
包阅导读总结
1.
关键词:LlamaExtract、结构化提取、数据处理、LLM、beta 版
2.
总结:LlamaExtract Beta 发布,可从非结构化数据中进行结构化提取,是一项管理服务,有 UI 和 API 两种使用方式,适用于多种文档类型,目前处于测试阶段,团队在努力改进。
3.
主要内容:
– LlamaExtract 简介
– 是从非结构化文档中进行结构化提取的管理服务
– 可推断文档模式并按指定模式提取值
– 通过 UI 和 API 供 LlamaCloud 用户使用
– 特点与限制
– 模式推断有文件数量和页数限制
– 当前处于测试阶段,在努力改进使其更具扩展性和可用性
– 数据提取的重要性
– 是 LLM 应用新数据 ETL 栈的关键部分
– 使用方式
– 通过 UI 进行原型设计
– 通过 API 创建提取工作流
– 示例用例
– 如处理简历、收据和发票、产品页面等
– 未来改进方向
– 支持多模态提取等功能
思维导图: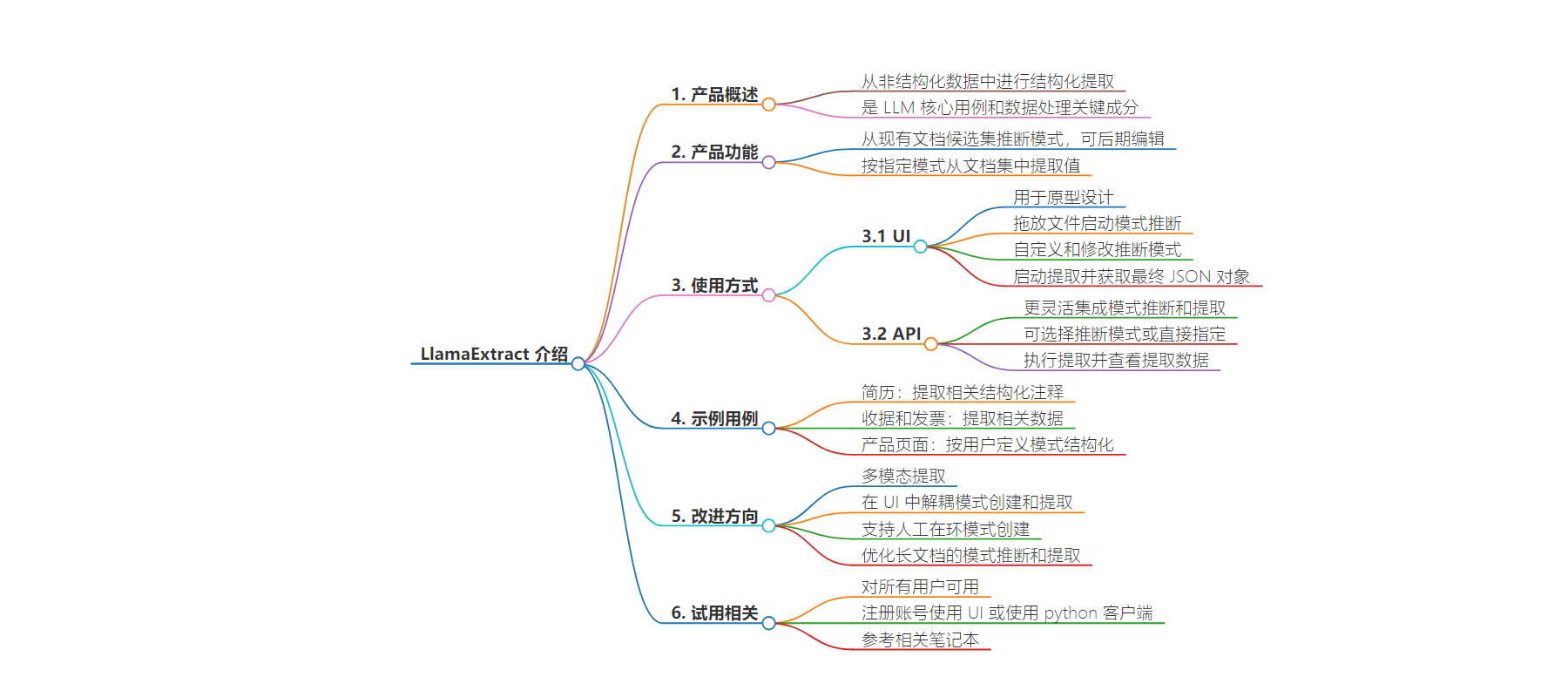
文章来源:llamaindex.ai
作者:LlamaIndex
发布时间:2024/7/25 0:00
语言:英文
总字数:877字
预计阅读时间:4分钟
评分:93分
标签:LLM 应用,数据提取,ETL 数据栈,LlamaIndex,API
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
Structured extraction from unstructured data is both a core use case for LLMs in its own right, as well as a key ingredient in data processing for retrieval and RAG use cases. Today we’re excited to announce a beta release of LlamaExtract, which is a managed service that lets you perform structured extraction from unstructured documents.
It does the following:
- Infers a schema from an existing candidate set of documents. You can choose to edit this schema later.
- Extracts values from a set of documents according to a specified schema (whether inferred from the previous step, specified by a human, or both).
LlamaExtract is available to LlamaCloud users through both a UI and API. Schema inference currently comes with a cap of 5 files, with a max of 10 pages per file. Given an existing schema, schema extraction happens on a per-document level.
LlamaExtract is currently in beta, meaning it is an experimental feature that we’re working hard to improve and make more generally scalable and usable. Please report any issues to our Github!
Metadata Extraction is a Key Part of the LLM ETL Stack
A new data ETL stack is needed for LLM applications. This data loading, transformation, and indexing layer is crucial for downstream RAG and agent use cases over unstructured data.
We built LlamaParse and LlamaCloud to serve these ETL needs and power thousands of production pipelines over complex documents in production. Through working with our users and customers, we realized that besides chunk-level embeddings, automated metadata extraction is an important part of the transformation story (the “T” in ETL); it is a core necessary ingredient for increasing transparency and control over broad swaths of unstructured data.
That led us to build the initial version of LlamaExtract – designed to automate data transformation for your unstructured data.
A Walkthrough
LlamaExtract is an API, it also has a python client and of course a web UI within LlamaCloud.
Use the UI to Prototype
The LlamaExtract UI allows you to prototype an extraction job. After clicking the “Extraction (beta)” tab in the left-hand side, you can click “Create a new schema” in order to define a new extraction job, which will take you to the schema creation screen:
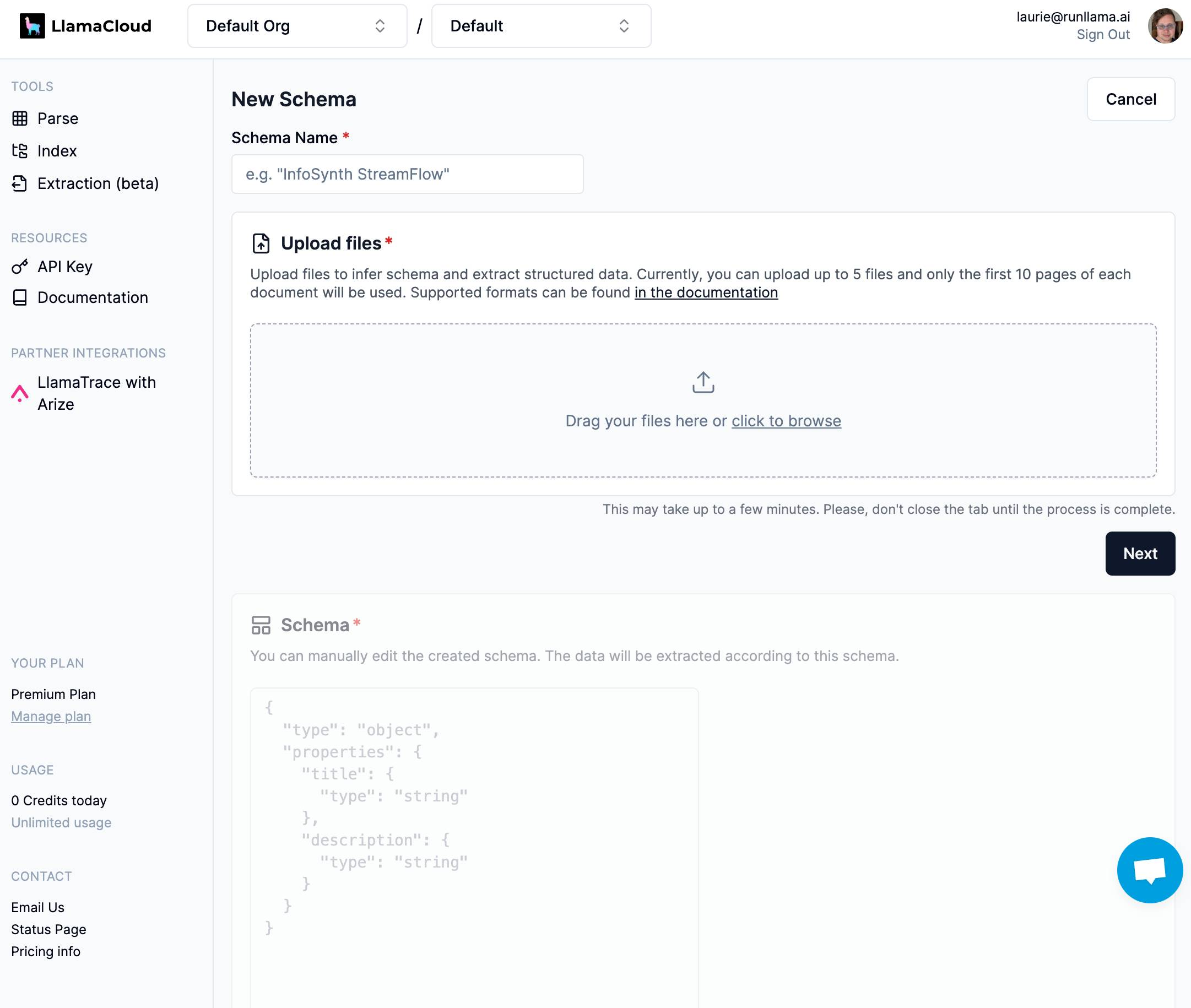
Drag and drop your files into the UI. Click “Next” to kick off schema inference – the inferred JSON schema will be shown in the “Schema” section below:
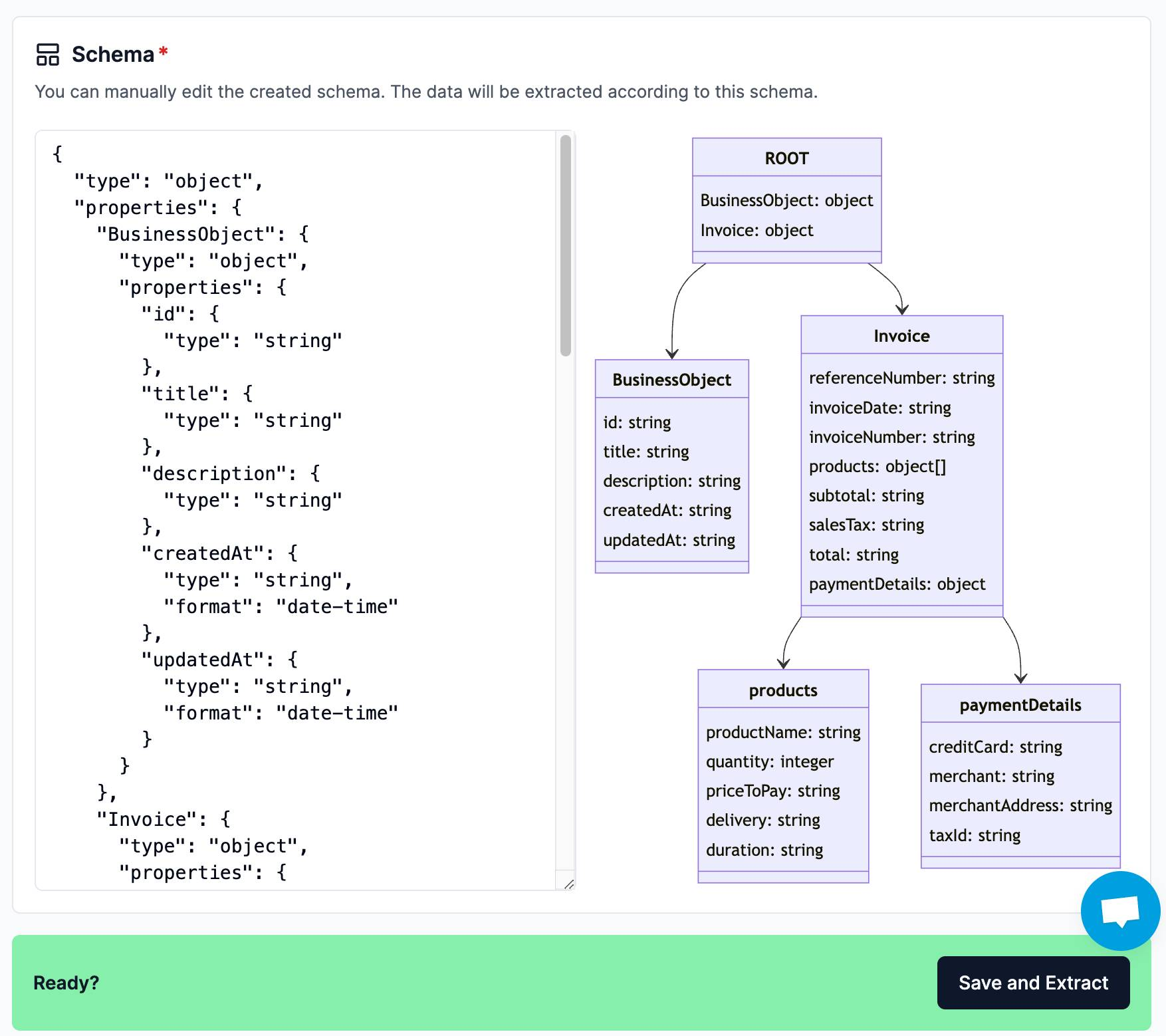
This follows the Pydantic JSON schema format; after inference you have full freedom to customize and modify the inferred schema. The schema visualization will reflect your changes.
Once you’re happy with your schema, you can kick off extraction, which will return the final JSON object with extracted keys and values in adherence with the schema.
There are some core improvements we are making to the UI, like decoupling schema inference and extraction, allowing users to pre-define a schema, etc. For more flexibility check out the API below.
Use the API to Create Extraction Workflows
The API allows users to more flexibly integrate schema inference and extraction. To access the API via our client package, follow these steps:
pip install llama-extractYou can choose to either infer a schema or specify your own schema (or infer first, and then modify it programmatically after to your liking). If you wish to use LlamaExtract’s schema inference capability, do:
from llama_extract import LlamaExtractextractor = LlamaExtract()extraction_schema = extractor.infer_schema("Test Schema", ["./file1.pdf","./file2.pdf"])If you prefer you can specify the schema directly rather than inferring it. The easiest way is to define a Pydantic object and convert that to a JSON schema:
from pydantic import BaseModel, Fieldclass ResumeMetadata(BaseModel): """Resume metadata.""" years_of_experience: int = Field(..., description="Number of years of work experience.") highest_degree: str = Field(..., description="Highest degree earned (options: High School, Bachelor's, Master's, Doctoral, Professional") professional_summary: str = Field(..., description="A general summary of the candidate's experience") extraction_schema = extractor.create_schema("Test Schema", ResumeMetadata)However you get your schema, you can now perform extraction:
extractions = extractor.extract(extraction_schema.id, ["./file3.pdf","./file4.pdf"])You can see the extracted data:
print(extractions[0].data)Some Example Use Cases
LlamaExtract uses LlamaParse as its underlying parser and is able to handle complex document types (note: native multimodal extraction coming soon!) Through our initial explorations, here are some initial datasets where LlamaExtract is valuable:
- Resumes: extract structured annotations like school, work experiences, YOE from a candidate’s profile
- Receipts and Invoices: extract line items, total price, and other figures.
- Product pages: structure and categorize your products according to a user-defined schema.
Check out the examples section of the LlamaExtract client repo to see more possibilities.
We’re Rapidly Improving our Extraction Capabilities
By opening this up to the community, we’re excited to rapidly improve the UX, scalability, and performance. Here’s an feature roadmap:
- Multimodal extraction
- Decouple schema creation from extraction in the UI
- Support for human-in-the-loop schema creation as a first class UX
- Make automated schema inference and extraction more robust over longer documents (e.g. a 10K filing)
Try it Out
LlamaExtract is available to all users. You don’t need to be let off a waitlist! Just create an account at cloud.llamaindex.ai to use the UI; you can also check out our python client. To get started, try one of these notebooks:
If you’re interested in the broader LlamaCloud functionality, join our waitlist.