
包阅导读总结
1.
关键词:AI 视频、Stable Diffusion、插件方案、大模型、生成质量
2.
总结:本文是 360 奇舞团前端开发工程师对 AI 视频解决方案的汇总。介绍了基于 Stable Diffusion 的动画插件方案,包括多个插件的功能、安装、模型下载及使用,还提及了独立的 AI 动画方案和开源的文生视频大模型,并指出当前 AI 视频生成存在的问题。
3.
主要内容:
– 基于 Stable Diffusion 的动画插件方案
– Animatediff + Prompt Travel + ControlNet + ADetailer
– 插件介绍:AnimateDiff 能生成和操作图像及动画,Prompt Travel 可精确调整正面提示。
– 插件安装:多种安装方式,如在扩展菜单安装或从网址安装。
– 模型下载:指定的主模型和 lora 模型放置位置。
– 填写 Prompt、设置插件、生成视频:设置特定 Prompt 及各插件参数生成视频,存在闪烁现象。
– 其他插件
– Mov2mov 插件:提取原视频帧重绘生成视频,操作简单但能力单一,闪烁较大。
– Deforum 插件:能生成流畅视频,可控性强但参数复杂、生成时间长。
– EbSynth 插件:能降低闪烁、优化生成时间,但安装配置复杂。
– 独立的 AI 动画方案
– animatediff-cli-prompt-travel:工作流优化整合项目,人物一致性高、融入自然,灵活高效,但有缺陷,如无 UI 界面、硬件要求高。
– 开源的文生视频大模型
– Stable Video Diffusion:可生成视频,开源,在不同 GPU 上生成时间不同。
– Zeroscope_v2 模型:二次开发模型,无水印,流畅度和分辨率提升,可与 MusicGen 配合。
– Rerender A Video:零样本文本引导视频到视频翻译框架,包括关键帧和完整视频处理,安装需一定条件。
– MuseV:虚拟人视频生成框架,有多种特点和支持功能。
– 其他文生视频工具及问题
– 列举了其他文生视频工具。
– 指出当前 AI 视频生成存在闪烁、动作不连贯等问题,上手成本增加。
思维导图: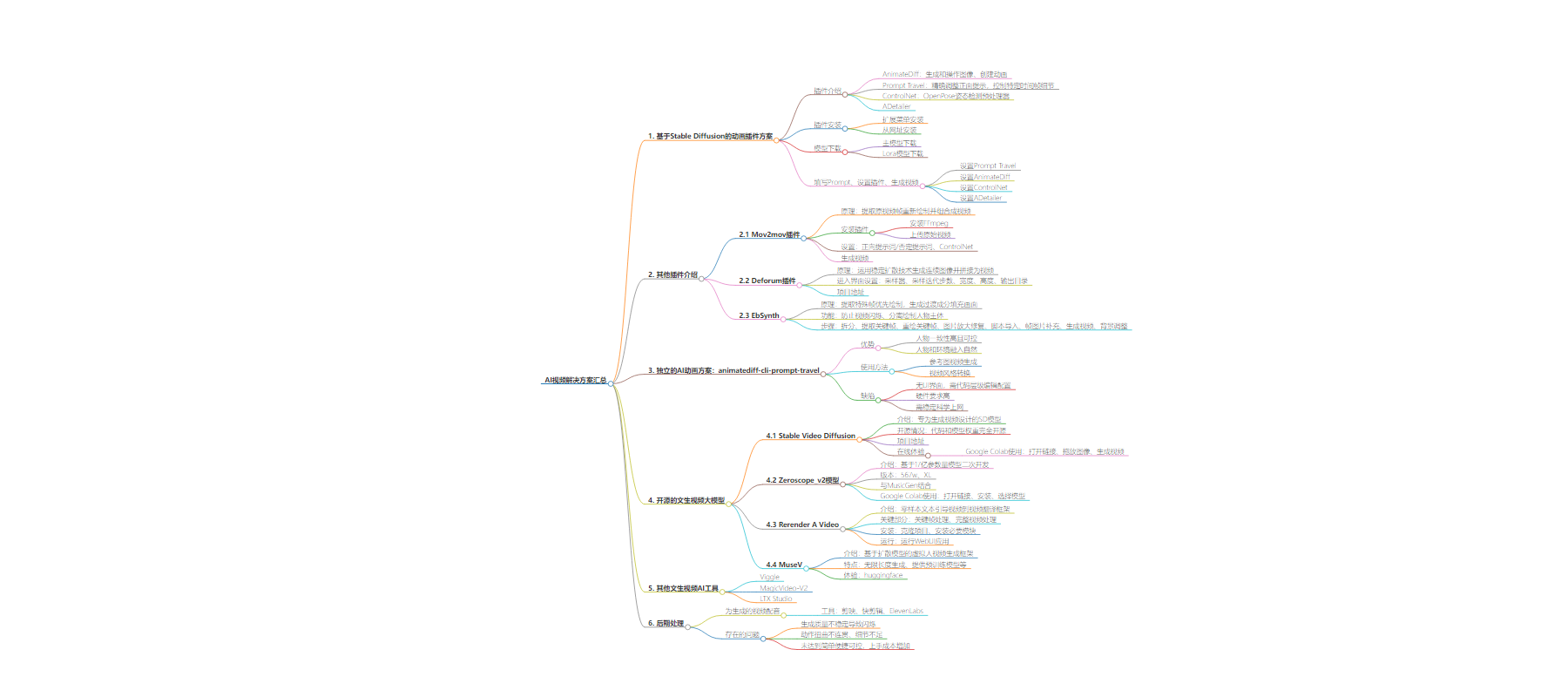
文章地址:https://mp.weixin.qq.com/s/AQDMHUcWDLrpmOQXIedEvA
文章来源:mp.weixin.qq.com
作者:天明
发布时间:2024/8/6 9:31
语言:中文
总字数:7586字
预计阅读时间:31分钟
评分:87分
标签:AI视频生成,Stable Diffusion,动画插件方案,视频生成技术,AI图像处理
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
本文作者为 360 奇舞团前端开发工程师
随着人工智能技术的不断发展,AI生成视频的领域也在不断壮大。从基于大规模数据的深度学习方法到创新的算法和工具,各种解决方案正在不断涌现,为视频制作带来了新的可能性,从最开始的Pika、Runway到一经问世就惊艳众人的Sora,可以说大模型在多模态,特别是视频模态的发展速度远超我们的想象。不过就文生视频而言,目前市面上仍然没有像ChantGPT这样的现象级产品出现。经过对目前主流文生视频解决方案的调研,我整理了以下内容供大家参考。
基于Stable Diffusion的动画插件方案
Stable Diffusion(下文简称SD)是2022年发布的深度学习文本到图像生成模型,通过它可以实现文生图的功能,并且它是免费且开源的,你可以通过Stable Diffusion WebUI(下文简称SD WebUI)提供的浏览器界面来利用SD大模型实现文生图的功能。网上有很多在本地或是云端部署SD WebUI的方法,这里不多赘述,下面介绍的插件,都可以通过SD WebUI来进行安装,并配合SD大模型来实现文生视频的功能。
1. Animatediff + Prompt Travel + ControlNet + ADetailer
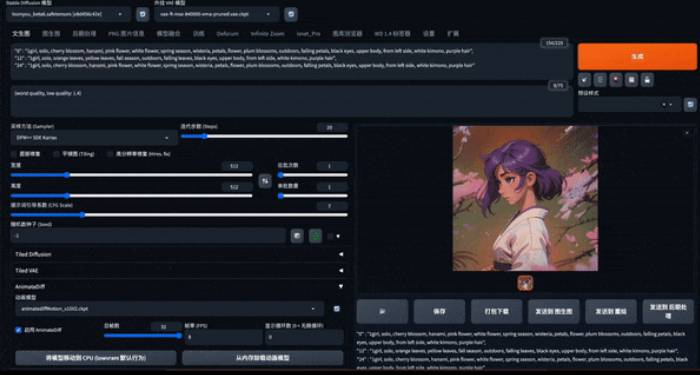
1.1 插件介绍
-
AnimateDiffAnimateDiff插件是一个用于生成和操作图像的强大工具,它属于SD模型的一个扩展,它能够基于用户的描述生成新的图像,或者对现有图像进行修改和增强。这个插件的另一个主要特点是它能够创建动画。用户可以指定一个系列的图像变化,插件会生成一系列平滑过渡的图像,从而创建出动画效果。 -
Prompt TravelPrompt Travelling是一种技术,用于在创建最终的GIF或视频时,精确调整正面提示(positive prompt),以精确控制特定时间帧内的具体细节。当与AnimateDiff和SD结合时,Prompt Travelling允许更大程度地影响GIF和视频的视觉美学,包括风格、背景、服装选择等元素。在AnimateDiff中,如果使用这种方式来制作动画,那么我们的提示词(Prompt)就能使用Prompt Travel的撰写方式。他主要分为三个部分:开头提示词( Head Prompt )指定帧数提示词( Frames Prompt )结尾提示词(Tail Prompt )例如正常的提示词为:
masterpiece,30yearoldwomen,cleavage,redhair,bun,ponytail,mediumbreast,desert,cactusvibe,sensualpose,(lookinginthecamera:1.2),(frontview:1.2),facingthecamera,closeup,upperbody
使用Prompt Travel 的撰写方式的提示词可以这样写:
masterpiece,30yearoldwomen,cleavage,redhair,bun,ponytail,mediumbreast,desert,cactusvibe,sensualpose,(lookinginthecamera:1.2),(frontview:1.2),facingthecamera,closeup,upperbody
0:(reddress:1.2)
16:(whitedress:1.2)
32:(greendress:1.2)
smile
头部提示
masterpiece,30yearoldwomen,cleavage,redhair,bun,ponytail,mediumbreast,desert,cactusvibe,sensualpose,(lookinginthecamera:1.2),(frontview:1.2),facingthecamera,closeup,upperbody
头部或基本提示充当基础输入,用于确定生成的视频或 GIF 的整体外观
帧提示
0:(reddress:1.2)
16:(whitedress:1.2)
32:(greendress:1.2)
帧提示遵循“帧编号:帧prompt”模式,确保您的帧编号按顺序排列。这些提示显示在特定时间范围内将发生的修改。并且对每一个“帧prompt”都可以添加单独的权重规则.
尾部提示
smile
案例中的最后一行代表尾部提示,不是必须的。您可以灵活地包含单行或者多行提示,也可以不写。
1.2 插件安装
插件有多种安装方式,这里介绍其中的两种:
-
在
SD WebUI的“扩展(extensions)”菜单,选择“可用(available)”,点击“加载自(load from)”,搜索“animatediff”,点击“安装(install)”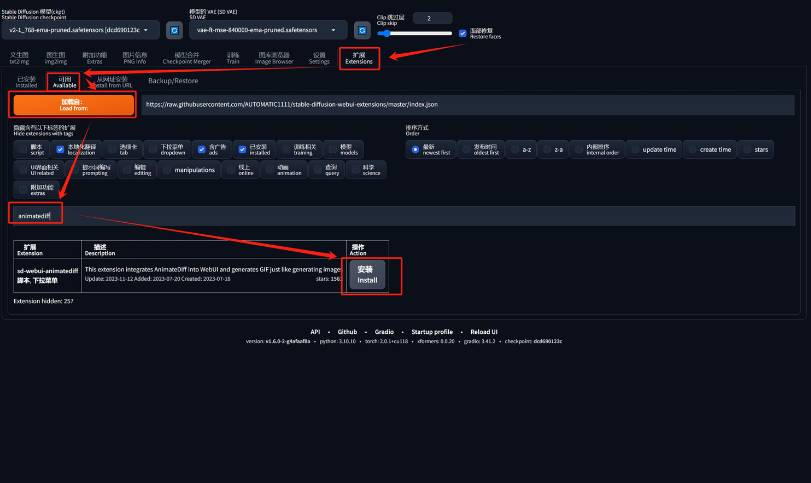
-
访问
animatediff的gitHub主页,点击绿色按钮code,点击复制HTTPS的按钮复制animatediff的库链接打开SD WebUI,找到“扩展(extensions)”菜单,选择“从网址安装(install from URL)”子菜单,将上面复制的库网址粘贴到“扩展的git仓库网址(URL ro extension’s git repository)”,最后点击“安装(install)”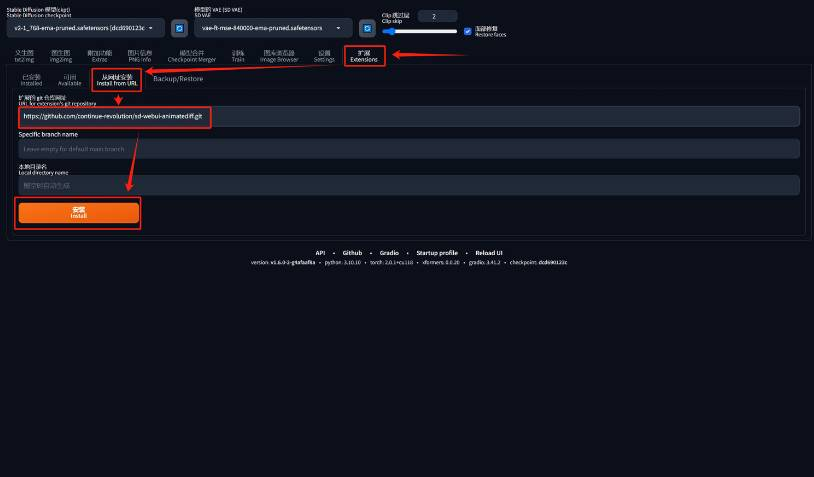
1.3 模型下载
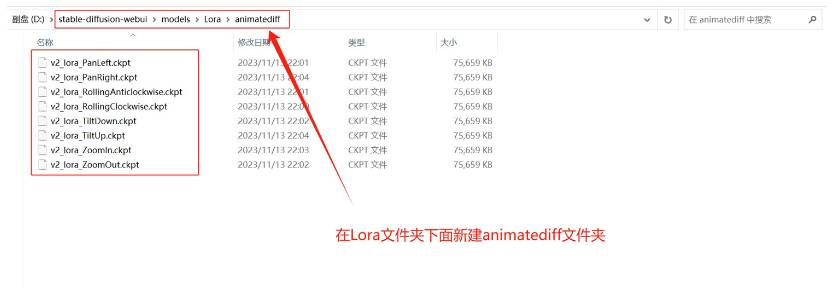
在ainimateDiff的huggingface的模型下载页面: https://huggingface.co/guoyww/animatediff/tree/main, 下载3个主模型放在“\stable-diffusion-webui\extensions\sd-webui-animatediff\model”文件夹;下载8个lora模型放在“\stable-diffusion-webui\models\Lora\animatediff”文件夹,其中的animatediff文件夹为lora文件夹下面自行新建的一个文件夹,避免与其他的lora模型混淆;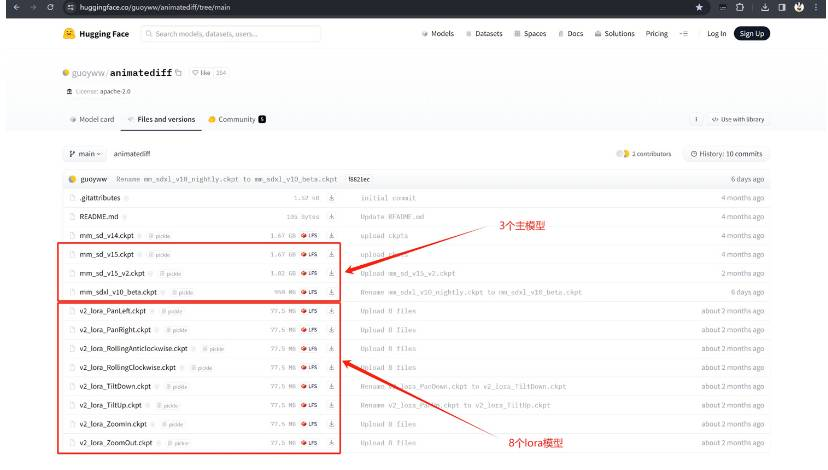
1.4 填写Prompt、设置插件、生成视频
设置Prompt Travel
masterpiece,30yearoldwomen,cleavage,redhair,bun,ponytail,mediumbreast,desert,cactusvibe,sensualpose,(lookinginthecamera:1.2),(frontview:1.2),facingthecamera,closeup,upperbody
0:(reddress:1.2)
16:(whitedress:1.2)
32:(greendress:1.2)
smile
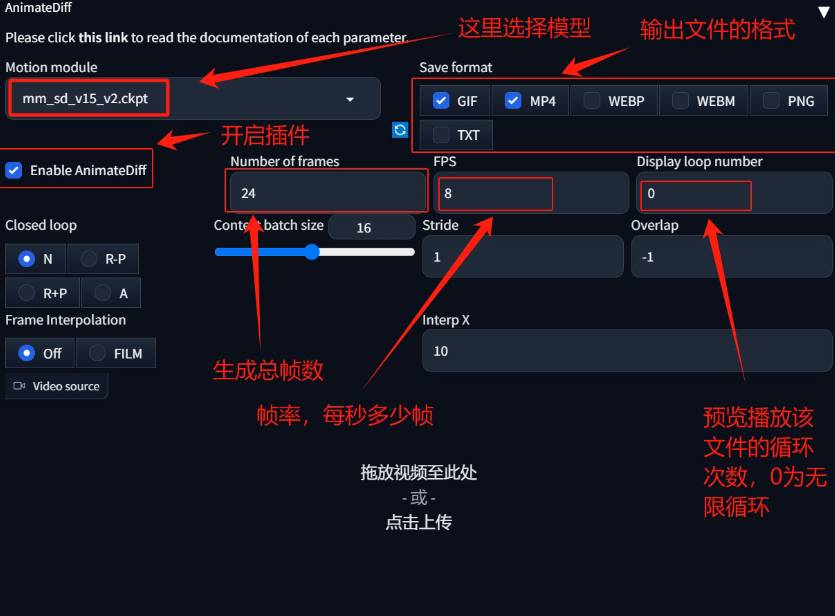
设置AnimateDiff
-
选择大模型版本为: mm_sd_v15_v2.ckpt,这是第二代的SD1.5版本的运动模型,配合SD1.5版本的checkpoint模型使用,也是现在使用最多的模块. -
设置首尾帧是否相同: Closed Loop:N:N意味着绝对没有闭环 – 如果Number of frames的值小于Context batch size且不为0 ,这是唯一可用的选项。
设置ControlNet
-
这里使用 ControlNet的OpenPose 姿态检测预处理器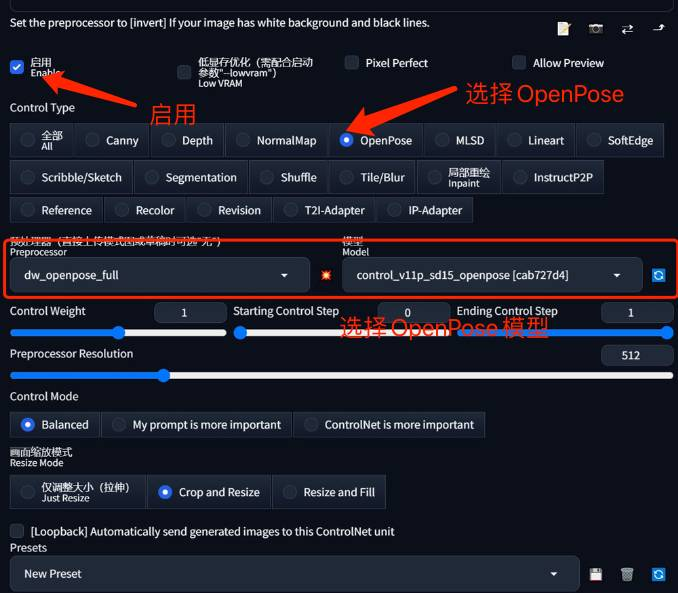
-
开启 OpenPose,选择对应的OpenPose预处理模型
设置ADetailer
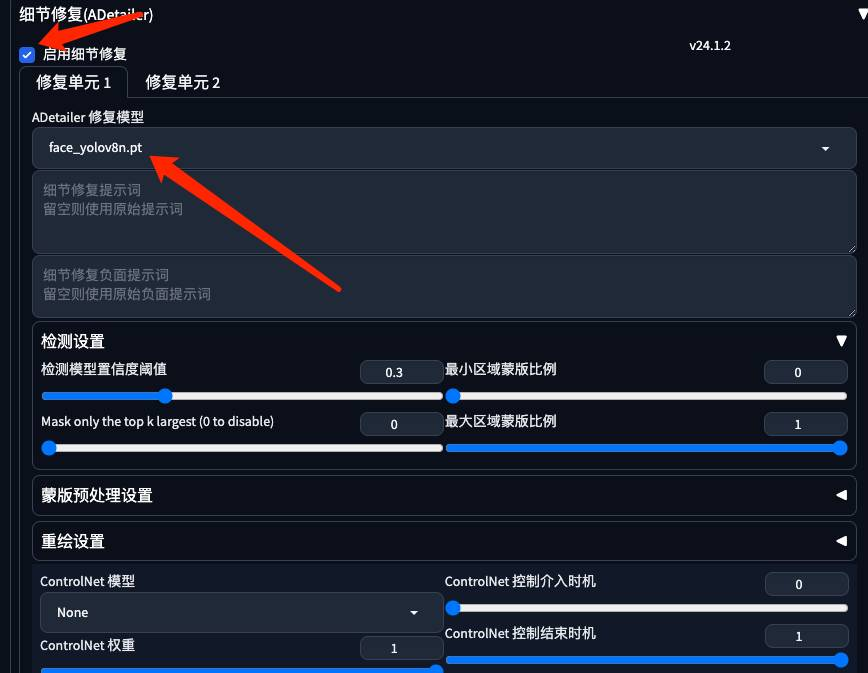
-
点击生成后,等待片刻会生成相应是Gif或是MP4视频
以上就是我们借助SD的一系列插件,来操控AI大模型生成相应的视频的方式。这种方式的好处是整体视频内容可控,缺点是存在一定的闪烁现象。
2.其他插件介绍
2.1Mov2mov插件

Mov2mov最早火起来的SD动画插件之一,Mov2mov的原理是提取原视频的帧,并将每一帧按照用户设置的模型和prompt重新绘制,然后将生成的帧组合成视频并输出。
-
安装插件
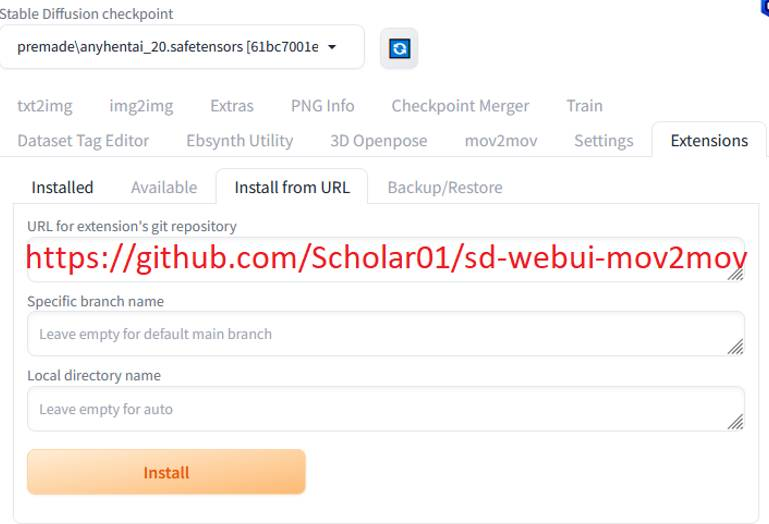
pic2 -
安装 FFmpeg : https://ffmpeg.org/download.html
安装FFmpeg有两个目的,一是如果输入视频的分辨率,对于您的 GPU 来说太高,可以利用FFmpeg缩小视频.
ffmpeg-iinput.mp4-vf"scale=-1:720"output.mp4
上面的命令会将视频的高度调整为 720 像素,并自动调整宽度以保持宽高比。
-
上传原始视频到
move2move选项卡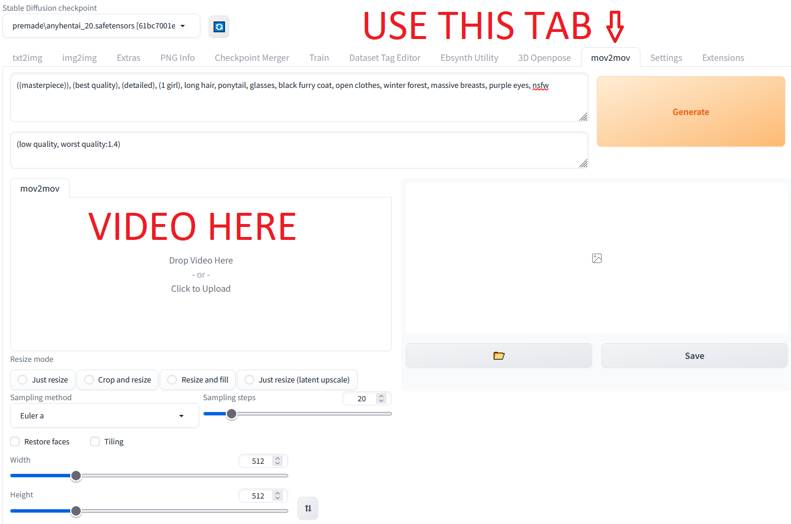
截屏2024-06-04 14.59.33
注意:需要将宽度和高度设置为与输入视频相同的分辨率
-
设置正向提示词/否定提示词。您可以像往常一样使用
LoRA嵌入,但界面不会在此选项卡上提供列表,因此需要复制模型名称到mov2mov选项卡 -
可以开启
ControlNet并使用Canny(边缘检测)预处理器,这一步是可选的 -
生成视频
生成每一帧的预览会输出到
\stable-diffusion-webui\outputs\mov2mov-images\<date>目录下,如果您没有强大的 GPU,预计 720p 的 30 秒视频需要数小时才能渲染完成。最终渲染完成的mov2mov 视频是没有声音的,生成的视频会输出到\stable-diffusion-webui\outputs\mov2mov-videos这个目录下
ffmpeg-igeneratedVideo.mp4-ioriginalVideo.mp4-map0:v-map1:a-c:vcopy-c:aaacoutput.mp4
对比SD自带的批量图生图,更推荐mov2mov插件。直接通过提示词控制、生成最终视频,省去了用其他视频产品将多张图片转成视频的过程。但比起Deforum,Mov2mov的能力比较单一,生成视频的闪烁也较大,胜在操作十分简单,这是它的项目地址:https://github.com/Scholar01/sd-webui-mov2mov.
可以直接从参考视频逐帧处理,处理完成后打包成视频,或是可以自定义选择关键帧或者自动生成关键帧
2.2 Deforum插件
SD的Deforum插件,这是一个运用了稳定扩散技术的动画制作工具,能依赖于文字描述或者参照视频,生成一系列连续的图像,并且将这些图像无缝拼接为视频。这个插件所应用的”image-to-image function”技术,能微调图像帧,并采用稳定扩散的方法来产生接下来的一帧。正因为帧与帧之间的变化非常细微,从而带来了流畅的视频播放体验。它可实现复杂的缩放、位移、旋转动画,并且可以同时控制多个帧间隔中的动画差异、提示词差异。可控性远远超过Runway和Pika labs,生成效果也十分惊艳,缺点是控制参数较为复杂,生成时间较长,逐帧重绘方式效率低, 这是项目地址:https://github.com/deforum-art/sd-webui-deforum
进入界面进行设置,主要需要设置的就是采样器、采样迭代步数、宽度、高度以及输出目录(Batch name),不同的设置对后期生成的视频影响较大,可以参考这篇文章:https://civitai.com/articles/5506/deforum-everything-you-need-to-know,了解相关参数设置,这里不再涉及。
2.3 EbSynth
EbSynth它的原理可以用一句话来概括,就是通过智能识别并提取视频里一些比较特殊的帧,优先绘制这些帧,然后通过一些特殊算法,在这些帧之间生成类似于过度的成分,来填充画面。通过EbSynth生成的AI动画,不仅可以实现画面的连续稳定,无闪烁,还能大大降低生成工作量,以原来五分之一甚至十分之一的时间,实现类似的效果,从而实现AI动画的降本增效。
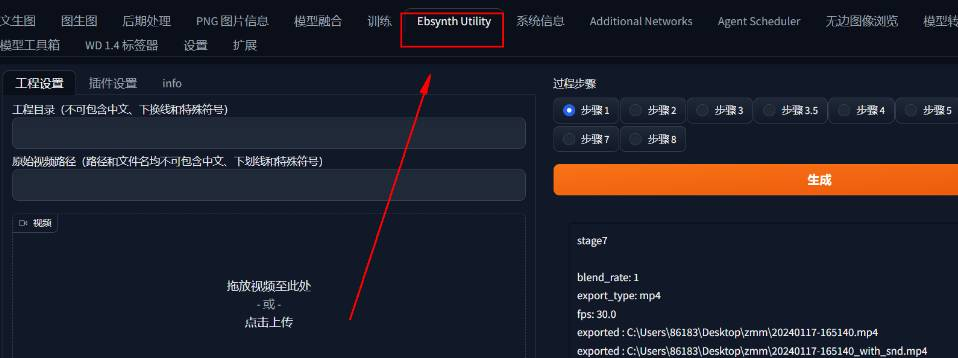
EbSynth有一个防止视频闪烁的功能,它是通过把画面中的人物主体等单独提取出来,进行绘制,因为大部分的闪烁和混乱,其实都是发生在和人物主体无关的部分上,只要背景不闪了,那其实整个视频看上去就会舒服很多,它实现分离绘制的方式,是去智能识别人物,并去生成一个蒙版,然后让SD执行蒙版重绘。
点击Ebsynth插件,会发现其中有八个步骤,其实这八个步骤就是在帮助你一步一步将你的视频转化为AI动画(拆分,提取关键帧,重绘关键帧,图片放大修复,脚本导入,帧图片补充,生成视频,背景调整)
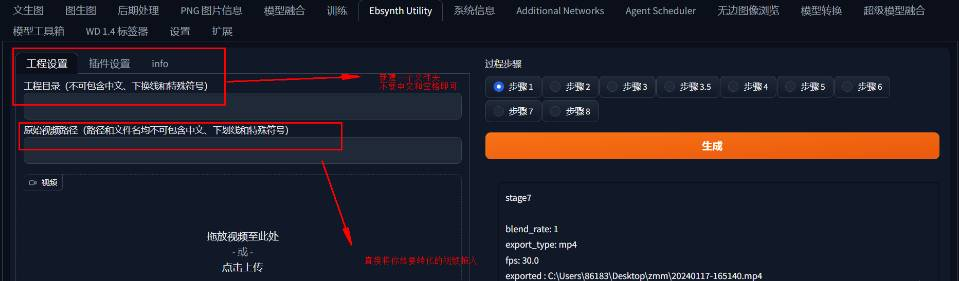
EbSynth相比于使用move2move这个插件可以解决视频闪烁问题,并且生成视频的时间也被优化,缺点是安装跟配置步骤较为复杂。
还有一些其他插件如m2m等,笔者没有过多研究这里不再涉及,感兴趣的同学可以自行civitai.
独立的AI动画方案:animatediff-cli-prompt-travel
animatediff-cli-prompt-travel是由ebsynth utility的SD插件作者基于animatediff项目技术基础做的一套工作流优化和整合的扩展项目,这个项目是独立部署,独立运行的,项目地址:https://github.com/s9roll7/animatediff-cli-prompt-travel,相比SD的animatediff插件有以下优势:
-
视频生成时人物一致性较高,且可控,据说动画模型后续可以自己训练。 -
视频转绘时人物和环境融入很自然。在实际应用中, Animatediff-cli-prompt-travel表现出了极高的灵活性和效率。用户可以通过命令行界面,轻松地设置各种参数,如生成时间、控制网络、提示词信息等,从而生成高质量的动画。此外,由于其开放源代码的特性,开发者可以根据自己的需求进行定制和扩展,进一步丰富其功能和应用场景。
Animatediff-cli-prompt-travel项目有2种使用方法:
-
参考图视频生成:类似 Runway或Pika,即Animatediff的基础用法,根据参考图片(1张或多张)来生成视频或GIF图或视频。 -
视频风格转换:相当于视频重绘,基于某个视频,转换风格。
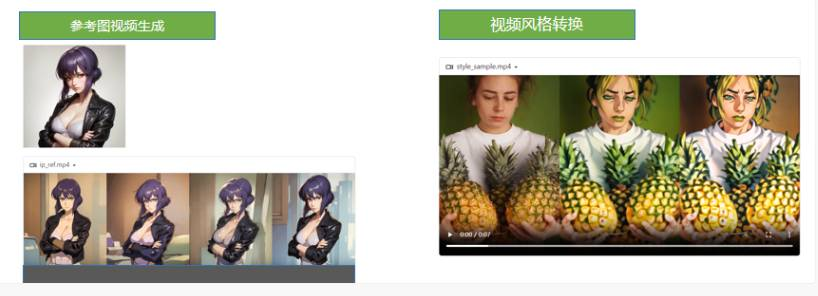
目前项目扔有一些缺陷:
-
项目目前没有UI界面,部署和运行都需要进行代码层级编辑和配置,需要至少一点点的代码基础。 -
硬件要求高:目前这个项目建议显卡的显存为12GB以上。 -
要有稳定的科学上网方式和流量,项目运行过程中需要连接外部下载资源,而且后续运行也会访问一些配置文件。
开源的文生视频大模型
1. Stable Video Diffusion
Stable Video Diffusion(SVD)是专为生成视频而设计的SD 模型。您可以使用它为SD生成的图像添加动画,从而产生令人惊叹的视觉效果。它是由Stability AI 推出的首个基础视频模型,与SD是同一开发者。这是一个开源模型,其代码和模型权重都已经完全开源项目地址:https://github.com/xx025/stable-video-diffusion-webui,你可以在线体验:体验地址:https://huggingface.co/spaces/multimodalart/stable-video-diffusion。
在Google Colab上使用
-
打开 Colab 笔记本的 Colab链接:https://colab.research.google.com/drive/1Gu8FhCBTS29YebjUN_zhvB1vvd6j286A?usp=sharing, 页面,点击全部执行
-
启动
GUI在加载完成后,您应该会看到一个gradio.live的链接。点击链接启动GUI。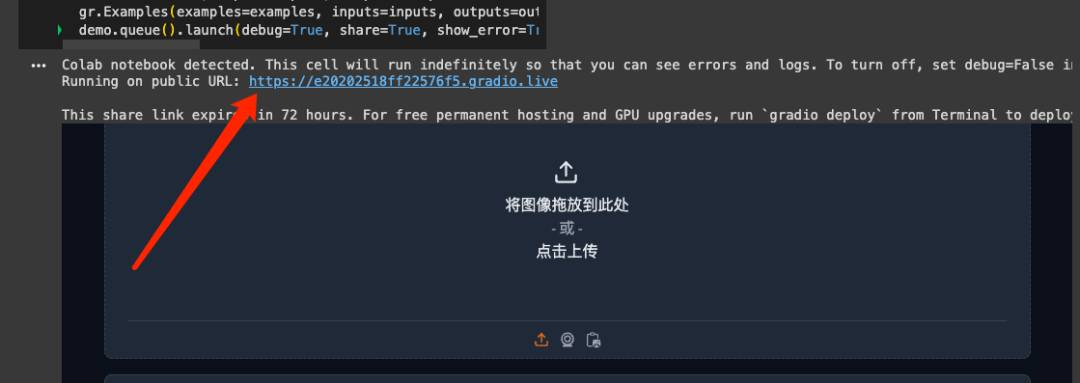
pic19
注意:如果在下载模型时候报错,请尝试选择其他模型在尝试
打开链接,拖放您希望用作视频第一帧的图像。
-
生成视频点击运行以开始生成视频。生成完成后,视频将显示在 GUI上。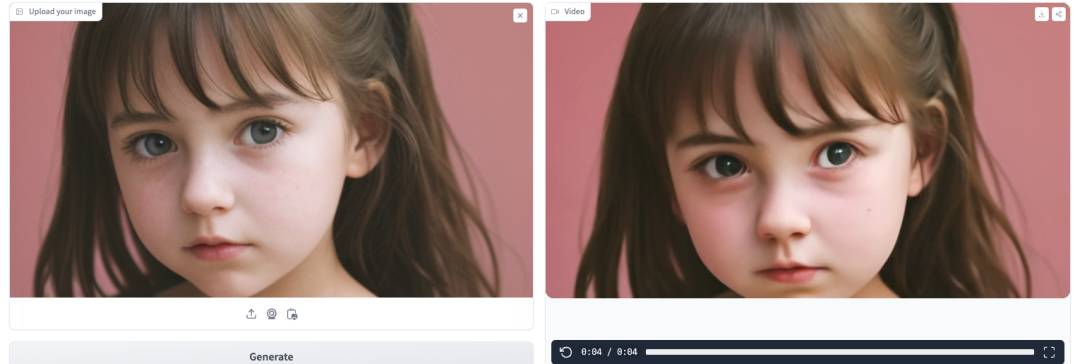 在
在T4 GPU(免费账户)上大约需要 9 分钟,在V100 GPU上则为 2 分钟。 -
对比 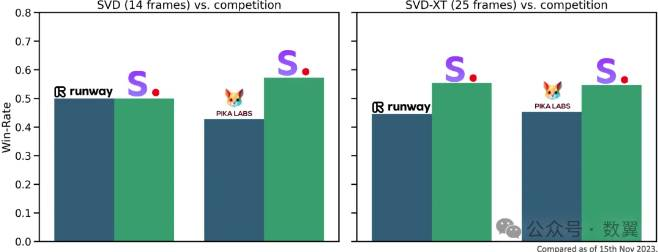 上图是
上图是Stability AI官方给的与Runway、Pika生成视频的对比,在25帧的视频上,视频质量是优于Gen2和PikaLabs,在 14帧的视频上,和Gen2相当, 优于PikaLabs.
2. Zeroscope_v2模型
Huggingface上有作者发布了一个文生视频模型Zeroscope_v2,它基于17亿参数量的ModelScope-text-to-video-synthesis模型进行二次开发。相比于原版本,Zeroscope生成的视频没有水印,并且流畅度和分辨率都得到了提升,适配16:9的宽高比。Zeroscope_v2包括两个版本,其中Zeroscope_v2 567w可以快速生成576×320像素分辨率、帧率为30帧/秒的视频,可用于视频概念的快速验证,只需要约7.9GB的显存即可运行。Zeroscope_v2 XL可以生成1024×576分辨率的高清视频,大约需要15.3GB的显存,Zeroscope还可以与音乐生成工具MusicGen一起使用,快速制作一个纯原创短视频。
在Google Colab上使用
-
打开 Colab 笔记本的 Colab链接 :https://colab.research.google.com/drive/1TsZmatSu1-1lNBeOqz3_9Zq5P2c0xTTq?usp=sharing.
-
先点击Step 1下的运行按钮,等待安装,大约需要3分钟左右;
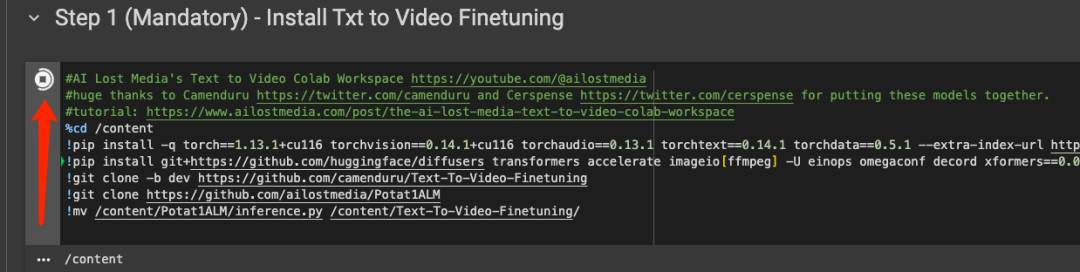
-
当Step 1执行完成后,在Step 2 选择一个你要使用的模型,选择其中一个点击运行即可
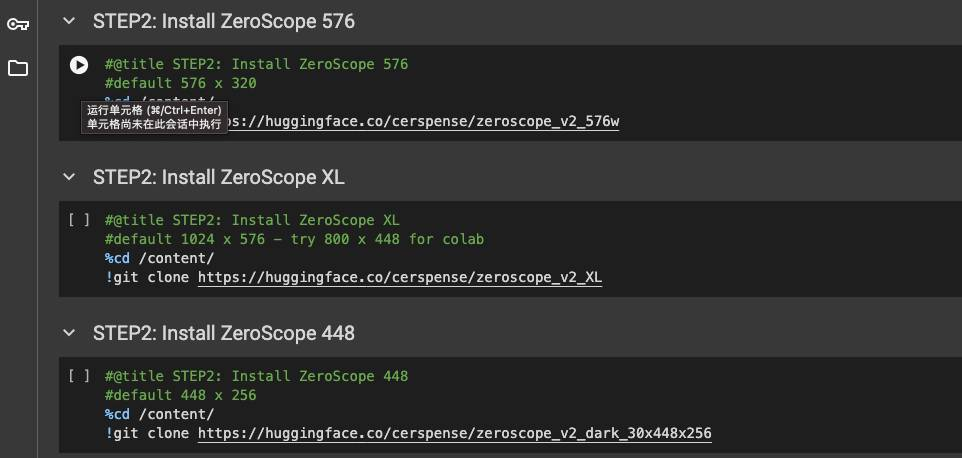 再次等待执行完成后,继续执行下一步
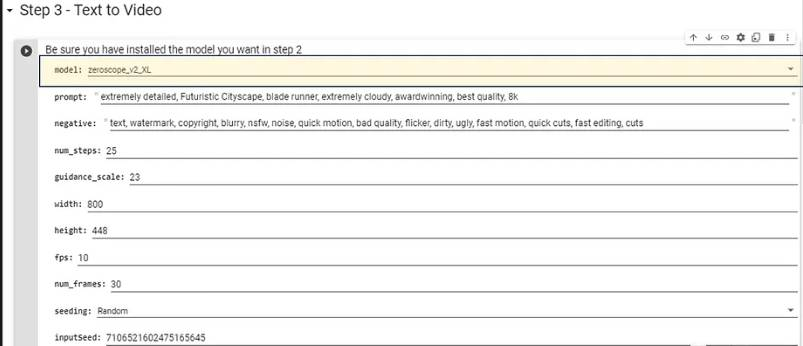
再次等待执行完成后,继续执行下一步 -
选择在Step2中安装并希望使用的模型型号,对于更高分辨率的模型,推荐下面的配置参数,不需要太长的生成时间。
3.Rerender A Video
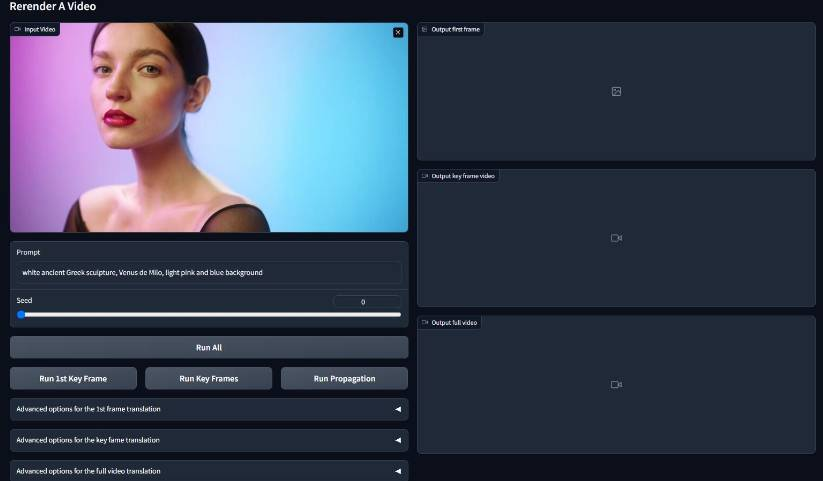
Rerender A Video项目是一个零样本文本引导视频到视频翻译框架,旨在实现高质量和时间上连贯的视频生成。该框架包括两个关键部分:关键帧处理和完整视频处理。
关键帧处理阶段使用改进的扩散模型生成视频的关键帧,而完整视频处理阶段将这些关键帧传播到整个视频,以确保全局样式和局部纹理的时间一致性。为了实现这一目标,引入了创新的帧间约束方法,涵盖了全局样式、形状、纹理和颜色的一致性。本框架的关键特点包括零样本训练、兼容性以及灵活性,可以与现有的图像扩散技术相结合,以实现各种定制化的视频生成任务,项目地址: https://github.com/williamyang1991/Rerender_A_Video.
安装
要使用Rerender A Video项目,您可以按照以下步骤进行安装:
-
克隆项目仓库,并确保使用 --recursive选项来获取所有必要的子模块:
gitclonegit@github.com:williamyang1991/Rerender_A_Video.git--recursive
cdRerender_A_Video
pipinstall-rrequirements.txt
condaenvcreate-fenvironment.yml
condaactivatererender
请注意,这里安装此项目需要至少24GB的VRAM。如果内存消耗较大,您可以参考项目文档中的说明进行降低内存消耗的操作。
运行
运行WebUI应用:
pythonwebUI.py
4. MuseV
MuseV 是基于扩散模型的虚拟人视频生成框架,项目地址: https://github.com/TMElyralab/MuseV,它具有以下特点:
-
支持使用新颖的视觉条件并行去噪方案进行无限长度生成,不会再有误差累计的问题,尤其适用于固定相机位的场景。 -
提供了基于人物类型数据集训练的虚拟人视频生成预训练模型。 -
支持图像到视频、文本到图像到视频、视频到视频的生成。 -
兼容 Stable Diffusion文图生成生态系统,包括base_model、lora、controlnet等。 -
支持多参考图像技术,包括 IPAdapter、ReferenceOnly、ReferenceNet、IPAdapterFaceID。
体验
你可以在huggingface上去体验这个项目: https://huggingface.co/spaces/AnchorFake/MuseVDemo.

其他
-
文生视频AI工具——Viggle: https://viggle.ai/. -
文生视频工具——MagicVideo-V2: https://magicvideov2.github.io/,这就是字节跳动最近推出的文生视频模型 -
生成式AI视频讲故事平台——LTX Studio: https://ltx.studio/.
最后
目前,无论是使用 SD 插件还是文生视频大模型,生成的视频都是“无声电影”。如果想要让它们更富有表现力,就需要为其配上音效。你可以利用剪映或者快剪辑来对生成的视频进行二次加工。当然,你也可以借助 AI 自动配音工具,比如 ElevenLabs: https://elevenlabs.io/ ,或者结合文字转语音的工具为你生成的视频进行配音。
需要了解的是,当前 AI 视频生成领域仍面临着生成质量不稳定导致的不同帧之间的“闪烁”现象,以及动作扭曲不连贯、细节表现不足等技术难题。而且,当前的 AI 视频生成仍远未达到简单、便捷和可控的程度,上手成本也在不断增加。不过相信随着 AI 能力的不断增强,AI 视频生成技术和可交互性会越来越成熟。
引用
https://civitai.com/articles/5506/deforum-everything-you-need-to-know
https://myaiforce.com.cn/stable-diffusion-adetailer/
https://www.bilibili.com/read/cv23190880/
https://sspai.com/post/83102
https://ebsynth.com/
https://juejin.cn/post/7308536984028807194
https://github.com/Scholar01/sd-webui-mov2mov/blob/master/README_CN.md