the countless people who had walked this path before me, ChatGPT accelerated my ability to identify and climb out of the pitfalls I’d stumbled into.
Explain the Code
Nowadays I make LLMs write regexes in long form with excruciatingly detailed commentary.
Once I emerged from the authentication maze, it was easy sailing. Here’s the core function that matches a list of patterns and swaps in replacements for them.
This isn’t the original function that Claude produced. In that one, the regexes looked like modem line noise. They worked fine, but I wasn’t confident that I could understand, explain or modify them. So nowadays I make LLMs write regexes in long form with excruciatingly detailed commentary. They won’t volunteer to do that, but if you push them, they’ll comply.
While we were at it, I asked for a quick refresher on Python’s re.sub and the use of anonymous (lambda) functions therein. The fact that I no longer need to have these idioms at my fingertips frees me to focus on the problem I’m solving. But that’s only a viable strategy if I can recover the knowledge quickly and easily, as LLMs powerfully enable me to do.
Find the Happy Path Others Have Trodden Before
In How I use “AI”, Nicholas Carlini delivers an exhaustive list of strategies like the ones I’ve been exploring in this column. He writes:
“Almost everything has been done by someone else before. Almost nothing you want to do is truly novel. And language models are exceptionally good at giving you solutions to things they’ve seen before.”
Some argue that by aggregating knowledge drawn from human experience, LLMs aren’t sources of creativity, as the moniker “generative” implies, but rather purveyors of mediocrity. Yes and no. There really are very few genuinely novel ideas and methods, and I don’t expect LLMs to produce them. Most creative acts, though, entail novel recombinations of known ideas and methods. Because LLMs radically boost our ability to do that, they are amplifiers of — not threats to — human creativity.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.