
包阅导读总结
1. 关键词:
– 小型语言模型
– 边缘计算
– Nvidia Jetson Orin
– Ollama
– Microsoft Phi-3
2. 总结:
本文介绍了在边缘运行小型语言模型的方法,以 Nvidia Jetson Orin Developer Kit 为例,配置 Ollama 模型服务器,运行 Microsoft Phi-3 小型语言模型,还提及了该开发套件的性能特点,并展示了如何通过 Jupyter Notebook 访问模型。
3. 主要内容:
– 如何在边缘运行小型语言模型
– 利用云的大语言模型和边缘的小语言模型
– 目标是在边缘运行能基于本地工具提供的上下文响应用户查询的小语言模型
– Nvidia Jetson AGX Orin Developer Kit
– 是边缘 AI 和机器人计算的重大进步
– 具有高性能模块,包含特定架构的 GPU 和 CPU 等
– 提供多种内存和功率配置选择
– 在 Jetson AGX Orin Developer Kit 上运行 Ollama
– 下载和安装 Ollama 客户端
– 通过 Docker 容器运行 Ollama 推理服务器
– 在 Ollama 上运行 Microsoft Phi-3 SLM
– Phi-3 模型的特点和版本
– 运行 4K 版本的 Phi-3 mini
– 通过 Jupyter Notebook 访问模型,可在 Jetson 设备上用 jtop 命令监控 GPU 消耗
思维导图: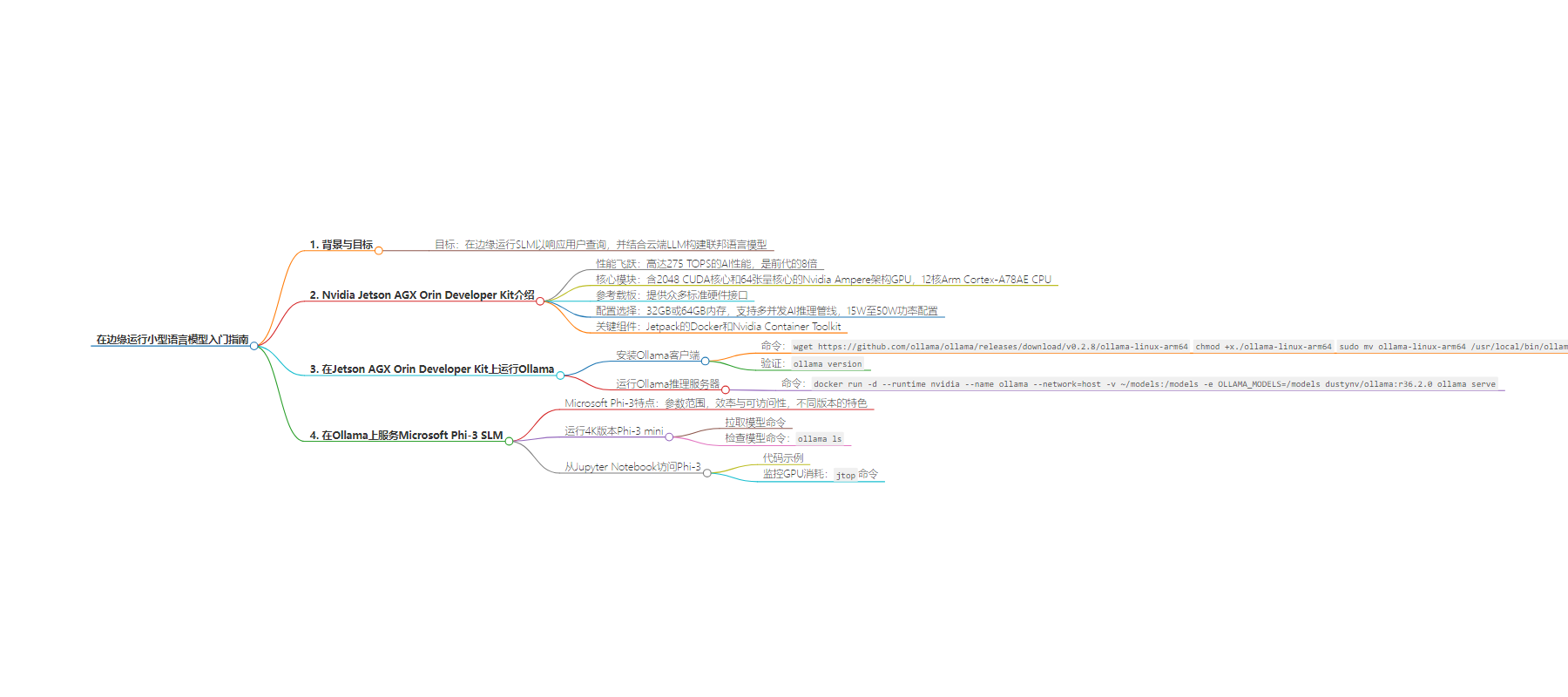
文章地址:https://thenewstack.io/how-to-get-started-running-small-language-models-at-the-edge/
文章来源:thenewstack.io
作者:Janakiram MSV
发布时间:2024/7/25 0:34
语言:英文
总字数:1001字
预计阅读时间:5分钟
评分:87分
标签:Edge Computing,Small Language Models,Nvidia Jetson AGX Orin,Ollama,Microsoft Phi-3
以下为原文内容
本内容来源于用户推荐转载,旨在分享知识与观点,如有侵权请联系删除 联系邮箱 media@ilingban.com
In my previous article, I introduced the idea of federated language models that take advantage of large language models (LLM) running in the cloud and small language models (SLM) running at the edge.
My goal is to run an SLM at the edge that can respond to user queries based on the context that the local tools provide. One of the ideal candidates for this use case is the Jetson Orin Developer Kit from Nvidia, which runs SLMs like Microsoft Phi-3.
In this tutorial, I will walk you through the steps involved in configuring Ollama, a lightweight model server, on the Jetson Orin Developer Kit, which takes advantage of GPU acceleration to speed up the inference of Phi-3. This is one of the key steps in configuring federated language models spanning the cloud and the edge.
What Is Nvidia Jetson AGX Orin Developer Kit?
The NVIDIA Jetson AGX Orin Developer Kit represents a significant leap forward in edge AI and robotics computing. This powerful kit includes a high-performance Jetson AGX Orin module, capable of delivering up to 275 TOPS of AI performance and offering eight times the capabilities of its predecessor, the Jetson AGX Xavier. The developer kit is designed to emulate the performance and power characteristics of all Jetson Orin modules, making it an incredibly versatile tool for developers working on advanced robotics and edge AI applications across various industries.

At the heart of the developer kit is the Jetson AGX Orin module, featuring an Nvidia Ampere architecture GPU with 2048 CUDA cores and 64 tensor cores, alongside a 12-core Arm Cortex-A78AE CPU. The kit comes with a reference carrier board that exposes numerous standard hardware interfaces, enabling rapid prototyping and development. With options for 32GB or 64GB of memory, support for multiple concurrent AI inference pipelines, and power configurations ranging from 15W to 50W, the Jetson AGX Orin Developer Kit provides developers with a flexible and powerful platform for creating cutting-edge AI solutions in fields such as manufacturing, logistics, healthcare, and smart cities.
See also: our previous tutorial on running real-time object detection with Jetson Orin.
For this scenario, I am using the Jetson AGX Orin Developer Kit with 32GB of RAM and 64GB of eMMC storage. It runs the latest version of Jetpack, 6.0, which comes with various tools, including the CUDA runtime.
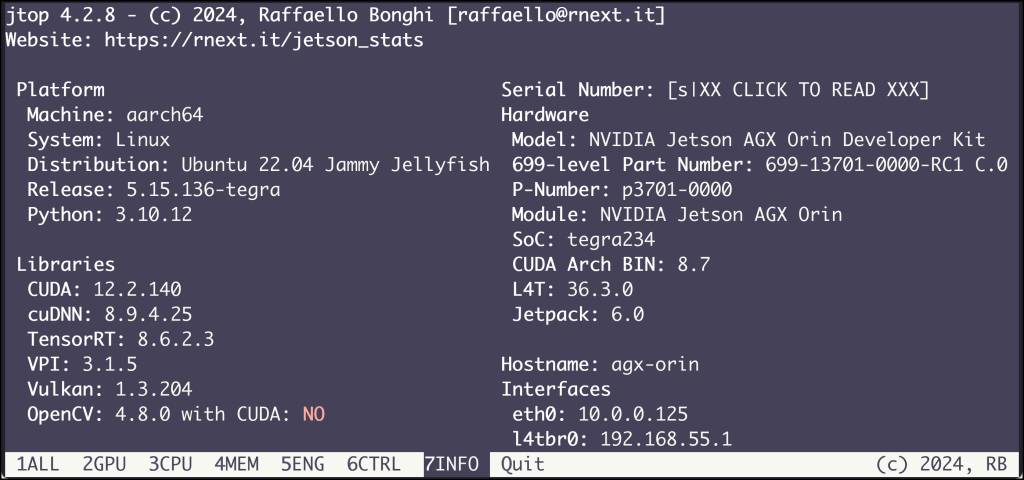
The most important components of Jetpack are Docker and the Nvidia Container Toolkit.
Running Ollama on Jetson AGX Orin Developer Kit
Ollama is a developer-friendly LLM infrastructure modeled around Docker. It’s already optimized to run on Jetson devices.
Similar to Docker, Ollama has two components: the server and the client. We will first install the client, which comes with a CLI that can talk to the inference engine.
|
wget https://github.com/ollama/ollama/releases/download/v0.2.8/ollama–linux–arm64
chmod +x ./ollama–linux–arm64
sudo mv ollama–linux–arm64 /usr/local/bin/ollama |
The above commands download and install the Ollama client.
Verify the client with the below command:
Now, we will run the Ollama inference server through a Docker container. This avoids any issues you may encounter while accessing the GPU.
|
docker run –d \ —runtime nvidia \ —name ollama \ —network=host–v ~/models:/models \ –e OLLAMA_MODELS=/models \ dustynv/ollama:r36.2.0ollama serve |
This command launches the Ollama server on the host network, enabling the client to directly talk to the engine. The server is listening on port 11434, which exposes an OpenAI-compatible REST endpoint.
Running the command ollama ps shows an empty list, since we haven’t downloaded the model yet.
Serving Microsoft Phi-3 SLM on Ollama
Microsoft’s Phi-3 represents a significant advancement in small language models (SLMs), offering impressive capabilities in a compact package. The Phi-3 family includes models ranging from 3.8 billion to 14 billion parameters, with the Phi-3-mini (3.8B) already available and larger versions like Phi-3-small (7B) and Phi-3-medium (14B) coming soon.
The Phi-3 models are designed for efficiency and accessibility, making them suitable for deployment on resource-constrained edge devices and smartphones. They feature a transformer decoder architecture with a default context length of 4K tokens, with a long context version (Phi-3-mini-128K) extending to 128K tokens.
For this tutorial, we will run the 4K flavor of the model, which is Phi-3 mini.
With the Ollama container running and the client installed, we can pull the image with the below command:
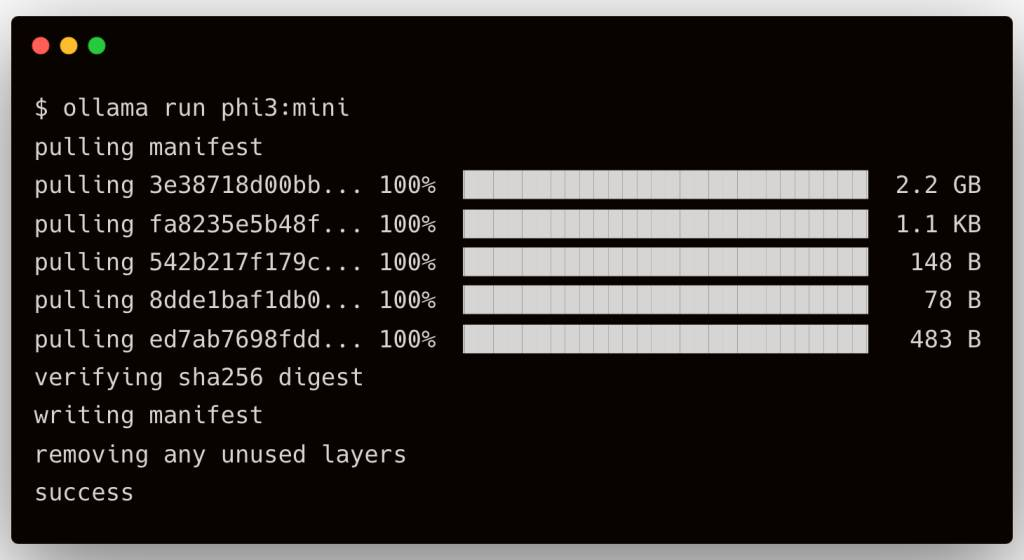
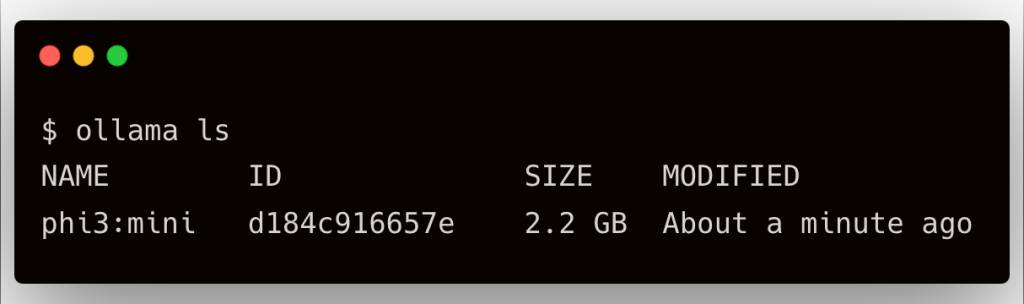
Check the model with the command ollama ls.
Accessing Phi-3 from a Jupyter Notebook
Since Ollama exposes an OpenAI-compatible API endpoint, we can use the standard OpenAI Python client to interact with the model.
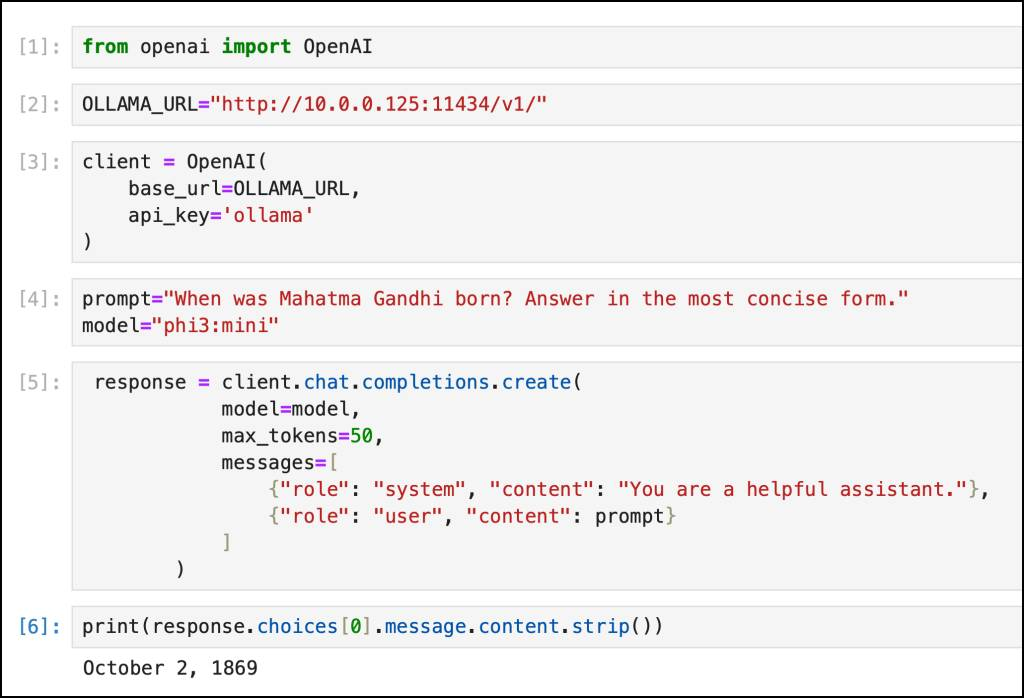
Try the below code snippet by replacing the URL with the IP address of Jetson Orin.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from openai import OpenAI OLLAMA_URL=“YOUR_JETSON_IP::11434/v1/”
client = OpenAI( base_url=OLLAMA_URL, api_key=‘ollama’ )
prompt=“When was Mahatma Gandhi born? Answer in the most concise form.” model=“phi3:mini”
response = client.chat.completions.create( model=model, max_tokens=50, messages=[ {“role”: “system”, “content”: “You are a helpful assistant.”}, {“role”: “user”, “content”: prompt} ] )
print(response.choices[0].message.content.strip()) |
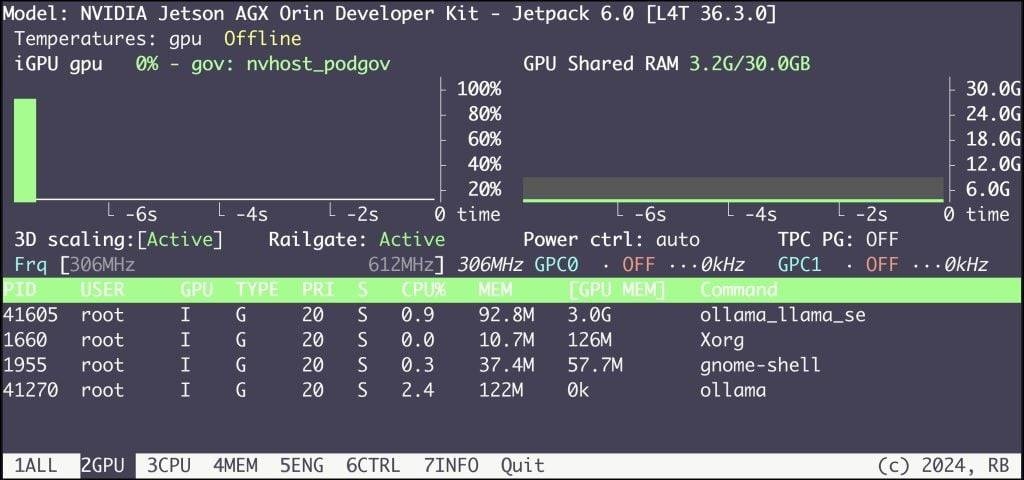
On the Jetson device, you can monitor the consumption of the GPU with the jtop command.
This tutorial covered the essential steps required to run Microsoft Phi-3 SLM on a Nvidia Jetson Orin edge device. In the next part of the series, we will continue building the federated LM application by leveraging this model. Stay tuned.
YOUTUBE.COM/THENEWSTACK
Tech moves fast, don’t miss an episode. Subscribe to our YouTubechannel to stream all our podcasts, interviews, demos, and more.