
包阅导读总结
1. 推荐大模型、数据质量、技术挑战、跨领域、未来发展
2. 本文主要探讨了推荐大模型的现状与问题,包括其与传统推荐系统的区别、数据生成关键环节、数据质量和完整性的影响及应对,还介绍了实际应用中的技术挑战、跨领域通用性、多行为推荐的意义以及未来的发展方向。
3.
– 推荐大模型的现状
– 广泛应用,性能飞跃
– 相比传统推荐系统,能利用文本信息辅助推荐,规模更大
– 推荐数据生成
– 关键环节是保证数据质量,包括压缩时保证信息损失最小化、保证数据多样性、进行数据去噪
– 数据质量和完整性
– 至关重要,影响模型预测和用户体验
– 可通过多种方法提高数据质量
– 技术挑战及应对
– 面临数据规模大、模型复杂、增量处理难等挑战
– 通过多种技术加速、优化模型架构、引入多行为和跨域数据应对
– 跨领域通用性
– 通用大模型灵活,推荐大模型跨领域迁移效果不佳
– 通用大模型发展对推荐大模型设计有启示
– 多行为推荐大模型
– 基于实时推荐场景需求,能更准确理解和预测用户需求
– 未来发展方向
– 提升推理速度,减少资源消耗
– 实现跨域统一有效大模型
– 进行多模态信息融合推荐
思维导图: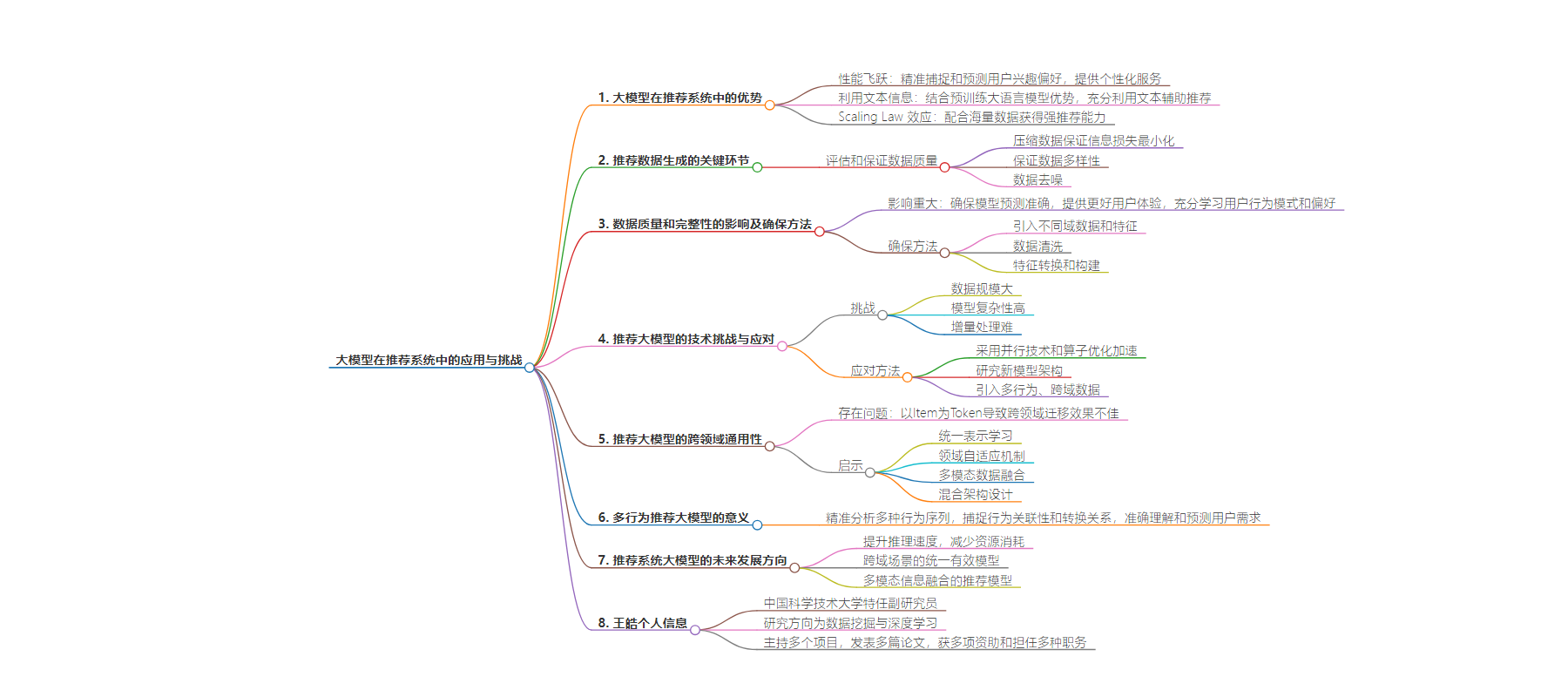
文章地址:https://mp.weixin.qq.com/s/UPiOJOifh0ygIaHMu3QLog
文章来源:mp.weixin.qq.com
作者:王皓
发布时间:2024/8/9 13:57
语言:中文
总字数:3270字
预计阅读时间:14分钟
评分:88分
标签:推荐系统,大模型,预训练模型,数据质量,模型复杂性
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
在 8 月 18-19 日的 AICon 上海站,InfoQ 邀请了中国科学技术大学特任副研究员王皓就这些问题进行深入分析,他将以《大模型在推荐系统中的落地实践》为主题进行分享。通过他的分享,你可以了解大模型在推荐系统相关现状以及了解大模型在推荐系统中的相关实践尝试与经验。本文为会前采访文章,希望对你了解大模型搜索有作用!
王皓: 传统推荐系统通常利用用户和物品的 ID 交互信息捕捉用户的偏好,还不能考虑到文本信息,大模型推荐系统是在大语言模型蓬勃发展的浪潮下产生的研究热点,其核心在于结合预训练大语言模型的优势,充分利用文本信息辅助推荐。同时,Scaling Law 效应在推荐系统领域也已经被验证,大模型配合海量的推荐数据能够得到很强的推荐能力,这通常是传统推荐模型达不到的规模。
王皓: 最关键的环节是评估或保证推荐数据的质量。首先,在一些应用场景中,原始推荐数据中存在信息冗余,为模型的训练带来了不必要的负担,因此可以通过压缩的手段生成新数据,在这个过程中,要保证信息的损失最小化,也就是保证推荐数据的质量;
其次,作为一个整体,推荐数据的多样性也很重要,对于推荐大模型来说,选择单一域或单一类型的推荐数据容易导致模型泛化性能较差,通常要进行数据选择,保证推荐数据的多样性;
最后,生成的数据最终要用于大模型的训练,然而数据中难免存在噪声,误导模型的训练,因此也需要一些去噪的手段。
王皓: 数据的质量和完整性对推荐系统至关重要。高质量的数据可以确保模型预测更加准确,减少噪声和偏差,提供更好的用户体验。而完整的数据则确保模型在训练过程中能够充分学习用户的行为模式和偏好,从而做出更加个性化的推荐。
在获得高质量推荐数据方面,存在几类方法。首先,在数据类别上,可以引入不同域的数据,研究跨域推荐方法;或者引入行为、文本等特征进行补充,辅助推荐系统的训练;还可以像上面那样引入数据生成方法;其次,对于收集到的数据,可以通过异常值检测和处理、缺失值填补等数据清洗手段,来提高数据可靠性和完整性;最后,可以通过特征转换和特征构建,增强数据的表达能力,提升模型的学习效果。
王皓: 推荐大模型仍面临着很多亟待解决的挑战,包括
-
数据规模大:推荐系统需要处理海量的用户和项目数据,对数据存储、处理和建模提出了极高的要求,也给长序列处理能力也带来了挑战;
-
模型复杂性高:大模型通常包含数百万甚至数十亿个参数,训练过程需要大量计算资源和时间。而且与通用大模型不同,推荐大模型的主要参数来源于数据,因此大规模数据往往会带来更多的参数;
-
增量处理难:新用户和新项目缺乏历史数据,导致推荐系统难以做出准确推荐。且对增量的处理也是一大难题。
目前,我们进行了初步研究,探索方法来解决这些挑战和困难:
-
采用数据并行、流水线并行、张量并行等技术进行加速,并针对华为昇腾芯片进行算子优化,实现了训练和推理速度的提高;
-
在模型架构层面,研究基于 Mamba 等状态空间模型的推荐大模型架构,解决了 Transformer 架构的自注意力机制计算和存储复杂度随输入序列长度的平方级别增长,导致的模型处理长序列能力不足的问题;
-
引入多行为、跨域数据,更准确地捕捉用户的兴趣动态,挖掘更加全面和细致的用户画像,同时在一定程度上缓解数据稀疏性。
王皓: 推荐大模型确实面临跨领域通用性的问题。通用大模型之所以能够适应多个领域和任务,关键在于它们使用文本作为 Token,而文本是一种高度通用的表示形式。无论是自然语言处理、图像描述还是其他任务,文本都可以作为一种通用的输入。这种通用性使得通用大模型在跨任务迁移时非常灵活。然而,推荐大模型的情况有所不同。推荐大模型通常以 Item(项目、商品、内容等)作为 Token。
这些 Item 往往是领域特定的,因此模型在一个特定领域内能够表现得非常好,但在跨领域迁移时,效果往往不如预期。例如,一个在电商平台上训练的推荐模型,直接用于音乐推荐时可能效果不佳,因为这两个领域的 Item 类型、用户行为和偏好模式都存在显著差异。
尽管如此,通用大模型的发展对推荐大模型的设计仍然提供了很多启示。首先,我们可以借鉴通用大模型的统一表示学习方法。通过对 Item 进行更加通用的表示学习,将不同领域的 Item 映射到同一个向量空间内。这意味着我们可以利用 Item 的属性(如文本描述、类别、用户评价等)进行编码,从而在多个领域之间共享知识,增强模型的跨领域能力。其次,领域自适应机制也是一个重要的启发。通用大模型在新任务或领域中能够快速适应,是因为它们具备领域自适应的能力。
推荐大模型可以引入类似的机制,通过在特定领域内进行微调,逐步适应新的推荐场景。例如,我们可以通过将通用 Item 特征与领域特定特征结合,帮助模型更好地适应新的领域需求。
此外,多模态数据的融合也是一个有效的策略,可以引入与 Item 相关的多模态数据,比如商品图片、用户评论文本等,来补充 Item Token 的表示。此外,混合架构设计也是一个值得探索的方向。可以设计一种结合通用大模型与推荐大模型优势的混合架构,利用通用大模型的能力,而在特定领域内的推荐任务中,发挥 Item Token 的优势。
王皓: 多行为推荐是基于实时推荐场景需求的研究课题。其他推荐任务往往将用户的交互行为视为单一的活动,如单纯的点击或购买行为。然而,现实中的用户可能会表现出多种不同的交互行为,包括浏览、加入购物车和购买等。这些不同的行为往往反映了用户不同层次的兴趣和意图。显然,不同的交互行为所揭示的用户兴趣和需求并不完全相同,甚至可能大相径庭。
因此,多行为推荐大模型的研究意义在于对这些多种行为序列进行精准的分析,进而捕捉到不同行为之间的关联性或转换关系,从而更准确地理解和预测用户的需求。
王皓: 首先,就如上文所说,推荐大模型虽然能力很强,但是也存在比如推理速度慢,资源消耗大的问题,要在拥有强大的预测能力下提升推理速度,减少资源消耗是一个研究难点;
其次,实际场景通常面临很多域的推荐,如何在跨域的场景实现一个统一有效的大模型也是一个新的发展方向;
最后,在一些推荐场景下,存在更多模态的数据例如商品图片等,如何高效地进行模态信息融合,实现多模态大模型的推荐也是比较有前景的研究方向。

王皓,中国科学技术大学特任副研究员研究方向为数据挖掘与深度学习,主持国家自然科学基金青年基金、CCF- 腾讯犀牛鸟基金和阿里巴巴创新研究计划 (AIR) 等项目,在 KDD、NeurlPS、TKDE、TOIS 等高水平期刊和会议上发表论文 50 余篇,获中国科大“墨子杰出青年特资津贴”资助,担任如 KDD、NeurlPS、WWW 等国际程序委员会委员及 TKDE、TOIS 等高水平期刊审稿人,人工智能智能计算服务专委会委员,相关工作 Google 学术引用 1400 余次。
InfoQ 将于 8 月 18 日至 19 日在上海举办 AICon 全球人工智能开发与应用大会,汇聚顶尖企业专家,深入端侧 AI、大模型训练、安全实践、RAG 应用、多模态创新等前沿话题。现在大会已开始正式报名,详情可联系票务经理 13269078023 咨询。
